マネージドMariaDBサービスの設計と仕組みについて


概要
こんにちは。
さくらインターネット株式会社 クラウド事業本部 SRE室の菅原大和(@drumato)です。
本記事では、先日「さくらのクラウド Labプロダクト」としてリリースされた、「エンハンスドデータベース」のMariaDB版について、その背景や目的、設計や仕組みについてかんたんに紹介します。また後半では、SREsの私が現段階の運用をどう改善し、どう今後の方針を組み立てているのかについて共有します。
リリース内容についてはこちらのニュースページをご覧ください。
https://cloud.sakura.ad.jp/news/2023/05/18/enhanceddb-mariadb-lab-release/
本記事全体を通して、MariaDB版エンハンスドデータベースの利用方法等については解説しません。よろしければ以下の公式マニュアルをご覧ください。
https://manual.sakura.ad.jp/cloud/appliance/enhanced-db/index.html
背景
さくらのクラウドとストレージサービス
さくらのクラウドでは、お客様がIaaSを利用して、サーバや仮想ネットワークを作成しシステムを構築できるようになっています。例えば、あるAPIサーバを運用するためのシステムとして、以下のような構成が考えられます。
- APIサーバをデプロイするサーバを、東京第一/第二ゾーンに用意する
- サーバのフロントエンドにエンハンスドロードバランサを配置する
このような場合に、APIサーバが連携するDBシステムをどのように構築するか、という選択肢が存在します。ここでは、後述するエンハンスドデータベースを除いた、大まかな比較表を以下に載せておきます。
| 選択肢 | 説明 | 手軽さ | DBシステムの冗長性 |
|---|---|---|---|
| 「DBアプライアンス」を利用する | お客様アカウント内に作成されたネットワークに接続する形でRDBMSが提供される | ○ コントロールパネルの操作だけで利用開始できる | △ ゾーン内での冗長性のみサポート |
| 「サーバ」を利用する | 作成した「サーバ」の上にDBシステムを構築する作業を、お客様自身が行う | × インストールや管理・運用等々がすべてお客様側で行われる | ○ 設計/運用によって、マルチリージョン/ゾーンで構成することも可能 |
| 外部のマネージドなデータベースサービスを利用する | AWSやGCPなど、さくらのクラウドの外部でDBシステムを構築して利用する | △ 2つ以上のパブリッククラウドサービスを併用するので、管理が煩雑になる | - 利用するサービスの冗長性に依存する |
この表から、さくらインターネットのシステムを利用して、マルチゾーンにDBシステムを構築し、それらを手軽に利用する選択肢がなかった、という背景がわかると思います。
エンハンスドデータベースについて
上述した背景から、さくらインターネットではエンハンスドデータベースプロジェクトが始動しました。これは、今までよりもかんたんに、かつ信頼性を実現したマネージドなDBサービスを目指したもので、後ほど紹介するMariaDB版とは別に、すでにTiDB版がLabプロダクトとして提供されています。
TiDBはオープンソースの分散SQLデータベースで、NewSQL実装の一つです。
- HTAP(Hybrid Transactional and Analytical Processing)データベース
- TiKVとTiFlashという2つのストレージエンジンを組み合わせることで、どちらのユースケースにも対応
- 水平スケーリング
- クエリエンジンとデータストアのコンポーネントを分けることができ、それぞれ独立してスケールできる
- tiupを利用した、宣言的でプラクティカルな運用
- マルチテナンシー
- MySQL互換
という特徴を持ちます。
TiDB版エンハンスドデータベースについては、当社からのニュースリリースや、過去に江草さんが発表した資料を以下に載せておきます。
- https://www.sakura.ad.jp/information/newsreleases/2021/07/08/1968207460/
- https://knowledge.sakura.ad.jp/29695/
MariaDB版エンハンスドデータベース
目的
上述したTiDB版エンハンスドデータベースは高いスケーラビリティとMySQL互換性を持ちますが、一部MySQLの機能で対応していないものがあります。詳しくは下記のURLをご覧ください。
https://docs.pingcap.com/tidb/v7.0/mysql-compatibility
また、(あくまで現状は、ですが)TiDB版エンハンスドデータベースはシングルゾーンに展開されており、ゾーン障害に強く影響を受けます。さらに、お客様の様々な背景から、NewSQLを選択しない場合もあるかもしれません。このような需要に対応するべく、マルチゾーンに展開するMariaDBクラスタを構築し、それを提供することにしました。
本プロジェクトは大久保さん(@jh1vxw) によって考案・設計・初期実装されました。私はその中で、db-controllerというコアコンポーネントのリプレイスや、モニタリング環境の整備、SLO策定、定期的な負荷試験実施の提案など、開発から運用まで貢献する役割を担っています。
仕組み
MariaDB版エンハンスドデータベースのアーキテクチャを以下に示します。マルチゾーンに展開されたDBクラスタのフロントエンドにGSLBが存在し、DBサーバに対する負荷分散を行います。
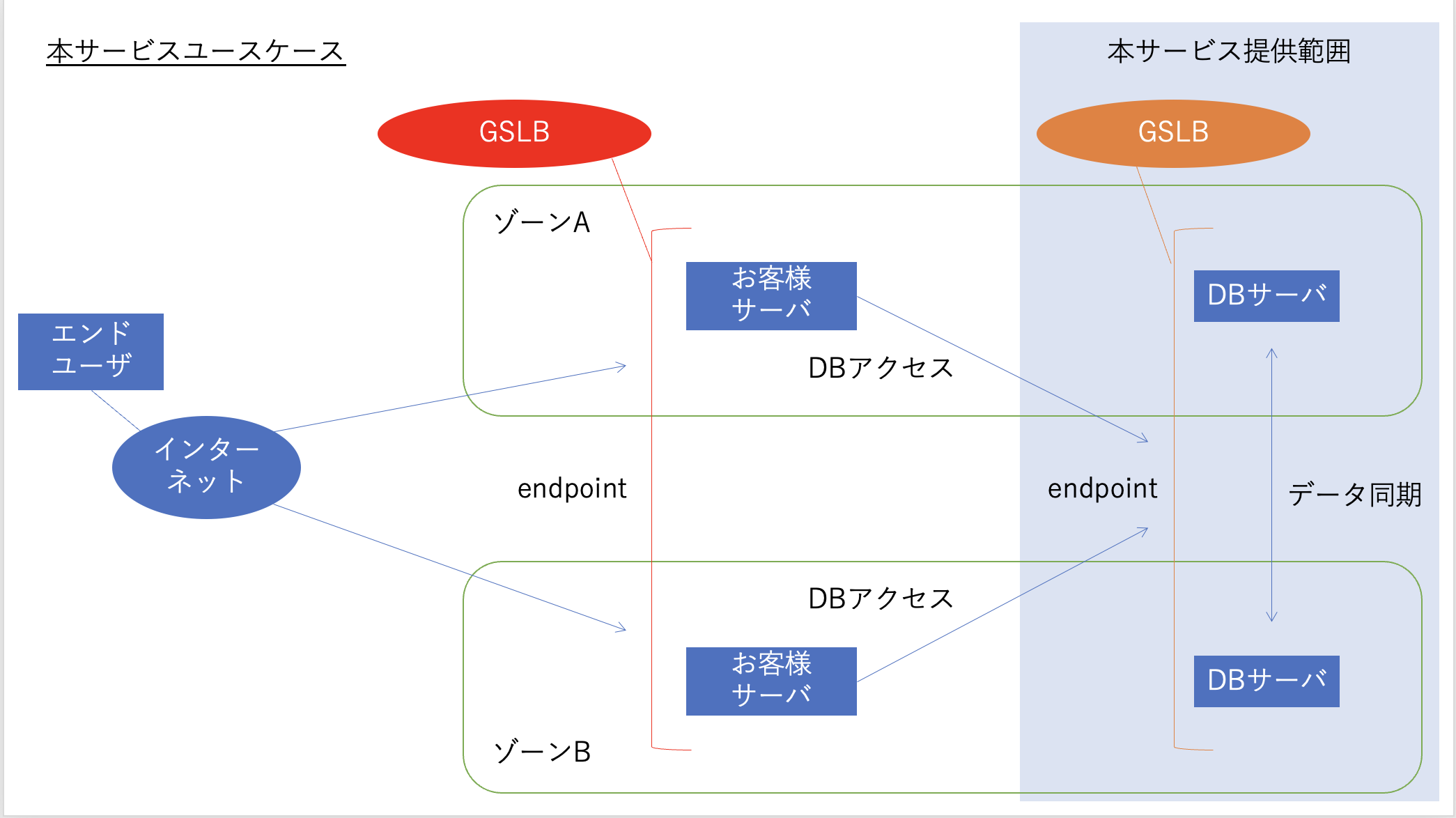
それぞれのDBサーバでは、下図のようなコンポーネントが協調動作して動いています。
ここで、db-controllerおよびedb-service-proxyが、さくらインターネットで独自に開発されたソフトウェアコンポーネントです。db-controllerはプロトタイプの段階では大久保さんがPerlで実装したものでしたが、現在は私がGoにリプレイスし、HTTP APIサーバやPrometheus Exporterが組み込まれたものになっています。また、ユニットテストや機能テストを整備して、オリジナル版に比べて開発が進めやすいものになっています。
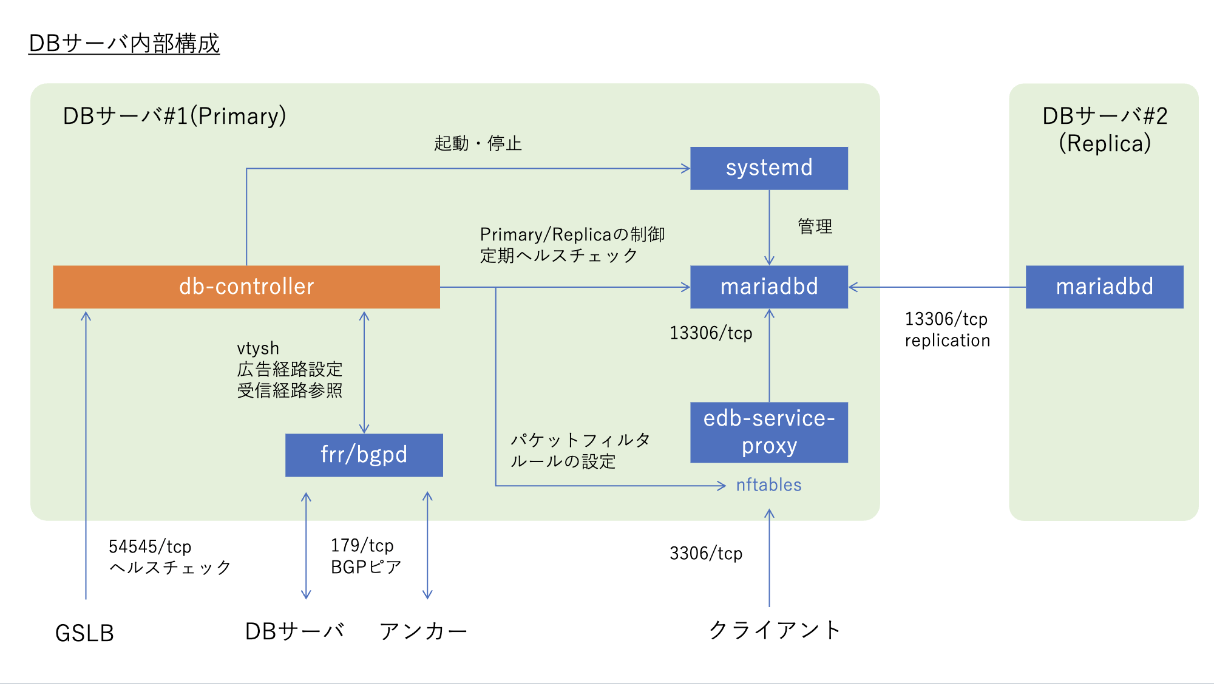
各クラスタは、MariaDBを動かすサーバ(以下dbserver)2台と、それらと連携するアンカーノードで構成されます。dbserverで動くdb-controllerは、MariaDBのレプリケーションやnftablesによるパケットフィルタ、FRRoutingのコンフィグ書き換えなどを行い、分散システム内での役割を調整します。
以下、それぞれのコンポーネントについて解説します。
db-controller
db-controllerは、dbserver上で動作するGoプログラムで、db-controller同士で連携しつつ、MariaDBを含むシステムソフトウェアを適切に設定します。これは、以下のような状態遷移図を持つステートマシンとして動作します。

それぞれ、次のような役割を持ちます。
- fault … 何らかの期待しない状態を検知した場合や、他のノードがprimaryに昇格する準備を進めている場合に遷移する
- candidate … primaryに昇格する意思表示を行う、1クッション置くためのステート
- 他ステートは、自身以外のノードにcandidateノードが存在する場合に、自身のステートを維持する
- クラスタ内で必ず1台以内になるように調整する
- replica … クラスタのレプリカノードとして動作する
- primary … クラスタのプライマリノードとして動作する
例えばPrimaryノードであれば、nftablesの設定を書き換えて、MariaDB(edb-service-proxy)が待ち受けるポートのインバウンドトラフィックを許可したり、実際にMariaDBにレコードを挿入できるかのテストを実行したりします。
db-controllerはGSLBのヘルスチェックに応答するエンドポイントを用意しており、そのヘルスチェックをもとに負荷分散を行います。
edb_service_proxy
dbserverで動作するGo製のリバースプロキシで、送信元ネットワークの制限機能を提供していたり、TLS終端を行っています。
FRRouting
MariaDB版エンハンスドデータベースでは、dbserverの経路広報にFRRoutingというオープンソースのルーティングプロトコルスイートを利用しています。
本アーキテクチャの大きな特徴として、BGPを経路広報のためのルーティングプロトコルとしてだけではなく、ネットワーク分断の検出や、それぞれのdb-controllerの内部状態の広報としても使用している点があります。具体的には、db-controllerの内部状態をBGP Communityで表現し、自身のユニキャストIPアドレスを広報し合うことで、お互いの状態を検出しあいます。
サンプルとして、あるサーバのFRRoutingコンフィグを以下に載せておきます。eBGPを使うことも検討されましたが、multihopを有効化する必要があり、現在はシンプルにiBGPで運用されています。それぞれのステートに対するroute-mapを定義しておいて、db-controller側で状態遷移が行われた際に、自身のユニキャストIPを広報する設定を書き換えて、適用するroute-mapを変更します。
hostname dbserver1
log syslog informational
no ip forwarding
no ipv6 forwarding
ip nht resolve-via-default
bgp no-rib
!
!
router bgp 65001
bgp router-id xxx.xxx.xxx.xxx
bgp log-neighbor-changes
no bgp network import-check
neighbor yyy.yyy.yyy.yyy remote-as 65001
neighbor yyy.yyy.yyy.yyy timers 3 9
neighbor zzz.zzz.zzz.zzz remote-as 65001
neighbor zzz.zzz.zzz.zzz timers 3 9
address-family ipv4 unicast
network xxx.xxx.xxx.xxx/32 route-map fault
neighbor yyy.yyy.yyy.yyy route-reflector-client
neighbor zzz.zzz.zzz.zzz route-reflector-client
exit-address-family
!
bgp community-list standard fault seq 5 permit 65001:1
bgp community-list standard candidate seq 5 permit 65001:2
bgp community-list standard primary seq 5 permit 65001:3
bgp community-list standard replica seq 5 permit 65001:4
bgp community-list standard anchor seq 5 permit 65001:10
!
route-map fault permit 10
set community 65001:1
!
route-map candidate permit 10
set community 65001:2
!
route-map primary permit 10
set community 65001:3
!
route-map replica permit 10
set community 65001:4
!
route-map anchor permit 10
set community 65001:10
!
line vty
!よく使われるサービス間連携の仕組みとしてHTTP APIやgRPCなどが挙げられますが、本アーキテクチャでは、コンポーネント間の情報交換にBGPが使われています。このようになっているメリットは後述します。
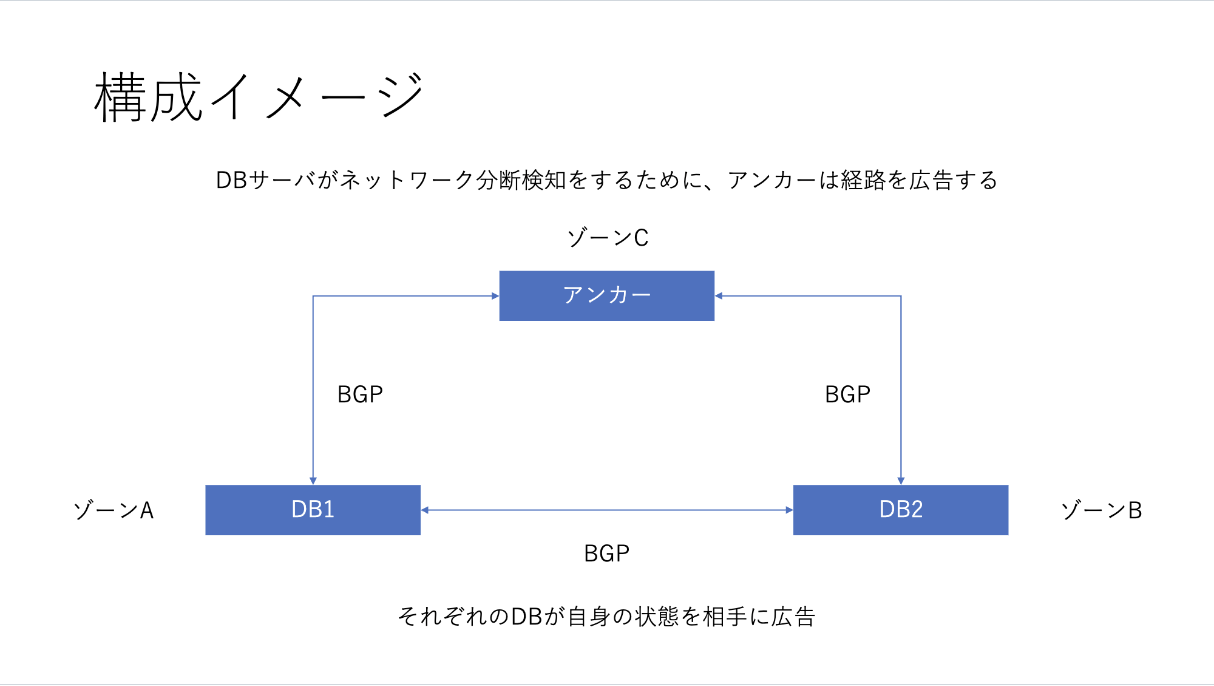
ここでアンカー(ノード)を用意している理由は、主に2つあります。
1つ目は、いわゆる"スプリットブレイン"の可能性を減らすためです。上記の図でアンカーが存在しないことを考えると、DB1-DB2間のネットワーク障害が起こった場合に、それぞれがPrimaryに状態遷移してしまい、スプリットブレイン状態となってしまいます。そこでアンカーを設けることで、DB1-DB2間のネットワーク障害が起こった場合でも、アンカーノード経由でステートが交換されます。これは、HTTP APIやgRPCを用いた場合でも、アンカーに追加の仕組みを実装したり、db-controllerのロジックを作り込むことで解決できますが、BGPに組み込まれている、「経路が数珠つなぎに伝搬される」機能を利用することで、シンプルに実現できています。
2つ目は、「自身のノードがネットワーク的に分断された」のか、「相手のdbserverがネットワーク分断されている」のかを区別するためです。これについて、障害時の動作パターンをもとに説明します。
まず、プライマリノードがネットワーク分断されたときの動作を以下に示します。
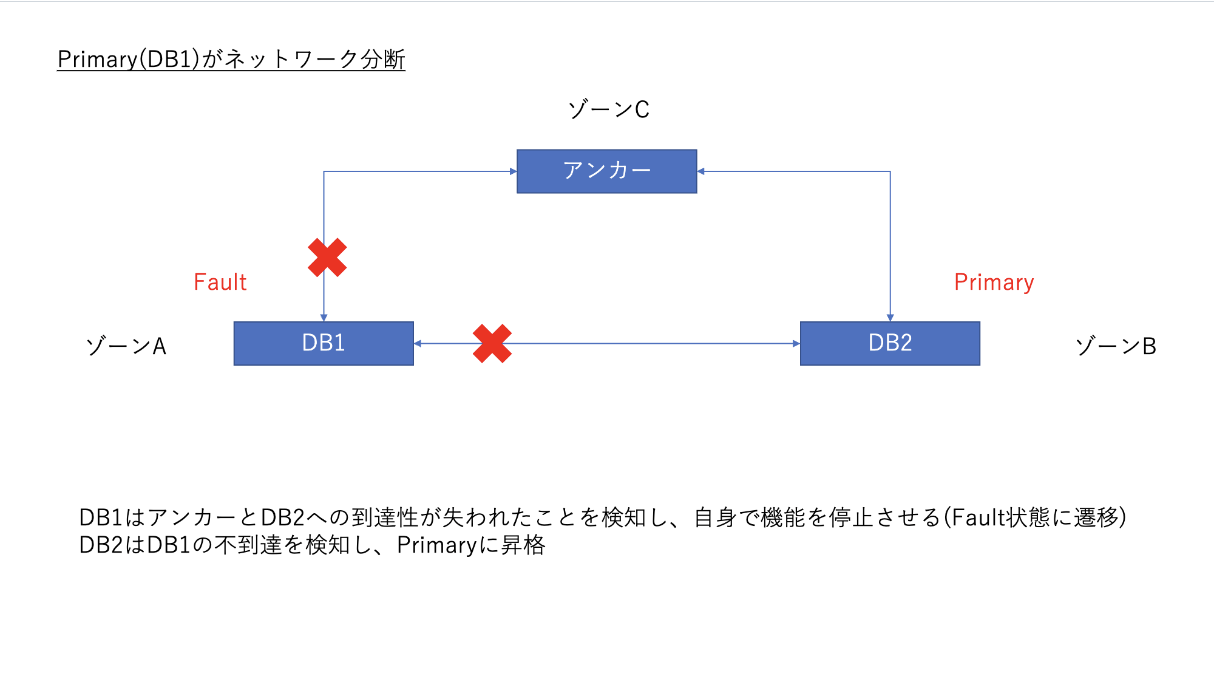
このとき、DB1では(BGPの仕様により)、ピアから広報されていた経路がすべて削除されます。これをdb-controllerで検知し、Faultに遷移します。これは、「自身のノードがネットワーク分断された」ことを検知するロジックです。
一方DB2では、DB1とのBGPセッションが維持されないことを確認しますが、アンカーとのセッションが維持できているため、DB1との間のネットワークに障害があるか、DB1がノード障害を起こしたかのどちらかであると判断します。そして、クラスタ内にPrimaryおよびCandidateがいないため、代わりにPrimaryに昇格します。これは、「相手のdbserverがネットワーク分断されている(かもしれない)」ことを検知するロジックです。
この2つの理由から、クラスタ内にアンカーを配置しつつ、db-controller間の情報共有がBGPで行われています。
運用
私達さくらインターネット SRE室は、Enabling SREsとして各サービスチームの信頼性を向上させ、お客様に価値を提供するまでをミッションとしています。MariaDB版エンハンスドデータベースプロジェクトについても、Enabling SREsとして行わなければならない活動は多岐にわたります。本記事では、その中の一部について、現状と方針、そして取り組んできたことを紹介します。
リリースまでの開発、運用は最低限の人数で行ってきましたが、今後の展望でお話しするように、運用に必要な知識や作業をドキュメント化およびコード化し、他の人が運用に参加できるような、非属人化された状態を作ろうと努めています。そのために私が取り組んでいる作業を2つほど紹介します。
プレイブック化による構築/テスト作業の自動化および自動的システムの検討
クラスタ構築作業は、一部シェルスクリプトやPerlスクリプトを利用しますが、ほとんどが手作業で行われています。また、クラスタ構築後に、正しく動作することを確認するテスト作業を行っていますが、これも同じく手作業で行われています。
それぞれの作業はドキュメント化されていましたが、Ansibleを利用することで作業を簡略化できることから、Ansible Playbookの導入を行いました。これによって、FRRouting等のバージョン管理もコードベースに行えるようになりました。
一方で運用の観点では、単に作業を自動化したスクリプトやツールを用意するだけでなく、障害に対して「自動的」に修復を試みたり、サーバ作成によって自動的にクラスタ構築が実行されるような世界の実現を検討しなくてはなりません。これはGoogle SREでも提唱されている重要な考え方です。
we want systems that are automatic, not just automated.
https://sre.google/sre-book/introduction/ より引用
Copyright © 2017 Google, Inc. Published by O'Reilly Media, Inc. Licensed under CC BY-NC-ND 4.0
以上のことから、必要な作業ではあったものの、Ansible Playbookを用意しただけでは不十分で、自動的システムを構築するために努力を続ける必要があります。自動的システムに対する取り組みについては、今後の展望をご覧ください。
Prometheus Exporterを組み込んだコントローラメトリクス
MariaDB版エンハンスドデータベースでは、クラスタのメトリクス管理にPrometheus、そしてアラート管理にAlertmanagerを利用していますが、オリジナル版(Perl版)db-controllerからGoにリプレイスした際に、コントローラの状態を公開するPrometheus Exporterを組み込むことにしました。これにより、プロトタイプでは行えていなかった「コントローラステートによるアラートの発火」が行えることになります。
ソフトウェアを実装したり、システムを構築する上で、オブザーバビリティを考慮した設計は非常に重要だと考えています。今回のリプレイスメントにおいても、実際にアラートルールに使用するかどうかが決定する前に組み込んでおいたものが、監視項目として採用される、というケースもありえます。
今後の展望
現在Labプロダクトとしてリリースされていますが、正式サービスとしてリリースするためには、よりシステムの信頼性を担保した開発/運用体制と文化の導入を行わなければなりません。このセクションでは、これからMariaDB版エンハンスドデータベースに必要だと考えている検討事項について紹介します。
クラスタの収容設計
現在はリリースされたばかりのプロダクトであり、想定されるお客様の数も少ないので、1つのクラスタにすべてのお客様のデータベースリソースを収容する設計となっています。しかし、今後少しずつお客様が増え、QPSが増加したり、ストレージが圧迫されることを想定して、クラスタのスケールについて考慮しなければなりません。
NewSQL実装のTiDBでは、それぞれのコンポーネントが独立してデプロイされ、かつそれぞれのコンポーネントが非常に高い水平スケーリング性を持っていますが、現在の設計では、MariaDBクラスタ一つに大量のトラフィックおよびデータベースリソースを収容することはできません。
これを解決するためには、リソースごとに収容するクラスタが分かれる、「データベースリソース単位で、クラスタのシャーディング」を行う必要があります。このアルゴリズムは、新規データベースリソースの作成ごとにAPIサーバ側で、様々な材料(CPUやストレージの使用率、ネットワークの帯域、プラン等々)をもとに収容先クラスタを決定します。
自動的システムの構築
現在は、クラスタ障害を発見した場合、Perlスクリプト等でシステムの各種状態を確認し、原因究明の後、手作業で対応する、という障害対応が想定されています。上述した「自動的システム」の考え方を導入するべく、これらシステムの状態がサーバへのSSHなしに確認でき、かつ、できるだけセルフヒーリングが行われるような状態を目指さなければなりません。
そのためには、システムの状態をどうアラート/チケット/ログに吐き出すかという適切な区別と、障害発生時に少しでも多くのことを学習すること(ポストモーテム文化の導入)、そして、過去の障害から、運用チームに通知せずに自動修復できる仕組みを実現するという、3つの非常に重要なプロセスを踏む必要があります。
現在は、これらの前段階として、システムのオブザーバビリティを深く検討する作業を行っています。上述した独自Prometheus Exporterの導入もそれに含まれます。
定期的な負荷試験の実施
現在はまだ構想段階にありますが、ステージング環境に対する定期的な負荷試験の実施を検討しています。これは、需要予測とキャパシティプランニングについて取り組む上で非常に重要な作業となっています。
まとめ
本記事では、さくらインターネットがエンハンスドデータベースプロジェクトをどう位置づけしていて、MariaDB版エンハンスドデータベースで何を実現したいのか、という点から、実際の設計や仕組みについて概観しました。
余談ですが、Enabling SREsとしてプロジェクトに貢献し、システムの信頼性をどう担保し、開発/運用体験からお客様の体験を向上させるまでを考えるのは、2022年に新卒入社してから初めての経験だったので、とても勉強になりました。
また、私はTiDB版エンハンスドデータベースプロジェクトにも参加しており、NewSQL実装とMariaDBの2つについて関わることができているのは非常に良い経験ができていると思います。
採用
さくらインターネット株式会社では、継続してエンジニア採用に力を入れています。ご興味のある方は、下記採用ページをご覧ください。
クラウド開発に興味のある方はもちろん、私の所属するSRE室はまだまだ設立されたばかりであり、やらなければならないこともたくさんあり、メンバー全員が責任を持ってエンジニアリングを行っています。0からSREチームを作り上げ、クラウドサービスにSREプラクティスを導入する仕事がしたい、という方をお待ちしております。