生成AI向け機械学習クラスタ構築のレシピ 北海道石狩編

こんにちは。さくらのナレッジ編集部の安永です。
2024年6月15日(土)、札幌コンベンションセンターにて「CloudNative Days Summer 2024 」が開催されました。このイベントで、株式会社Preferred Networks(以下「PFN」と称します)の清水翔さんと上野裕一郎さんが、さくらインターネットのサービスを利用した生成AI向け機械学習クラスタ構築の方法について発表しました。そのレポートをお届けします。

生成AIの学習とは

最初に、生成AIの学習とは何かについて説明します。生成AIの学習では、非常に大規模なパラメータを持つ言語モデル(LLM)を使用します。PFNや株式会社Preferred Elements(以下「PFE」と称します)では、「PLaMo」という大規模言語モデルを開発しています。例えば、100億のパラメータを持つモデルの場合、メモリ使用量はパラメータとパラメータ更新時のOptimizerの内部状態(12Byte/デバイス)も含めると、約120GB(10G x 12byte)になります。たとえ最新の GPU に搭載されているVRAMでも、保存できるパラメータ量には限りがあり、1 GPU でこれらをすべて扱うことはできません。そのため、単一のデバイスで処理するのは難しく、パラメータを複数のデバイスに分散して学習させます。
今後さらに大きなモデルの学習を行うためには、より大きな計算量・要求メモリを必要なときに利用できる大規模な計算資源が求められます。
生成AI向け機械学習クラスタとは?
開発する機械学習クラスタの要件

その大規模な計算資源を提供するために、さくらインターネットの石狩DCに構築した機械学習クラスタについて紹介します。今回開発する機械学習クラスタには、以下の要件があります。
- 迅速にクラスタを構築する
- 大規模な言語モデルの学習には数ヶ月単位の時間がかかるため、できるだけ早くクラスタを 構築して、言語モデルの開発を始めたい。
- 潤沢な最新GPUの確保
- 大規模な言語モデルの学習には、多数の高速なNVIDIA GPUが欠かせません。また、GPU 同士の高速な通信(Remote Direct Memory Acces)が求められる。
- 十分なストレージ
- 言語モデル学習に耐障害性をもたせるため、高速で安定したストレージが必要。
- 使いやすい基盤
- 既存の PFN で運用している Kubernetes クラスタと同じような使い勝手が求められる。
- 複数ユーザで共有したい
- 複数のプロジェクトで、限りある資源を最適に配分しつつ共同利用したい。
- 運用効率の向上
- 特に1台ごとの運用コストをできるだけ下げて、大規模クラスタの運用を容易にすることが必須。

これらの要件を満たすため、さくらインターネットの高火力PHYという生成AI学習に向いたベアメタルサービスを使ってクラスタを構築することになりました。利用可能な最新世代のGPU(2024年6月現在)であるNVIDIA H100 Tensor コア GPUを8基搭載したサーバをベアメタルとして提供しているサービスです。これにより、低オーバーヘッドでクラスタを構築することができます。生成AI向けの学習では、ネットワークが高速である必要があります。それに対して、最大200Gbps x 4の高速なインターコネクトネットワークが提供されています。

機械学習クラスタの要件と利用サービスが決まり、上図のような大きな規模感のクラスタを構築する方針となりました。
設計の大方針
今回のクラスタ構築プロジェクトは、主に3名のメンバーが他の業務を抱えながら取り組みました。全員がさくらインターネットのサービスについての知識はほとんどないため、サービスの理解とクラスタ設計を並行して進める必要がありました。また、GPUは高価で貴重なリソースであるため、サーバが利用可能になったら即クラスタを完成させることが求められました。
このような背景から、構築スケジュールは段階的なサーバ増設をもとに設定しました。
第1弾は、本番環境のスムーズな立ち上げをサポートするための準備期間としました。具体的には、一部のサーバが利用可能になると同時に、設計の進行と検証のためのクラスタ構築を行いました。また、将来の本番運用で必要な自動化のためのクラスタAPIの設計と実装を進めました。
第2弾は、第1弾から3〜4ヶ月後に、多数のサーバを追加して本番環境として完成させました。第1弾で準備した設計・検証クラスタおよび自動化のためのAPIが本番環境に統合され、システムの運用が開始されます。
デザイン空間
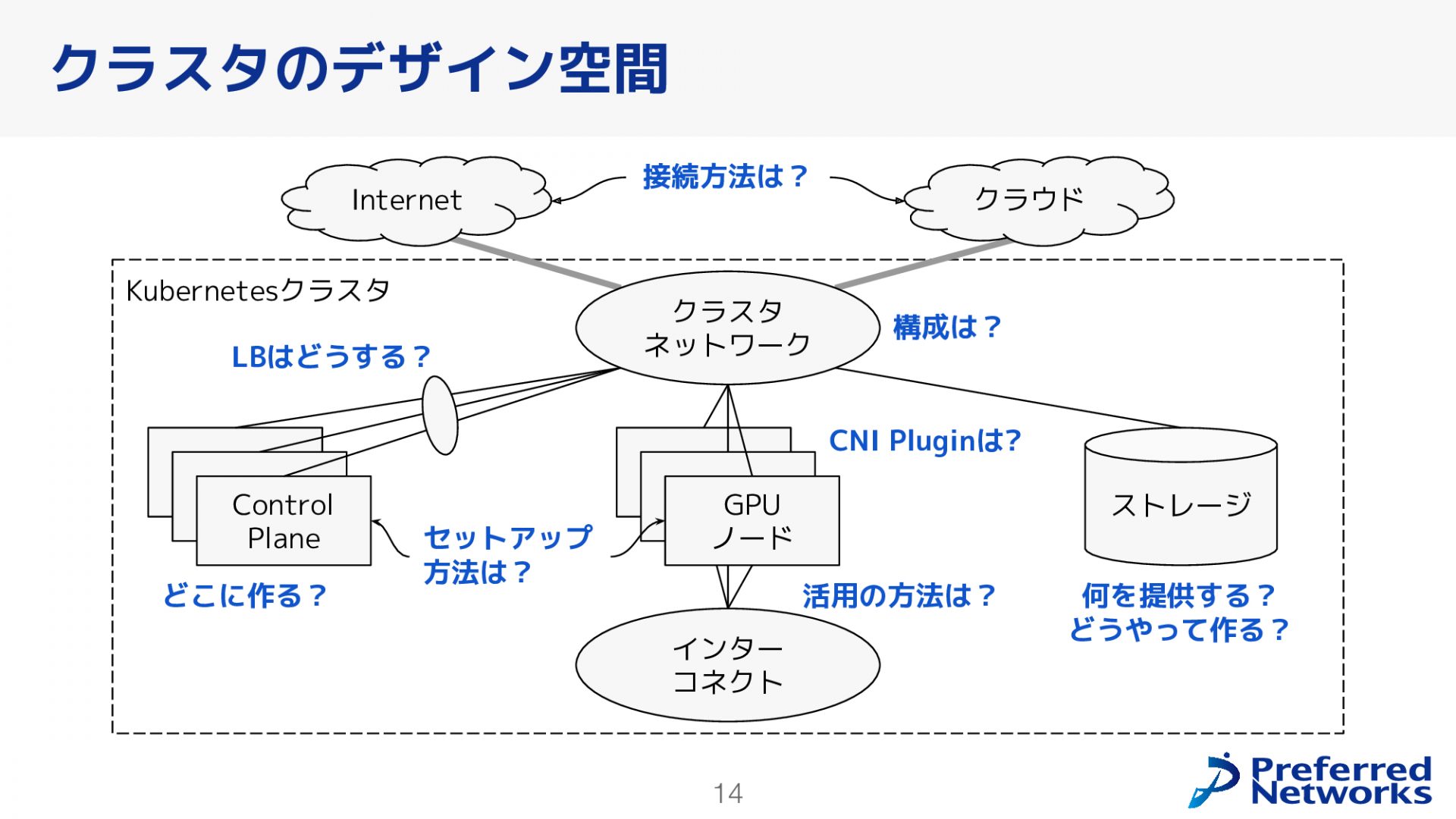
クラスタを構築するにあたって考えなければならないことを、上図を使って説明します。GPUノードをKubernetesクラスタに組む際には、以下の点について考える必要があります
- サーバ構成
- Control Planeをどこに配置するか
- ネットワーク構成
- 様々なネットワークをどのように構成するか
- クラスタ構築方法
- Kubernetesクラスタをどのようにセットアップするか
- ストレージ構成
- 機械学習で使用する大量のデータを格納するストレージをどのように構成するか
これらの点は、クラスタを作る際に慎重に考慮しなければなりません。
構築レシピ
各構成について、検討内容を説明します。
サーバ構成
KubernetesのControl Planeや管理ノードなど、Kubernetesを運用するに当たって必要なコンポーネントをデプロイする先のノードの構成について検討しました。検討にあたり、さくらインターネットのサービスについて簡単に説明します。さくらインターネットのサービスは、ベアメタルを提供する高火力PHYと通常のCPUサーバを提供するさくらの専用サーバPHYと、IaaSのVMを提供するさくらのクラウドに大別できます。これらの二つのサービスは、連携可能ですが別のサービスとなります。
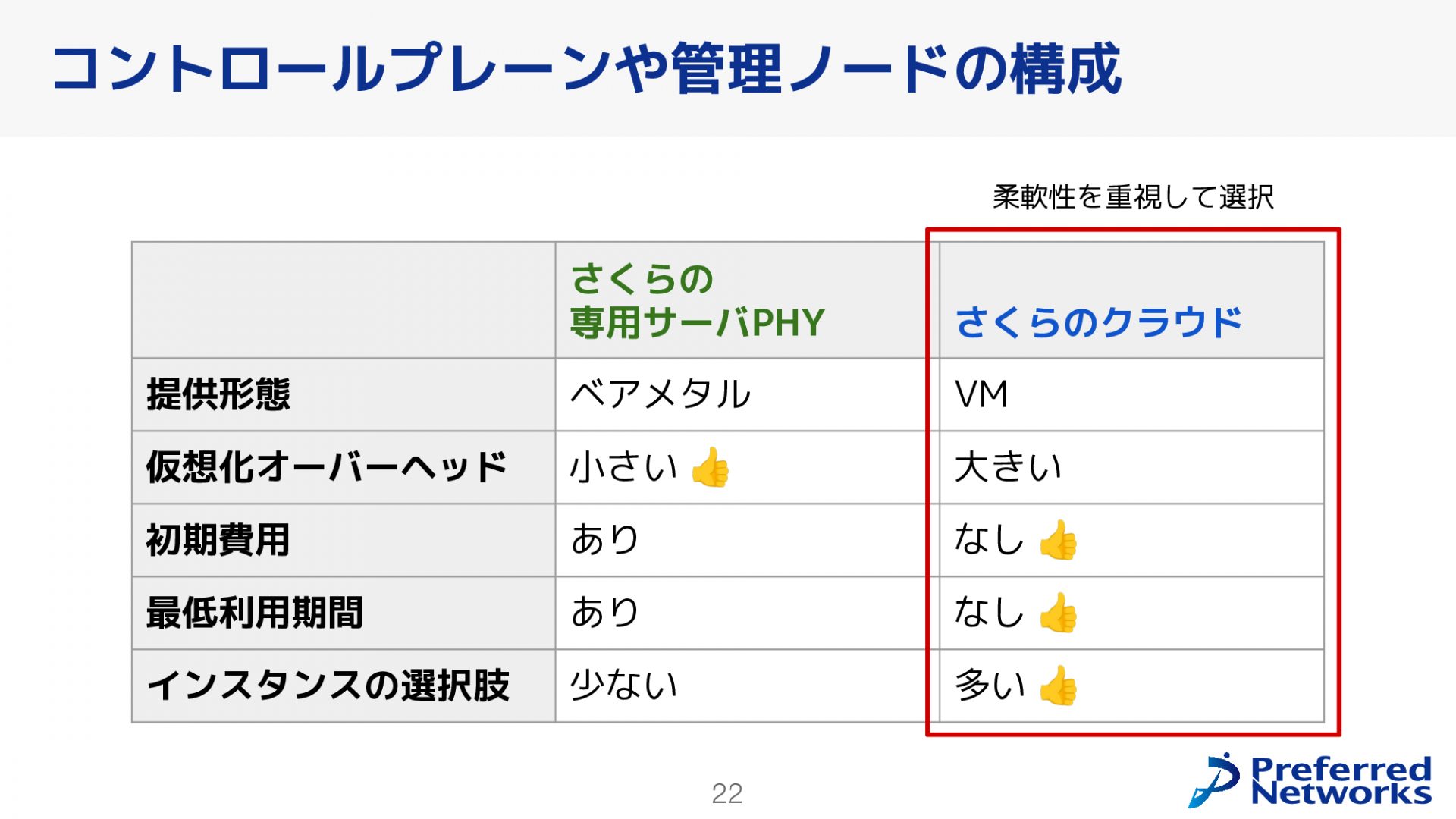
ノード構成の検討は、さくらの専用サーバPHYとさくらのクラウドを比較して実施しました。検証用クラスタ作成段階では、さまざまなノードを作成する必要性、Control Planeや管理ノードのスペックや台数変更への柔軟性が必要だと判断しました。この要件を満たすため、Control Planeや管理ノードについては、さくらのクラウドを選択しました。これにより、必要な柔軟性を確保することができます。
ネットワーク構成
次に、ネットワーク構成について説明します。
ノード間ネットワーク
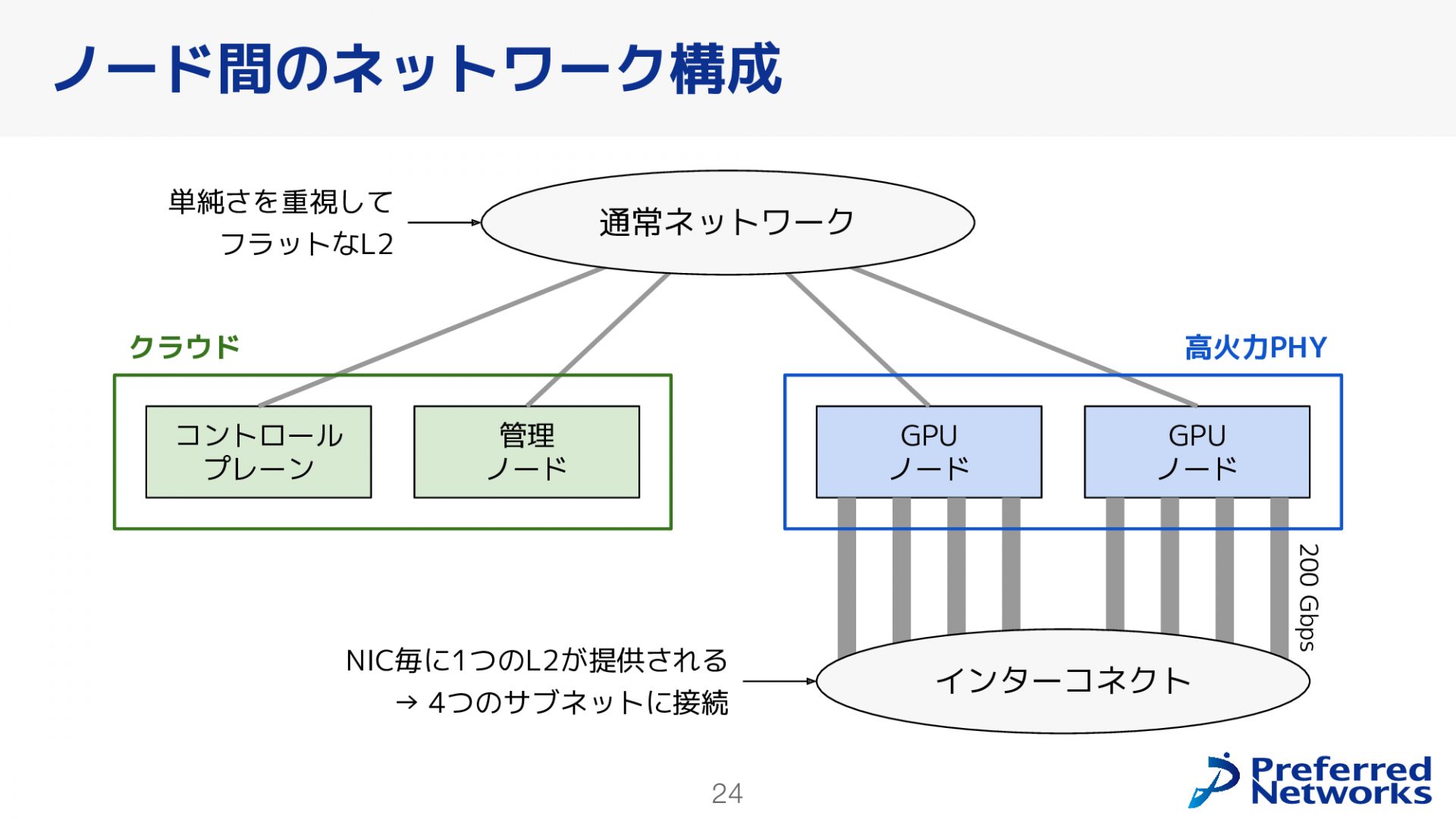
まず、クラスタの中のノード間ネットワークについて説明します。ノード間のネットワークには、通常のネットワークとインターコネクトの二つがあります。通常のネットワークはコントロールプレーン、管理ノード、GPUノードが全て接続されており、Pod間や通常のトラフィックはこのネットワークを通じて流れます。通常ネットワークに関しては、L2かL3どちらで接続するか選択できますが、今回は単純さを重視してL2接続にしました。
GPUノードについては、通常ネットワークに加えてインターコネクトにも接続されています。各GPUノードは200Gbpsのインターフェイスを4本持っており、それぞれが異なるサブネットに接続されています。このような構成により、GPUノード間の高速な通信が可能となっています。
インターコネクトの活用方法
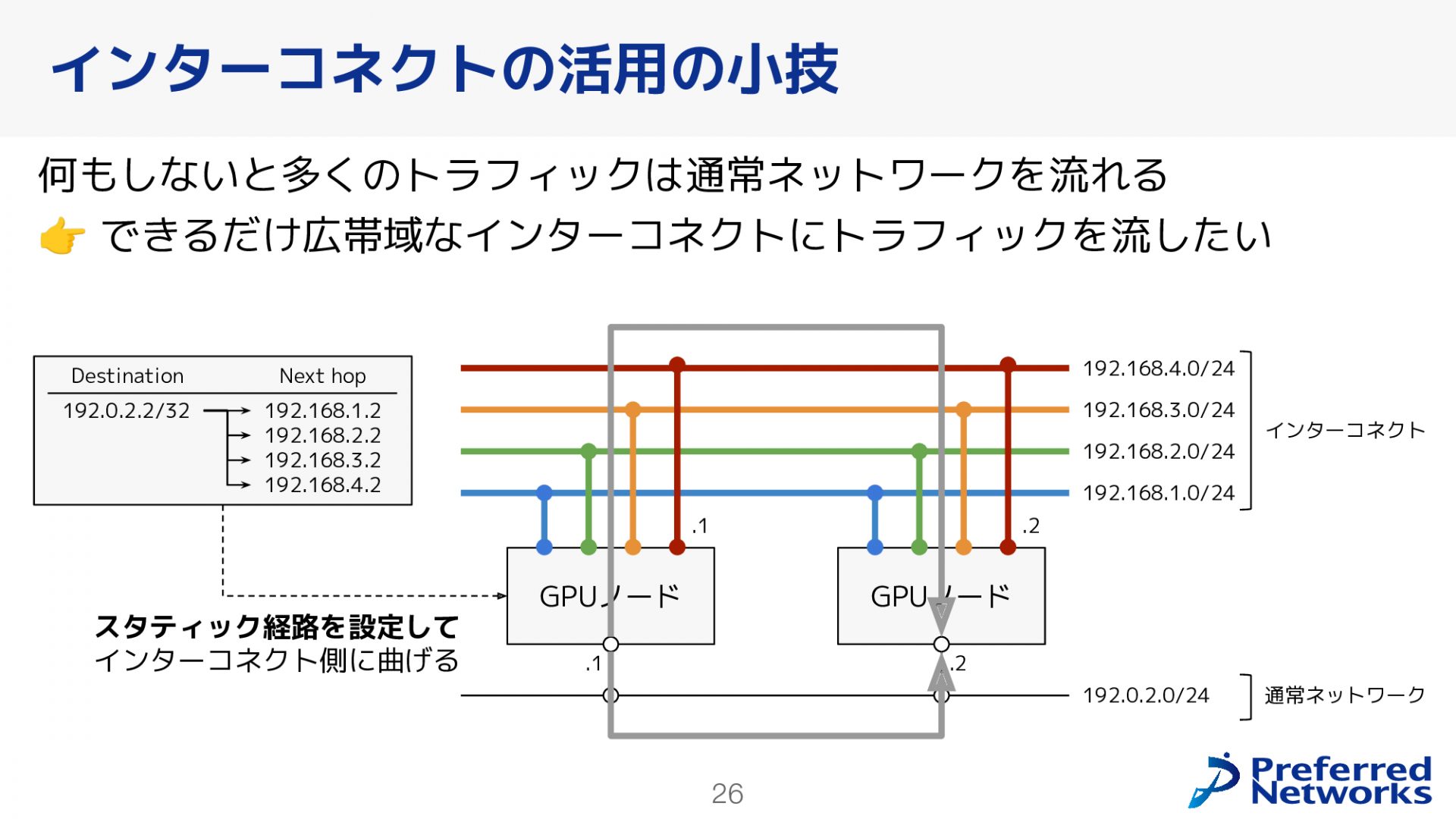
GPUノードは前述した通り、通常のネットワークとインターコネクトの二つのネットワークに接続されています。Kubernetesクラスタとして使用する際、IPアドレスは通常のネットワークのアドレスを設定しているため、デフォルトではトラフィックが通常ネットワークに流れます。しかし、このままでは広帯域のインターコネクトが活用されません。そこで、インターコネクトを有効活用するために、各GPUノードにスタティックルートを設定しています。これにより、トラフィックをできるだけインターコネクト側に向けるようにしています。
対外接続
対外接続には、インターネットとパブリッククラウドの二つがありますが、まずインターネットについて説明します。今回のクラスタではインターネット側からのインバウンド接続は不要であり、各ノードがNATを使ってインターネットに接続できれば十分です。この要件に基づいて、二つの案を検討しました。案1はさくらの専用サーバPHY側から接続する案、案2はさくらのクラウドから接続する案です。
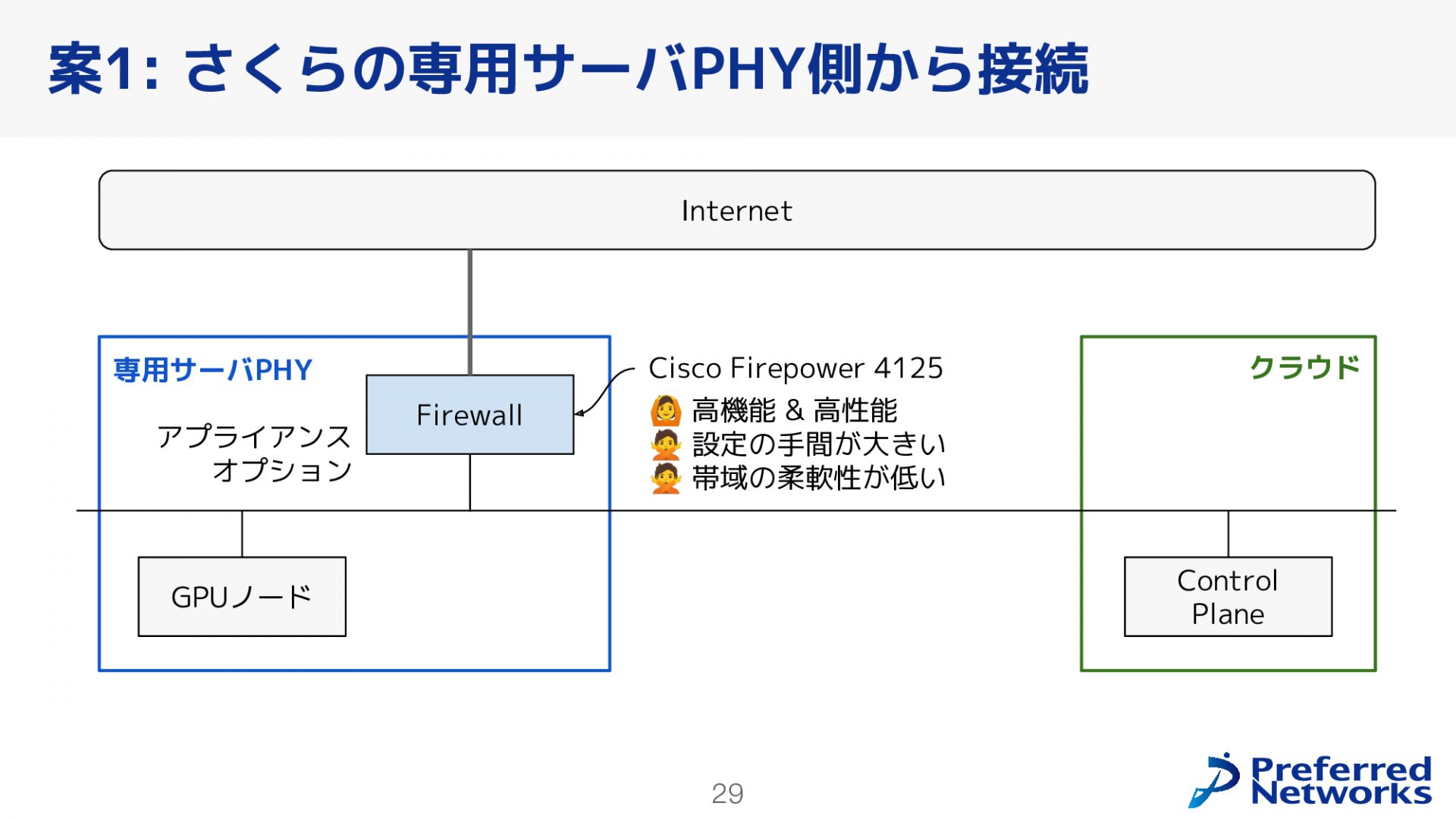
上図は、案1について説明したものです。さくらの専用サーバPHYには、アプライアンスオプションとしてFirewall機能が提供されています。このFirewallを使用してインターネットに接続する方法は、高機能で高性能なアプライアンスが提供される反面、設定の手間や帯域選択の柔軟性があまりないという特徴があります。
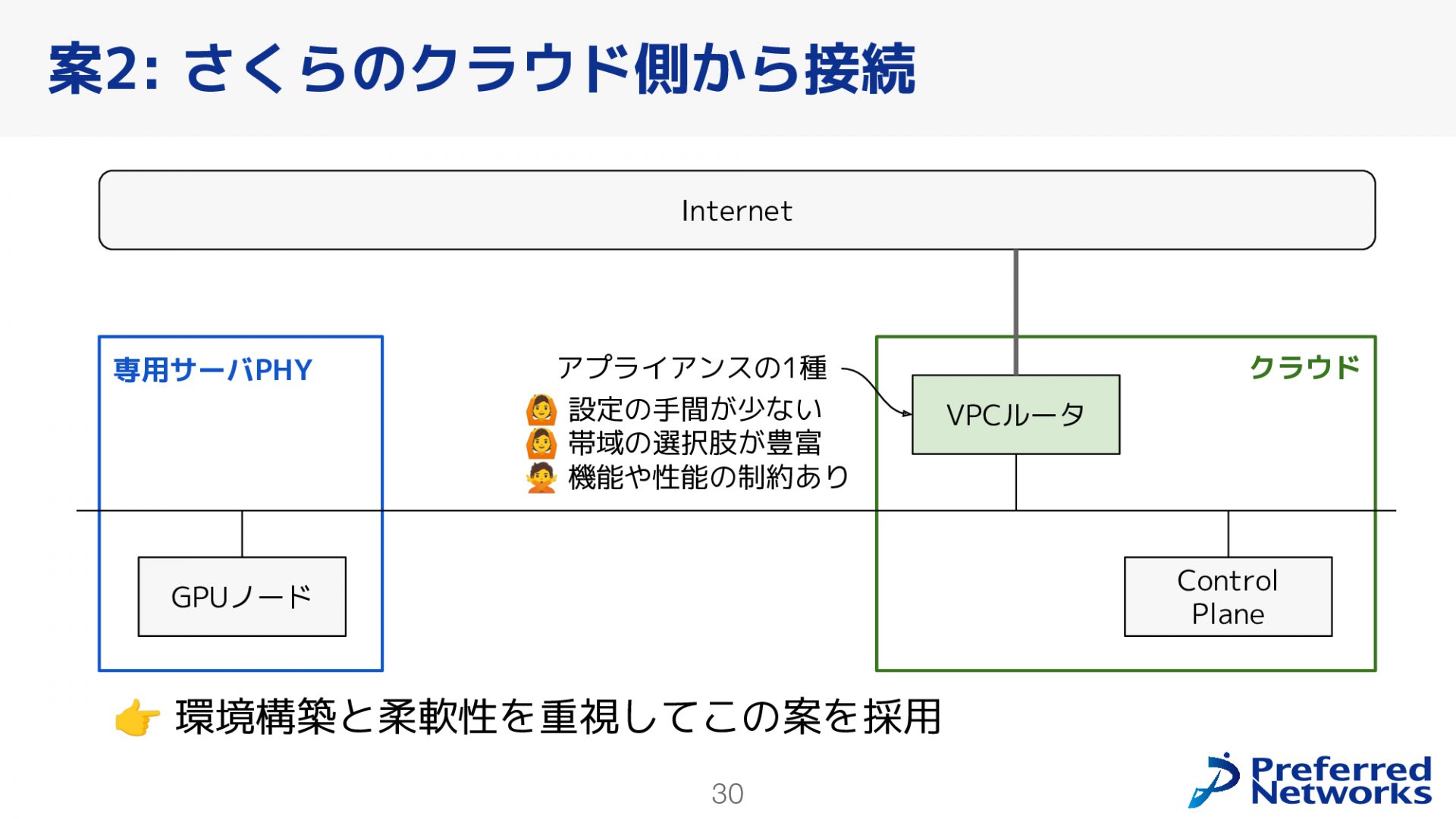
次に、案2についてです。こちらは、さくらのクラウドで提供されているVPCルータというオプションを使用してインターネットに接続します。この方法は設定の手間が少なく、帯域の選択肢が豊富にあるという利点があります。一方で、先ほどの専用サーバPHYを使った案と比べると、機能や性能に制約があります。今回は、環境構築を迅速に行うことと柔軟性を重視し、さくらのクラウドを利用する案2を採用しました。
パブリッククラウドとの接続
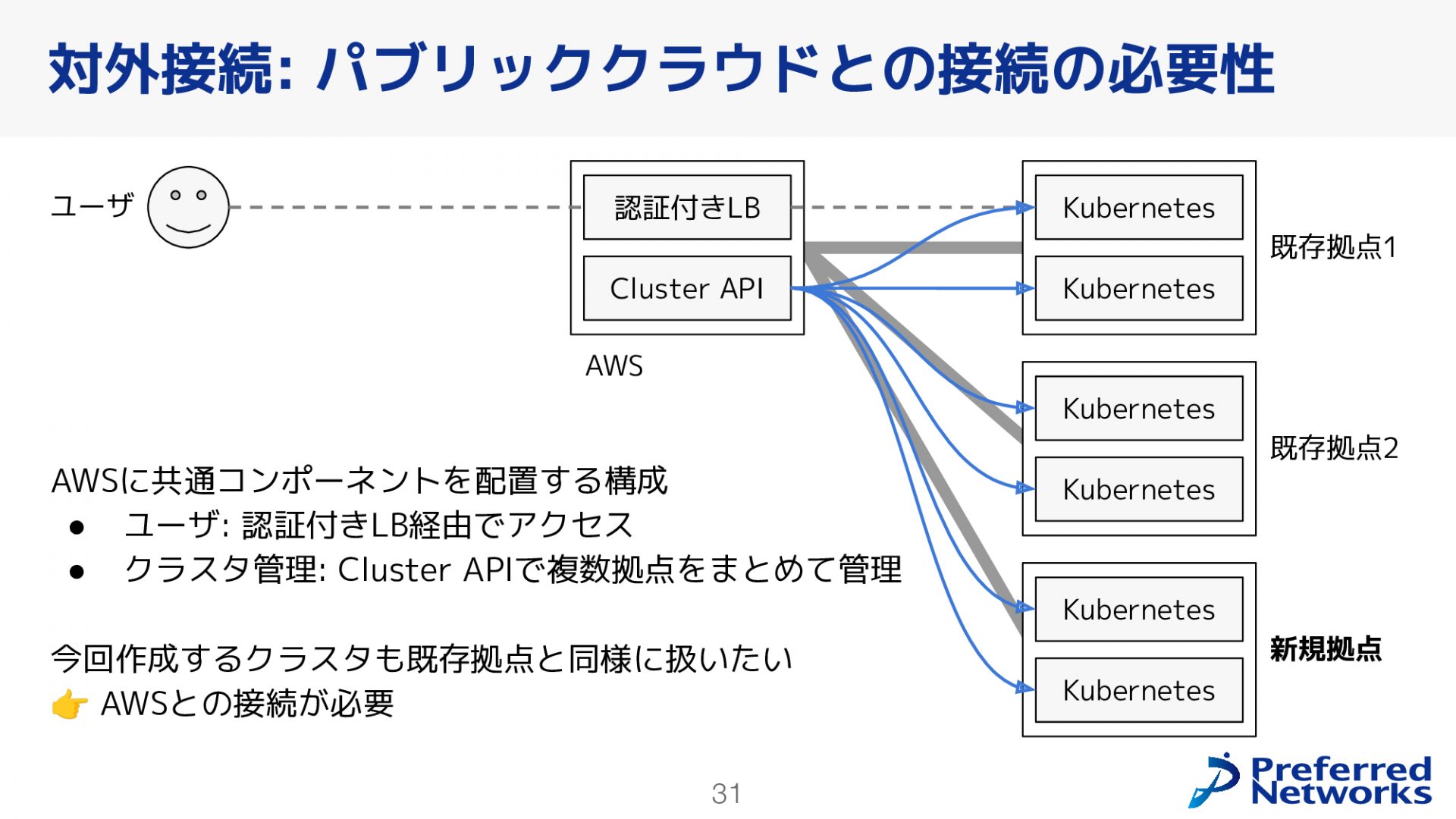
次にパブリッククラウドについてです。既存環境では、複数のKubernetesクラスタに共通するコンポーネントをAWS上に配置する構成を採用しています。例えば、ユーザはAWS上のロードバランサを経由してKubernetesにアクセスします。また、Kubernetes上にある多くのコンポーネントやクラスタ自体を管理するCluster APIもAWS上に配置しています。今回構築するクラスタにもこの構成を採用するために、AWSとの接続が必要でした。

AWSとの接続に関して検討した方法は二つあります。一つはOCXで、もう一つはAWS接続オプションです。OCXはNaaSと呼ばれるサービスで、広帯域のネットワークを比較的低コストで利用可能です。もう一つのAWS接続オプションは、さくらのクラウドのオプションとして提供されていて、さくらのクラウドから簡単に利用できます。この二つの方法について検討した結果、構築期間の短さと柔軟性を重視し、AWS接続オプションを採用することにしました。
ロードバランサ
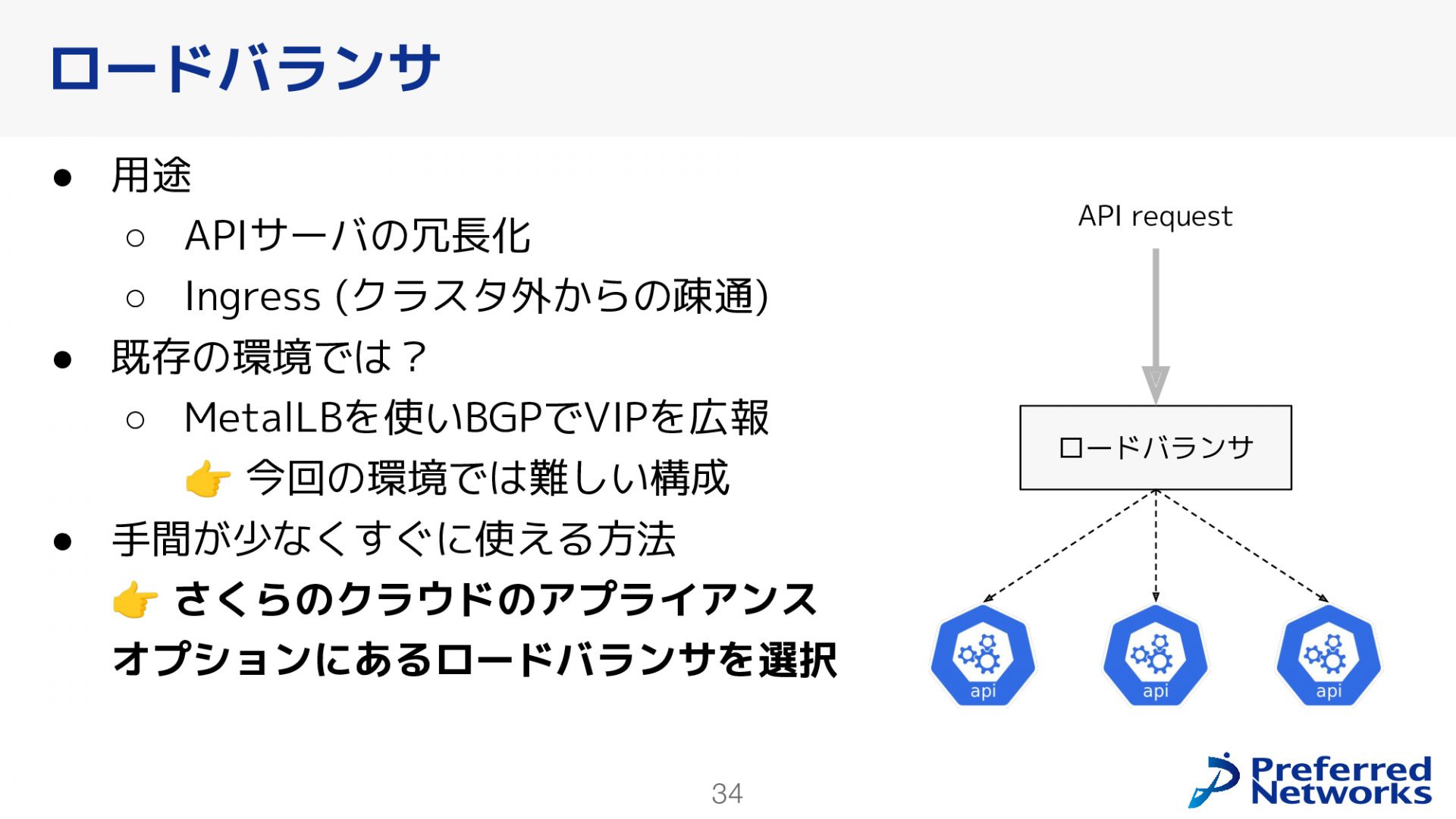
Kubernetesクラスタを構成するにあたって、APIサーバの冗長化やIngressを考えると、ロードバランサが欠かせません。既存環境では、MetalLBを使ってBGPでVIPを広報するという方法でロードバランサを作っています。しかし、今回の環境ではその構成が難しいため、さくらのクラウドにあるロードバランサのオプションを利用することにしました。
Pod間ネットワーク
RDMAの実現手段
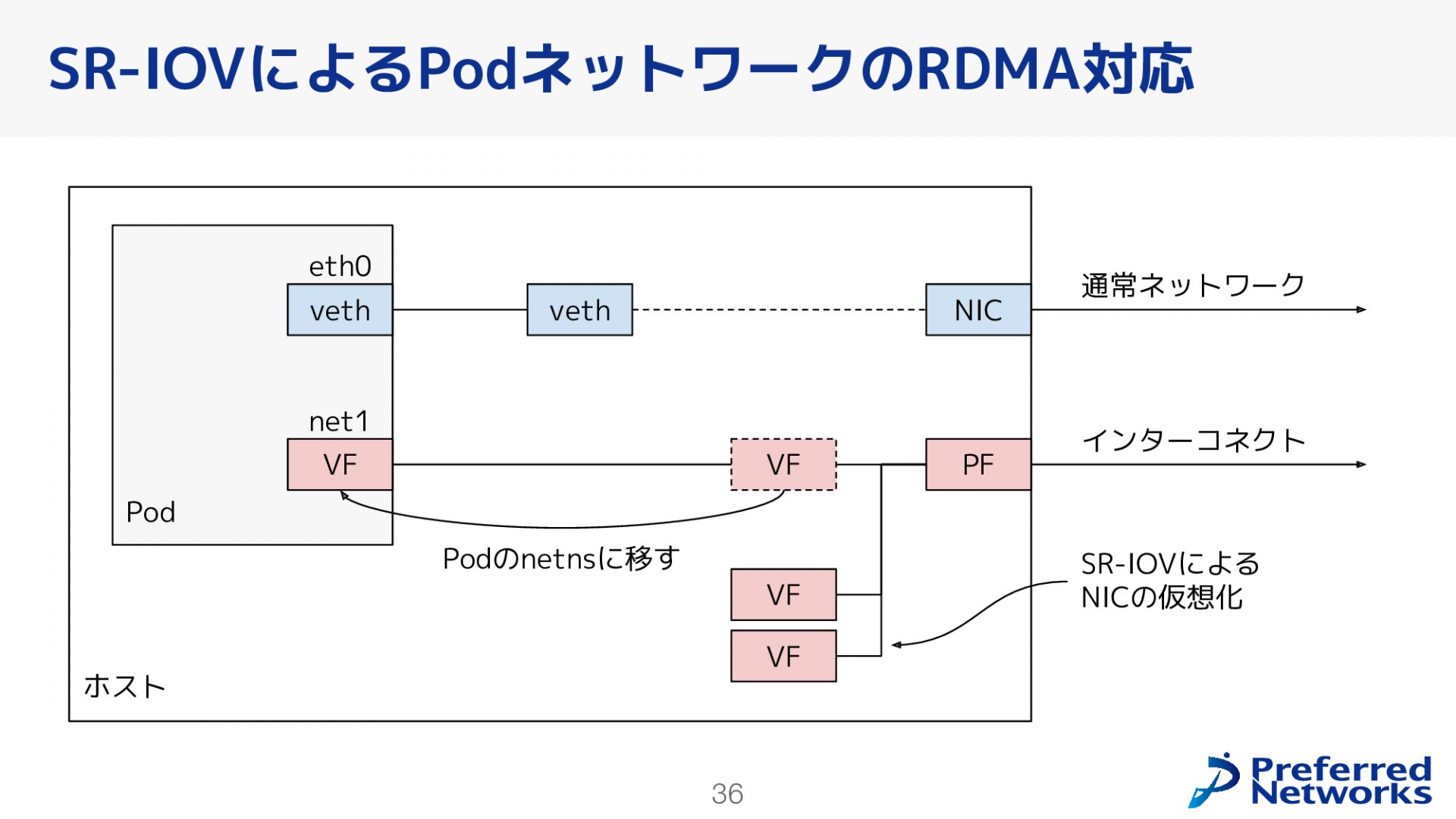
次に、Pod間ネットワークについてです。機械学習クラスタでは、RDMA(Remote Direct Memory Access)トラフィックを効率的に処理することが重要な課題となります。RDMAトラフィックをPodで効率的に処理するためには、RDMAに対応したハードウェアに近いNICをPodに持たせることが重要です。その上で、複数のネットワークインターフェースを持たせる構成が一般的です。具体的には、ホスト側のSR-IOV(Single Root I/O Virtualization)機能を使ってNICを仮想化し、1つの物理NICを複数の仮想NICに分割します。そのホスト側で仮想化されたNICをPodにアタッチし、1つのインターフェースを通常のネットワークトラフィック用、もう1つをRDMAトラフィック用に設定します。これにより、トラフィック別に専用のインターフェースで処理することができるようになり、RDMA対応の効率的な通信が可能になりました。
CNI plugin選定
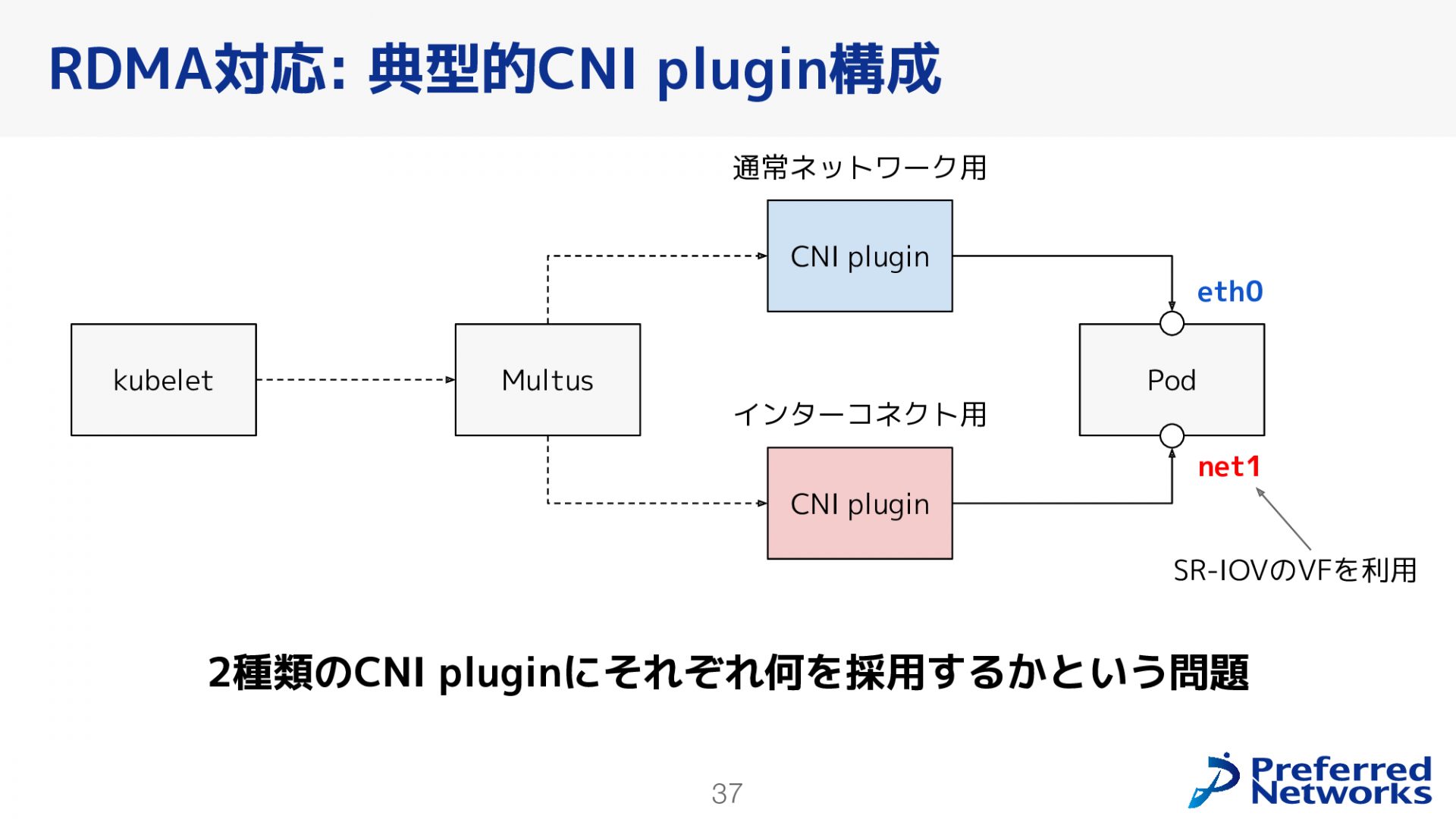
RDMAトラフィックを効率的に処理するためのPod間ネットワークを構成する際、CNI pluginの選定と構成が重要です。上図は、RDMAに対応するCNI pluginの典型的な構成となります。この構成では、KubernetesのCNI pluginの一つであるMultusと呼ばれるMeta CNI Pluginを使用して、複数のCNI pluginを使い分けています。これにより1つのPodに対して通常ネットワーク用、RDMAを行うためのインターコネクト用と設定することが可能となります。

今回は、通常ネットワーク用のCNI pluginとして既存環境で利用実績のあるCiliumを採用しました。しかし、既存環境と今回の環境ではCiliumの動作モードが異なっています。既存環境では、BGPを使用してL3ファブリックを構成しており、これにより効率的なパケット転送、柔軟性のある安定したネットワーク運用を実現していました。一方、今回の環境ではBGPでの構成が難しかったため、VXLANのトンネリングモードを使用することにしました。VXLANはL2のトンネリング技術であり、ネットワークセグメントを仮想的に拡張することができるため、物理ネットワークの制約を超えて柔軟なネットワーク構成が可能です。今後可能であれば今回の環境でも既存環境と同様にBGPを使用したネイティブルーティングモードへの変更を検討しています。

次に、インターコネクト用CNI pluginについて説明します。今回採用したのはSR-IOV CNI pluginというオープンソースのCNI pluginです。既存環境では内製のCNI pluginを使用してインターコネクト用のネットワークを構成していました。しかし、この内製pluginは既存環境のネットワーク構成と密接に結びついた実装となっており、そのまま今回の環境で使用することが難しいという課題がありました。さらに、独自のコンポーネントをなるべくオープンソースに置き換える方針もあり、今回はあえて既存環境とは異なるSR-IOV CNI pluginを選択しました。インターコネクト用CNI pluginの場合、特にIPアドレスの管理が問題となります。通常のCNI pluginでは、IPアドレスの割り当て機能がCNI plugin自体に含まれていますが、SR-IOV CNI pluginにはその機能がないため、別途考える必要があります。この問題を解決するために、クラスタ全体で特定のサブネットからIPアドレスを割り当てる機能を持つWhereaboutsというオープンソースのCNI pluginを採用することにしました。
クラスタ構築
ここでは、機械学習用Kubernetesクラスタ構築を3つのステップに分けて簡単に説明します。

ステップ1として、コントロールプレーンを構築します。コントロールプレーンには、Kubernetesのリソースを永続化するためのetcdや、Kubernetesに必要なAPIを提供するkube-apiserverなどのクラスタ全体で必要なコンポーネントをインストールし、初期化します。
次に、ステップ2として、機械学習を実行するためのワーカーノードをセットアップします。ワーカーノードでコンテナを実行するために必要なコンテナランタイムのインストールや機械学習モデルのトレーニングにGPUを利用するため、適切なGPUドライバをインストールしたり、ネットワーク接続を最適化するためNICドライバのインストール等の一連の準備が必要です。これらの準備が整ったら、ワーカーノードをKubernetesクラスタに参加させ、Kubernetesとして利用できるようにします。
最後にステップ3として、クラスタに必要なアドオンをインストールします。例えば、NVIDIAのGPUを使用する場合はNVIDIA device pluginをインストールします。また、ネットワーク用のCNI pluginやストレージ用のアドオンも必要に応じてインストールします。
なお、ステップ2において通常のワーカーノードをセットアップする際には、まずVMや物理マシンにOSをインストールし、IPアドレスを設定します。例えば、VMの場合はTerraformやクラウドのAPIを使用して必要なVMを作成します。物理マシンの場合は、OSを再インストールしてノードを使える状態にします。次に、コンテナランタイムや各種ドライバなどのソフトウェアをインストールします。この作業は多くの場合、Ansibleなどの構成管理ツールを使用して行われます。最後に、kubeadm joinコマンドを使用してノードをKubernetesクラスターに追加します。

この方法でノードを作成することは可能ですが、数十台規模になると管理が非常に大変です。例えば、特定のサーバでAnsibleが失敗した場合、再実行するとドライバのバージョンが最新になってしまうことがあります。このような問題が発生すると、ノードごとに異なるバージョンが原因で予期しないバグが発生することがあります。また、ハードウェアの故障時には再度OSをインストールしてAnsibleを実行する必要があり手間がかかります。
このように、一台一台のサーバを丁寧に管理することは現実的ではなく、クラウドネイティブな運用とは言えません。そこで、今回はKubernetesクラスタのノード管理を自動化し、柔軟性があり効率的な運用が可能なCluster APIという機能を使用しました。
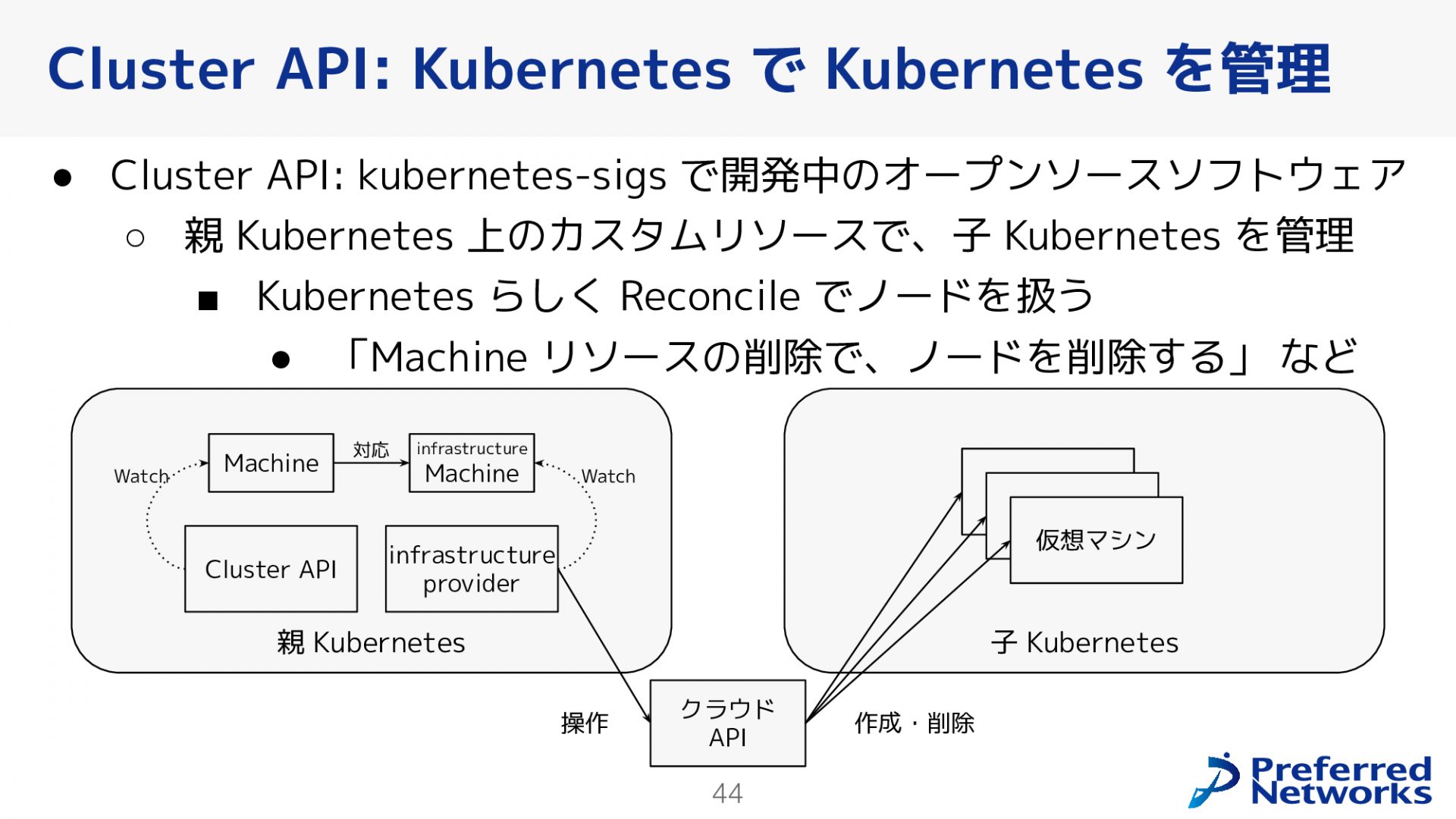
Cluster APIは、Kubernetesを使ってKubernetesクラスタを管理するためのkubernetes-sigsによって開発中のオープンソースソフトウェアです。親Kubernetesと、それが管理する子Kubernetesクラスタの関係を持っていて、親Kubernetesクラスタ上には、子Kubernetesクラスタを管理するためのカスタムリソースがあります。例えば、仮想マシンの管理には「マシン」という名前のリソースがあります。このマシンリソースを削除すると、それに対応する仮想マシンが削除されるといった操作がCluster APIによって可能になります。これにより、インフラストラクチャーの管理がよりイミュータブルな形になります。
また、使うクラウドによって仮想マシンの作成方法や物理マシンの管理方法が異なるため、それぞれの環境に対応するためのinfrastructure providerというコンポーネントも存在します。infrastructure providerは、特定のクラウド環境やオンプレミス環境において仮想マシンや物理マシンを管理するための機能を提供します。

Cluster APIを利用することで、ノードの作成、セットアップ、クラスターへのジョインなど、すべてのプロセスを完全に自動化できます。この自動化により、ハードウェア障害や大規模化にも対応できるカスタマイズ可能なインフラストラクチャーが実現します。
Cluster APIを活用するためには、infrastructure providerの実装が必要です。これにより、さまざまなクラウド環境やハードウェアに対応することができます。例えば、既存環境のベアメタルサーバではCanonicalのMAASを使ってOSインストールなどのマシンのプロビジョニングを行っていますが、Cluster APIからMAASを利用可能にするためのinfrastructure provider(MAAS provider)は内製したものを利用しています。今回、新たにさくらインターネットのクラウドサービスや専用サーバPHYを利用することにしたため、専用のinfrastructure providerを実装しました。これにより、既存環境と同じ仕組みでベアメタルとさくらのサービスの両方を一元的に管理することが可能になりました。
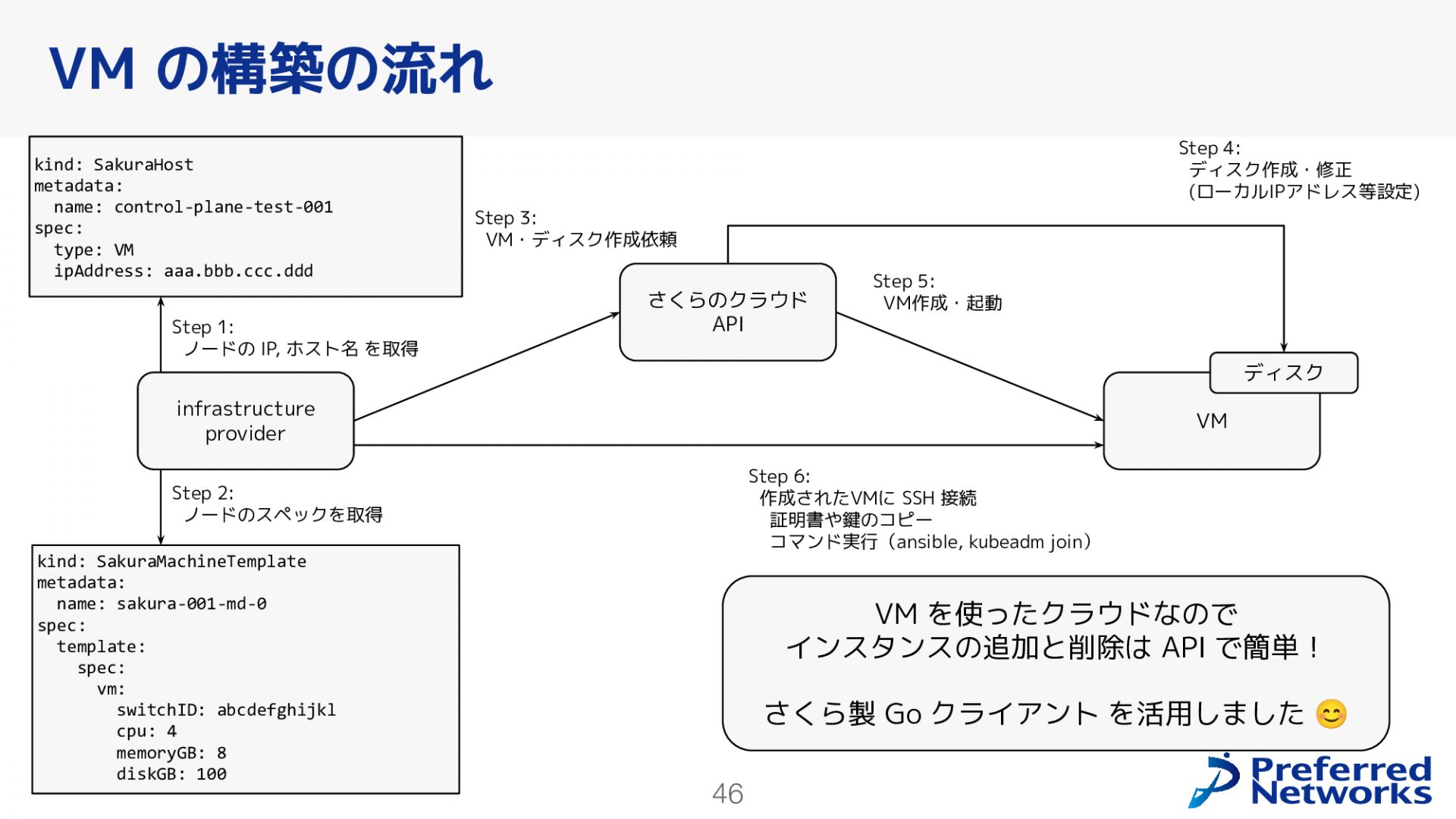
VM構築の流れを上図を使って説明します。
ステップ1として、ノードのIP、ホスト名を取得します。infrastructure providerは親Kubernetesにデプロイされているコンポーネントであり、さくらのクラウドAPIを利用します。まず、infrastructure providerは親Kubernetesの上にあるカスタムリソース(ここではSakuraHost)からノードのIPやホスト名などの情報を取得します。ステップ2として、CPUの数やメモリのサイズなどノードのスペックを取得します。
ステップ3として、さくらのクラウドAPIを呼び出して、VMとディスクの作成を依頼します。ステップ4として、さくらのクラウドAPIはディスクを作成し、必要なローカルIPアドレスなどの設定を行います。次にステップ5では、さくらのクラウドAPIはVMを作成し、起動します。
最後にステップ6でinfrastructure providerから作成されたVMにSSH接続し、Kubernetesクラスタに入るための証明書やAnsibleのPlaybookをクローンするためのデプロイキーを取得します。これらを使ってコマンドを実行するとKubernetesノードとして動作するようになります。
VMを使ったクラウド環境では、インスタンスの追加と削除はAPIを利用することで簡単に行えます。infrastructure providerを実装する際には、さくら製のGoクライアントを活用しています。このプロセスをすべて自動化することで、大体15分ほどでVMを作成したり削除したりすることができるようになります。
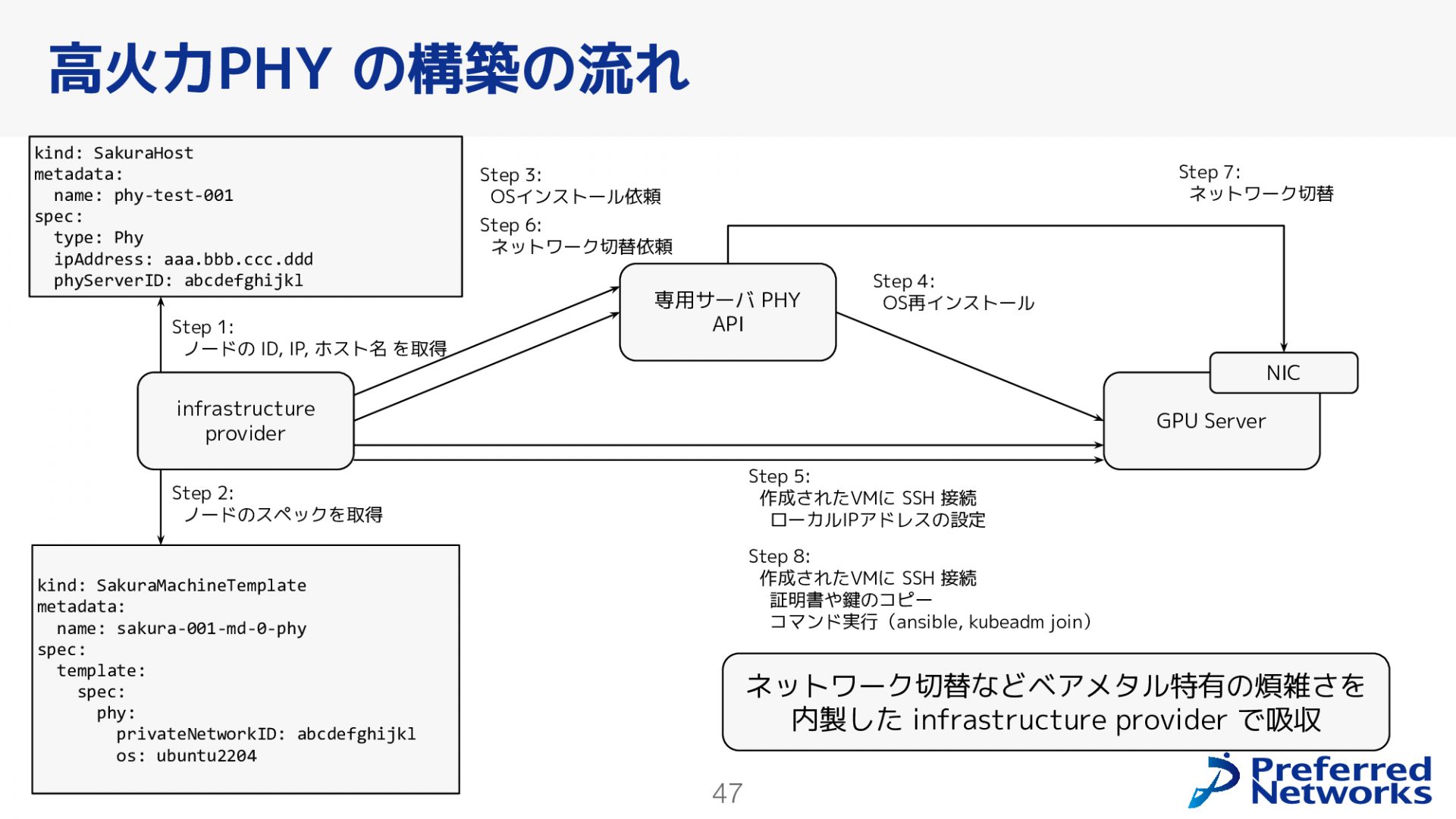
上図を使い、GPUサーバの構築プロセスについて紹介します。
ステップ1では、infrastructure providerは親Kubernetesの上にあるカスタムリソース(ここではSakuraHost)からノードのID、IP、ホスト名などの情報を取得します。ステップ2では、GPUサーバではCPUの大きさなどは変わりませんが、インストールするOSや接続するネットワークに関する情報等ノードのスペックを取得します。
ステップ3では、infrastructure providerはさくらの専用サーバPHYのAPIに対して、GPUサーバにOSをインストールするよう依頼します。ステップ4では、さくらの専用サーバPHYのAPIはGPUサーバにOSを再インストールします。
ステップ5では、infrastructure providerから作成されたVMにSSH接続し、ローカルIPアドレスを設定します。ステップ6では、infrastructure providerがさくらの専用サーバPHYのAPIに対して、ネットワークの切り替えを依頼します。ステップ7では、NICのネットワークが切り替わり、通信が可能になります。ステップ8では、infrastructure providerからSSH接続し、証明書やデプロイキーをコピーしてコマンドを実行します。これにより、GPUサーバのセットアップが完了します。
ネットワークの切り分けや切り替え、ベアメタル特有の煩雑な作業も、infrastructure providerで吸収し自動化しています。これより、約1時間でノードの再インストールが完了することができます。
ストレージ構築
生成AIに求められるストレージ要件
生成AI、特に大規模言語モデル(LLM)の運用に必要なストレージ要件を振り返ってみたいと思いま す。まず特徴として、大規模言語モデルでは多くのパラメータを扱うため、モデル全体を保存するには 数百GB以上のストレージが必要になります。数ヶ月に及ぶ学習中の物理故障に対応するためには、 学習過程でモデルのスナップショットを定期的に取得する必要があります。分散学習では、複数の Podからの書き込みが発生するため、それに対応したストレージが必要です。また、推論時にはPod 数などの条件が変わることもあり、それに対応できることも必要です。これらの要件を満たすストレージソリューションを見つけることは困難です。実績のあるLinuxベースの ディスクエクスポート機能を提供するNFSや、PFNが以前から採用しているOzone、Rock/Cephや独自の分散キャッシュシステムでは、完璧なストレージソリューションとはならず、生成AIの要件を満たす ストレージを探しています。

高火力PHYのGPUサーバには、高速なディスクが4つずつ搭載されています。これを効果的に活用することで、ストレージ要件を満たすことができると考えています。最初にとったアプローチは、Rook/Cephの信頼性と分散キャッシュシステムの高速性を組み合わせることでした。Rook/Cephを用いたブロックストレージやファイルストレージは、信頼性が高く、データの整合性を保って安定してデータを保存することができます。一方で、パフォーマンスの面で課題があります。内製の分散キャッシュシステムは、高速でデータアクセスが可能ですが、信頼性に課題があります。このトレードオフのある2つのストレージシステムを併用することで、生成AI学習で必要となる高度なストレージ要件を達成することができると考えています。
まとめ

今回の発表では、さくらインターネットの石狩DCを利用して、PFNで考える生成AI向けのクラスタを構築する最適な構築レシピについて説明されました。クラスタ構築には考えなければならないことがたくさんあり、選択肢も多岐に渡ります。また、技術は日々進化しており、新しいソリューションやより効率的な方法が出てくる可能性があります。みなさんがGPUクラスタを構築する際には、ぜひおすすめのレシピや新しい発見を清水さんと上野さんに共有してください。
あとがき:さくらインターネットの担当者より
本記事の最後に、今回のクラスタ構築プロジェクトにおいて当社側の担当者として参加した、テクニカルソリューション本部の鶴田憲也からのコメントを掲載します。
「清水様、上野様と初回お打合せした際、現在のアーキテクチャが大方出来上がった状態の構成を提示頂きました。その後、使用するサービスの最適な組み合わせ・技術仕様の詳細について議論する中で、高い技術力をもって高火力PHYをいかに賢く利用するかを計画頂いていると感じました。 また、発表頂いた中で触れて頂いている仮想環境と物理環境の比較・組み合わせ例の検討経緯や、クラウドのアジリティと高火力PHYの専有性を両立させた構成は、他ユーザ様にもぜひ参考にして頂きたい内容となっています。
Preferred Networks様のプロジェクトではスケジュールが非常にタイトであったため、弊社側でも迅速な対応が求められました。本来であれば試験運用期間を設けて正式契約に進むところ、今回はそのプロセスを省略しすぐに本格運用としてご利用開始頂きました。 他のお客様/プロジェクトでも同様にタイトなスケジュールで利用開始頂く事はありましたが、今回のように複数のサービスを組み合わせて大規模に運用頂くのはPreferred Networks様の技術力あってのものと考えています。『よくぞここまで使い込んでいただきました』と改めてお礼申し上げるとともに、今後もより活用頂けるよう引き続きお手伝いさせて頂きます」