さくらのAI Engine ことはじめ(3):画像読み込みを実現させるマルチモーダルを試す


さくらのAI Engine とマルチモーダル
『さくらのAI Engine』は従量課金型のAPIで、様々な生成AIモデルを利用可能なクラウドサービスです。さくらのナレッジでも使い方をご紹介しています。
搭載されているモデルは、チャット補完、RAG用文書埋め込み、RAG検索、音声の文字起こしなどです。
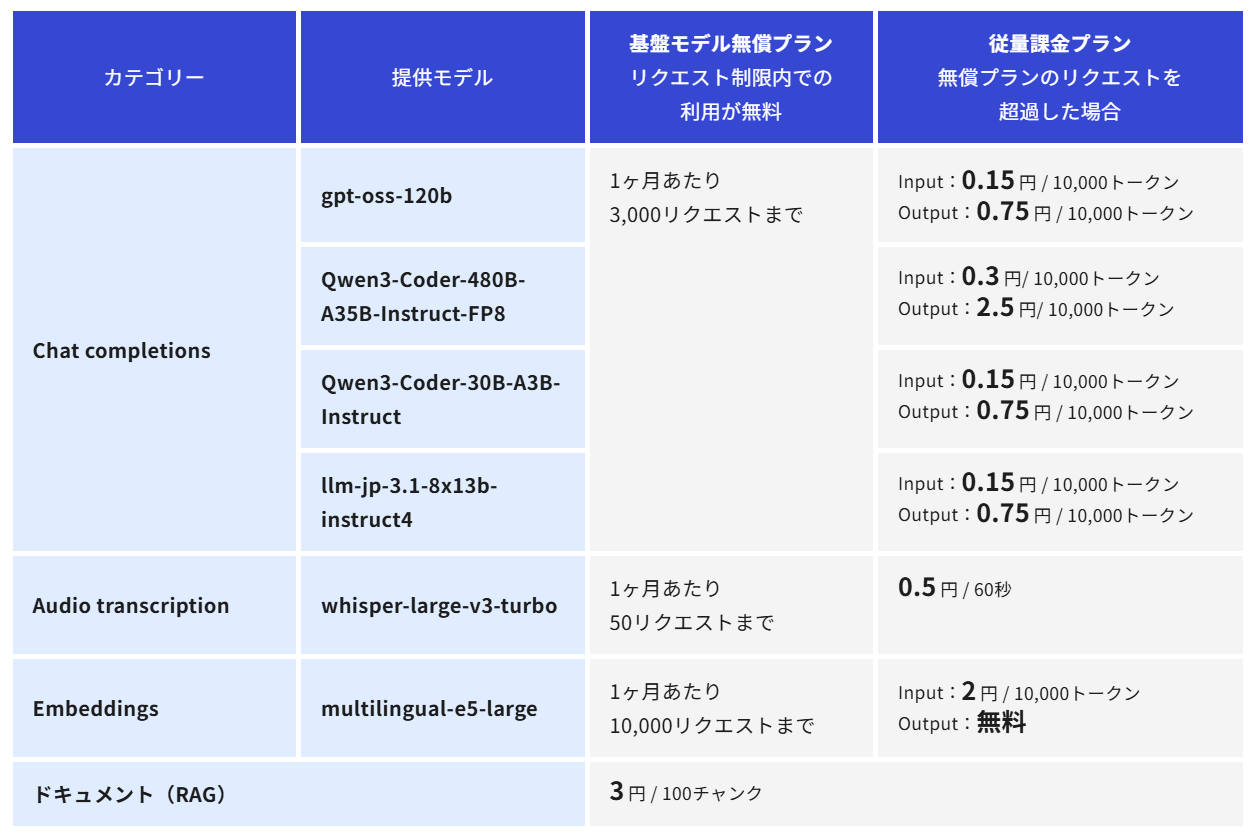
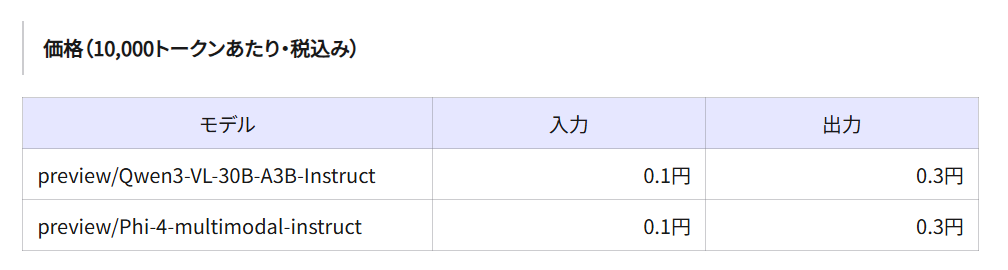
10月21日にプレビューとして新たに2つのマルチモーダルモデルを搭載しましたので、早速使ってみたいと思います。
マルチモーダル とは
マルチモーダルなLLMモデルとはテキスト以外の情報(画像、音声、動画、コード、センサー情報など)も理解・生成できる大規模言語モデル(LLM) のことを指します。テキストのみを扱うLLMモデルに対して、マルチモーダルなモデルでは複数の「モード(モダリティ)」を統合して処理することができます。
この複数のモードが存在しているというのがポイントです。画像処理を例にとると画像の中身を認識するだけではなく、そのまま言語モデルにつなげた処理が可能となります。
[入力画像/音声] → (1) エンコーダ → (2) テキストLLM → (3) デコーダ → [出力(テキスト/画像など)]
まず、エンコーダ(Encoder)が非テキスト情報を埋め込み化(ベクトル化)します。その後テキスト基盤のLLMが意味的推論を行った後、出力をテキスト以外の形式(画像・音声・動画など)に変換します。
このように一つのモデル内部で複数の処理が行われることが特徴です。ただしこれは一般的な説明でマルチモーダルのモデルがすべてこの機能を備えているわけではなく、それぞれ得意な領域というものも存在します。
Phi‑4‑multimodal‑instruct
この記事で試してみる Phi‑4‑multimodal‑instruct は入力として、テキスト/画像/音声 をサポートし、テキスト出力を行います。多言語対応が特徴であり、一つのモデルで以下の言語を処理できます。
テキスト入力
対応言語:
アラビア語、中国語、チェコ語、デンマーク語、オランダ語、英語、フィンランド語、フランス語、ドイツ語、ヘブライ語、ハンガリー語、イタリア語、日本語、韓国語、ノルウェー語、ポーランド語、ポルトガル語、ロシア語、スペイン語、スウェーデン語、タイ語、トルコ語、ウクライナ語画像入力(Vision)
対応言語:
英語音声入力(Audio)
対応言語:
英語、中国語、ドイツ語、フランス語、イタリア語、日本語、スペイン語、ポルトガル語
注意点としては画像入力(画像内の文字の読みとり)では日本語に対応していないことです。画像から日本語を読み取ることが必須の場合は、 Qwen3-VL-30B-A3B-Instruct の検証を行っていただくことを推奨します。公式には日本語読み取り対応は名言されていないものの、動作確認を行ったところ対応はしているようです。
さっそくやってみる
ではまず単純なチャットから行ってみます。余談ですが、LLMにおけるチャットコマンドの ‘chat completion` は日本語にするとチャットではなくチャット補完といいます。これはOpenAI APIがそうなっており実質デファクトとなっていますが、LLMではユーザーとアシスタントの対話構造から構成されており、あくまでもユーザー(人)の会話を補完するというコンセプトで チャット ではなく チャット補完 となっています。
まずは以下のコマンドを実行してみます。
curl -X POST "https://api.ai.sakura.ad.jp/v1/chat/completions" -H "Authorization: Bearer ${SAKURA_API_KEY}" -H "Content-Type: application/json" -d '{
"model": "preview/Phi-4-multimodal-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "あなたはだれですか?"
}
]
}
],
"temperature": 0.7,
"max_tokens": 1000,
"stream": false
}'以下の様なレスポンスが戻ってきます。
{
"id": "chatcmpl-cfa18bf9f4ac41c392a95d1a638114a0",
"object": "chat.completion",
"created": 1761901027,
"model": "preview/Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "私はアシスタントAIで、ユーザーの質問やタスクに関する支援を提供するためにここにいます。今日はどのようにお手伝いできますか?",
"refusal": null,
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [],
"reasoning_content": null
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": 200020,
"token_ids": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 10,
"total_tokens": 52,
"completion_tokens": 42,
"prompt_tokens_details": null
},
"prompt_logprobs": null,
"prompt_token_ids": null,
"kv_transfer_params": null
}ではいよいよマルチモーダルの神髄といえる画像解析を行ってみます。
curl -X POST "https://api.ai.sakura.ad.jp/v1/chat/completions" \
-H "Authorization: Bearer ${SAKURA_API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"model": "preview/Phi-4-multimodal-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "この画像について説明してください。"
},
{
"type": "image_url",
"image_url": {
"url": "https://knowledge.sakura.ad.jp/wp-content/uploads/2025/07/cropped-449652678_7709529589129107_2176919591431881016_n-192x192.jpg"
}
}
]
}
],
"temperature": 0.7,
"max_tokens": 2000,
"stream": false
}'このURLは以下の画像を指定しています。

結果として以下のようなレスポンスが返ってきます。
{
"id": "chatcmpl-f696f56ca7034271b3d7da7a94cea178",
"object": "chat.completion",
"created": 1761901824,
"model": "preview/Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "この画像は、ある男性がルーム内でのスピーキングシーンを描いています。男性は長い髪を白いシャツの上に包み、青色のネクタイを身に着け、青色の色合いのカラフルなライトが照らされた背景の前に立っています。彼は青色のカーテンに囲まれた黄色いテーブルの前に立っており、何かを緊張して握っているようです。テーブルの上には小さな黒いデバイスがあり、男性の右側にあるガラスの容器に置かれています。男性はピアノのように手を広げて話しているようで、明るい青色の背景の前を向いています。画像には明らかに緊張感があり、男性が興味深いために聴衆に向けて話していると推測できます。",
"refusal": null,
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [],
"reasoning_content": null
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": 200020,
"token_ids": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 555,
"total_tokens": 772,
"completion_tokens": 217,
"prompt_tokens_details": null
},
"prompt_logprobs": null,
"prompt_token_ids": null,
"kv_transfer_params": null
}
レスポンスにおけるcontentの部分に解析結果のテキストが格納されています。
"この画像は、ある男性がルーム内でのスピーキングシーンを描いています。男性は長い髪を白いシャツの上に包み、青色のネクタイを身に着け、青色の色合いのカラフルなライトが照らされた背景の前に立っています。彼は青色のカーテンに囲まれた黄色いテーブルの前に立っており、何かを緊張して握っているようです。テーブルの上には小さな黒いデバイスがあり、男性の右側にあるガラスの容器に置かれています。男性はピアノのように手を広げて話しているようで、明るい青色の背景の前を向いています。画像には明らかに緊張感があり、男性が興味深いために聴衆に向けて話していると推測できます。"
かなり細かい描写をしてくれていることがわかります(髪は長くないですけど💦)。
画像はbase64形式で以下の様に直接ローカルのファイルを読み込ませることも可能です。
curl -X POST "https://api.ai.sakura.ad.jp/v1/chat/completions" \
-H "Authorization: Bearer ${SAKURA_API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"model": "preview/Phi-4-multimodal-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "この画像について説明してください。"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,'$(base64 -w 0 sample.jpg)'"
}
}
]
}
],
"temperature": 0.7,
"max_tokens": 2000,
"stream": false
}'さいごに
今日はマルチモーダルのモデルを使って画像を読み取ってみました。『さくらのAI Engine』ではまだまだ対応モデルを増やしていきます。ご要望などございましたらお近くのさくら社員かX:@kameoncloud までお気軽にご連絡ください!