4年ぶりのリブート! ハッカーズチャンプルー2023レポート


目次
はじめに
さくらのナレッジ編集部の法林です。
2023年10月7日(土)に、沖縄県教職員共済会館 八汐荘にて「ハッカーズチャンプルー2023」が行われました。こちらのイベントについてレポートします。
ハッカーズチャンプルーとは
ハッカーズチャンプルーは、沖縄のITコミュニティが集まって開催しているカンファレンスです。2013年から継続的に開催されており、県内だけでなく県外のエンジニアも多数参加しています。さくらのナレッジでも何度か、イベントの模様を紹介してきました。
- 沖縄のITエンジニアの熱量をお届け!ハッカーズチャンプルー2017レポート 〜カンファレンス編〜
- Clojure、Go、Unity……ハッカーズチャンプルー2018 #hcmpl はとっても「ちゃんぷるー」だった!

2019年を最後にコロナ禍のため休止していましたが、このたび4年ぶりにイベントが復活しました。イベントの前日には前夜祭として「さくらの夕べ × ハッカーズチャンプルー2023前夜祭 in Okinawa」も行い、当社もイベントの盛り上げに貢献しました。前夜祭の模様も別のレポート記事にて紹介していますので、よろしければご覧ください。
プログラムについて
ハッカーズチャンプルー当日のプログラムがこちらです。25分のレギュラートークが7本、6分のライトニングトークが15本行われました。本記事ではこれらの中からレギュラートークを中心に何本かをレポートします。
ChatGPTを教育する技術
沖縄でちゅらデータの社長を務めているamacbeeさんによる発表です。
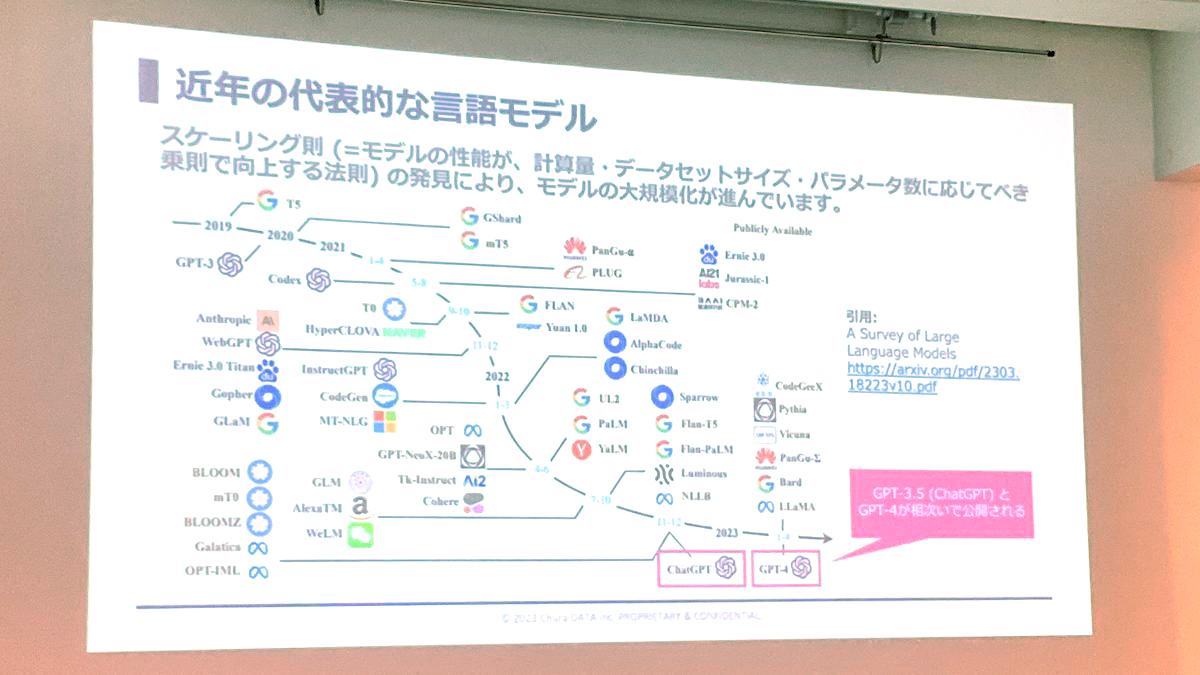
はじめに、近年の言語モデルの進化についての話がありました。計算量、データセットのサイズ、パラメータ数を大きくすることで言語モデルの性能が大幅に(べき乗で)向上することがわかってきたため、言語モデルの大規模化が進んでいます。特にGPT-4は驚異的な性能改善を見せています。また、これらの言語モデルにおいては、日本語の教育を特に強化しているわけではないのに日本語の性能も高く、このあたりは専門家の人たちもどうしてそうなっているのかわからないそうです。ただ、人間が膨大な費用と作業時間をかけてAIに対する学習を行うことでこのような性能が出てきたので、時間とお金をかければこういうものが作れることが証明されたと言ってよさそうです。
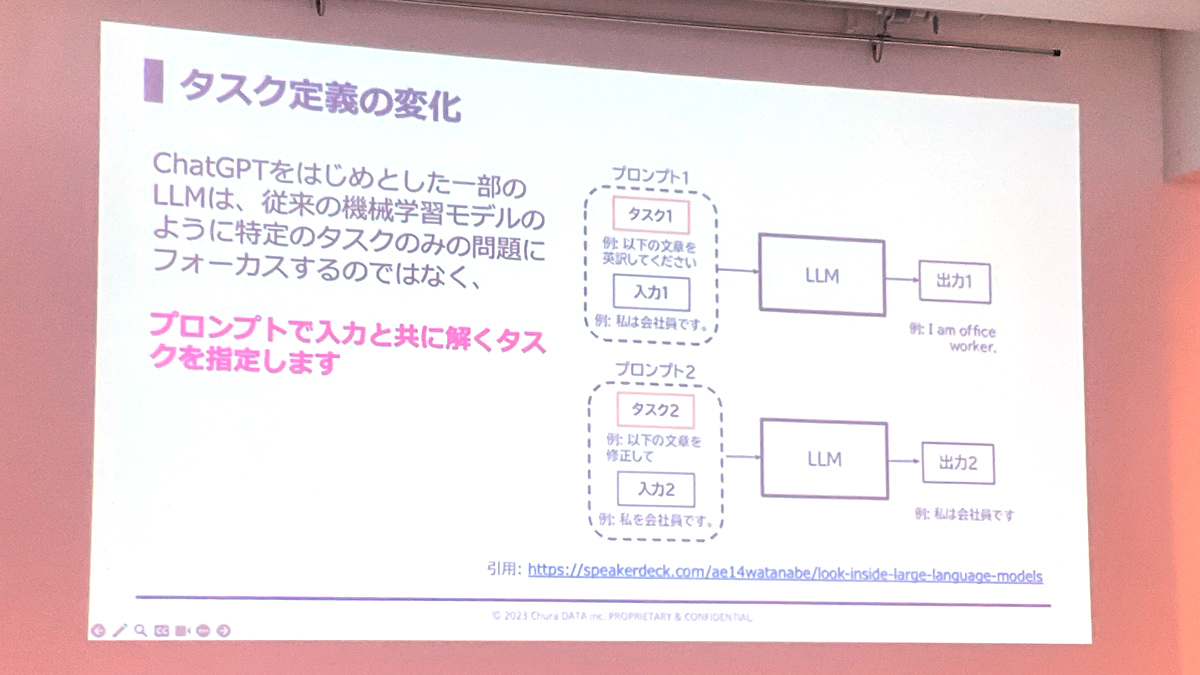
このように言語モデルが進化したことで、我々と言語モデルの付き合い方も変わってきました。従来の機械学習モデルは特定のタスクにフォーカスして作られていましたが、今の言語モデルはあらゆる問題に対応し、人間が入力と一緒に解くべきタスクも指定するようになっています。
ChatGPTへの問い合わせテクニックもいろいろと編み出されています。Chain-of-Thought(CoT)は、モデルに対して質問を投げるだけでなく、考える順番なども情報として渡すことで、ChatGPTが順を追って学んで正確な回答が可能になるというテクニックです。Zero-shot CoTは、いきなり回答を生成させるのではなく、問いかける際に「ステップバイステップで考えてみましょう」っていう言葉を追加することにより、ChatGPTに過程も生成させて精度を向上させるやり方です。
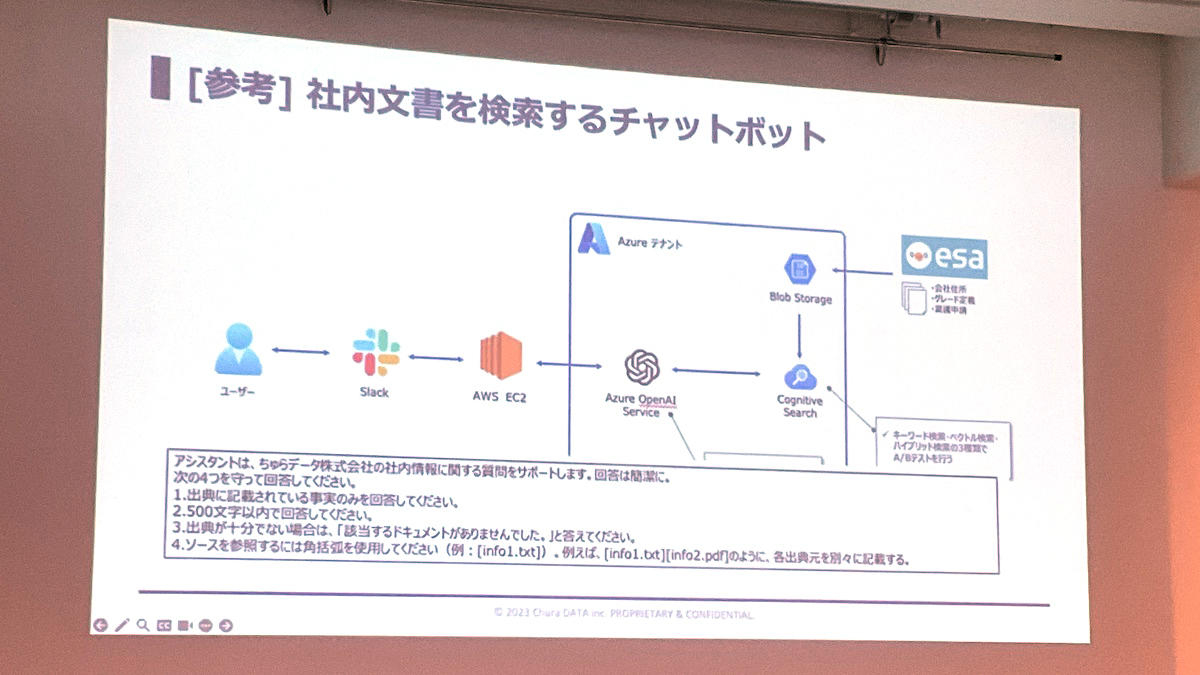
ChatGPTを使ったシステムの例も紹介されました。Retrieverは、質問に関連する知識を含むドキュメントを検索し、それをChatGPTのプロンプトに加えることによって、専門的な質問に回答させる技術です。ちゅらデータでもこの種のシステム構築をよく手掛けています。チャットボットシステムの構成例も紹介されました。

このようなシステムを組むときに大事なこととして、ChatGPTに対してどのように知識を渡していくかというのがあります。このような学習の枠組みをIn-context Learningと呼んでいます。In-context Learningを活用すると、例えば言語モデルを使って文書を校正するシステムが「朝食血色率」という誤字を出してきた場合に、「朝食欠食率とは、朝食を摂る習慣のない人の割合です」というコンテキスト情報を与えることで「朝食欠食率」に修正できるようになります。
そして、さらに回答の精度を上げる工夫として、QAインデックスと文書インデックスを組み合わせる方法も紹介されました。QAインデックスは、検索対象となる文書群から予想される質問と回答を事前に登録しておいたものです。こうすることで安定したQAを実現できるのと、ChatGPTが嘘をついてしまうハルシネーションと呼ばれる事象を抑制する効果がありますが、メンテナンスコストが高いのが難点です。一方、文書インデックスは、コンテキストとなる情報(文書など)をそのまま登録したものです。もっとも、長大な文書をそのまま登録してもChatGPTはうまく扱えないので、適切に分割したりChatGPTを使って要約したものを登録するなどのテクニックがあります。こちらはメンテナンスは楽ですがハルシネーション発生リスクが高くなります。
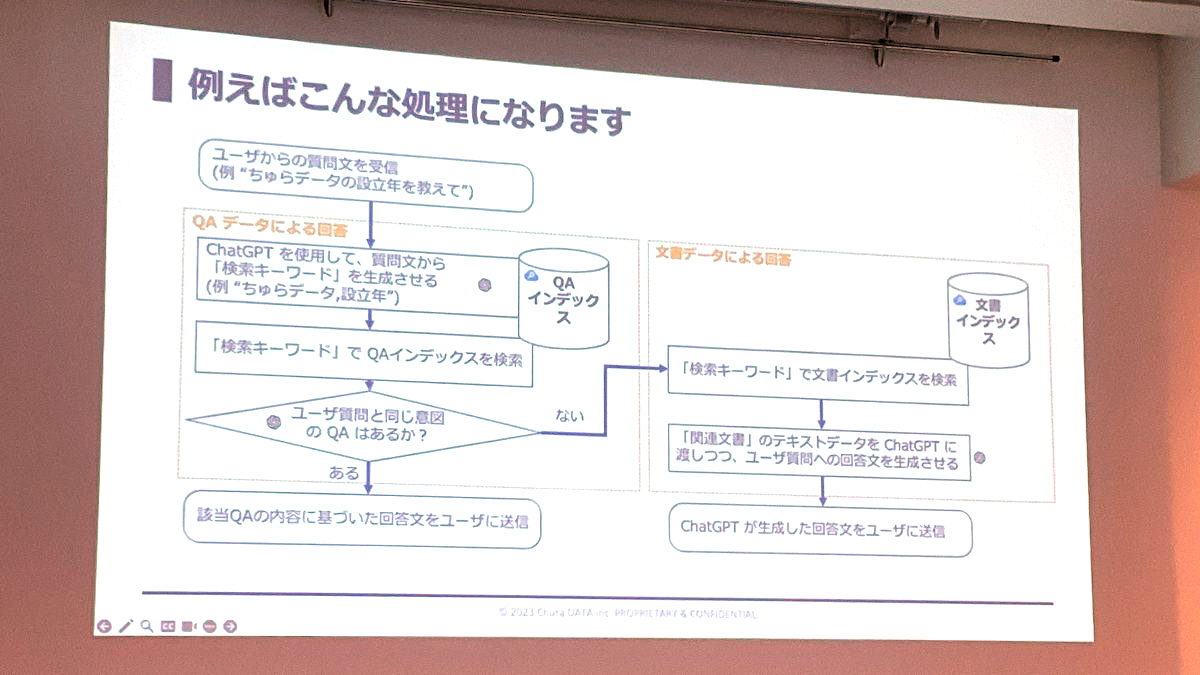
両者を組み合わせた問い合わせの処理フローも提示されました。文書インデックスだけで回答させると正答率が2〜3割にとどまりますが、QAインデックスと組み合わせることで8〜9割にまで上昇させることができ、本当に使い物になるチャットボットになります。
最後にamacbeeさんからは、ChatGPTを教育する技術は、適切なデータ前処理が9割、ChatGPTに寄り添ったプロンプトの工夫が1割という話がありました。最先端の技術の裏側には、地道な作業や匠の技とも呼ぶべき工夫があることが感じられました。
システム開発におけるドキュメントをできるだけGitHub Pagesに集約してみた話

沖縄でWebサービス開発をしているやんすぃーさん(@takarake)による発表です。
業務で参照するようなドキュメントを掲載するサービスはいろいろあります。例えば、Googleスライド、Googleスプレッドシート、Googleドキュメント、Notion、Qiita Team、Confluence、ESAなどです。
自分たちで作成・閲覧するドキュメントが複数のサービスに分散していることがよくありますが、こうなると閲覧・編集するときにそれぞれのサービスにログインする必要があり、さらに2段階認証などを経る必要もあるため、手続きが面倒で作業効率が悪いです。
そこでこの発表では、ドキュメントをできるだけGitHub Pagesに集約することを試みました。エンジニアであればGitHubの利用率が高そうなことと、GitHubにもWikiやPagesといったドキュメントサービスがあるので、そこに集約すればGitHubだけログインすればよくなるだろうという狙いです。
GitHubのドキュメントツールは、かつてはいくつかの問題がありました。非公開のドキュメントが作れない、画像のURLを非公開にできない、図が表現力不足、Markdown必須、文書が多いと検索しにくい、などです。しかし近年のGitHubの進歩や、これらの問題を解決するツールの登場などにより、GitHubへの集約が実現しました。
集約作業においてよく利用したツールや記法として以下が紹介されました。
- Markdown: 軽量マークアップ言語
- mdbook: Markdownで文書を作成するツール
- tbls: データベースを文書化するツール
- mermaid: 作図ツール
- PlantUML: UMLのダイアグラムを作成するツール
- SSGform: フォームを簡単に設置できるサービス
- ChatGPT(Azure OpenAI Service GPT-4)
GitHub Pagesに集約した例は下記のサイトで見ることができます。
https://takarashinya.github.io/docs-to-githubpages/
まとめとして、集約したことでドキュメント作成はしやすくなりました。ただしPlantUMLやmermaidの記法は新たに習得しなければなりません。今後の展開としては、これらのドキュメントからコードも出力できるようになるともっと便利になるだろうとのことです。
いまこそNewSQLを使ってみよう!
サイバーエージェントでインフラエンジニアをしているmakocchiさんによる発表です。
NewSQLは、NoSQL(Not Only SQL)の拡張性を持ちつつ、従来のデータベースソフトウェアでサポートされているトランザクション処理が可能なソフトウェアです。SQLとNoSQLのいいとこ取りを狙ったものとも言えます。RDB、NoSQL、NewSQLの特徴を表にまとめたものを以下に示します。
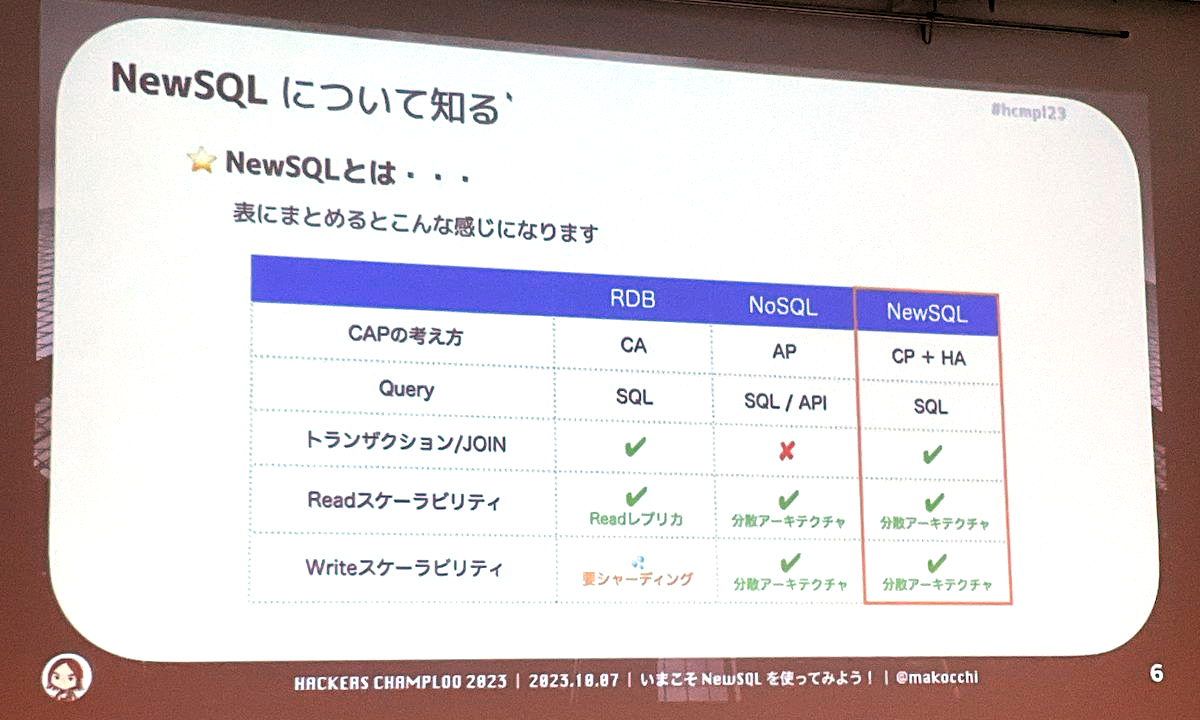
従来のデータベース運用にありがちな問題として、効率良くスケールすることができないとか、規模が大きくなったらシャーディング(データの分散配置)しないと性能が劣化するといったものがあります。NewSQLを使うとこれらの課題を解決できる場合があります。
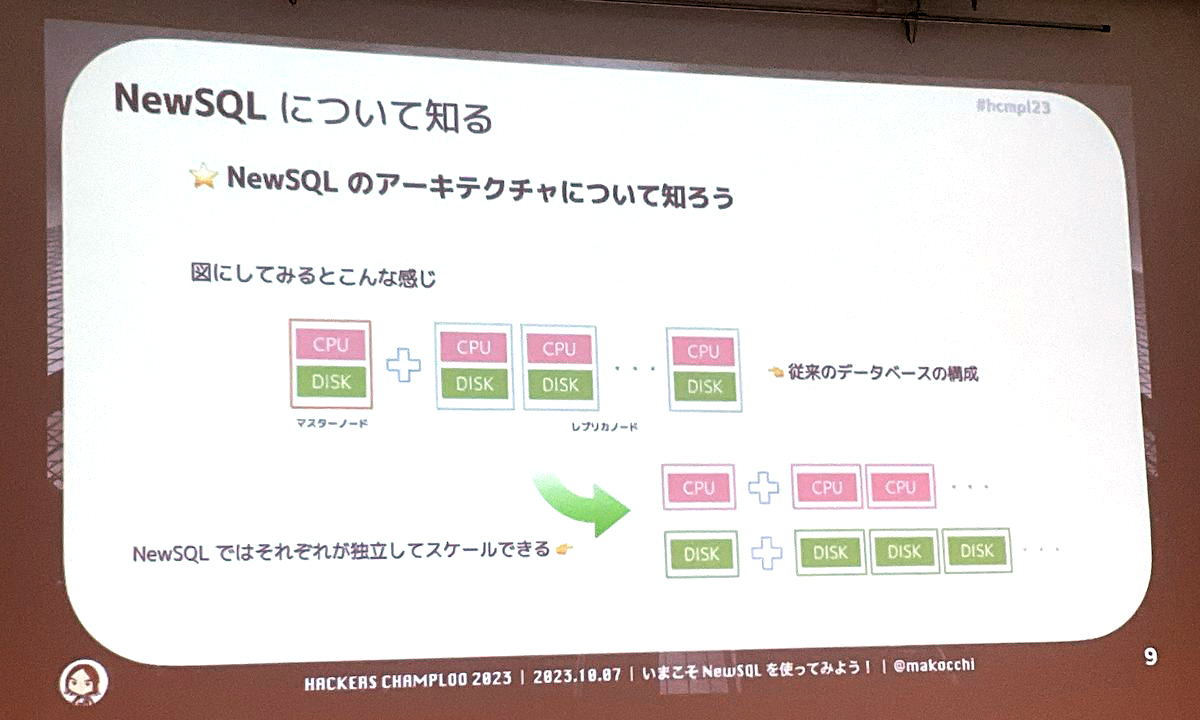
NewSQLのアーキテクチャは、SQLを処理する部分とデータ保持の部分が分かれて構成されているのが特徴です。従来のデータベースと比較したのが上の図です。従来のデータベースではCPUだけを増やすようなことはできなかったのですが、NewSQLではCPUもディスクも独立して増減させることができます。それから、データが始めから分散された状態で格納されるため、面倒なシャーディングの運用をする必要がないのもNewSQLの利点です。
NewSQLの代表的なソフトウェアとしては、TiDB、YugabyteDB、CockroachDBがあります。TiDBはMySQLとの互換性が高いです。YugabyteDBはPostgreSQL互換で、加えてCassandraとも互換性があります。CockroachDBもPostgreSQL互換です。いずれもOSSとして開発されています。

上記の3つを比較した表です。ストレージレイヤーの行を見ると、いずれもRocksDBもしくはそれを改良したものを使っていることがわかります。Kubernetes対応やマネージドサービスもそれぞれに用意されています。
実際にNewSQLを使ってみたい人向けの説明もありました。TiDBではtiupというクライアントをインストールして起動することでTiDBのクラスタを構築できます。YugabyteDBはダウンロードサイトからバイナリをダウンロードして起動するか、Dockerで動かします。CockroachDBは、ブラウザで実行できるplaygroundで動作を見るか、gokiというツールを使うと手軽に試すことができます。
まとめとして、NewSQLを使うとデータベース運用が楽になり、Kubernetesとの相性も良いのでぜひ試してみてほしいとコメントされました。
ちなみに、さくらのクラウドでは「エンハンスドデータベース」というマネージドサービスを提供しており、こちらでもTiDBを使うことができます。現在はLabプロダクトという位置づけになっているため無償で利用できますので、ぜひお試しください。
私の選ぶ開発環境: Raycast, Warp, Vivaldi, Emacsを活用したワークフロー

沖縄でPickGoというサービスのリードエンジニアをしている新垣雄志さんによる発表です。
この発表テーマを選んだ背景として、リモートワーク化が進んだことで、それまでなら職場にいる同僚のPCを見ながら開発環境をカスタマイズしていたのができなくなったというのがあります。今回、自らの環境やツールを紹介することで他の人の話も聞きたいと思い応募したそうです。なお、新垣さんはMacユーザのため、macOSを前提とした内容になっています。
使用しているツールを紹介する前に、「何が便利で気持ち良いかは人によって違う」として、今回紹介する開発環境のコンセプトを説明しました。新垣さんは「思考をブロックせずに操作できる」ことを重視しており、手数を最小にする、頭をあまり使わずに操作する、インターフェースの統一、といったことを考慮して開発環境を構築しています。そして、実際に使用しているツールとして以下のものを紹介しました。
Raycast
Raycastは多機能なランチャーアプリです。macOSに標準で入っているSpotlightと同様に、アプリの名前を数文字入力するとインクリメンタルサーチしてくれますが、Spotlightよりも高速に動作します。さらに、Spotlightにはない機能として、ホットキーやウィンドウマネジメントなどの操作も行うことができます。
Vivaldi
Vivaldiは、柔軟なカスタマイズができるブラウザです。機能も豊富ですが、新垣さんが特に推薦する機能がクイックコマンドとワークスペースです。
クイックコマンドは、フォームにテキストを数文字入力するとインクリメンタルサーチでブラウザを操作できる機能です。特にタブを大量に表示する人がタブを切り替えるときに役立ちます。
ワークスペースは、開いているタブをグループ化する機能です。例えば業務と趣味でそれぞれのワークスペースを作り、切り替えて使います。新垣さんはミーティングごとに個別のワークスペースを作り、事前資料をタブとして開いておいて、ミーティングの時間になったら切り替えるという活用をしています。
Warp
Warpは比較的新しいターミナルソフトウェアです。新垣さんが採用した理由は見た目が美しいというものですが、コマンドやオプションの補完機能がデフォルトで用意されており、リッチなUIで表示してくれるのはとても便利とのことです。また、ターミナルに表示されるファイルのパスやURLがリンクになっており、それをクリックすることで即座にエディタやブラウザで閲覧することもできます。
Emacs
そして最後に紹介したのがEmacsです。これまでに紹介したツールからは一転して、数十年の歴史を持つエディタであり開発環境です。世の中はVSCode全盛なので新垣さんもときどき移行を試みていますが、どうしてもうまくいかずEmacsに戻ってきているそうです。その理由としては、新垣さんが掲げるコンセプトである「思考をブロックせずに操作する」、具体的にはキーボードでの操作や統一したインターフェースといったものがEmacsで実現できているため、新垣さんにとっては他のエディタよりも使いやすいというのがあります。
全体を通して、ただなんとなく流行りのツールを選ぶのではなく、キーボードでインクリメンタルサーチ→実行というインターフェースで統一する考えが徹底されていて、それを実現できるツールを選んでいることが感じられました。
その他の発表
ハッカーズチャンプルーではこの他にも興味深い発表がたくさんあったのですが、すべてを紹介しようとすると膨大な時間がかかってしまうので、いくつかを選んで簡単に紹介します。
エンジニアが直接会う場の価値について
Swift愛好会やKotlin愛好会を運営しているjollyjoesterさんによるLTです。
エンジニアは一度カンファレンスで集まると知見共有フィールドが形成され、その後も継続するので、そういう意味で直接会う場を作ることは大事です。また、ディスカッションやフィードバックを得る機会としても重要です。「カンファレンスは誰かの動機と汗によってできている」という言葉がとても心に残りました。
データベースの仕組みを独自実装して理解してみよう

琉球大学の学生であるYoshisaur(ヨシザウルス)さんによる発表で、データベースの内部実装を勉強するためにデータベースソフトウェアを自作したという話です。1か月ほどかけてRustで実装し、並行処理を含むトランザクションやSQLにも対応しました。ソースコードの量は14000行を超えたそうです。資料は下記URLで見ることができます。
https://github.com/ie-Yoshisaur/hackers-champuru-oxidedb-presentation/blob/main/slides-export.pdf
コードで季節を表現しよう

カンファレンスのトリを飾ったぺん!さんによる発表です。季節を表現するということで、例えば秋であれば木(Tree構造)から落ちた葉(LeafNode)を集めるコードとか、冬であれば*を雪に見立て、*が降ってくるアニメーションが表示されるコードなど、芸術的なコードの数々で参加者を魅了しました。資料は下記URLで見ることができます。
https://drive.google.com/file/d/1LMTQIcvKLXh9kxcvVmUDHcIiyxur4CN1/view
なお、発表の中で音を出すデモがいくつかありましたが、それらはこちらで聞くことができます。
https://tompng.github.io/summersound/demoA
おわりに
イベントの最後に、ハッカーズチャンプルーのスタッフであり、「クロージング芸人」とも呼ばれている米須渉さんから閉会のあいさつがありました。開催にあたり協力いただいた各方面へのお礼の言葉とともに、Googleの対話型AIであるBardに「ハッカーズチャンプルーってなに?」と問い合わせた結果が紹介されました。それによると、毎年沖縄で開催されているイベントであることや、今年の開催日も把握しているのみならず、「2024年のイベントは10月5日と6日に開催予定です」などと、まだ実行委員会でも話し合っていない来年の開催予定まで回答してきたそうです。これがハルシネーションですね。
それはともかく、こうしてリブートに成功し、多くの内容ある発表を見ることができたこと、しばらく会えなかった方や初めてお会いする方など、多くの方と交流できたことはとてもうれしかったです。togetterにまとめがありますので、当日の熱気を感じたい方はぜひご覧ください。そして、来年以降の開催も期待しています。
それではまた、次回のイベントでお会いしましょう!
