分散処理環境で原価計算屋の夢を実現!「第26回さくらの夕べin東京」レポート


初めてさくナレに記事を書くことになりました法林です。今年の5月からさくらインターネットに常駐していて、技術広報、コミュニティ支援、イベント運営などを担当しています。
さて、当社のイベントと言えば「さくらの夕べ」を思い出される方も多いでしょう。今回は9月28日(月)に東京は新宿にて開催した「第26回 さくらの夕べ in東京 ~さくらで作る大規模分散処理環境~」の模様をお伝えします。久しぶりの東京開催にもかかわらず、今回も約100名の参加登録をいただきました。ありがとうございます!
なぜ分散処理環境と原価計算システムを作ったの?
今回の夕べでご紹介したのは、当社がノーチラス・テクノロジーズ様と共同で構築した分散処理環境と、その上に実装したデータセンターの原価計算システムです。はじめに、なぜこのようなものを構築したのかを、当社代表の田中より説明いたしました。
もともと当社ではHadoopなどの分散処理システムを用いたサービスを検討していました。またその一方で、サービスの原価管理の精度が課題のひとつでした。
これに対して、ノーチラス社では分散処理のミドルウェアを開発しており、さらに原価計算システムの構築実績もあったので、それならさくらの原価計算システムをノーチラスの分散処理技術で作ろうという話になりました。そして、原価計算の高精度化・即時化・自動化、原価計算の基礎となる社内データの整備、分散処理環境の構築・運用ノウハウの獲得といった目標を掲げ、プロジェクトがスタートしました。
担当者が語るシステム構築の舞台裏
続いて、実際に構築したシステムについて、当社側の担当者であるクラウド開発室の須藤が説明いたしました。
プロジェクトがスタートしたのは2013年11月です。フェーズ1では石狩リージョンの専用サーバに的を絞り、要件定義やモデル定義などから作業に取りかかりました。最初の原価計算バッチが完成したのは約半年後です。続いて2015年3月までのフェーズ2ではさくらのクラウドや石狩リージョンのVPSも対象とし、現在進行中のフェーズ3では他拠点・全サービスを対象に作業を進めています。
システム構成は、データ収集部とデータ処理部に大別されます。データ収集部では、コストを構成する情報を社内から集めます。ネットワークやサーバのログ、契約情報や会員情報など運用系のデータ、固定資産台帳や各種請求情報など経理財務系のデータ、土地や建物や電力などファシリティ系のデータなど、全部で約60種類あります。データ処理部ではコスト構造を表すツリーモデルを作成し、それに基いて原価計算バッチを作成します。モデル化とバッチ作成には、ノーチラス社が開発しているAsakusa Frameworkという分散処理フレームワークが活躍しています。
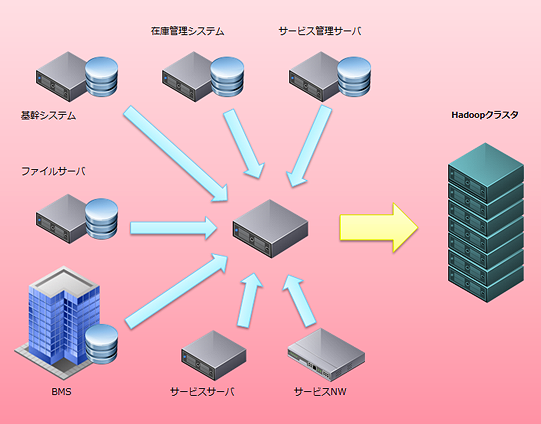

データ量は1日500GB以上あり、対象サービスの拡大に伴ってさらに増加中ですが、このデータの収集がなかなか大変なようです。サーバのログなど機械的に収集・整形できるものはよいのですが、各種伝票や台帳の類は電子データとして利用されることを想定していないため、システムに取り込むにはデータの正常化など多くの労力が必要でした。また、このような大量のデータを複雑かつ長いバッチで処理するとなるとRDBではうまく動いてくれません。この点はHadoopやAsakusa Frameworkを選択したことが大きくプラスに作用しました。
こうして作られた本システムですが、主な成果としては、データセンターやサービスごとのコストと利益がわかる月次レポートが出力されるようになったこと、開発過程でデータ整備の重要性が認識され、改善の動きが出てきたこと、より確かな原価企画を立案する基礎データが提供されたことの3点が挙げられます。
ノーチラス社・神林社長からもぶっちゃけ話が続出!
続いて神林社長からもプロジェクトの裏話が紹介されました。プロジェクトメンバーは当社2名、ノーチラス社6名という少数精鋭でしたが、要所で当社の全面的協力が得られたことが成功の要因とのことです。データ処理部の構造は、前処理をHadoop、計算処理をSparkで行い、最終結果はExcelに出力されます。
HadoopとSparkを比較すると圧倒的にSparkの方が優秀で、神林さんいわく「木製バットと金属バットぐらい違う」そうです。ただしSparkはオプションが多すぎて初心者には使いこなせないので、詳しい人にサポートしてもらいながら使うことを勧めていました。

開発手法は基本的にウォーターフォールで、半年単位でフェーズ分けして開発が進められました。プロトタイプはノーチラス社で作成し、それをベースに初期開発に入りましたが、コストツリーのモデル化は当社側で行いました。これは神林さんからも当社が頑張ったというお褒めの言葉をいただきました。一方、開発も中期に入ると毎週のように仕様変更や新サービスへの対応が入ってきます。特に、Hadoopでは性能が足りないのでSparkに変更したのですが、すでにかなり作り込んでいたので単純な置き換えができず、Asakusa FrameworkのコンパイラをSpark用に書き換えることで対処しました。技術力の高いノーチラス社ならではの荒技に驚嘆しました。
パネルディスカッション

後半は、登壇者3人によるパネルディスカッションを行いました。最初に「このプロジェクトは何がすごいのか」という話題が提示されたのですが、これに対する神林さんからの「このプロジェクトは原価計算屋の夢を達成している」というコメントが印象に残りました。従来、原価計算においては間接費(各製品に共通でかかる費用)を無視していたのですが、当社のように間接費がコストの大半を占める業態でそれをやると正しい原価計算ができません。そこでActivity Based Costing(ABC)と呼ばれる手法を用いて間接費を管理し原価を計算するのですが、これを正確に算出するのは非常に困難です。その主な理由は十分なデータが取れないこと、計算が終わらないことの2点にありますが、今回のプロジェクトではこれらの壁をクリアして原価の算出に成功しており、原価計算の分野では画期的な成果と言えるそうです。
一方、キレイごとばかりでも・・・ということで、このプロジェクトで至らなかった点は?という質問がありました。これに対して、須藤からは「原価計算の元データを提供するシステムに古いものが多く(例えばビル管理システムなど)、データが取れないとか精度が悪いケースがあったことが残念」というコメントがありました。また、神林さんからは、ネットワーク系の情報が取れないことに対する厳しい意見が出ました。構成図も自動で作れないし、物理結線も自動で取れない、ベンダー間の互換性もないという非常に残念な状況であり、これはネットワーク業界全体の課題として認識すべきだというコメントは考えさせられるものがありました。
セミナーの最後に、実際の原価計算結果のグラフ を見せていただきました。顧客ごとの収支にとても大きなバラつきがあることが素人目にもわかるもので、「えっ?ここまで詳細に出てくるの?」と、とても驚かされました。
懇親会とLT
セミナー終了後は別室にて懇親会を行いました。短い時間ではありましたが、登壇者と参加者、それからスタッフも交えて、和やかな歓談がなされました。

LTの様子
さらに、さくらの夕べの懇親会ではライトニングトークを実施しています。今回は以下の3件の発表がありました。
・当社プラットフォーム事業部・吉田:さくらでのはじめてのデータセンター作業
・OSS貢献者賞実行委員会・小山さん:OSS貢献者賞への推薦のお願い
・当社プラットフォーム事業部・江草:自動化可能なオペレーション


小山さんからお話のあったOSS貢献者賞は、オープンソースの開発や普及に顕著な貢献をされた方を表彰するものです(僭越ながら私も2012年に受賞しました。とても感激しました)。この記事が掲載される頃には受賞者が発表されているでしょう。ぜひチェックしてください。


おわりに
今回のさくらの夕べは、分散処理環境や業務システムの構築といった、今までこのイベントではあまり取り上げたことのないテーマにチャレンジしました。そのため、ユーザの皆さんに関心を持っていただけるかどうか不安もありましたが、フタを開けてみると常連さんもさることながら初参加の方が多く、参加者層の拡大につながったようでうれしかったです。
さくらの夕べは今後も各地で開催していく予定です。開催の折は当社のWebサイトや広報のTwitterアカウント(@sakura_pr)などでアナウンスいたしますので、そちらをフォローしていただければ幸いです。またお会いしましょう!


以上、法林によるさくらの夕べレポートでした!