ビギナー向け生成AIのキホン講座 #2

目次
はじめに
株式会社TechWorker 古野 光太朗です。
弊社では生成AIの導入支援を行っています。今回の記事の内容は、さくらインターネット様の社内向け生成AI勉強会にて私が講演した内容を記事化し、一部新たに更新・追記したものです。この記事を読むことで、生成AIビギナーの方も、生成AIに関する基本的な知識が身につけられます。
全2回に分けて解説をしており、今回は第2回目になります。
第2回目では、実際に生成AIを使うにあたって、知っておくべき情報をまとめて解説しています。第1回目では、現在に至るまでのAIの歴史から、生成AIを支える技術の全貌が大まかに捉えられる内容となっていますので、併せてチェックしてみてください。
それでは今回はまず、ChatGPTなどのテキスト生成AIの根本原理から見ていきましょう!
テキスト生成AIの根本原理
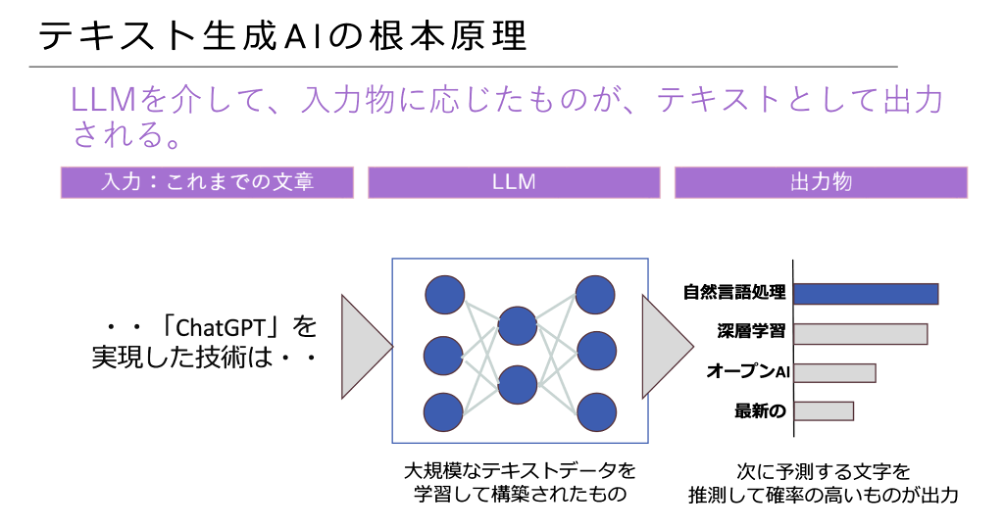
テキスト生成AIの根本原理は、「確率に基づいた推測」です。あくまで推測なので、生成AIは間違うことがあります。まずこの大前提をしっかり覚えておきましょう!
ChatGPTやGeminiのようなテキスト生成AIは、テキストの入力を受けたら、大規模言語モデル(Large Language Model:LLM)を介して、推測したテキストを出力します。テキスト生成AIは思考する能力を持っているわけではなく、あくまで次に出力される文字を予測しているだけなのです。
例えば、「今日のご飯はとっても」の後に来るテキストはなんでしょうか? 「美味しい」など、味の感想である確率が高そうですね。
では「1+1は?」というテキストを入力した場合はどうでしょうか? 出力は「2」である確率が高そうです。
ここで注意しなくてはならないのが、LLMが数式を計算している訳ではなく、入力した分脈に基づいて、次に続く文字の確率を計算します。そのため、意図した結果を得るためには、適切に指示をしなくてはいけない点を押さえておきましょう。
この特徴を理解し、LLMから質の良い出力を得るための指示を書くことを「プロンプトエンジニアリング」と言います。
プロンプトエンジニアリング

それではプロンプトエンジニアリングがどういうものか見ていきましょう。
前述のとおり、プロンプト(入力物)とは、LLMに対して入力される指示・命令文のことです。生成AIはこのプロンプトに応じて出力物を生成するため、出力物の質を向上させるためにプロンプトを工夫する必要があり、プロンプトエンジニアリングが研究されるようになりました。
プロンプトは、#で情報を整理するマークダウン記法を活用したり、定量的かつ具体的な表現にすると、ユーザにとってもAIにとっても理解しやすくなり、結果として出力の質が向上することがあります。一例として、スライドのプロンプトの実行結果を記します。

とはいえ、実はこのプロンプトの書き方には、決まった1つの正解があるわけではありません。
LLMは様々な企業や研究機関が開発を行っており、それぞれに特性があります。そのため、LLMや生成AIサービスによって、最適なプロンプトの書き方も変わってきます。
サービスの提供元が提供しているプロンプトガイドラインを見るのも有効です。テキスト生成AIサービスであれば、そのAIに最適なプロンプトを尋ねてみるのが手っ取り早いです。
多くのテキスト生成AIサービスは無料で使うことができますので、ぜひ有効なプロンプトを研究してみてください。
LLM(大規模言語モデル)とは
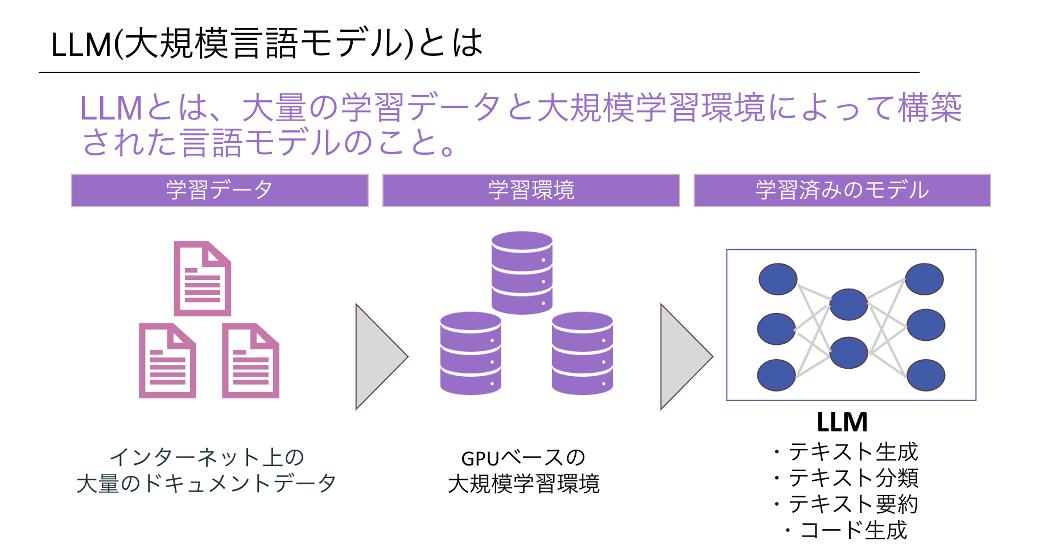
それでは、ここでやっとLLMについて見ていきましょう。
LLM(大規模言語モデル)とはLarge Language Modelの略であり、機械学習モデルの1種です。
※ 現在は「言語」以外のモデルもあるため、総称としての「Foundation Model(LM)」や「基盤モデル」と呼ばれる場合もあります。
大量のテキストデータを学習しており、自然な文章を生成したり、入力されたテキストに対して要約や翻訳など意味のある応答を提供できるモデルのことを言います。
LLMの開発には大量のデータ、専門知識を有する人材、計算資源である高性能なGPUサーバと、計算を行うサーバを動かすための膨大な電気が必要になります。つまりとってもお金がかかるため、日本でも積極的な投資が行われています。
次からはLLMの主要プレイヤーをチェックしていきましょう。
世界で代表的なLLM
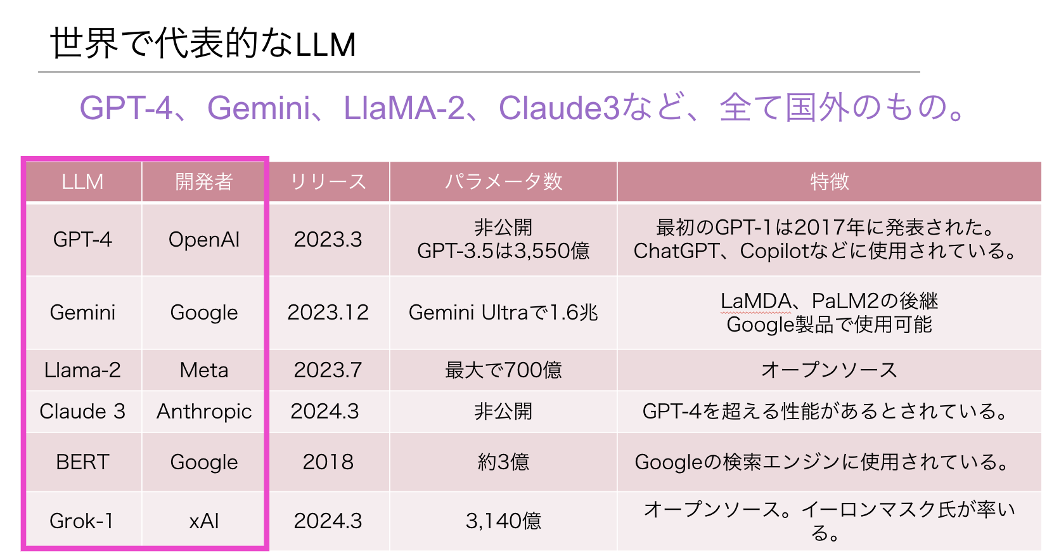
前述の通り、代表的なLLMは海外のスタートアップやメガテック企業を中心に開発が進められています。
特にOpenAIが開発したGPTやGoogleが開発したGeminiは、一度は目にした事があるのではないでしょうか。2024年6月に行われたAppleの年次イベントではAppleとOpenAIの提携も発表され、生成AI開発のトップランナーは依然としてOpenAIであると言えます。
Metaが開発したLlamaはオープンなライセンスで公開されており、商業利用や研究目的にLlamaベースのカスタマイズされたLLMが開発されています。AnthoropicはOpenAIの元研究者が2021年に設立した会社で、ClaudeというLLMを開発しています。ClaudeはGPTに匹敵する性能を持ち、Amazon Web ServicesやGoogle Cloud上でも提供されており、存在感を強めています。
LLMの性能を評価する重要な指標として「パラメータ数」と呼ばれる値があります。パラメータ数が多いほど、データから学べる情報量が多くなり、複雑な学習が可能となるため、賢いLLMであると言えます。しかし、LLMを評価する指標はパラメータ数だけではないため、パラメータ数が高ければいいというものでもありません。特に2024年に入ってからは、SLM:Small Language Model(小規模言語モデル)も登場し、軽量化・分野特化型のLLMの開発が加速しています。
日本国内の代表的なLLM
ここまで海外の企業のLLMのお話が中心となっていましたが、国内企業による国産LLMの開発も盛んに行われています。
- 日本電信電話株式会社(NTT)
- 日本電気株式会社(NEC Corporation)
- LY Corporation
- 株式会社サイバーエージェント
- 株式会社オルツ
- 株式会社ELYZA
海外のLLMがスタンダードであるうちは、生成AIの利用の多くが海外に依存することになってしまいます。それは経済安全保障の観点からも好ましくありません。そこで国産LLMの開発や開発に向けた投資が行われ、日本でも高機能なLLMが生まれつつあります。
ELYZA、グローバルモデルに匹敵する日本語LLMを開発、デモ公開
https://prtimes.jp/main/html/rd/p/000000042.000047565.html
経産省、生成AI基盤モデル開発の新興企業など7社を支援 84億円
https://jp.reuters.com/markets/japan/funds/HFRHVSJPJBLSVL46ABTV477VAA-2024-02-02/
経済産業省からも、AI開発に必要な計算資源の整備に対する大規模な助成が行われています。
経済安全保障推進法に基づくクラウドプログラムの安定供給確保に係る供給確保計画の認定等について
https://www.meti.go.jp/press/2024/04/20240419002/20240419002.html
LLMの出力の特徴
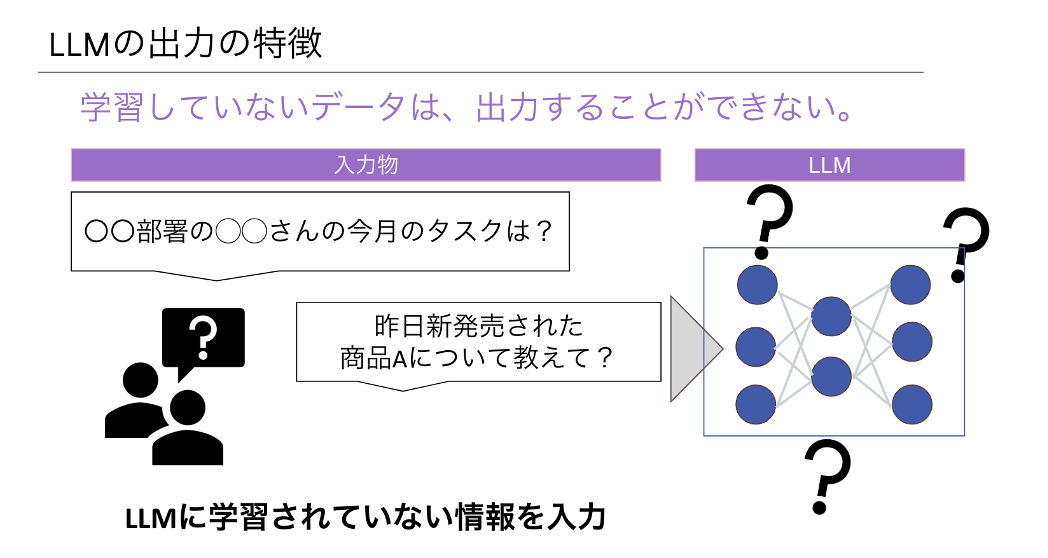
LLMが出力する結果の知っておくべきポイントとして、学習していないデータは出力できないという点があります。例えば、ChatGPTに対して、勤めている会社の業務マニュアルの内容や、その日に新しく発売されたゲームについての質問をしても、LLMの中にその情報はありません。
そういうLLMが持っていない情報を補完するため、最近では必要時にインターネット検索を行う「ブラウジング機能」が実装されています。また、ChatGPTに関しては、ユーザがChatGPTをカスタマイズしたり、カスタマイズしたChatGPTを共有して利用できるGPT Storeというサービスも存在します。
それでは、会社のように外部に公開できないデータを用いて、業務の中で生成AIを使いたいとなった場合はどうしたらよいのでしょうか? 次からはその方法について解説します。
RAG(ラグ)
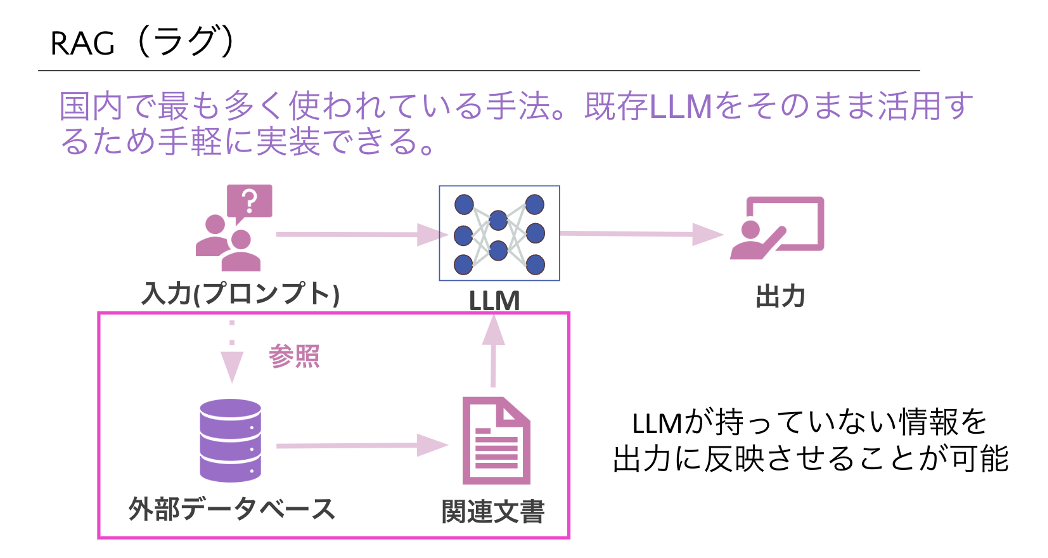
RAG(Retrieval-Augmented Generation)は、既存のLLMをそのまま活用しながら検索エンジンや外部データベースを参照することで、それを基にした応答を生成することが可能です。例えば、社内に存在する業務マニュアルやFAQなどを踏まえた社員向けの回答の生成、顧客からの過去の問い合わせや購入履歴に基づいた、よりパーソナライズされたカスタマーサポートの実現などが考えられます。
この方法は国内で多く使われている手法ですが、データをなんでもかんでも取り込めばいいというわけではなく、データを活用するため前処理が必要です。古い情報や誤った情報、重複したデータの削除や、個人情報や機密情報に対する適切な処理などが必要になります。
FineTuning(ファインチューニング)
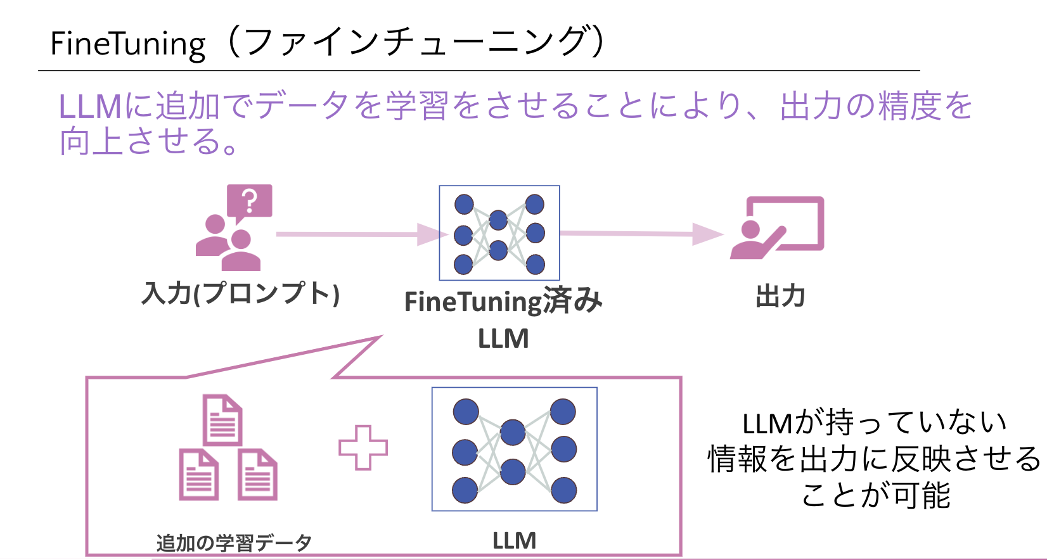
Fine Tuningとは、既存のLLMを活用するRAGとは違い、LLM自体をカスタマイズすることで特定のタスクに特化させます。例えば、医療や金融などの分野に特化したLLMは、Fine Tuningが施されているのが一般的です。このような専門性の高い分野においては、公開されているような汎用的なLLMでは不十分なため、Fine Tuningが施された独自のLLMが用いられます。
生成AIの将来性
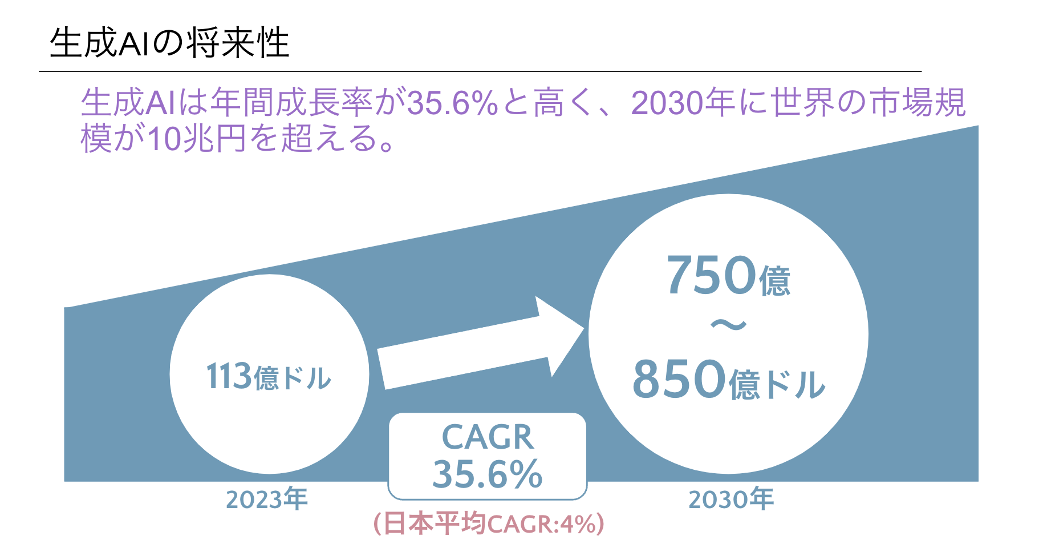
生成AIに対する期待が高まっているのは、日々のニュースなどから皆さんも感じ取っていらっしゃるかと思いますが、数値予測を見てみましょう。
生成AIの市場は急速に拡大しており、年間成長率は35.6%と非常に高い水準にあります。この成長率が続くと、2030年には世界の市場規模が10兆円を超えると予測されています。2023年と比較して、約7倍という高い市場の将来性を見込んでいます。
※CAGR(Compound Annual Growth Rate、年平均成長率):複利の考え方をもとに、複数年にわたる成長率を考慮し、1年あたりの平均成長率を求めたもの。最初の値から最終値に達するために、毎年一定の成長率で増加したと仮定した場合の成長率。
生成AIの課題
それでは次に、生成AIを使う上で知っておきたい、生成AIが抱える課題をいくつか見ていきましょう。
ハルシネーション
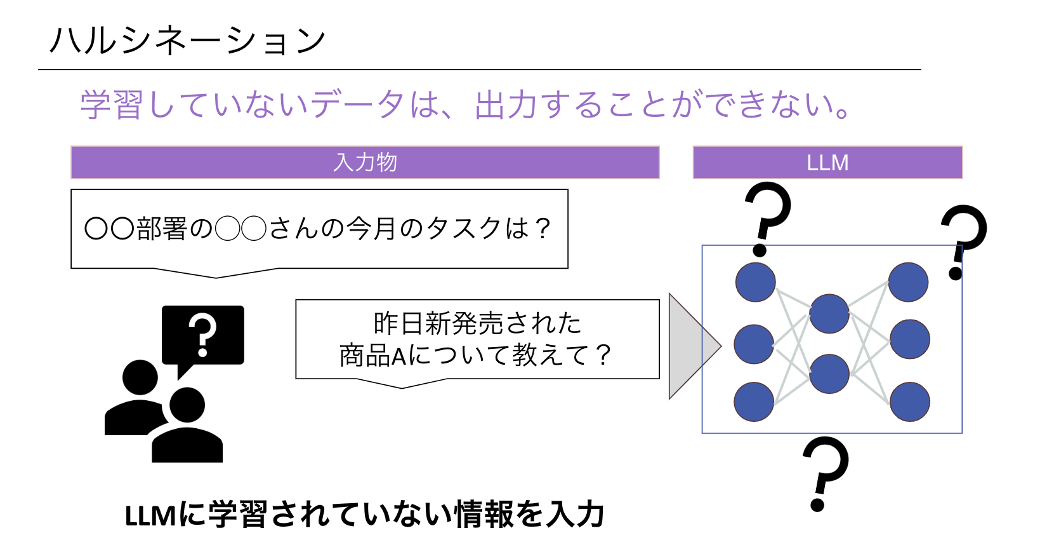
LLMはそれらしいテキストを出力しますが、実際には間違っていたり、存在しない情報を出力する現象があります。これをハルシネーション(Hallucination)と呼びます。ハルシネーションには「幻覚」という意味があります。たとえそれっぽい主張であっても、生成AIの回答が事実なのかどうかは、必ず人間が調べて確認をする必要があります。
大規模言語モデル(LLM)はインターネット等から収集した大量のデータから学習して回答を生成しますので、そもそものデータに偏りがあったり誤情報が含まれていれば、間違った情報を出力する可能性があります。また、各LLMごとの学習プロセスでも変わってくるなど、様々な要因でハルシネーションは引き起こされます。
学習するデータセットの品質の向上や、出力結果をチェックする別のAIを用意するなどの対策がとられていますが、現時点ではハルシネーションを完全に抑制することは難しいと言われています。
倫理的な問題
前述のとおり、大規模言語モデル(LLM)はインターネット等から収集した大量のデータから学習して回答を生成しますので、そもそものデータにバイアス(偏り)があり、知らず知らずのうちに偏見を含んでいる可能性があります。例えば、人種、性別、文化的背景に関する偏見が含まれている場合、AIの生成結果にもその影響が反映されることがあります。
知的財産権の問題
生成AIは既存のデータを基に新しいコンテンツを作成するため、そのデータが著作権で保護されている場合、知的財産権の侵害に関する懸念が生じます。学習した既存データに酷似した画像や映像、音楽、文章などを出力した場合、知らず知らずのうちに知的財産権を侵害してしまう恐れがあります。
プライバシーの問題
生成AIは個人に関するデータも学習することがあり、そのデータが適切に保護されていない場合に、個人のプライバシーを侵害する恐れがあります。具体的には、個人情報を含むテキストや画像が生成される可能性が考えられます。
プライバシーの問題を含む生成物を使用しないことも重要ですが、生成AIを使う場合に自身の個人情報を入力しないように注意することも重要です。各生成AIサービスには、ユーザの入力した質問やデータを再利用させない設定があることが多いため、サービスを使用する前に確認するようにしましょう。
企業活用の停滞
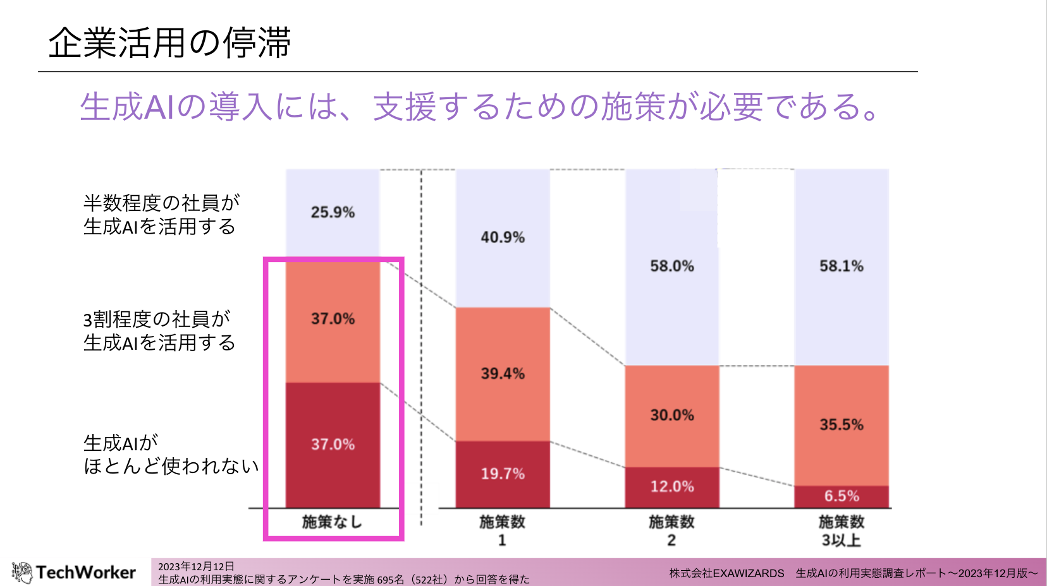
前述した課題などの影響もあってか、生成AIの企業活用は停滞しています。
未だニュースの尽きない生成AIですが、施策なしの状態では「社員の半数程度が生成AIを活用する」の割合が3割を下回っており、4割近くがほとんど使っていないとなっています。そのため、生成AIの企業活用を推進するには、導入を支援するための施策を打つことが重要です。
上記のスライドにあるとおり、施策の数が3つ以上の状態になると、「社員の半数程度が生成AIを活用する」の割合が6割まで上昇し、「生成AIがほとんど使われていない」の割合は1割以下となっています。
企業における生成AI活用推進の具体策
企業の生成AI活用が停滞している点について、導入を支援するための施策を打つことが重要と述べました。ここからは、具体的にどういうアクションを起こせば良いのかを見ていきましょう。企業が生成AIを導入する際には、3つのプロセスを適切に行うことが効果的であると言われています。
①チャンピオン(リーダー)の選出
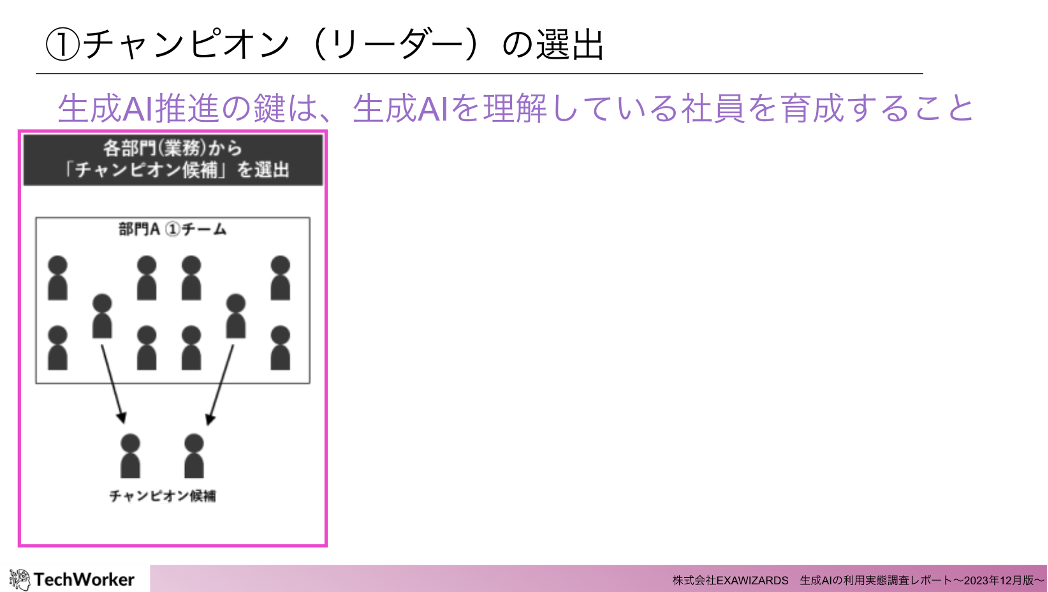
生成AIの活用を推進するためには、各部門、または業務を行うチームの単位で、生成AIを理解する社員を育成することが重要です。その最初のプロセスとして、リーダー候補を選出しましょう。部門(業務)ごとに課題は異なるため、現場の課題を理解する担当者から選出します。
もし生成AIに関心のある社員がいれば、その方が適任です。本人のモチベーションを尊重する形で、まずはその方を「リーダー候補」として選出しましょう。
※出典:株式会社EXAWIZARDS 生成AIの利用実態調査レポート〜2023年12月版〜
②ハンズオントレーニング

2つ目のプロセスは、社内の生成AIスペシャリストや、生成AIトレーニングを行う企業に頼むなどして、リーダー候補たちがハンズオン形式のサポートを受けることです。
ハンズオントレーニングでは、部門(業務)ごとの活用機会の洗い出しと、それに応じた有効なプロンプトの組み上げを行います。単純に有効なプロンプトの提供を受けるだけでは、業務に変更が生じた途端に生成AIの活用が止まってしまいます。業務に変更があった場合にも対応できるよう、リーダー候補を育て上げることが重要です。生成AIの根本原理を知り、中長期的に役立つ知識・スキルを身につけたリーダーを育てましょう。
③部門(業務)への還元
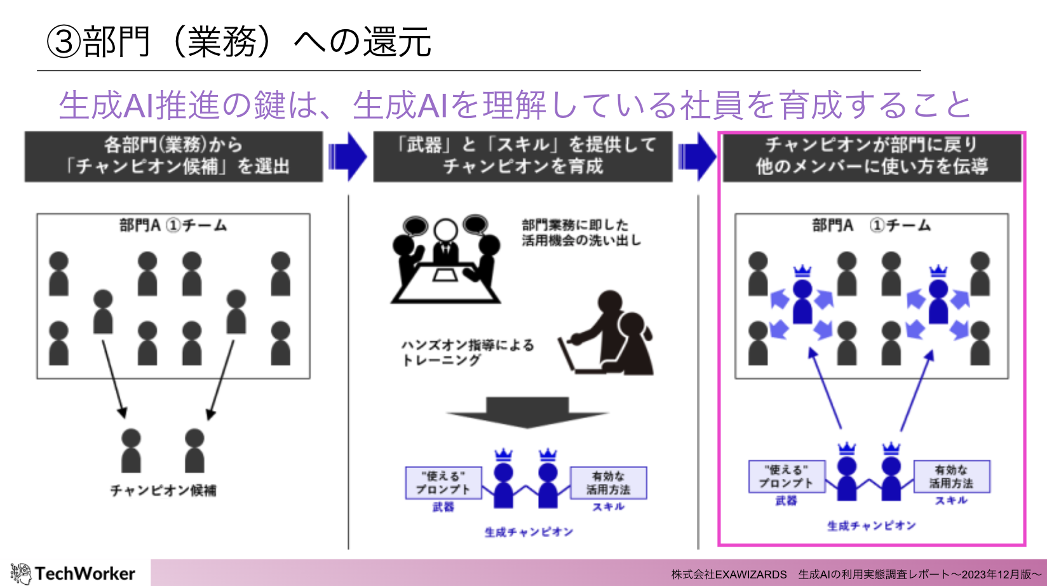
最後である3つ目のプロセスとして、生成AIの活用スキルを身に着けたリーダーが、部門(業務)全体で使えるように使い方を伝授します。リーダーが部門(業務)単位で存在する状態を作ることで、気軽に相談できる環境が構築できます。そうして、生成AIを日々の業務に多く組み込むことで、業務効率化のインパクトが最大化されます。
おしまい
いかがだったでしょうか?
全2回、ビギナー向け生成AIのキホン講座と題して、解説をさせていただきました。生成AIなどのディープテックと呼ばれる分野はどうしても難しそうなイメージが先行してしまいがちですが、この記事を読むことで少しでも興味を深めていただけると嬉しいです。
最後までお読みいただき、ありがとうございました!
TechWorkerについて
株式会社TechWorkerは、 生成AIを導入したけど"なぜか社内で活用されていない"を解決するために生成AIソリューションを法人向けに提供しております。具体的には、生成AIの適用可能な用途の特定、適切な生成AI手段の選定、ビジネス要件に合わせたカスタマイズ、そして従業員が新しい技術を効果的に利用できるようにするためのトレーニングを実施しています。
社内の生成AI人材育成をお考えの場合は、ぜひ株式会社TechWorkerにご相談ください!
記事協力
さくらインターネット株式会社 社長室
イノベーション共創グループ スタートアップチーム
新発田 大地