超進化したAI「ChatGPT」が生み出す無限のクイズをライブ配信してみた


こんにちは、テリーです。2023年1月に急速に認知度が高まったAI、ChatGPTは世界で瞬く間に広がっています。急激に変わっていく社会には期待と不安の両方を感じる人もいるでしょう。携帯電話が出た時も、スマートフォンが出た時もライフスタイルが変わるのはあっという間でした。このテクノロジーの流れは止められないので、人間がAI社会に適応する必要があります。
さて、今回はChatGPTをデータ生成機と位置づけ、出力されたデータの一部を字幕としてライブ配信中の画面に表示するサンプルを紹介します。VTuberがライブ配信で使うケースを想定して、三択クイズの作成を依頼し、クイズの質問、正解、誤答2つ、やや長めの解説、をChatGPTに無限に考えてもらいます。OBSで文字列を字幕表示する方法は前回の記事を参照してください。
動作確認環境
- Windows 11
- Python 3.10.11
- OBS 29.0.2
ChatGPTをWeb APIとして使う方法
ChatGPTはブラウザで会話するだけでなく、プログラムからWeb APIとして呼ぶことができます。こちらに詳しく書かれています。ライブラリを使わずにピュアなHTTPリクエストとしても呼び出しは可能ですが、今回はPythonのライブラリを使用します。まずはアカウントを登録し、APIKEYを取得します。Windows Terminal(PowerShell)を実行し、環境変数に設定します。
$Env:OPENAI_API_KEY="(取得したAPIKEY)"下記のコマンドをPowerShellで実行します。専用のフォルダを作成し、ChatGPTのPython用のライブラリをインストールし、VSCodeでカレントフォルダを開きます。
mkdir aiquiz
cd aiquiz
python -m venv .
.\Scripts\Activate.ps1
pip install openai
python -m pip install --upgrade pip
code .VSCodeで下記のPythonコードを実行し、OpenAIのライブラリのインストールが成功していること、APIキーが正しいことを確認します。
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
list = openai.Model.list()
for model in list["data"]:
print(model.id)実行すると64個ものモデルidが表示されます。この中から一つのモデルを選びます。モデルによってそれぞれ特徴があり、質問に対する回答に個性が現れます。本記事執筆時点では text-davinci-003 が応答速度が速くライブ配信には適しているように見えます。
ChatGPTをデータ生成機として使うコツ
ChatGPTをPythonプログラムから呼べるようになりました。次はデータ生成機として使う方法について解説します。ChatGPTは人間が読むための文章を返す前提で作られているため、改行、句読点、区切り文字は会話のたびにバラツキがあります。下記の例では全角のセミコロンで問題、選択肢、解説を書き出し、選択肢3つは、A,B,Cで区別され、ドットのあとにデータが来ています。正解がどれかも解説を読めばわかりますが、プログラムからはわかりません。こういったChatGPTの文字列データを自作のプログラムで解釈するのは大変です。

そこで、あらかじめ返答の書式(フォーマット)をChatGPTに指定し、その書式が返ってくる前提でデータをパースします。
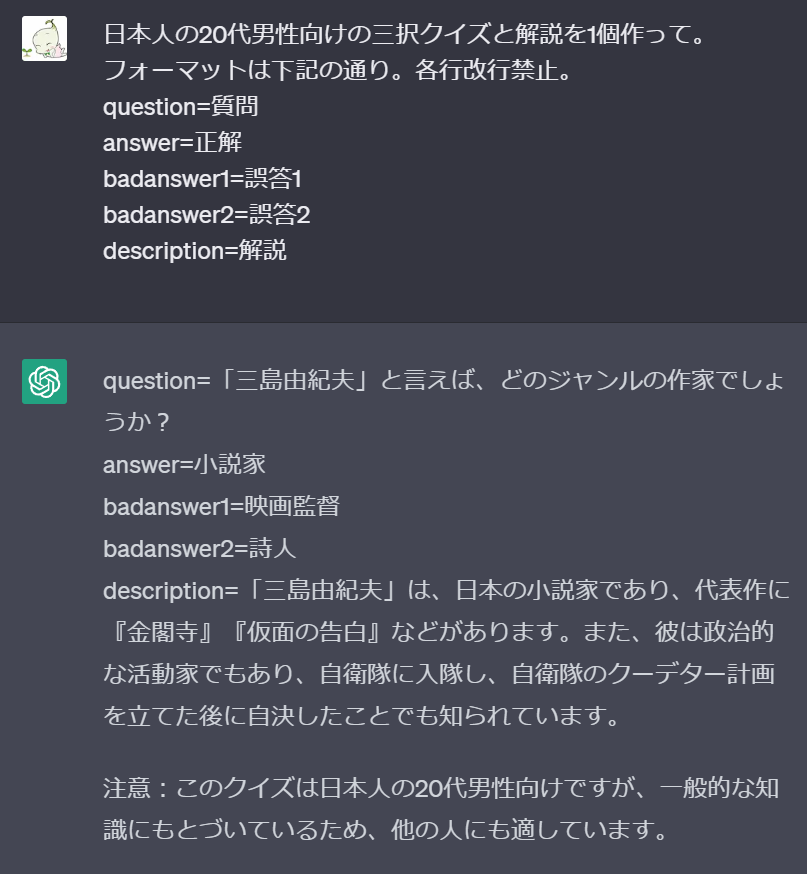
WebAPIらしくJSONフォーマットを使いたくなりますが、ダブルクォーテーションが閉じていない、コンマがついていない、文頭文末に不要な文字がついている、などのJSON的に文法違反をしているレスポンスが返ってくる確率がかなり高いです。それらの文法違反を復旧・回避するためのコードを自作するととても冗長になります。本サンプルのようにデータのメンバーが確定的で増減が少ない場合はキーとバリューを=でつないだ、TOML形式風に具体的に指示を出す方法がおススメです。この場合、多少の文法違反でもパースに失敗する確率が下がります。
ChatGPTをクイズデータ生成機として使う
以上をふまえた下記のコードをaiquiz.pyというファイル名で作成し、実行します。
1 import os
2 import openai
3 import random
4
5 openai.api_key = os.getenv("OPENAI_API_KEY")
6 # MODEL_NAME = "gpt-3.5-turbo"
7 MODEL_NAME = "text-davinci-003"
8
9 PROMPT = """
10 日本人の20代男性向けの三択クイズと解説を1個作って。
11 フォーマットは下記の通り。各行改行禁止。
12 question=質問
13 answer=正解
14 badanswer1=誤答1
15 badanswer2=誤答2
16 description=解説
17 """
18
19
20 def createQuiz():
21 for _ in range(3):
22 try:
23 if MODEL_NAME == "gpt-3.5-turbo":
24 response = openai.ChatCompletion.create(
25 model=MODEL_NAME,
26 messages=[{"role": "user", "content": PROMPT}],
27 temperature=1,
28 frequency_penalty=2.0,
29 max_tokens=1000,
30 )
31 responsetext = response["choices"][0]["message"]["content"]
32 else:
33 response = openai.Completion.create(
34 model=MODEL_NAME,
35 prompt=PROMPT,
36 temperature=1,
37 frequency_penalty=2.0,
38 max_tokens=1000,
39 )
40 responsetext = response["choices"][0]["text"]
41 data = {}
42 for line in responsetext.splitlines():
43 kv = line.split("=", maxsplit=1)
44 if len(kv) < 2:
45 continue
46 key = kv[0].strip()
47 if len(key) > 0:
48 data[key] = kv[1].strip().replace('"', "")
49 assert data.keys() >= {
50 "question",
51 "answer",
52 "badanswer1",
53 "badanswer2",
54 "description",
55 }
56 answers = [data["answer"], data["badanswer1"], data["badanswer2"]]
57 random.shuffle(answers)
58 data["answers"] = answers
59 return data
60 except Exception as e:
61 print("error", e)
62
63
64 if __name__ == "__main__":
65 for i in range(2):
66 try:
67 qa = createQuiz()
68 print("質問", i + 1, ":", qa["question"])
69 print("選択肢:", qa["answers"])
70 print("正解:", qa["answer"])
71 print("解説:", qa["description"])
72 print()
73 except Exception as e:
74 print("error", e)実行するとコンソールに質問、選択肢、正解、解説が2組表示されます。

上記コードの主要部分を解説します。
9 PROMPT = """
10 日本人の20代男性向けの三択クイズと解説を1個作って。
11 フォーマットは下記の通り。各行改行禁止。
12 question=質問
13 answer=正解
14 badanswer1=誤答1
15 badanswer2=誤答2
16 description=解説
17 """9~17行目は、Pythonの三連引用符の文法を使って、複数行文字列でChatGPTに送る問い合わせ文を定義します。ChatGPTに限らず、AIに送る問い合わせ文または質問文のことを「プロンプト」と言います。
今回は三択クイズを作りましたが、細かいノウハウが詰まっています。
- 「日本人の20代男性向け」: 楽しく解けるクイズを作るためには視聴者層にマッチしなければなりません。アメリカの女性にしかわからない問題を日本人の男性に出されても楽しく感じません。
- 「解説」: 正解だけでなく、ウンチクや解説を知りたい場合もあるでしょう。
- 「1個」: 1回のAPI呼び出しで複数のデータを作る依頼を出すこともできますが、応答に時間がかかりタイムアウトが発生することもありますので、1つに限定します。
- 「フォーマットは下記の通り」: 自作プログラムで少ない行数でパースできるように書式を指定します。
- 「各行改行禁止」: パース処理をシンプルにするために改行禁止を明示します。
20 def createQuiz():
21 for _ in range(3):
22 try:
60 except Exception as e:
61 print("error", e)20-22行目、60-61行目
ChatGPTは応答が完了する前に途中でタイムアウトしたり、文法違反のまま終了することがよくあります。そこで、エラーが発生しても最大3回リトライを繰り返します。
23 if MODEL_NAME == "gpt-3.5-turbo":
24 response = openai.ChatCompletion.create(
25 model=MODEL_NAME,
26 messages=[{"role": "user", "content": PROMPT}],
27 temperature=1,
28 frequency_penalty=2.0,
29 max_tokens=1000,
30 )
31 responsetext = response["choices"][0]["message"]["content"]最新のgpt-3.5-turboとgpt-4からAPIの仕様が新しくなっています。最新のものを使いたくなりますが、応答速度が10数秒かかるため、ライブ配信には向かないようです。今後クイックレスポンスのモデルも登場するでしょうから、参考として書いておきます。
33 response = openai.Completion.create(
34 model=MODEL_NAME,
35 prompt=PROMPT,
36 temperature=1,
37 frequency_penalty=2.0,
38 max_tokens=1000,
39 )
40 responsetext = response["choices"][0]["text"]33行目: gpt-3.5-turbo以外のモデルを使用する場合のAPI呼び出しです。
34行目: モデルIDを指定します。
35行目: 問い合わせ文(プロンプト)を指定します。
36-37行目: 同じクイズが2度出ないようにするパラメータです。
38行目: 長すぎる解説が出ないように、文字数の上限を指定します。
40行目: ChatGPTのAPIレスポンスの中から、主要となるテキストを受け取ります。
41 data = {}
42 for line in responsetext.splitlines():
43 kv = line.split("=", maxsplit=1)
44 if len(kv) < 2:
45 continue
46 key = kv[0].strip()
47 if len(key) > 0:
48 data[key] = kv[1].strip().replace('"', "")
49 assert data.keys() >= {
50 "question",
51 "answer",
52 "badanswer1",
53 "badanswer2",
54 "description",
55 }
56 answers = [data["answer"], data["badanswer1"], data["badanswer2"]]
57 random.shuffle(answers)
58 data["answers"] = answers
59 return data41-55行目は自前のパース処理です。=(イコール)でキーとバリューを分割し、連想配列に代入します。まれにメンバーが不足している場合があるので、不正な書式やデータを検知したらエラーとみなしてリトライします。
56-58行目で画面に表示する選択肢をランダムに並び替えています。
64 if __name__ == "__main__":
65 for i in range(2):
66 try:
67 qa = createQuiz()
68 print("質問", i + 1, ":", qa["question"])
69 print("選択肢:", qa["answers"])
70 print("正解:", qa["answer"])
71 print("解説:", qa["description"])
72 print()
73 except Exception as e:
74 print("error", e)64行目以降はこのソースコード単体で動作確認するための処理です。問題を2問作成し、ターミナルに出力します。
OBSにデータを送り、クイズ字幕を表示
次にOBSに対して字幕を送り、問題を数秒、正解と解説を数秒、を無限に繰り返します。
下記のコードを obsaiquiz.py という名前で保存して実行してください。
1 import os
2 import re
3 import time
4 import threading
5 import obsws_python as obs
6 import sys
7
8 sys.path.append(os.path.dirname(os.path.abspath(__file__)))
9 from aiquiz import createQuiz
10
11 OBS_PASSWORD = "your_obs_password"
12 TARGET_SOURCE_NAME = "クイズ"
13 CSS_TEMPLATE_PATH = os.path.join(
14 os.path.dirname(os.path.abspath(__file__)), "jimaku.css"
15 )
16
17
18 def load_css_tempalte():
19 global CSS_TEMPLATE
20 with open(CSS_TEMPLATE_PATH, encoding="utf-8") as f:
21 CSS_TEMPLATE = f.read()
22
23
24 def send_jimaku(text):
25 print(text)
26 text = "\\\A ".join([line for line in text.replace('"', "").splitlines()])
27 css = re.sub(" content: .*;", ' content: "' + text + '";', CSS_TEMPLATE)
28 global obscl
29 try:
30 obscl
31 except Exception as e:
32 obscl = obs.ReqClient(host="localhost", port=4455, password=OBS_PASSWORD )
33 try:
34 obscl.set_input_settings(TARGET_SOURCE_NAME, {"css": css}, True)
35 except Exception as e:
36 print(e)
37
38
39 def wait(t: int):
40 for _ in range(t):
41 if threadalive:
42 time.sleep(1)
43
44
45 def qasend():
46 while threadalive:
47 while threadalive and len(qalist) == 0:
48 print("waiting chatgpt response")
49 time.sleep(1)
50 qa = qalist.pop()
51 jimaku = (
52 "質問: "
53 + qa["question"]
54 + "\n"
55 + "\n".join([str(i + 1) + ". " + v for i, v in enumerate(qa["answers "])])
56 )
57 send_jimaku(jimaku)
58 wait(5)
59 if threadalive:
60 jimaku = "正解: " + qa["answer"] + "\n" + qa["description"]
61 send_jimaku(jimaku)
62 wait(5)
63
64
65 def main():
66 load_css_tempalte()
67 send_jimaku("問題作成中...")
68 global qalist
69 qalist = []
70 global threadalive
71 threadalive = True
72 threading.Thread(target=qasend).start()
73 try:
74 while True:
75 if len(qalist) < 2:
76 qalist.append(createQuiz())
77 else:
78 time.sleep(1)
79 except KeyboardInterrupt:
80 threadalive = False
81 send_jimaku("")
82 sys.exit(0)
83
84
85 if __name__ == "__main__":
86 main()75行目で問題は常に2件、メモリに蓄えようとしています。
72行目前後でマルチスレッドで動かしているのは、ChatGPTの応答にそれなりの秒数(5~30秒)がかかるためです。問題の表示と正解・解説の表示の間隔は、同じ秒数が望ましく、また、解説を読み終わったあとの次の問題を表示するまでの間隔がバラバラだと動作に不安を覚えます。そこで、ChatGPTからのデータ取得をメインスレッドで行い、2件キャッシュさせ続けた上で、OBSへの送信タイミングの調整を別スレッドで行っています。両方とも別スレッドで行うことも可能ですが、サンプルコードを短くするためにこのような実装としています。PythonのプログラムはCTRL+Cで強制終了させてもバックグラウンドスレッドが終了しないことがあるので、スレッドからOpenAIのAPIを呼ぶ場合は特に気を付けてください。気づかずに何日も動作させ続けると、意図せずにAPIの無料枠を使い切ってしまいます。上記プログラムの場合はメインスレッドで動作しているため、そういったことは起こりません。
字幕データ表示のためのCSSは、前回の記事でご紹介したものとほぼ同じです。文字色は背景の映像に合わせて修正するとよいでしょう。
jimaku.css というファイル名で、同じフォルダに保存してください。
@import
url('https://fonts.googleapis.com/css2?family=M+PLUS+Rounded+1c:wght@900&display=swap');
body {
margin: 0;
padding: 0;
border: 0;
display: flex;
flex-wrap: wrap;
justify-content: center;
align-items: flex-end;
align-content: flex-end;
overflow: hidden;
margin: 5vh 5vh;
font-family: 'M PLUS Rounded 1c', sans-serif;
font-size: 9vh;
line-height: 1.1em;
text-align: center;
position: relative;
white-space: pre-wrap;
}
body::before {
content: attr(data-text);
position: absolute;
color: #FFF;
-webkit-text-stroke: 0.5vh #00F;
z-index: 30;
}
body::after {
content: attr(data-text);
position: absolute;
color: #00F;
-webkit-text-stroke: 1.0vh #00F;
z-index: 20;
}最後に僕が撮影したサンプル動画をお見せしましょう。ときどき長すぎる解説や誤答選択肢を出してくることもありますが、ご愛敬というところでしょうか。

まとめ
ChatGPTをクイズデータ生成機として呼び出し、そのレスポンスを自作プログラムでパースしてOBSに字幕表示させるサンプルをご紹介しました。この仕組みならば1時間でも24時間でもライブ配信可能です。一つ注意しないといけないのは「ChatGPTの作成したクイズ問題に対する"正解"が事実に反することがある」ということです。必ずしもうのみにせず、気になるものは自分で調べましょう。クイズ以外にもアンケートやチャットの自動応答にも応用できそうです。ぜひ挑戦してみて下さい。
