分散推論基盤の基礎技術 〜高火力 PHYで作る分散推論基盤 vol.2〜


目次
はじめに
さくらインターネットで高火力PHYのチームに所属している道下です。
本連載では、高火力 PHYで利用しているサーバーと同種のGPUサーバーを利用し、近年注目度を増しているLLMの分散推論基盤技術に関して詳細な技術調査や性能検証を行う中で獲得したナレッジを紹介しています。
前回の記事は連載の第1回目ということで、分散推論基盤に関する基本的な仕組みや考え方について紹介しました。今回の記事は、前回紹介した技術であるPrefill-Decode Disaggregation(PD-Disaggregation)における「KV Cacheの転送」に焦点を当てた記事になっています。まず、軽く前回のおさらいを行いつつ、KV Cacheの転送にまつわる技術について詳細に解説するとともに、ベンチマークの結果を共有しながら関連するソフトウェアの説明をしていきます。
前回のおさらい: LLMの推論処理とPD-Disaggregation
軽く前回記事のおさらいをしましょう。
LLMの推論処理は入力トークンをもとに新たなトークンを一つ生成する、というのが基本的な動作になります。生成されたトークンを入力系列の末尾に付け加え、同様の処理を繰り返すことで、最終的に我々がChatGPTなどのシステムから受け取るような文章になります。
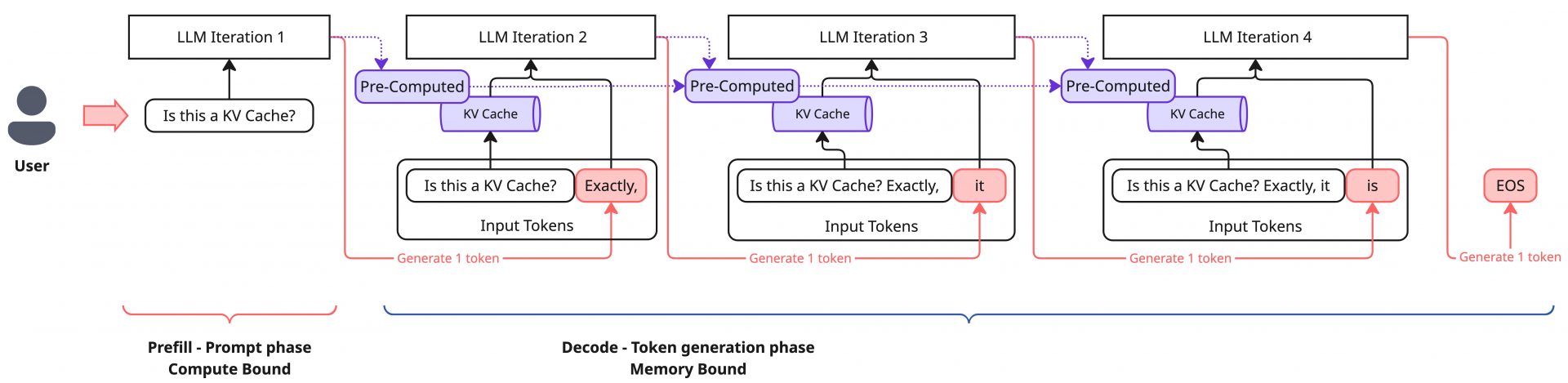
ユーザーからのリクエストに対して、初回の処理では入力内容に対しての計算を行いますが、同時にKV Cacheと呼ばれる計算結果のキャッシュが生成されます。以降の処理ではこのKV Cacheを読み込むことで、処理済みの入力トークンに関しては計算が省略でき、高速なトークン生成が可能になります。一方でこれは、計算にかかる処理よりも、KV Cacheの読み込みなどのメモリー操作が処理の支配要因になる特徴があります。そのため、初回処理とそれ以降の処理でボトルネックが明確に変化し、前者のCompute Boundな処理をPrefill、後者のMemory Boundな処理をDecodeと呼びます。
そして、近年の分散推論基盤では、このPrefillを行うGPUとDecodeを行うGPUをそれぞれ分けて処理するという構成が取られるようになり、Prefill-Decode Disaggregationと呼ばれているのでした。
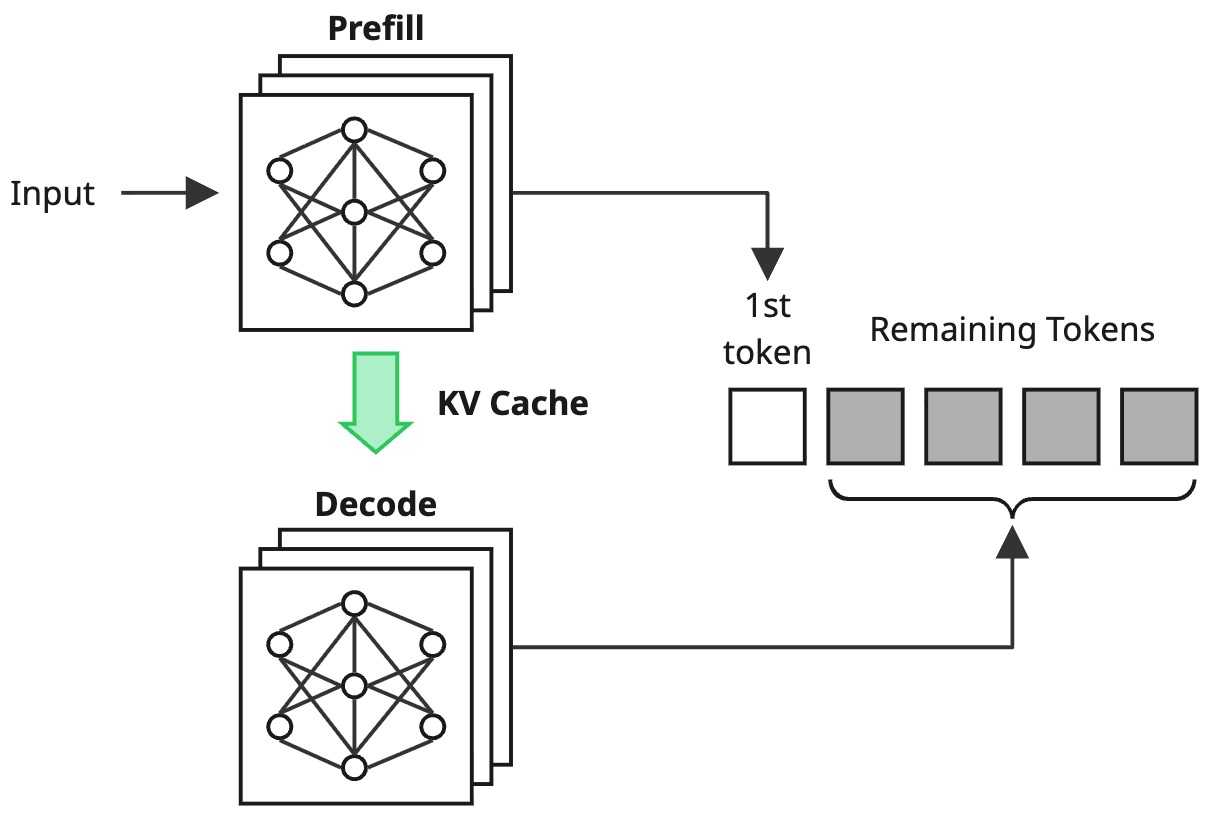
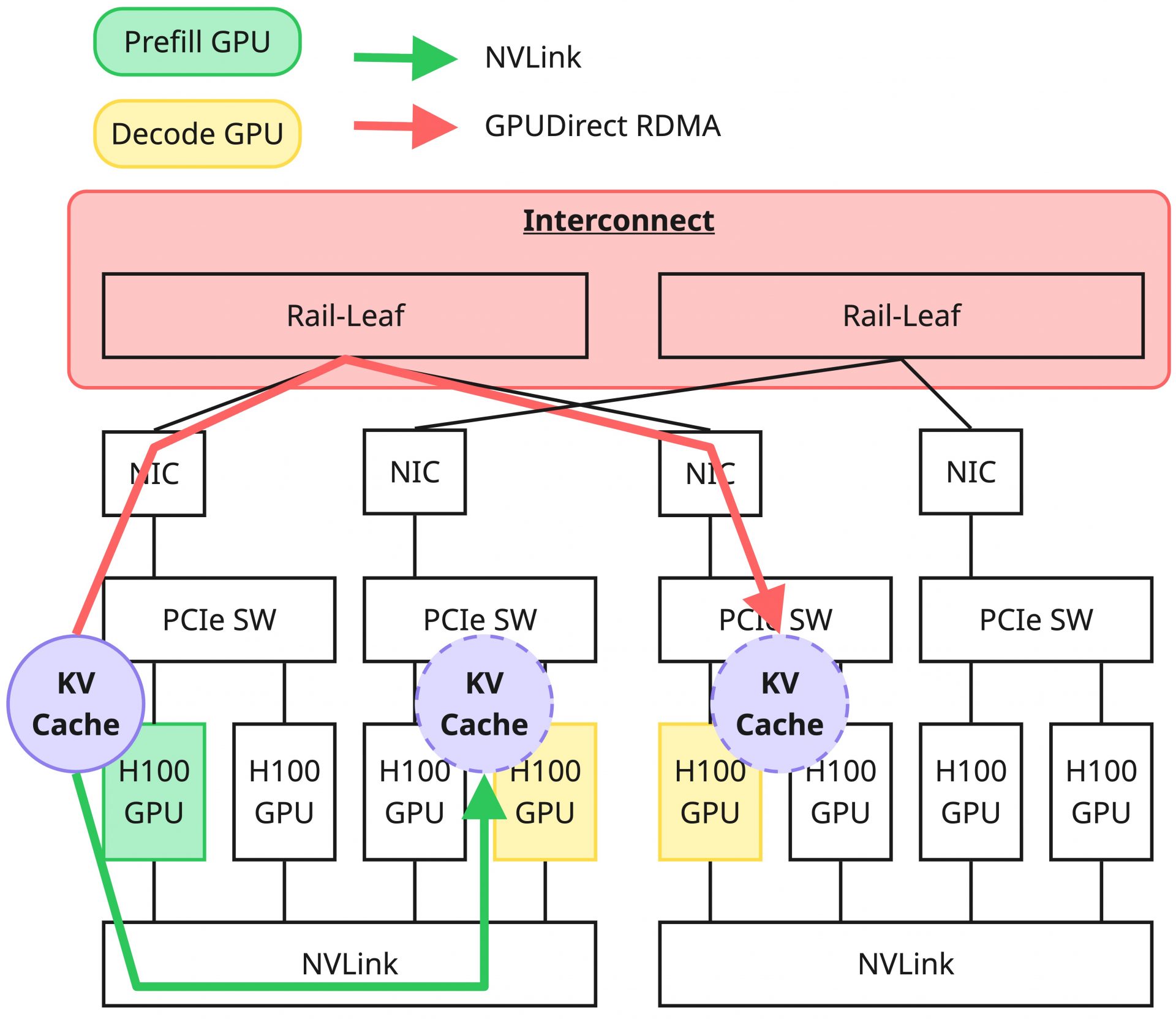
ただしこの構成は、Prefill処理を行ったGPUからDecode処理を行うGPUに対してKV Cacheを転送する必要があり、このKV Cacheのデータサイズが現実的にリクエストあたり数GB以上のデータとなりうるため、高速転送するためのインフラが必要であることを紹介しました。
あるGPUメモリーから別のGPUメモリーへのデータ転送は、対象のGPUが同一ノード上にあるか、それともノードを跨いでいるかによって、関わってくる技術やインフラへの要求が大きく変化します。
以降では、改めて推論処理におけるデータ転送の複雑性について触れたうえで、Scale Up NetworkやScale Out Networkについて順番に説明していきます。
GPU間データ通信とScale Up / Out Network
推論におけるGPU間データ転送
先ほどの図はあくまで単純化したKV Cacheの転送に着目したものであり、実際の推論処理におけるデータ転送はもっと複雑です。本記事の主眼はあくまでKV Cacheの転送ではあるものの、推論基盤におけるデータ転送はこれのみを考えればよいというものではありません。誤解をなくすために簡単にですが触れておきます。
近年のモデルはパラメータが数100Bというレベルのものが登場しており、これらは単一GPUのメモリーに乗り切らないケースもあるため、複数のGPU、場合によっては複数のノードを利用して起動させる必要があります。このとき、当然ながら複数GPU、複数ノード間でのデータのやりとりが発生することになります。これはKV Cacheの転送ではなく、純粋に推論処理の演算を複数のGPUに分割することで発生するものです。
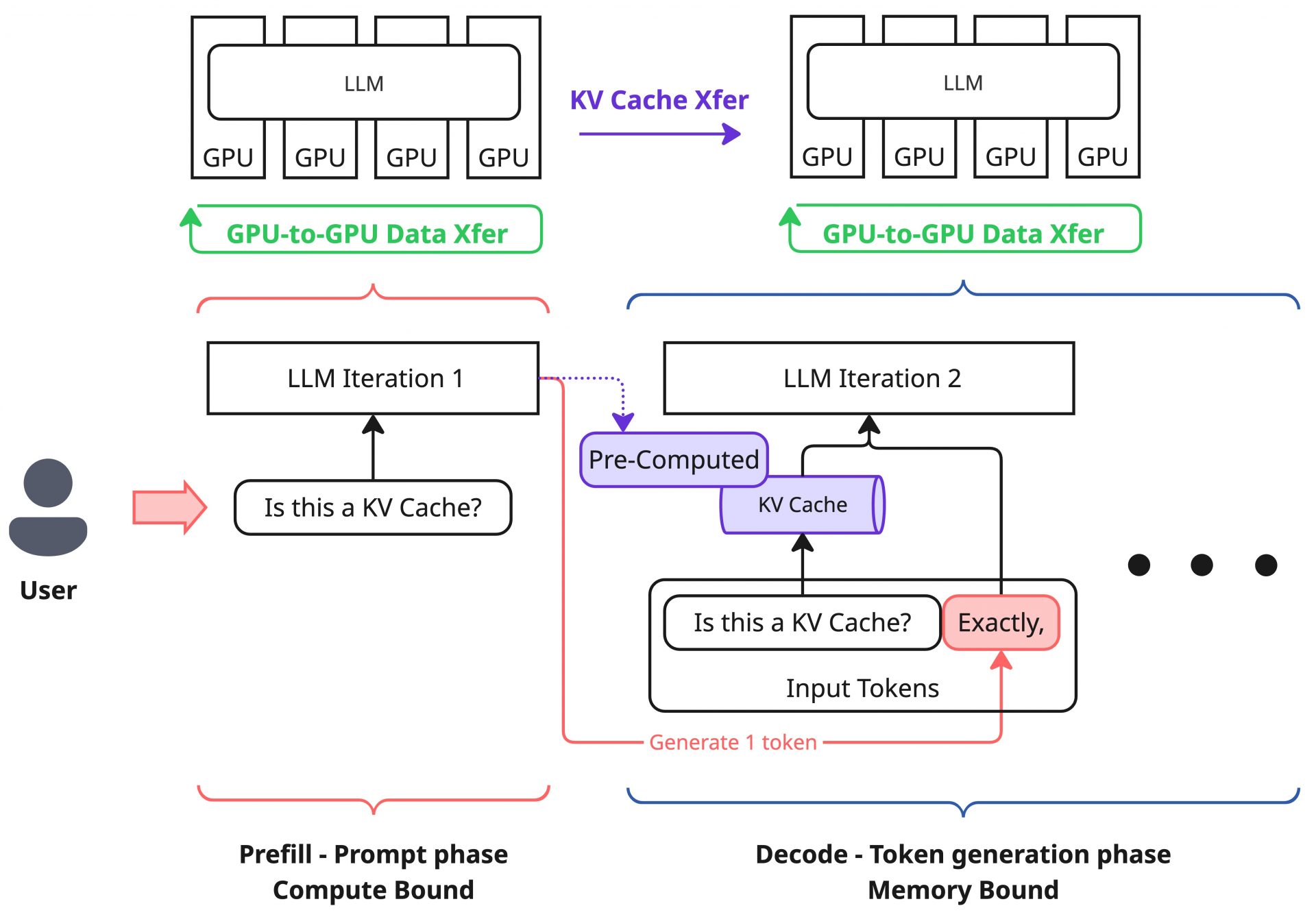
このとき発生する通信は、モデル起動時に採用する並列化の方式に依存し、選択した方式次第で通信パターンが変化します。近年では複数の並列化方式を組み合わせることも多く、GPU間のデータ通信パターンは非常に多様になっています。
このような状況においてインフラ側で考慮するべき重要な点として、いかにして通信のボトルネックを作らないようにするかがあります。これを考える上で、以降ではScale Up NetworkとScale Out Networkについて説明します。
Scale Up Network
Scale Up Networkは、主にサーバー内(*)においてXPU(本記事ではGPUと読み替えてよい)を相互接続する高速なデータ転送路のことです。広く知られているソリューションでいうとNVIDIA社のNVLinkがこれに該当し、UALink(Ultra Accelerator Link)やSUE(Scale Up Ethernet)などもこれに該当します。
(*)近年ではラックスケールソリューションとして同一ラック上でScale Up Networkを構成する製品が存在しています。そのため「サーバー内」という説明はすでに適切ではなくなってきています。
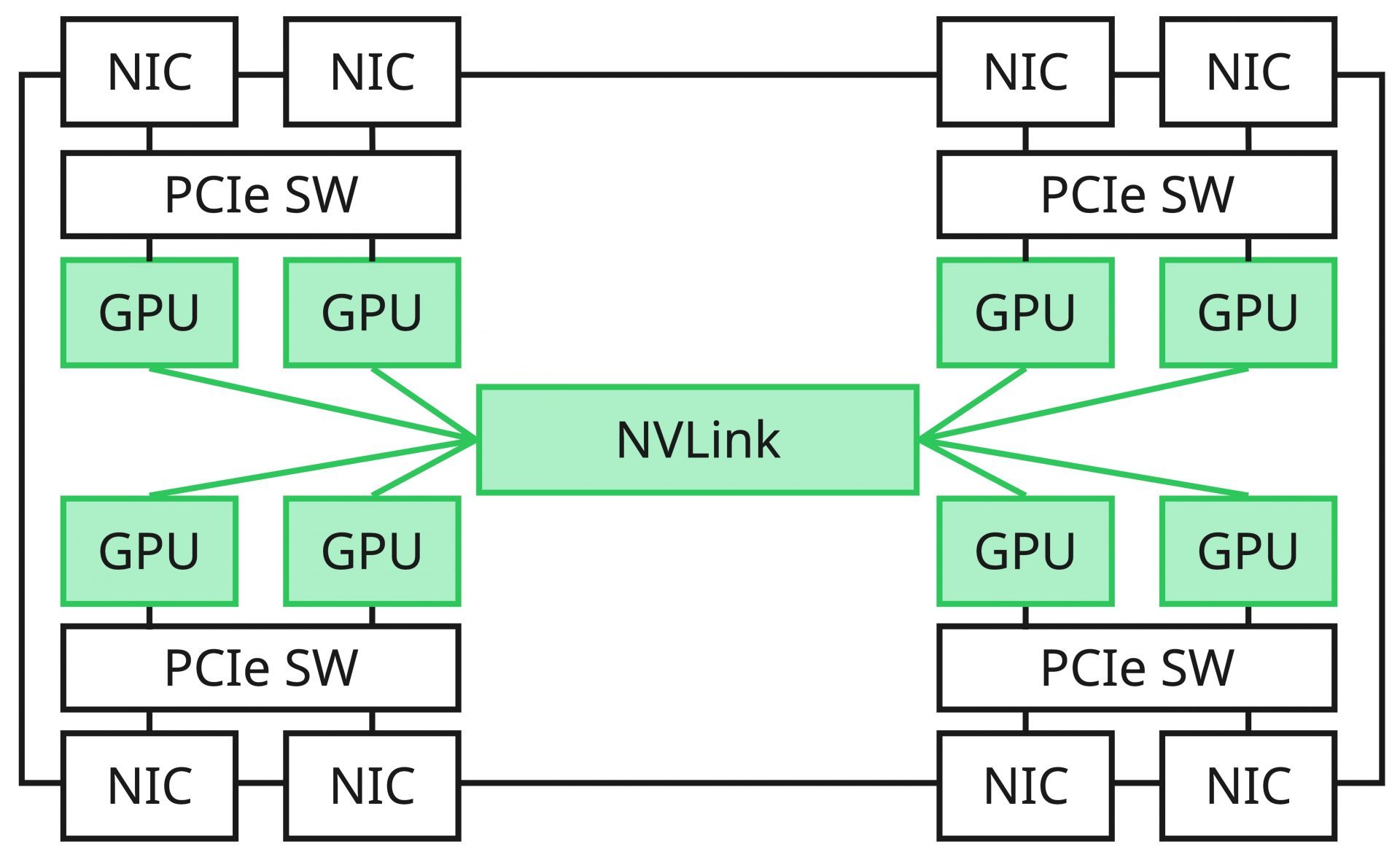
通常、サーバーの内部バスとして一般的にはPCIeが利用されますが、XPU間の高速なデータ転送という要求に対して、帯域の問題、接続数の問題、機能の問題(メモリーコヒーレンシなど)から、現状は必ずしも最適なバスであるとはいえない状況です。例えば、NVIDIAのNVLinkとPCIeを比較すると次のように大きな性能差が存在しています。
| 伝送経路 | 最大伝送速度(1XPUあたり) | 備考 |
|---|---|---|
| PCIe Gen5 | 64 GB/s(x16, 単一方向) | 1レーンあたり4GB/s |
| PCIe Gen6 | 128 GB/s(x16, 単一方向) | 1レーンあたり8GB/s |
| NVLink 4.0 | 400 GB/s(18 Links, 単一方向) | Hopper, 1リンクあたり25GB/s |
| NVLink 5.0 | 900 GB/s(18 Links, 単一方向) | Blackwell, 1リンクあたり50GB/s |
基本的に特定のノード上のXPU間の通信はScale Up Networkを通すのが最も良い形と言えます。これを実現する方法は現状それぞれのGPUベンダーが提供するエコシステムに依存し、NVIDIAの場合はCUDA、AMDの場合はROCmによって実現されます。
Scale Out Network
Scale Out Networkは、Scale Up Networkを効率的にノード外に延伸しようとした結果生まれたものです。異なるノード間のXPU同士のデータ転送を高速に行うための高帯域・低遅延なネットワークのことであり、一般には「GPUインターコネクト」などがこれに該当します。
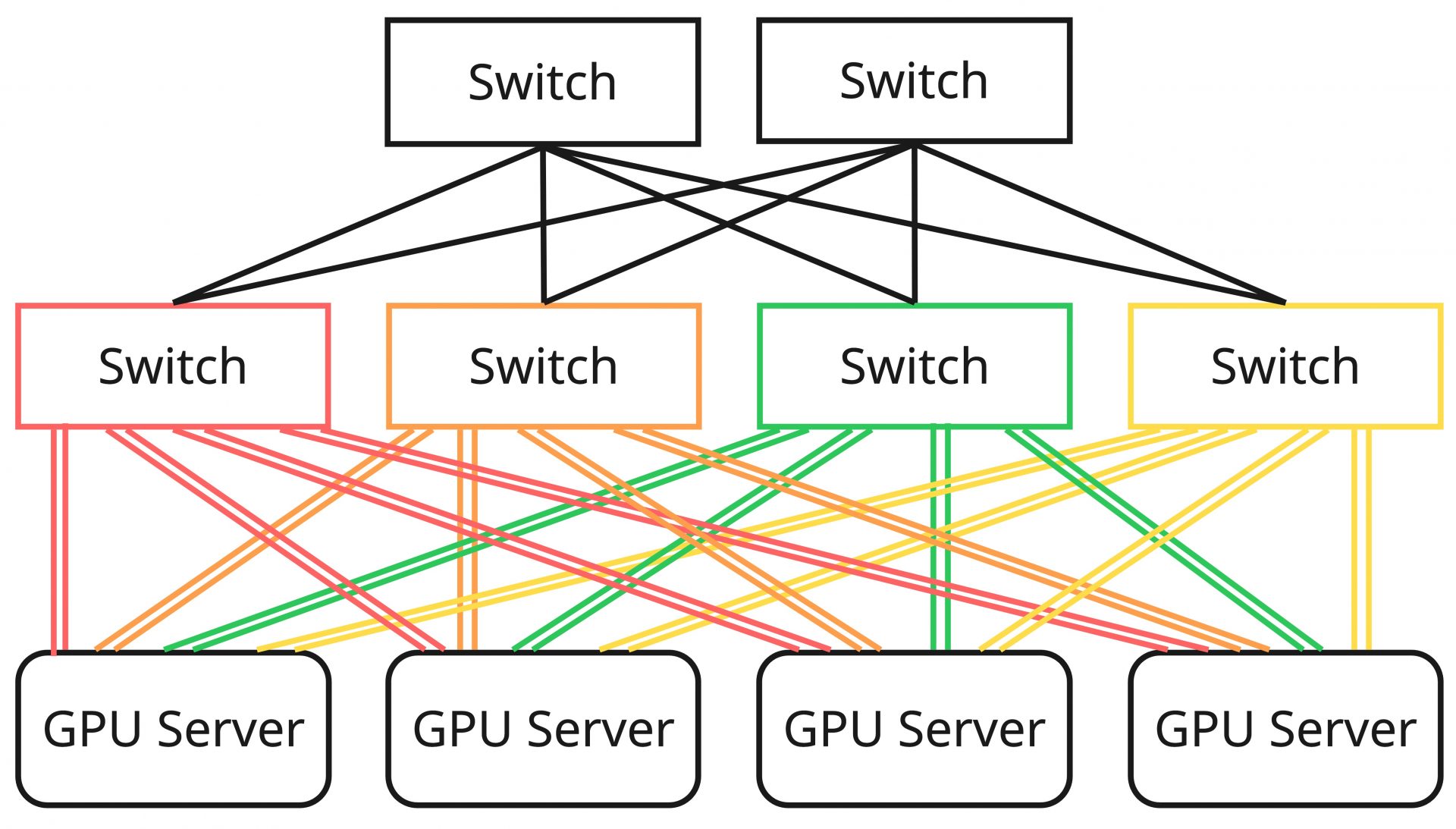
Scale Out Networkはノード外にまたがるXPU間の通信を高速に行うことを目的としているため、従来とは異なるトポロジーとなるケースが多く、その設計はサーバー内部のScale Up Networkの構成に依存します。また、広帯域・低遅延を実現するためにRoCEv2などのプロトコルの利用、ロスレスを実現するための輻輳制御アルゴリズム、AIワークロード特有のトラフィック傾向に対応するための負荷分散技術など、数多くの技術的要素によって実現されるものがあり、それぞれの内容を正しく把握しコントロールすることが要求されます。Scale Out Networkを構成する技術はどれをとっても奥が深いことと、本記事の趣旨からはやや外れるため割愛しますが、もし興味がある方は、弊社の小林正幸が作成した以下の資料などを参考にしていただけるとよいかと思います。
現在、Scale Out Networkで利用されるインターフェイスの帯域は400Gbps(これがXPUの枚数分搭載されるため、8XPUの場合はノードあたり3.2Tbps)に達します。一方で、Scale Up Networkの延伸という前提に立ち返ると、これらの性能はまだまだ不十分です。この事実が業界的な推進力にもなっており、今後はさらに高帯域なものが現れてくることも既定路線となっています。
一方で、このScale Out Networkを利用するサーバーやアプリケーションの視点に立って考えてみましょう。このようなインフラを最大限活用するためには、サーバーにおける設定やチューニング、場合によってはライブラリの選択やアプリケーションレベルの調整が必要になります。設定不備がある場合に十分に性能を出し切ることができないというケースは事実として多く存在しており、そのようなケースにおいてはインフラへの高価な投資が無駄になってしまう可能性があります。そのため、「どのような仕組みで効率の良いデータ転送が実現されているか」を理解しておくことが重要です。さらに、システムが想定した性能を実際に達成できているかを測定して確認することも欠かせません。
以降ではまず、Scale Out Network上でGPU間のデータ転送を高速に行う技術の中核であるGPUDirect RDMAに関してやや詳細に踏み込んで解説します。その後、このGPUDirect RDMAを土台として利用するソフトウェアのうち、本記事の趣旨であるKV Cacheの転送に関わるものとしてUCXとNIXLについて紹介し、実際にこれらを利用したデータ転送性能の実測を行った内容を共有します。
GPUDirect RDMA
この節では、GPUDirect RDMAを「MOFED + PeerDirect」と「Linux kernelのdma-buf」の2系統から整理し、サーバーセットアップとアプリケーション実装の両方の観点で何が要求されるかを整理します。
GPUDirect RDMAの概要
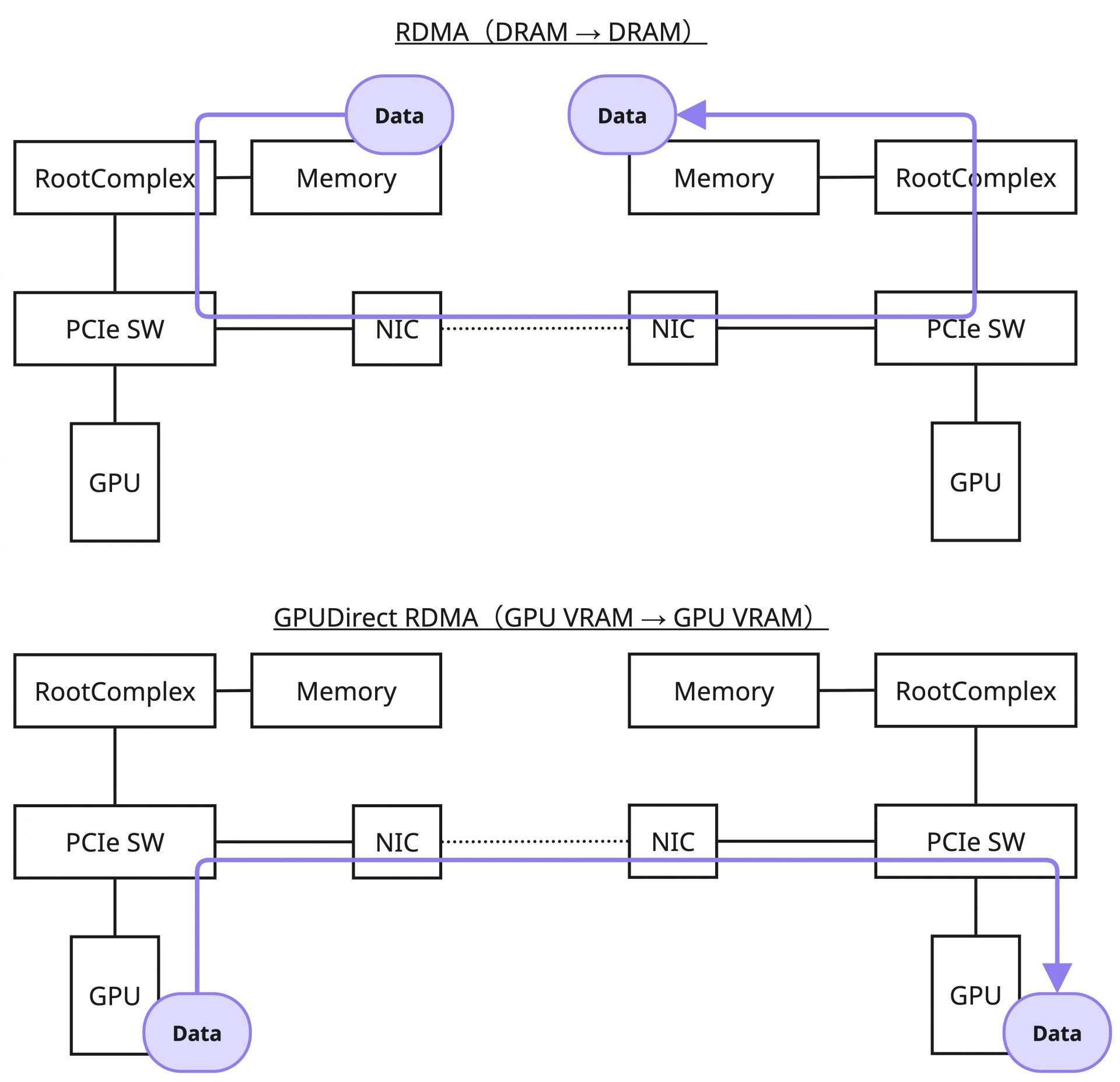
GPUDirect RDMAは、RDMAをベースとしてGPUメモリー上のデータをメインメモリー(バウンスバッファ)を介さずにリモートのGPUメモリーに直接転送する技術です。RDMAがメインメモリー間の直接転送技術であったことと比較すると、GPUDirect RDMAはGPUメモリー間の直接転送技術となります。
はじめに、今回の説明の中で登場する語彙について整理しておきます。
| 語彙 | 意味 |
|---|---|
| libibverbs | InfiniBand/RoCEを取り扱うためのユーザースペースライブラリ |
| ib_core.ko | InfiniBand/RoCE向けのカーネルオブジェクト |
| nvidia.ko | NVIDIAのGPUを操作するためのカーネルオブジェクト |
| MOFED | NVIDIA(旧Mellanox)のInfiniBand/RoCE対応のインターフェイス用ドライバパッケージ MLNX_OFED、もしくはDOCA-OFEDの略称として利用 |
GPUDirect RDMAについて理解するモチベーションとしては主に以下があります。
- サーバー内部のセットアップとして「なぜそれが必要か?」を詳細に把握できるようになる。これは単純に設定漏れの防止にとどまらず、想定したパフォーマンスが発揮できない場合のトラブルシューティングなどの足がかりにもなる。
- GPUDirect RDMAを実施するためのアプリケーションへの要求を知ることができる。これはどのライブラリ、フレームワークが実装しているかや、要求されるソフトウェアバージョンなどの詳細を把握する手がかりとなり、ソフトウェアスタックに対しての解像度が上がる。
- GPUDirect Storage、GPUDirect Async(GPU-Initiated Communication)の理解へ繋げるためのステップになる。
GPUDirect RDMAを単に利用すること自体はそこまで難しい話ではありませんが、インフラ・プラットフォームを提供する立場として、これらがどのような技術要件のもとで成立しているかを正しく把握しておくことは重要だと考えています。
以降では、具体的にGPUDirect RDMAの詳細について踏み込んでいきますが、この成り立ちはNVIDIA(旧Mellanox)のドライバであるMOFEDとNVIDIAのGPUの間でのサポートに始まり、後にLinux kernelでもサポートされるようになったという歴史的経緯があるため、実現方法は現時点で大きく2種類存在しています。
本記事ではそれぞれ順番に紹介したのち、簡単にまとめるという形式で進めます。
GPUDirect RDMA: MOFEDにおける実装(レガシー方式)
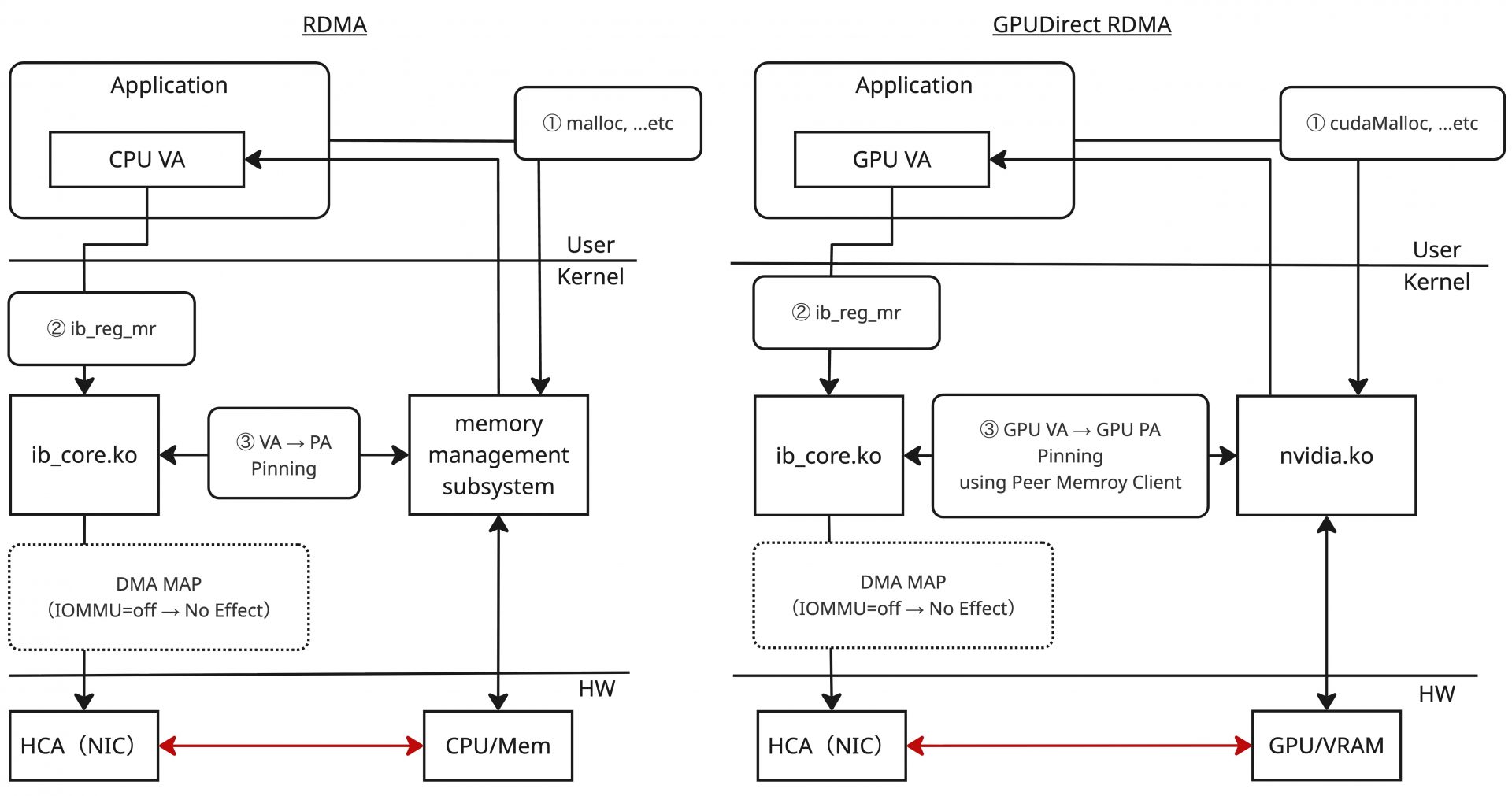
GPUDirect RDMAの詳細を説明する前に、まずは通常のRDMAの処理について整理します。以下の図は、RDMAの処理について、ユーザースペース、カーネルスペース、ハードウェアの3層に分けて大まかに記載しています。
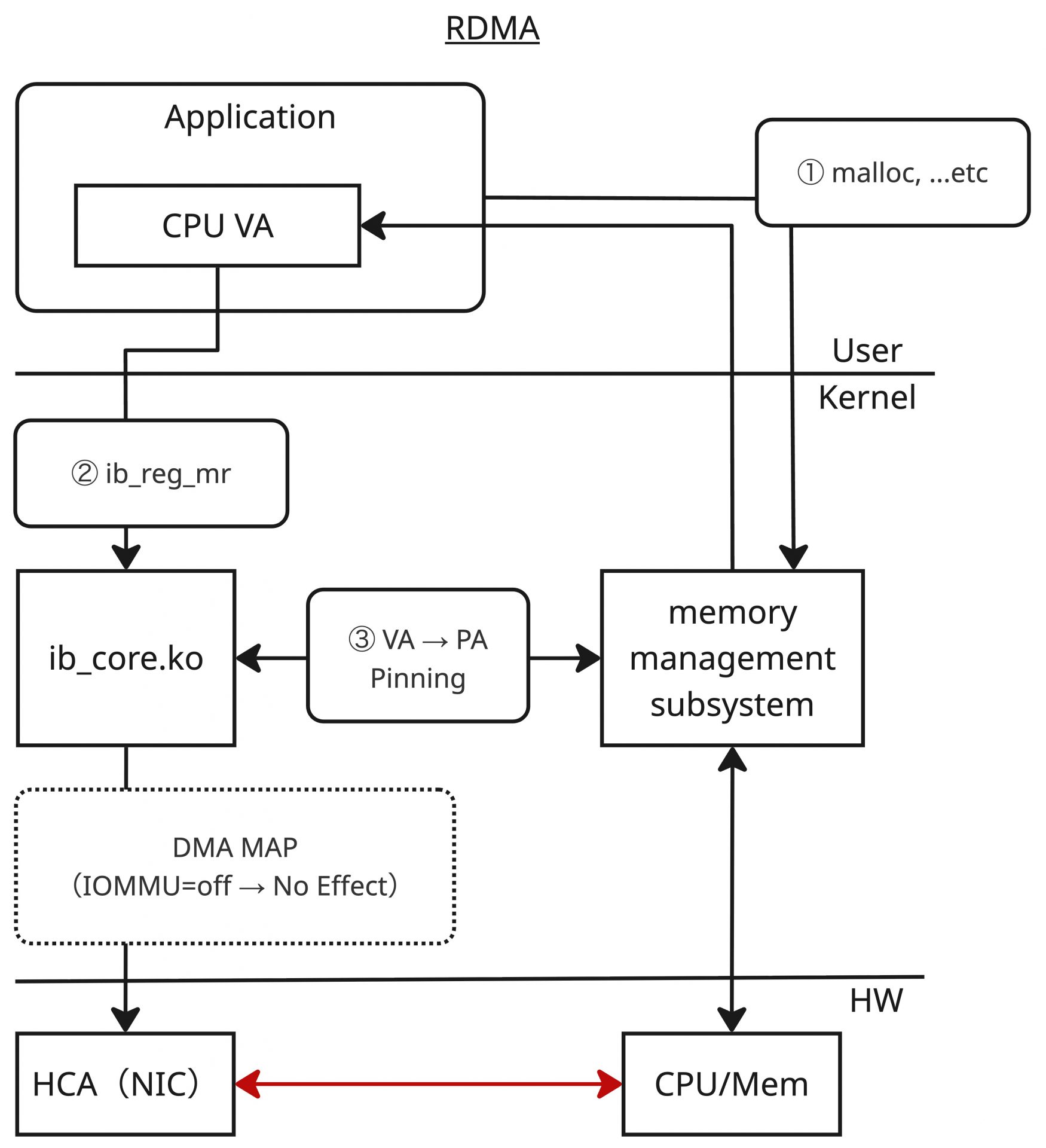
通常のRDMAの場合、アプリケーションで確保したメインメモリー(正確には仮想アドレス、①)を、libibverbsが提供するib_reg_mr関数によってMemory Regionとして登録します(②)。ib_reg_mr関数に渡された仮想アドレスが指す領域は、メモリーからスワップアウトされないようにPinningされた上で、その物理アドレスが取得されます(③)。このアドレスをDMA実行向けにバスアドレスへ変換(IOMMUを無効にしている場合は恒等変換)し、HCA(RDMAの文脈でのNIC)に登録するというのがRDMAの処理の概要になります。
次にGPUDirect RDMAの処理について類似の図を以下に示します。
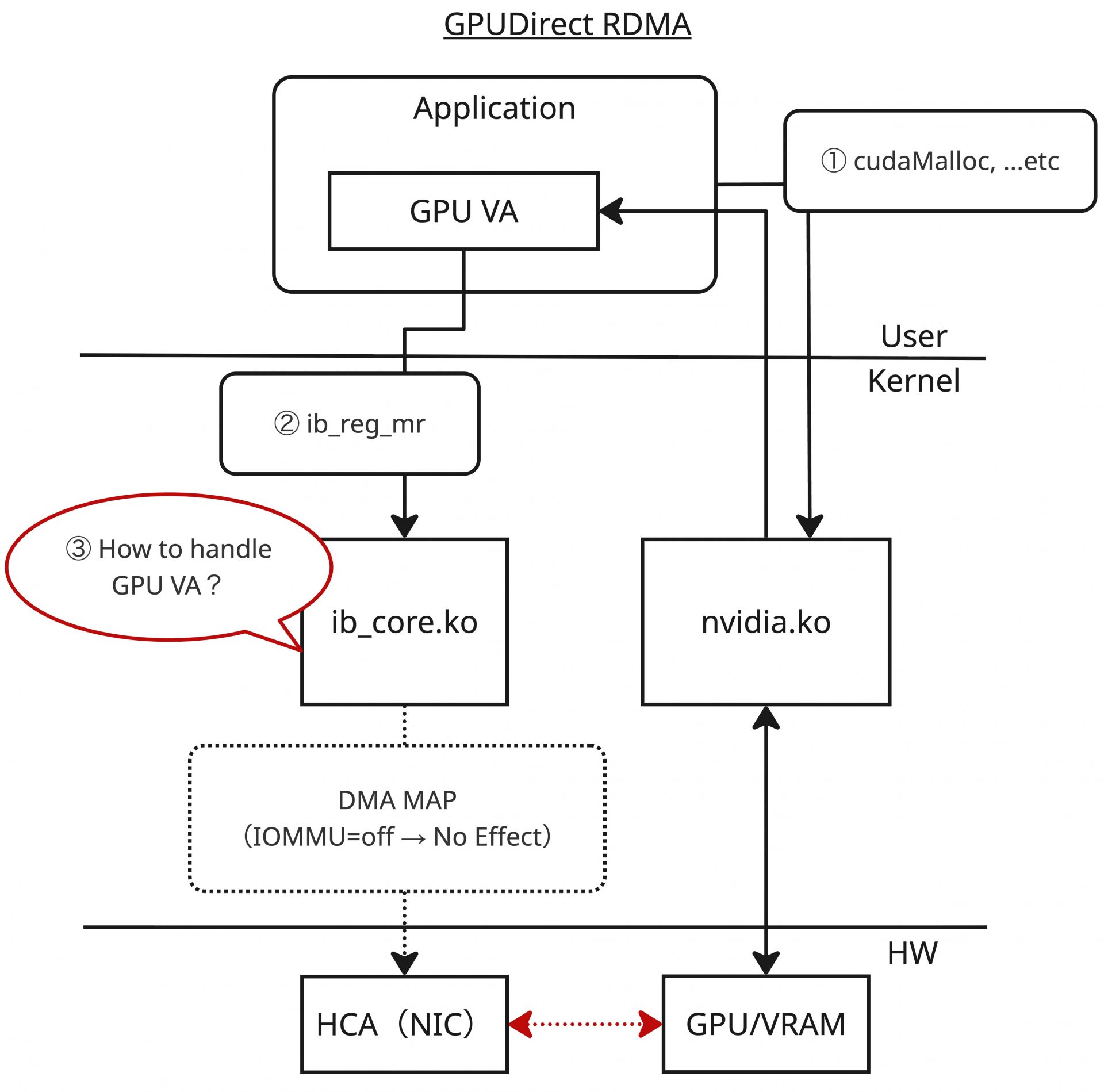
通常のRDMAの処理と同様にGPUDirect RDMAについて考えてみると、アプリケーションで「GPUメモリー」を確保し(①)、ib_reg_mrのような関数に渡すことで登録する(②)、というのが順当に思いつく仕組みになります。さらにGPUメモリーの確保は、アプリケーションからはCUDA API(cudaMallocなど)を利用して実施可能であるため、それを利用すれば良さそうだということも想像できます。実際、MOFEDで提供されるib_coreおよびlibibverbsでは、まさにこの手続きをアプリケーションレイヤーから実施する形になります。
一方、CUDAを経由して得られるGPUのメモリー領域はGPUメモリーの仮想アドレス(GPU VA)であり、DMAのためにはこのGPU VAからGPUメモリーの物理アドレス(GPU PA)を操作できる必要があります(③)。通常のRDMAではこの部分はカーネル内で解決できますが、GPUメモリーに対しては何かしらの手段で解決する必要があります。ユーザースペースからは見えませんが、通常のRDMAとGPUDirect RDMAで大きくギャップのある部分です。これを解決するために、MOFEDに同梱されるib_coreではこのGPU VAからGPU PAを操作する処理をnvidia.koとの連携(nv-p2p APIの利用)によって実現しています。
しかし、ib_coreに直接この連携の実装を組み込むのは汎用性に欠けます。例えば、NVIDIAのGPUのみでなく、AMDのGPUで同様のことを達成する場合は、AMD版の同種の処理をib_coreへ組み込むことになるでしょう。当然、それ以外に類似のアクセラレータなどに対応する場合も同じことを考える羽目になるため、好ましくありません。そのためMOFEDのib_coreでは、PeerDirectと呼ばれる抽象化の仕組みが実装されています。PeerDirectでは、ib_coreとPeer Memory Clientと呼ばれるクライアントの間のAPIを規定し、サードパーティデバイスのメモリー操作をib_coreから分離しています。
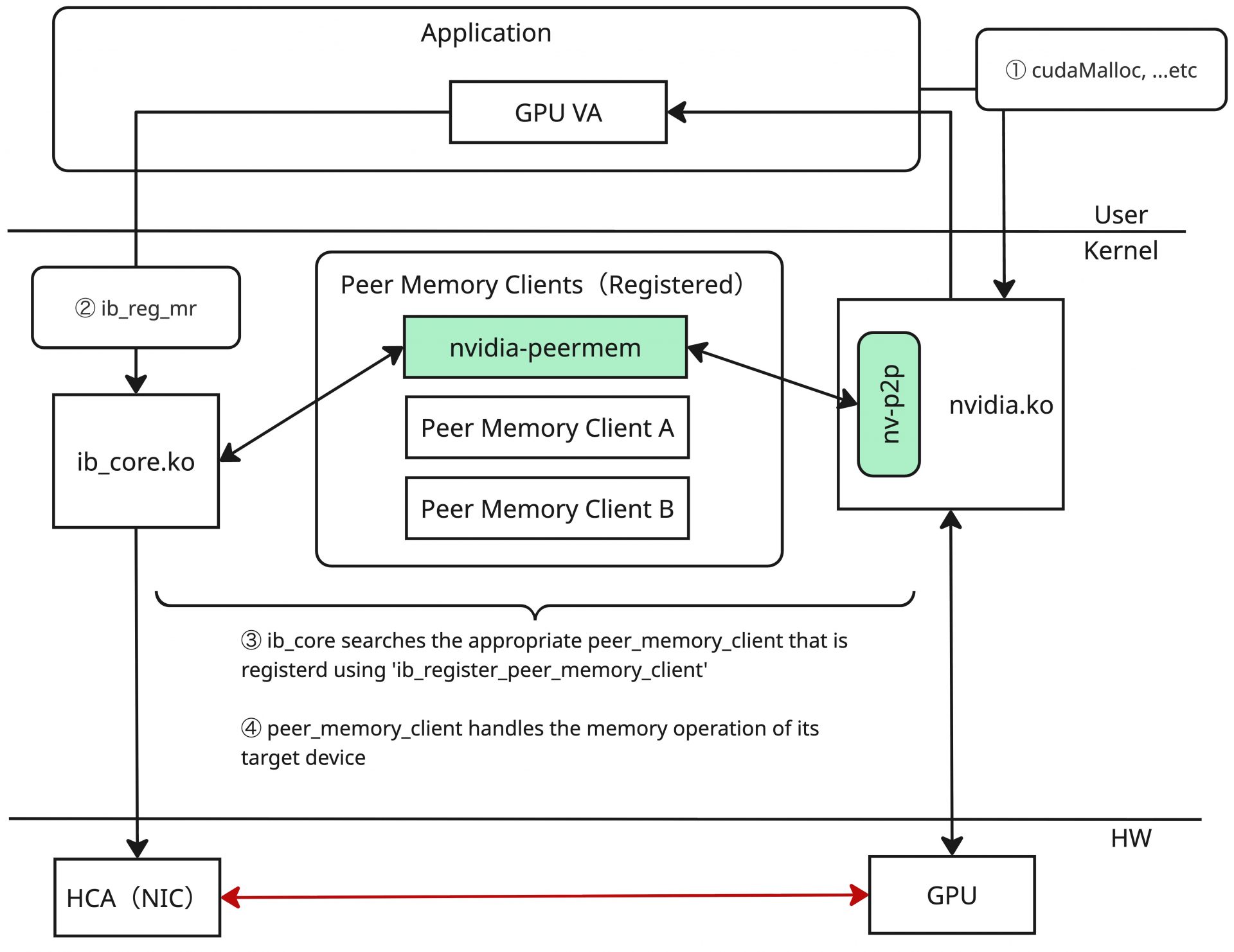
Peer Memory Clientはコード上の実態としてはサードパーティデバイスのメモリー操作に関わるCallbackを提供するための構造体になっており、ib_coreではこの構造体を登録・解除する実装(ib_register_peer_memory_client / ib_unregister_peer_memory_client)を提供しています。あるデバイスに対するPeer Memory Clientが登録された状態で、メインメモリー以外のメモリーをib_reg_mrで登録しようとすると(①~②)、ib_coreは登録済みのPeer Memory Clientを走査し、そのメモリーに対応するClientが存在するか確かめます(③)。もし見つかればそのClientにメモリー操作に関する処理を委譲し、メモリーのPinningなどRDMAに必要な処理が実施されます(④)。
なお、このPeer Memory ClientについてはPFNの上野裕一郎さんの記事にも詳細な記載がありますので、気になる方は合わせて読まれることを推奨します。
例えば、NVIDIAのGPUに対しては、nvidia-peermemがPeer Memory Clientの実装を含んだカーネルオブジェクトです。これはメモリーを操作する処理の中でnv-p2p APIの関数を呼び出し、必要な処理をGPUメモリーに対して行うような実装になっています。またこのカーネルオブジェクトはmodprobeを契機としてib_register_peer_memory_clientを呼び出し、自身をPeer Memory Clientとして登録するように実装されています。NVIDIA GPUでGPUDirect RDMAのセットアップを行ったことがある人は、このカーネルオブジェクトをmodprobeで読み込む手続きを踏んだことがあると思いますが、これによってPeer Memory Clientとして登録され、GPUDirect RDMAが実現されていたわけです。
PeerDirectの抽象化によって、あくまでib_core側にはインターフェイスの定義と登録・解除、およびCallback呼び出しの枠組みだけを実装し、デバイスのメモリー操作に関する実装はPeer Memory Clientという形でデバイスやデバイスドライバの開発者に委ねられるため、実装の責任範囲が明確になったという見方もできるでしょう。
改めて、通常のRDMAとGPUDirect RDMA処理を比較した図を以下に示します。カーネル内部の連携によって、ユーザーアプリケーションは確保するメモリーについて意識するだけでGPUDirect RDMAが実現可能な仕組みになっています。
GPUDirect RDMA: Linux kernelの実装(推奨方式)
上記で説明したPeer Memory ClientによるGPUDirect RDMAですが、結果的にこの方式はアップストリームのLinux kernelでは採用されませんでした。理由として大きいのは、P2P DMAというRDMAデバイスに限られないものがRDMAサブシステムで実装されてしまっているという点でした。他のサブシステム上でP2P DMAを実現したい場合に再利用が難しい課題や、メモリー管理の問題を特定のI/Oサブシステムに実装すべきではないという議論が起きたようです。
結果的に、Linux kernelコミュニティーはdma-bufを利用して実現する方針を採用し、最終的に5.12で機能として追加されました。dma-buf自体はLinuxの3.3で導入された仕組みであり、デバイスドライバやサブシステム間でハードウェアアクセス用のバッファを共有するためのフレームワークを提供します。dma-bufは汎用的で標準的なフレームワークであり特定のサブシステムに依存していないこと、すでにGPU(グラフィック用途)やその他のマルチメディアでの実績があること、ファイルディスクリプタベースでありユーザースペースフレンドリーであること、十分な柔軟性があることなどから、Linux kernelでのGPUDirect RDMA実装のベースとして適切と判断されたようです。
dma-bufでは、メモリーバッファを提供するExporterと、提供されたメモリーバッファを利用するImporterという二つの役割があります。GPUDirect RDMAのシナリオでこれを考えた場合、Exporterに該当するのがGPU driver(nvidia.ko)、Importerに該当するのがRDMA driver(ib_core.ko)ということになります。Exporterはメモリーバッファをdma-bufオブジェクトという形でエクスポートし、ユーザースペースにはそれに対応するファイルディスクリプタを提供します。Exporterは合わせてdma_buf_opsと呼ばれる構造体にCallbackを実装している必要があります。Importerは、ファイルディスクリプタをもとにdma_buf_opsのCallbackを呼び出し、バッファの操作を行うことができます。
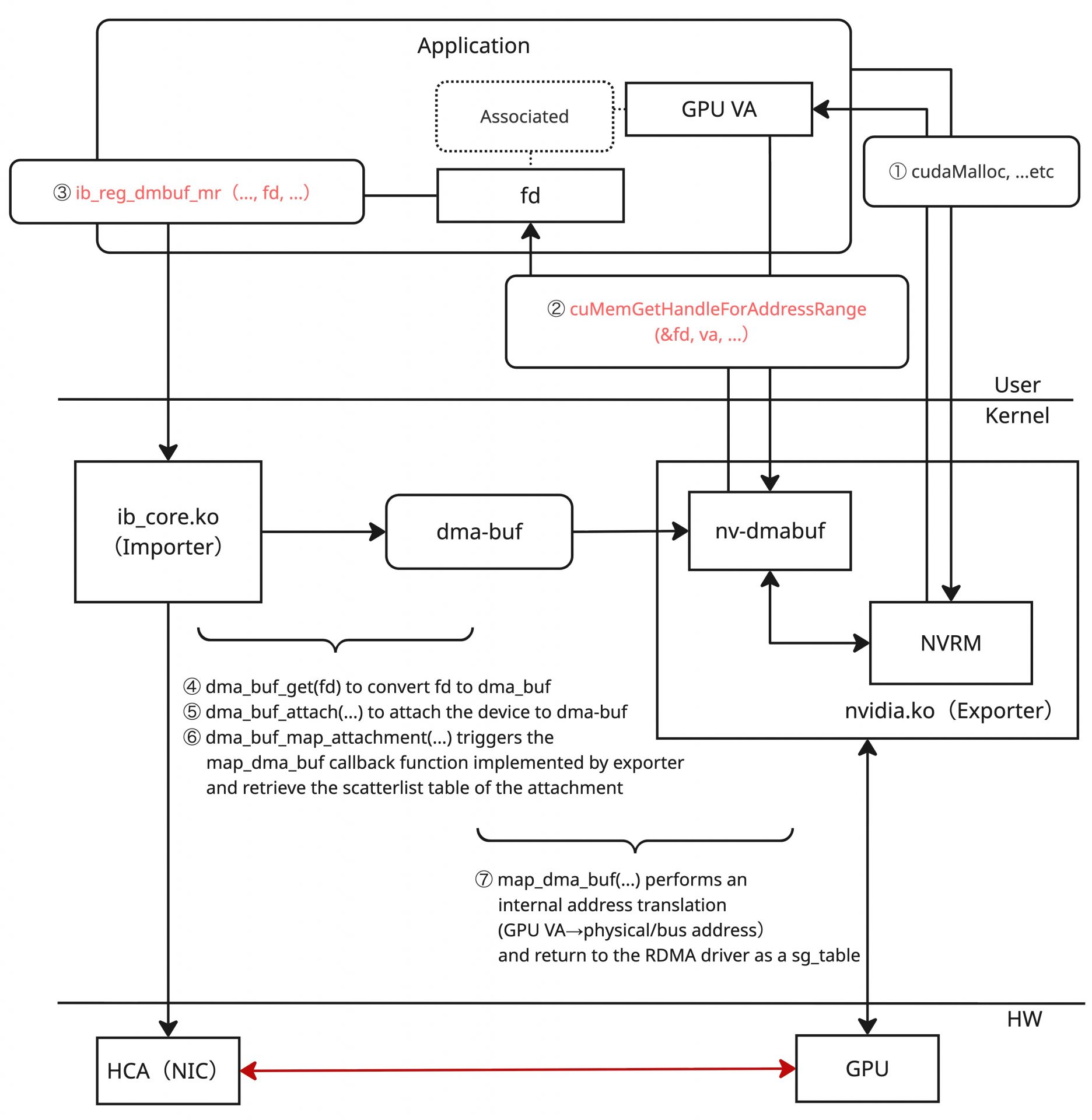
上図のとおり、ファイルディスクリプタを利用するdma-bufベースの実装は、先ほど見たMOFEDの実装と比較して、ユーザースペースの手続きのレベルから少し変化が起きます。CUDA API経由で確保したGPU VAを利用し(①)、dma-buf用のファイルディスクリプタを取得する手続き(②)を踏む必要があり、さらにそのファイルディスクリプタを使ってdma-buf用のlibibverbs APIを呼び出す(③)必要があります。
カーネル内部では、渡されたファイルディスクリプタをもとにdma_buf構造体を取得し(④)、必要な処理を行った上で(⑤~⑥)、メモリー操作のためのCallbackを呼び出します(⑦)。これによってGPU VAからGPU PAの変換が実現されます。
このdma-bufの方式は今後のNVIDIA GPUにおけるGPUDirect RDMAの推奨方式となり、PeerDirectの方式はレガシーという位置付けになることが公式資料から読み取れます。また、この資料に記載のあるとおりdma-bufの方式はLinux kernelのバージョン以外にも、NVIDIA Open Driverが必須であることや、CUDAのバージョンが11.7以上であることが要求されます。
GPUDirect RDMAの整理
ここまでGPUDirect RDMAに関する詳細な技術解説を中心に紹介してきました。実際にサーバーの設定という視点からみると、GPUDirect RDMAの実現には現状大きく二つの手段がありました。改めて整理すると次のような形になります。
| GPUDirect RDMAの実装方式 | 要求事項 |
|---|---|
| PeerDirect実装 | MOFEDドライバ+Peer Memory Client レガシーな方式 |
| dma-bufの実装 | アプリケーション側の対応(dma-bufベースの実装) Linux kernel 5.12+、NVIDIA Open Driver、CUDA 11.7+ が必須 公式の推奨する方式 |
どちらの手段を採用できるかは、運用するシステムで利用したいOSやカーネルのバージョン、CUDAのバージョン、動作させたいアプリケーションの実装状況などを踏まえて決定することになります。ただし、現状は過渡期であり、今後はdma-bufの方針に変わっていくことは頭に置いておくとよいでしょう。
また、ここでは記載を避けていますが、GPUDirect RDMAを実現するには上記のようなソフトウェア上でのセットアップ以外にも、サーバーのハードウェアトポロジーやIOMMUの調整、ACSやATSなどのPCIeトランザクションの制御なども性能に関与します。本記事では割愛しますが、一部の内容は LINEヤフーのGPUサーバーの内部設計とパフォーマンス検証(Rethinking AI Infrastructure Part 3) に記載されているため参考にしてみてください。
KV Cacheの転送に関わるソフトウェア
ソフトウェアスタック概要
今回登場するソフトウェアスタックは概ね次のようになっています。
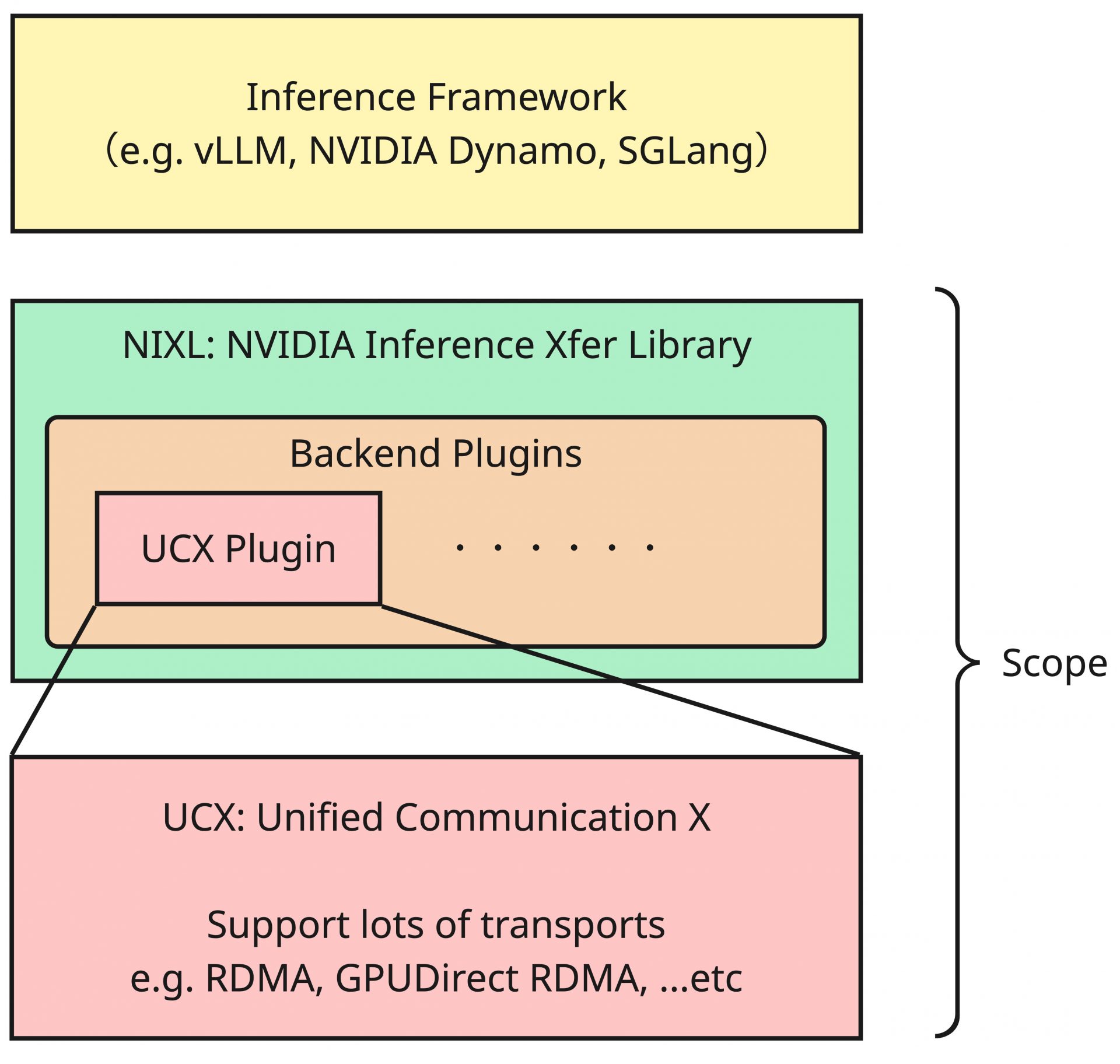
本記事ではこのソフトウェアスタック中のUCXとNIXLの二つを取り上げて説明します。推論フレームワークで用意されているコンテナイメージなどを利用する場合はあまり深く気にすることのないソフトウェアかもしれませんが、現在の推論ソフトウェアエコシステムにおいていずれも重要な位置付けのものです。
これらはKV Cacheの転送で利用され、PD-Disaggregationを実現するための核となるソフトウェアです。これまで見てきたとおり、KV Cacheの転送はノード上のGPU間の転送の可能性もあれば、ノードを跨いだ転送になる可能性もあり、それぞれで利用される通信経路と技術が異なります。これらをうまく隠蔽し適切なトランスポートを選択してくれるソフトウェアがUCXであり、UCXやその他の技術を用いてKV Cacheの転送を実現するソフトウェアがNIXLです。
以降では順番にそれぞれのソフトウェアについて深掘りしていきます。なお、図中のInference Frameworkについては次回以降の連載で取り上げるため、今回はソフトウェアスタックとしての関係性のみ把握してもらえれば問題ありません。
UCX: Unified Communication X
UCX(Unified Communication X)はモダンな高帯域、低遅延ネットワーク向けに設計された通信フレームワークです。UCXはさまざまなトランスポートをうまく抽象化した高レベルのAPIを提供してくれるため、APIに従ってアプリケーションを実装するだけで、UCXがサポートするいくつかのトランスポートに自動的に対応できます。また、UCXは通信性能に非常に重きをおいた実装になっており、トランスポートの自動選択以外にも、内部ロジックとして効率よくデータ転送するための仕組み(メッセージサイズの決定やフラグメンテーション方式、どのような通信プリミティブを利用するかなど)を自動で選択してくれます。
UCXはおおまかにUCTとUCPの二つのレイヤーがあります。
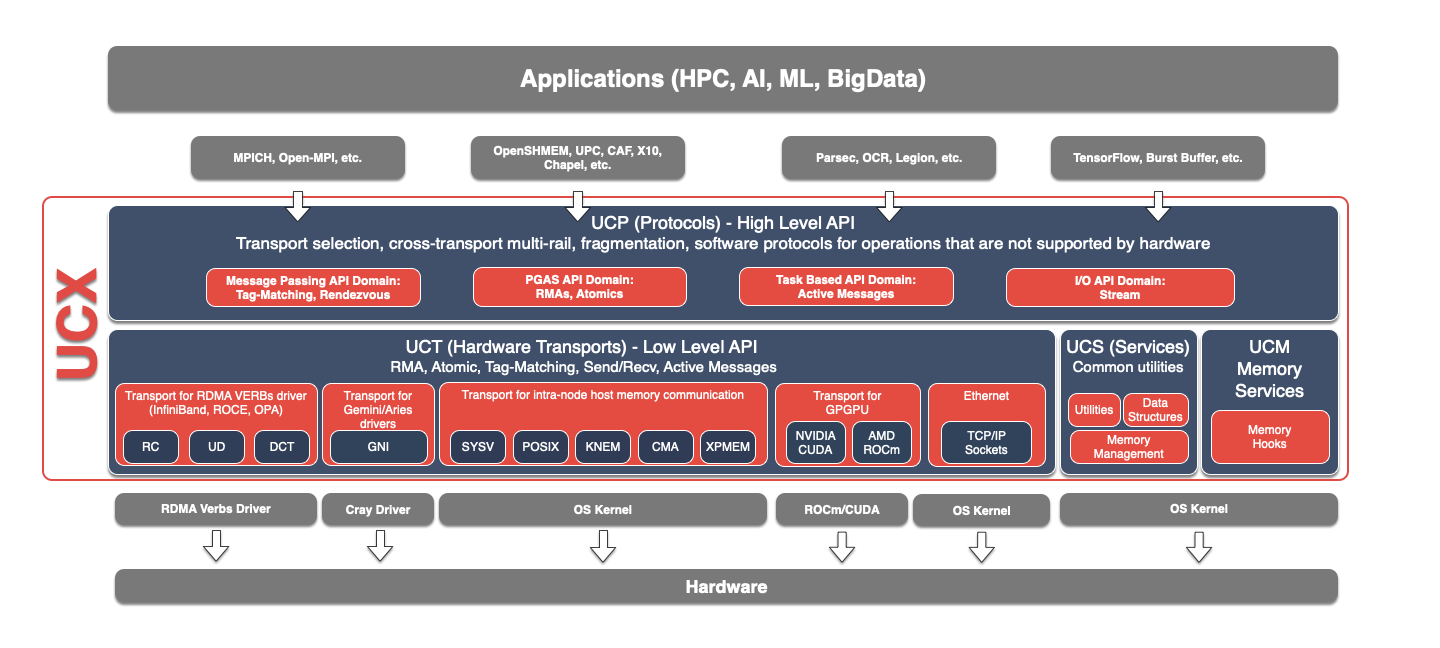
UCTはトランスポートAPIであり、異なる種類の通信デバイスを共通基盤として統合するハードウェア抽象化レイヤーです。UCTはAPI定義として複数の通信プリミティブの定義が存在している一方で、現実問題として各種デバイスはそれ自身がサポートしている機能には限度があります。そのためUCTでは、それぞれのデバイスがAPI定義のうち「どれか」を実装しているという形式を許容しており、これはほぼイコールでそのハードウェアがネイティブにサポートしている機能と一致します。従ってUCT APIを利用する場合は、UCT APIでは定義されているが実際のトランスポートサービスとしては実装がない、というケースをうまくハンドルする必要があります。基本的にはUCT APIをユーザーアプリケーションから利用することは想定されておらず、UCTの上に構築されるUCPを介して間接的に利用されます。
UCPは多様なユースケースにおいて最大限のパフォーマンスを実現するために、UCTを利用して異なるトランスポートを活用、統合、操作するビジネスロジックを実装しています。前述した効率の良いデータ転送のための仕組みも基本的にはUCPに実装されています。さらに、UCPはユーザーが利用するための高レベルAPIを提供しており、ユーザーはUCXを利用する際はこのUCP APIを利用することでUCXによる恩恵を受けることができ、多様なトランスポートのサポートやそれらの性能の最適化の悩みから解放されます。
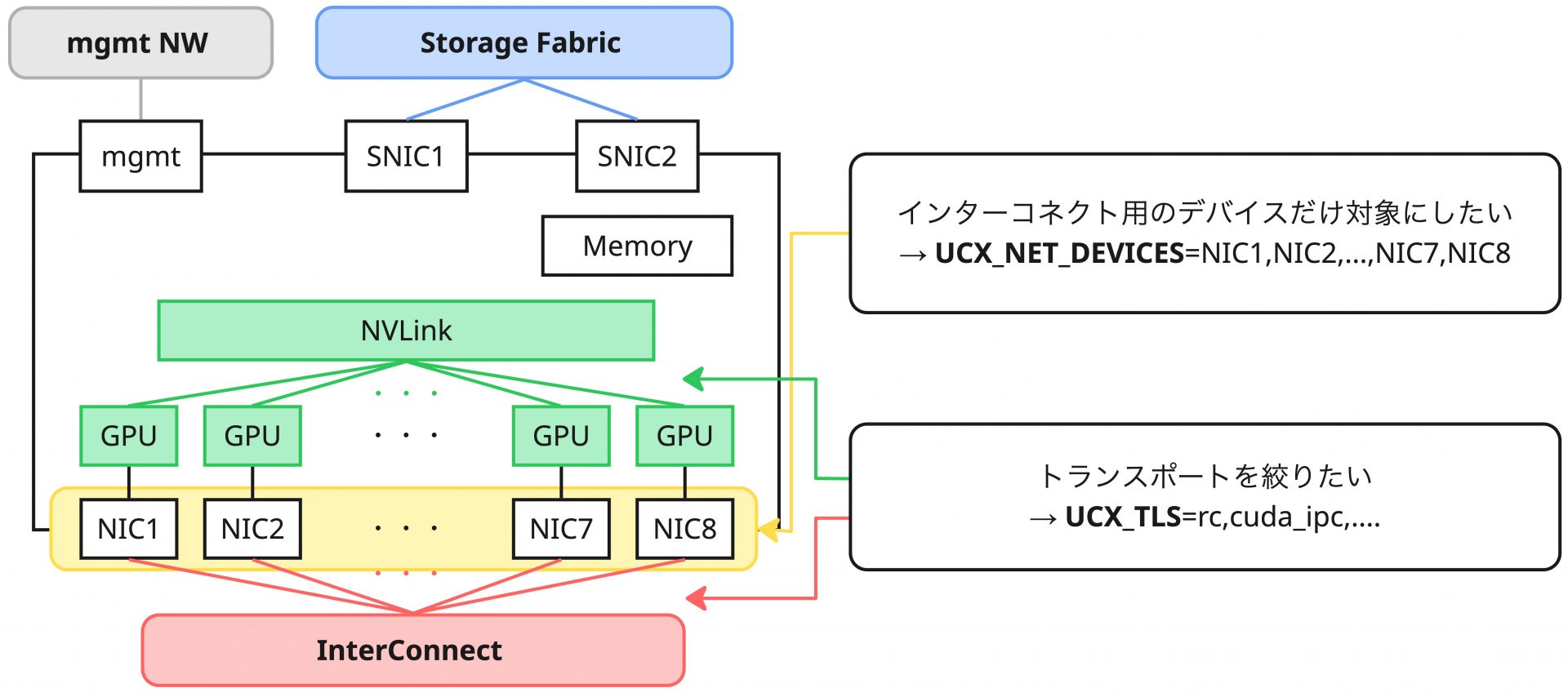
UCXが最適なトランスポートをロジックで選択する一方、ユーザーである我々は場合によってはデータパスを設計し、利用したいインターフェイスを選択したいケースなどがあります。特に近年のGPUサーバーでは、インターコネクト用のインターフェイス、ストレージ通信用のインターフェイス、管理通信用のインターフェイスなど多数のインターフェイスを備えていることが多く、それぞれの用途向けに正しく利用したいところです。UCXは環境変数を与えることで振る舞いを変更できるようになっており、例えばトランスポートを選択・制限する環境変数としては UCX_TLS 、利用可能なデバイスを選択・制限する環境変数としてはUCX_NET_DEVICESがあります。もし意図したようなトランスポートやデバイスの選択が行われない場合などはこれらの環境変数を調整するとよいでしょう。設定の詳細についてはUCX environment parametersを参考してください。
UCXにおけるGPUDirect RDMAの実現についても触れておきます。UCXを利用して記述したプログラムは、GPUDirect RDMAの場合であっても、コードの多くはその他の通信方式と共通になるケースが多いです。一方でどうしてもNVIDIA GPUのようなサードパーティデバイスのメモリーを取り扱うことになるため、アプリケーション側でCUDAの初期化やcudaMallocなどのメモリー確保の処理は実行が必要になります。とはいえ、それ以外の処理に大きな差分がないため、GPUDirect RDMAであってもかなり強力にUCXの恩恵を受けることができます。また、GPUDirect RDMAではGPUに対してPCIe Switchで繋がる近傍のNICを選択しなければならないトポロジー的な制約がありますが、これもUCXのロジックの中で解決されます。
さらに、UCXは同一ノードのGPU間の通信の場合にNVLinkのようなベンダー固有のScale Up Networkの利用をサポートしています。技術的にはベンダー固有のエコシステムの実装(CUDA IPC / ROCm IPC)を利用して実現されていますが、これもUCXのロジックの中で自動的に選択されることになります。従って、UCXを利用するアプリケーションはノード内外の両方に対して適切な高速通信路を利用したGPU間通信が実現できることになります。また、詳細は省略しますがCPUとGPUの間のメモリー転送についてもサポートがあります。
このようにUCXを利用することで複雑なトランスポートの実装や最適化から解放されることになります。これはアプリケーション開発者、ライブラリ開発者にとって、通信について考慮することが減り、それぞれの関心領域の実装に注力できるという非常に大きな恩恵があります。
NIXL: NVIDIA Inference Xfer Library
今回の記事の本題となるソフトウェアの説明に入りましょう。KV Cacheの転送に関する重要なソフトウェアとして、NIXL: NVIDIA Inference Xfer Libraryというソフトウェアがあり、現状ほぼデファクトスタンダードになっています。
NIXLは主に、LLM推論における高帯域、低遅延で効率的なデータ転送(KV Cache転送)を実現するために利用できるソフトウェアであり、異種デバイス(GPU、CPU、Storageなど)間におけるデータ転送をサポートします。NIXLはデータ転送に関するコミュニケーションメカニズムやメモリー操作に関するAPI(North-Bound API / NB API)をライブラリとして提供する一方で、NIXLのコアロジック内には各種デバイスを直接的に操作する実装は存在していません。デバイスを直接制御するための処理は、Backend Pluginと呼ばれる、デバイス毎のプラグイン部に実装されています。このモジュラープラグインの仕組みを実現するために、前述したユーザー向けのNB APIの他に、Backend Plugin向けのインターフェイス(South-Bound API / SB API)が存在し、このインターフェイスを実装するようにPluginを記述することで任意のデータバックエンドをサポートできるような拡張性が実現されています。
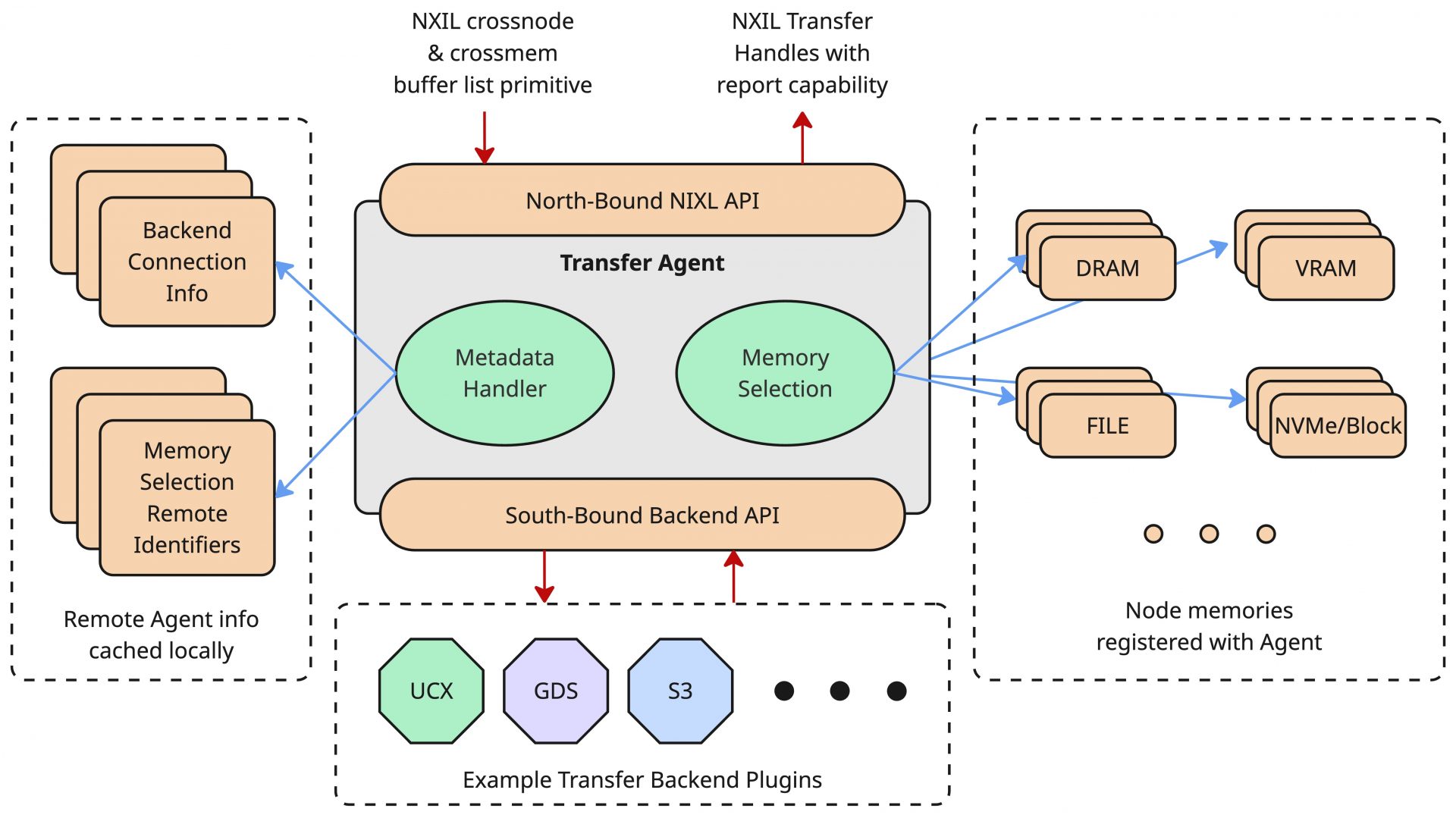
幸いなことに、NIXLはデフォルトでいくつかのBackend Pluginを提供しています。特殊なソリューションとの統合でなければ、概ねデフォルトのPluginを利用することで目的の通信を実現可能です。そのため、普段は上記のような構造、仕組みを意識しなくても利用できますが、特殊なソリューションを組み込みたい場合であっても、SB APIに従って実装することで組み込み可能であることは知っておくとよいでしょう。
デフォルトで利用可能なBackend Pluginのうち、いくつかに絞って以下にリストアップします。実際の実装状況は、NIXLのリポジトリのsrc/pluginsを参照してください。このプラグインは新しいものが追加されたり、逆にデフォルトから削除されるケースもあるようなので、都度アップストリームの実装を確認するとよいです。
| Backend | Memory Type | Description |
|---|---|---|
| UCX | DRAM、VRAM | UCXを利用してGPUメモリー、メインメモリーのデータ転送 |
| GDS | DRAM、VRAM、FILE | GPUDirect Storageを利用してGPU、メインメモリーとストレージ間でデータ転送 |
| OBJ | DRAM、OBJ | S3 API互換のストレージサービスとメインメモリーの間のデータ転送 |
| MoonCake | DRAM、VRAM | GPUとMoonCakeの間のデータ転送 |
| HF3FS | DRAM、FILE | メインメモリーと3FSの間のデータ転送 |
上記にもありますが、UCXはNIXLから見た時にBackend Pluginの実装の一つとして利用されており、これは特にGPU/CPUメモリー間通信で利用可能なPluginという立て付けになっています。また、MoonCakeや3FSのようなOSSのソリューションに対してのPlugin実装も提供しており、NIXLの拡張性の高さが伺い知れます。
これらのBackend Pluginの選択は基本的に設定ファイルなどで与える形になります。通常、NIXLはさらに上位の推論フレームワーク(vLLMやNVIDIA Dynamoなど)から利用される形になるため、設定方法についてはそちらのフレームワークの資料を参照する方がよいでしょう。ここからは、NIXLの具体的な動作について、まずは概要の説明を行ったのち、例としてUCX、GDS Pluginを簡単に紹介します。
NIXLの動作の概要
一言で表すと、アプリケーション(推論フレームワーク)は、NIXLのNB APIから「このGPUバッファを転送したい」という意思だけを伝えれば、NIXLがバックエンド(UCX / GDS / 3FSなど)を選んで最短経路で運んでくれる、というのが大枠の動作の概要です。
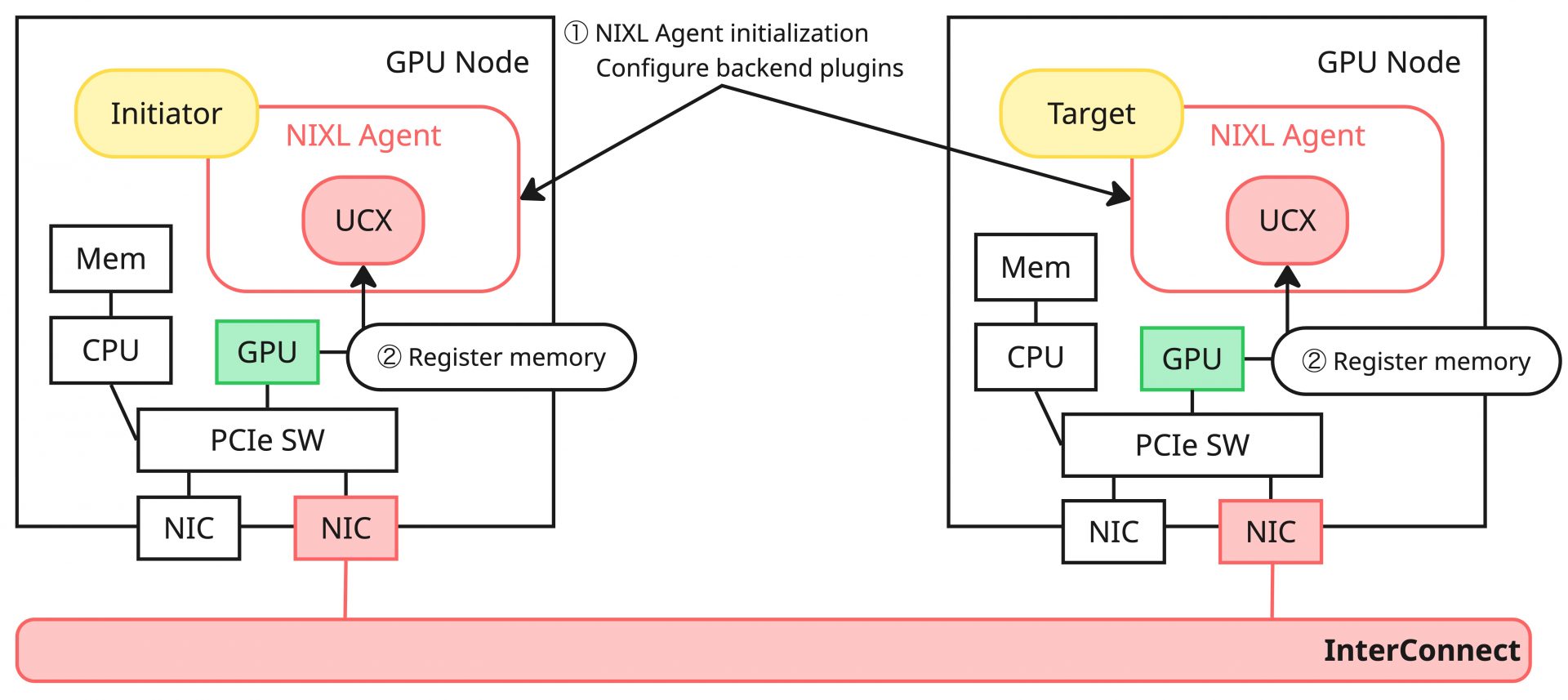
NIXLではまず対象のノードでNIXL Agentを初期化します。NIXLにおいて転送要求をする側のAgentをInitiator、転送要求を受けるノードのAgentやストレージをTargetと呼ぶため、以降ではこの呼称に従って説明をします。このAgent初期化の段階で、利用するBackend Pluginの設定も合わせて行います(①)。
Agent初期化後にメモリーの登録処理を行います(②)。このときに渡すメモリーのデータ型や、指定するメモリータイプ(DRAM/VRAMなど)によって、適切な設定を含んだNIXL独自のディスクリプタをAPI経由で作成し、それを登録用APIに渡す形で登録処理を実施します。このユーザーサイドのAPI実行(NB APIの呼び出し)によって、Agent内部では各種バックエンドのメモリー登録処理がSB API経由で呼び出され、それぞれのPluginは自身のサポートする方式に従った処理を実施します。また、Agentは登録処理に成功したPluginがローカル転送・リモート転送に対応しているかをSB API経由で判断し、サポートする方式についての内部ハンドルを生成します。ユーザーレベルからは基本的に隠蔽されている処理ですが、NIXLの後続の処理に必要なメタデータの生成処理を行っているイメージです。
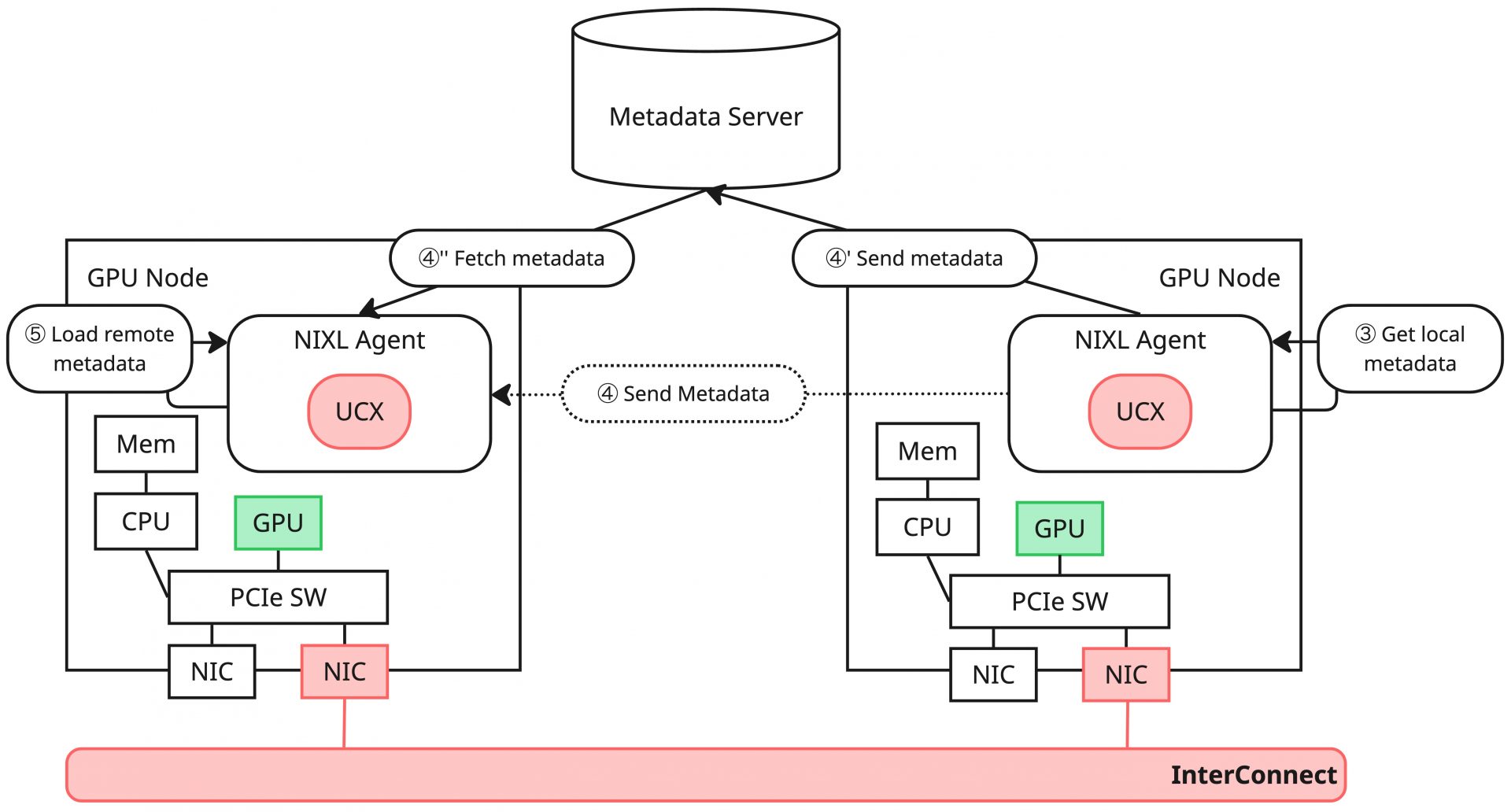
この処理を行ったのち、Agent間でメタデータの交換を行います。これはTargetのメタデータをInitiatorが取得し、それをInitiator Agentが読み込むことでリモートアクセス(データ転送)に必要な情報を得ることが目的の処理です。
Targetは自身のシリアライズされたメタデータを取得し(③)、Socketベース、もしくはETCDベースでInitiatorにデータを送信します。Initiatorでは送信側の方式に合わせてメタデータを受信します(④、④'~④'')。Socket、ETCDベースのメタデータ交換はデフォルトで実装されている機能ですが、転送処理の独自実装も可能なので、アプリケーションの要件に合わせてこの部分は実装します。
メタデータの転送後、Initiatorでは手に入ったターゲットのメタデータを自身に読み込むことでリモートアクセスのための情報が手に入ります(⑤)。
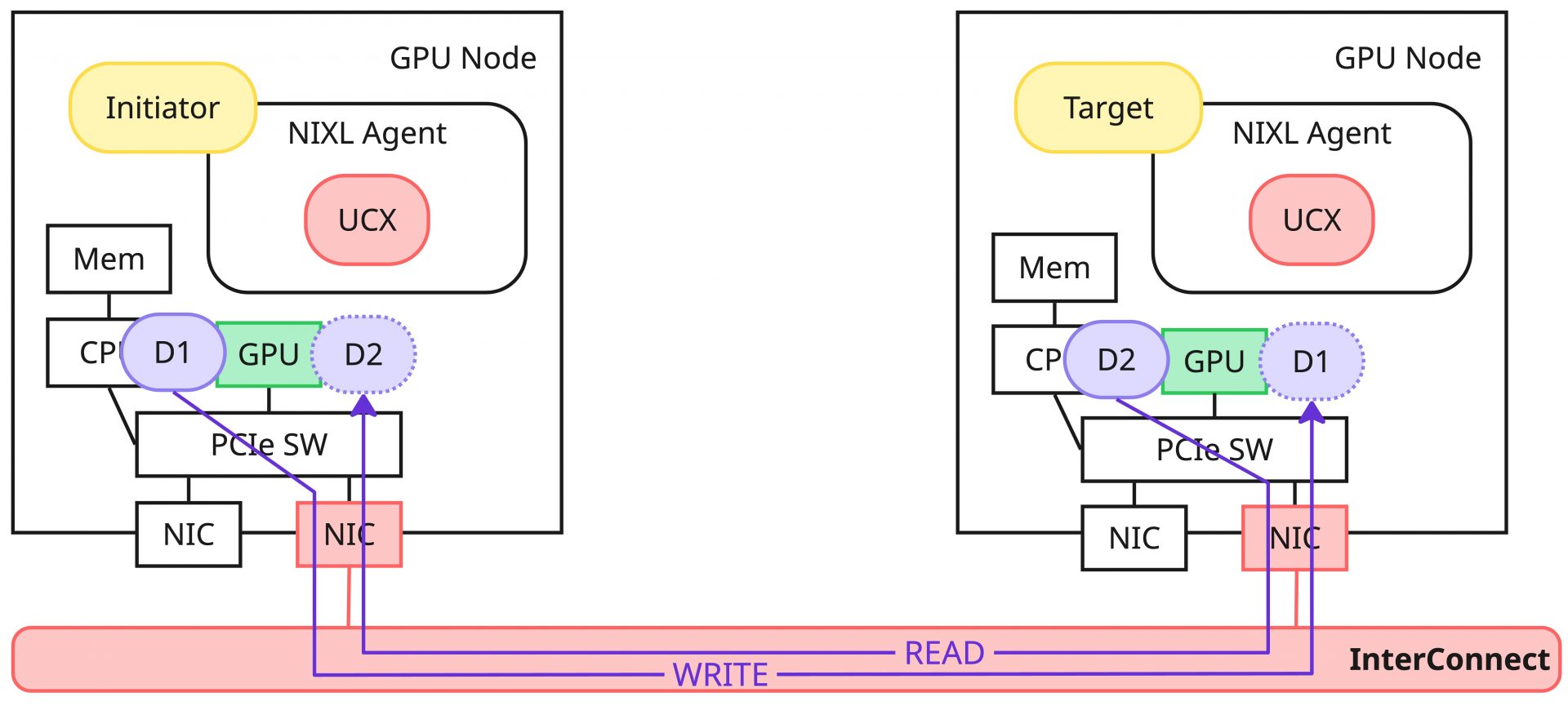
メタデータの交換後はいよいよ転送処理になります。メタデータの交換によって得られた内容からTargetのバッファリストをInitiator側で構築し、ローカルのデータと合わせて転送要求やハンドラを組み立て、転送処理を実行します。データ転送のオペレーションとしてREAD/WRITEがあり、READ要求の場合はリモート(Target)からローカル(Initiator)にデータを読み、WRITEならローカル(Initiator)からリモート(Target)に書き込みを実施します。上記の転送要求に対応するNB APIを実行すると、Agent内部ではハンドラの検証、リモートエージェントの有効性チェック、転送ステータスのチェックなどいくつかの段階を踏んだ上で、SB APIの転送APIを呼び出し、Pluginで実装されているデータ転送の具体的な処理を実行する形になります。
かなり詳細を省いていますが、大まかに以上のような手続きでデータの転送を実施します。Backend Pluginは複数選択が可能であり、例えばUCX PluginとGDS Pluginを組み合わせることで、データをGPU、CPU、Storageのいずれのバックエンドに対しても転送可能になります。
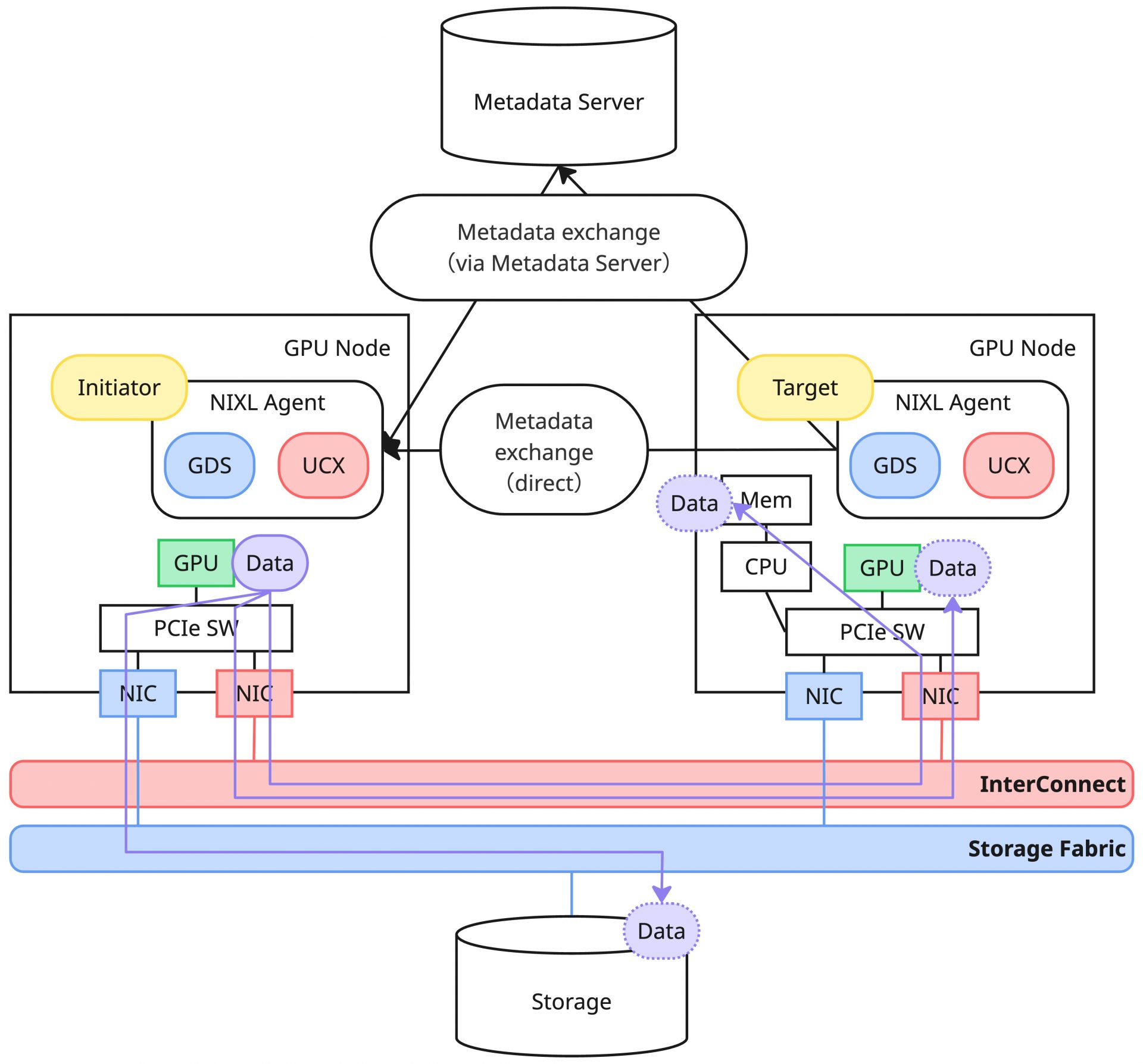
上記の説明ではKV Cacheという単語を使いませんでしたが、上記における転送データをKV Cacheと読み替えると、推論フレームワークが行っているKV Cacheの転送処理と一致します。推論フレームワークはNIXLから見た場合にはNB APIのユーザーであり、推論時に生成されるKV CacheデータをNB APIを利用して別のNIXL Agentに転送しているわけです。
NIXL UCX Plugin
NIXLでは特に指定がない限り、デフォルトのバックエンドとしてUCX Pluginを利用します。UCX Pluginはその名のとおり、UCXを利用したBackend Pluginの実装になっているため、UCXの恩恵による最適なトランスポートの選択と最適な性能が担保されます。
前述したとおり、UCX PluginでサポートされるMemory TypeはVRAM、DRAMという二種類があります。これはUCXそのものの能力として、CUDAやROCmによるGPU間の直接的な通信およびGPU-CPU間の通信、GPUDirect RDMAによるノード間のGPU通信、RDMAによるノード間メモリー通信のような多様なトランスポートがサポートされるからこそ実現されています。結果的にUCX Pluginを利用することで、GPUからローカルのCPU/GPU、リモートのCPU/GPUのいずれに対しても、そのシステムで利用可能な高速通信路を利用したデータ転送が可能であり、これだけでストレージソリューションを利用しないケースはほとんどカバーできます。
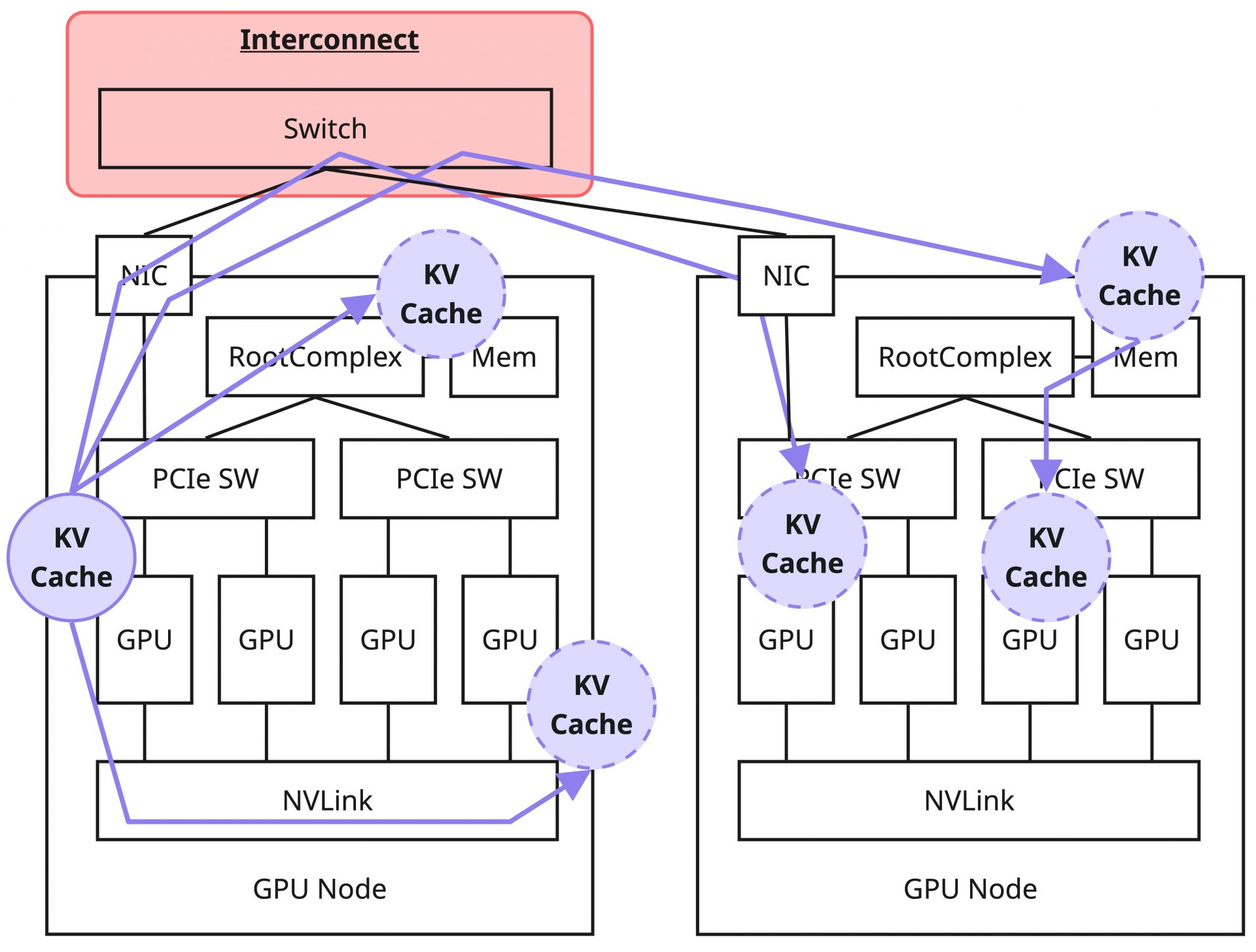
一方でUCXでは、データ転送先がストレージである場合は対応できません。そのためストレージにも対応させたい場合は、UCXと合わせてストレージソリューション向けのBackend Pluginを選択することになります。以降では代表的なPluginであるGDSについて少しだけ触れることにします。
NIXL GDS Plugin
KV Cacheをストレージにデータとして書き込みたい場合や、ストレージからデータを読み込みたい場合の一例としてGDS(GPUDirect Storage)Pluginがデフォルトで提供されています。
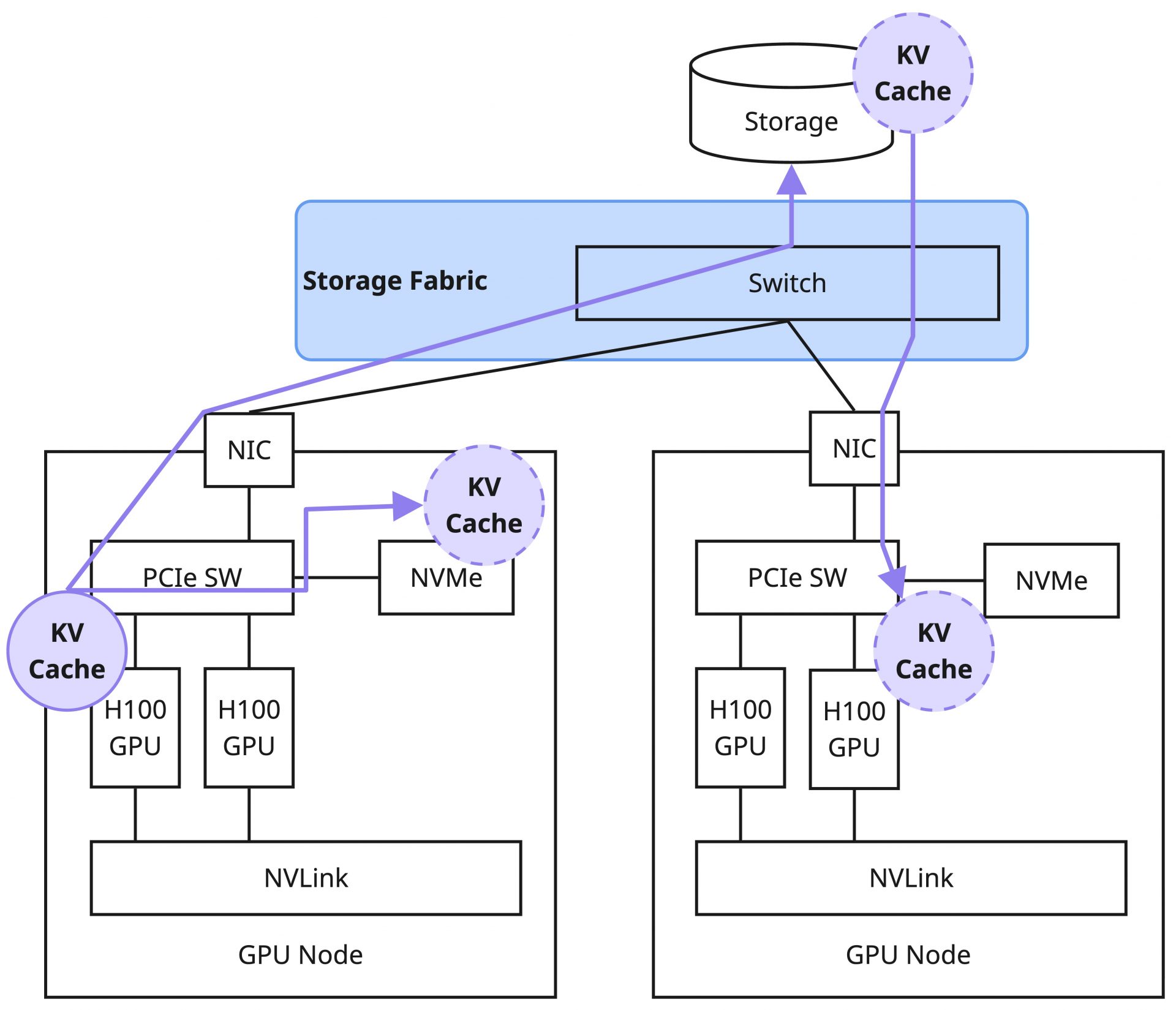
KV Cacheを配置するストレージの種類(ファイルストレージ、ブロックストレージ、オブジェクトストレージなど)や利用可能なストレージ技術(NFS over RDMA、NVMe-oF/NVMe over RDMA、S3 over RDMAなど)によって選択可能なプラグインが変わるため、正しく選択するにはストレージに関する知識やGPUDirect Storage自体の仕組みなどの理解が不可欠です。これらに関しては、そもそもKV Cacheをストレージに配置する理由やモチベーションが何なのかという根本的な疑問への回答と合わせて連載後半に触れる予定です。
NIXLによるKV Cacheの転送性能の検証
ここまででGPUDirect RDMAやUCX、NIXLといったKV Cacheを効率的に転送するための技術についてかなり詳細に見てきました。以降では、これらの技術スタックによって実際に十分な性能が発揮できるかについて測定した内容を共有します。
性能検証の内容と構成
今回の検証では、NIXLおよびUCXを利用した場合に、想定される理想的な性能値に近い性能が達成できるかを確認することを目的としています。この確認ができると、正しくシステムを構成していればNIXLやUCXをベースとしたソフトウェアの通信性能については概ね担保できることが期待されます。実際、プロダクションで動作させる推論フレームワークからみるとこれらはパーツの一部でしかありませんが、パフォーマンスボトルネックになった際の切り分け時などに非常に強力な情報になるでしょう。
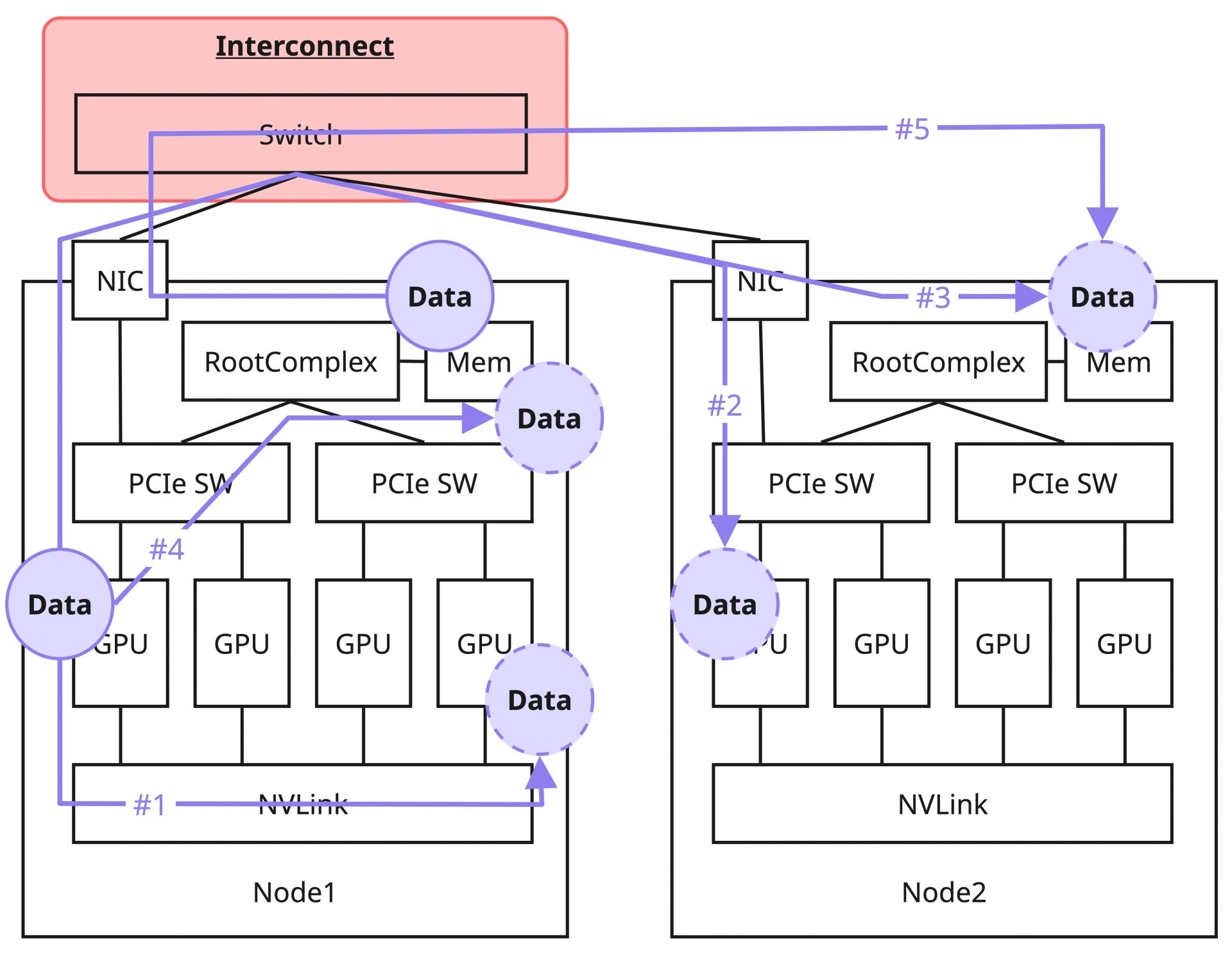
今回の測定内容と、それに対しての理想的な性能について以下のとおり整理します。この測定ではGPU同士の測定に限らず、GPUからCPUへの通信、CPU同士の通信などのさまざまなパターンでの測定を行うことにしました。
| No | 測定内容 | 想定される律速要因 | 期待性能 |
|---|---|---|---|
| #1 | 同一ノード内のGPU間の転送 | NVLink | 400 GB/s(単一方向) |
| #2 | ノード1のGPUからノード2のGPUへの転送 | インターコネクト | 50 GB/s(400Gbps NIC) |
| #3 | ノード1のGPUからノード2のCPUへの転送 | インターコネクト(*) | 50 GB/s(400Gbps NIC) |
| #4 | 同一ノード内のGPU-CPU間の転送 | PCIe Gen5 x16 バス | 64 GB/s(単一方向) |
| #5 | ノード1のCPUからノード2のCPUへの転送 | インターコネクト(*) | 50 GB/s(400Gbps NIC) |
(*)CPU(メインメモリー)へのデータ転送であっても、NIXL + UCXが通常のRDMAを利用してくれることが期待されます。そのため想定される律速要因としてはインターコネクトの性能を想定しています。
当然ながら、この期待性能が達成されるかは転送時のデータサイズなどによって変化することが想定されます。幸いなことに今回利用するベンチマークツールである NIXL Benchmark(nixlbench) は、データサイズを刻みながら性能を測定してくれるため、その結果をそのまま利用し傾向を捉えることにしました。
検証環境の構成ですが、上記の測定内容を達成するために、今回はH100 HGXサーバー(8GPU/8NIC)を2台用意しました。GPU間通信のためのインターコネクトも用意し、すべてのNICが400Gbpsで結線され、RoCEv2で通信可能にし、念のためロスレスの設定なども行っています。
測定パターンを含めた環境の構成図は以下のようになります(図では簡易化のために4GPU/1NICしか記載していませんが実際は8GPU/8NICあります)
また、サーバーのOSとしてはUbuntu 22.04.5 LTSを利用し、カーネルバージョンは5.15.0-160-genericを利用しています。このOS/カーネルバージョンの選択に深い意味はありません。その他、関連するソフトウェアやパッケージ類については以下の通りです。
| Package | Version |
|---|---|
| nvidia-driver-580-server-open | 580.95.05-0ubuntu0.22.04.2 |
| cuda-* | 13.0.88-1 |
| cuda-drivers-fabricmanager-580 | 580.95.05-0ubuntu0.22.04.2 |
| doca-ofed | 3.0.0-058218 |
| UCX | 1.19.0 |
| NIXL | 3daa987(commit number) |
この検証環境は諸々の理由により、いくつかのパッケージを手動でビルドしてインストールしています。上記ではUCXとNIXLがそれに該当します。そのため、パッケージマネージャのような仕組みでインストールした場合や公式に提供されるコンテナイメージなどで完全に同様の環境を再現することは難しいかもしれませんが、今回の検証に関して言えば大きく問題になることはないと思います。また、今回の検証ではGPUDirect RDMAを暗黙に利用していますが、MOFED + Peer Memory Clientの方式を利用しています。
ベンチマークツール
NIXLはそれ自体がライブラリであるため、今回のようにNIXLの機能性や性能面の確認目的でベンチマーク測定を行う場合は、NIXLを利用して実装されたベンチマークツールが必要になります。幸いなことに、NIXLはリポジトリ内部にベンチマークツールとしてNIXL Benchmark(nixlbench)を実装、同梱してくれているため、このツールをそのまま採用しました。
NIXL Benchmarkはコマンドライン引数によって、利用するBackend Pluginの指定(UCX、GDSなど)やInitiator、Targetのメモリー種別の設定(VRAM、DRAM、FILEなど)、オペレーション種別の設定(READ、WRITE)など細かい調整が可能なため、上述した内容を測定する目的にフィットしたツールです。また、ベンチマークの結果としても、前述したとおりデータサイズを刻みながら測定を行いつつ、それぞれBandwidth/Latencyなどの不足のない情報を出力してくれます。
測定結果
最初に結論を述べると、次のような結果になりました。
- NVLink経由のGPU間転送は、理論値400GB/sに対して、その近傍まで到達。
- 400GbE RoCE経由のGPUからリモートCPU、CPUからリモートCPUへの転送は、いずれも40〜50GB/sで頭打ちになり、概ねインターコネクト帯域通りの値。
- これにより、NIXL + UCXを正しく構成した場合、KV Cache転送のボトルネックは主に「物理リンクの帯域」に収束することを確認。
以下に、ノード内部で完結する通信(#1, #4)について測定した結果のグラフを掲載します。グラフの横軸は転送データのブロックサイズ、縦軸の左はBandwidth、右はLatencyの軸となっています。プロットしているグラフには2種類あり、丸マーカーと実線はBandwidth、三角マーカーと点線はLatencyの測定結果になります。また、オペレーションとしてはWRITEを実行しているため、例えば判例にある「Local GPU → Local GPU」はローカルGPUから別のローカルGPUへのWRITE操作を意味します。
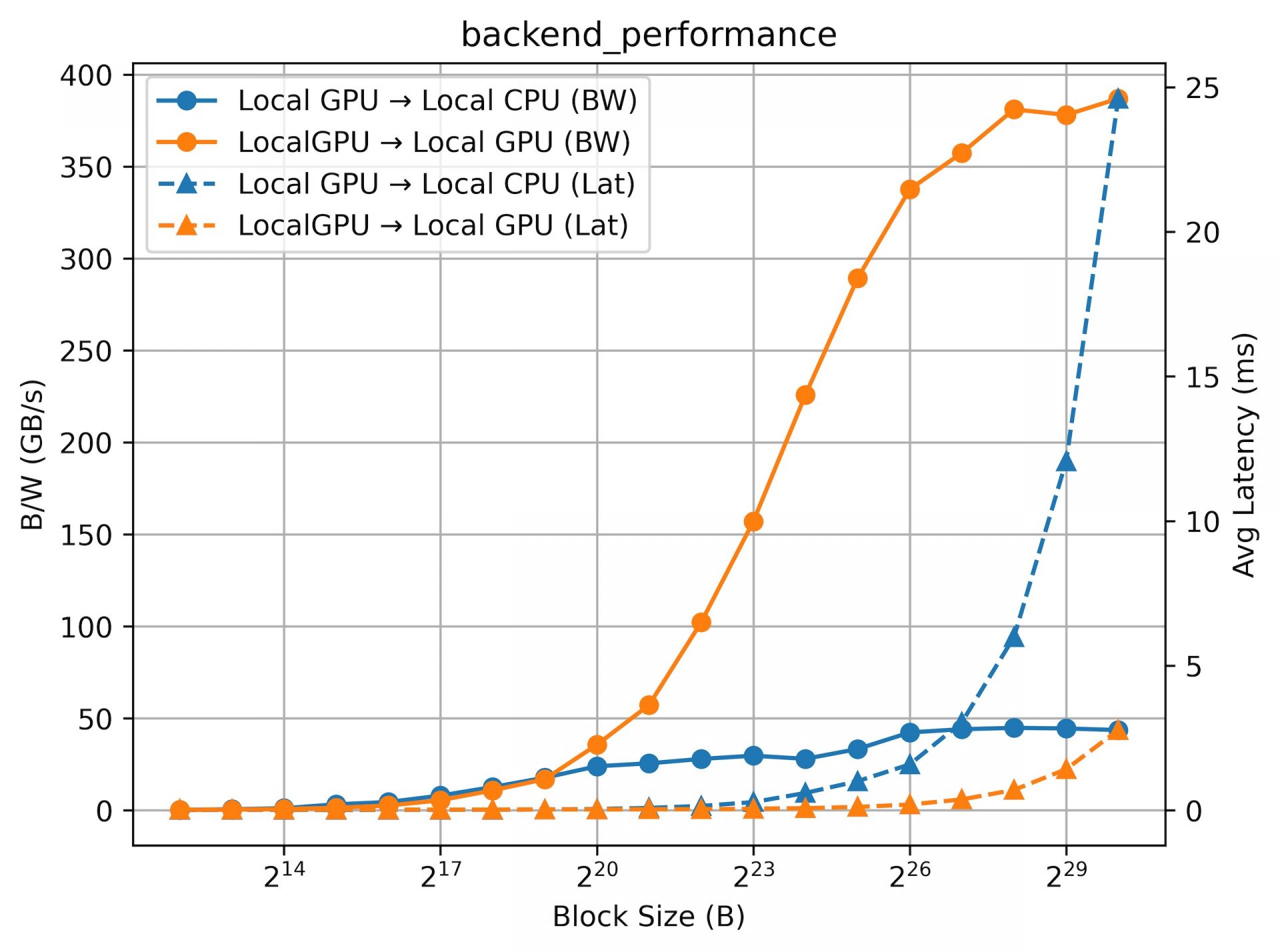
GPU同士の通信(橙のグラフ)に関しては、ブロックサイズを上げると400GB/s近くのBandwidthを達成しており、NVLinkがサポートする帯域を最大限利用できています。またこのBandwidthを達成しつつLatencyは3ms程度に抑えられており、NVLinkなどのScale Up Networkを利用するパスの効率の良さがよくわかります。
一方で、GPUからメインメモリーに対するデータの転送は50GB/s程度で律速していることがわかります(青のグラフ)。このケースでの期待性能は64GB/sであり、PCIeのデータ転送におけるオーバーヘッドを加味してもやや律速が早いように見受けられます。この疑問について明確な回答を現時点では提示できませんが、致命的な性能欠損というほどでもないため、今回は最大に近い値が出ているとポジティブに評価しています。
次に、インターコネクトを利用し複数ノードで通信を行う場合について測定した結果のグラフを掲載します(#2, #3, #5)。こちらのグラフのプロットも上記のプロットと同様の形式に従っていますが、Bandwidthの軸のレンジは異なるため注意してください。
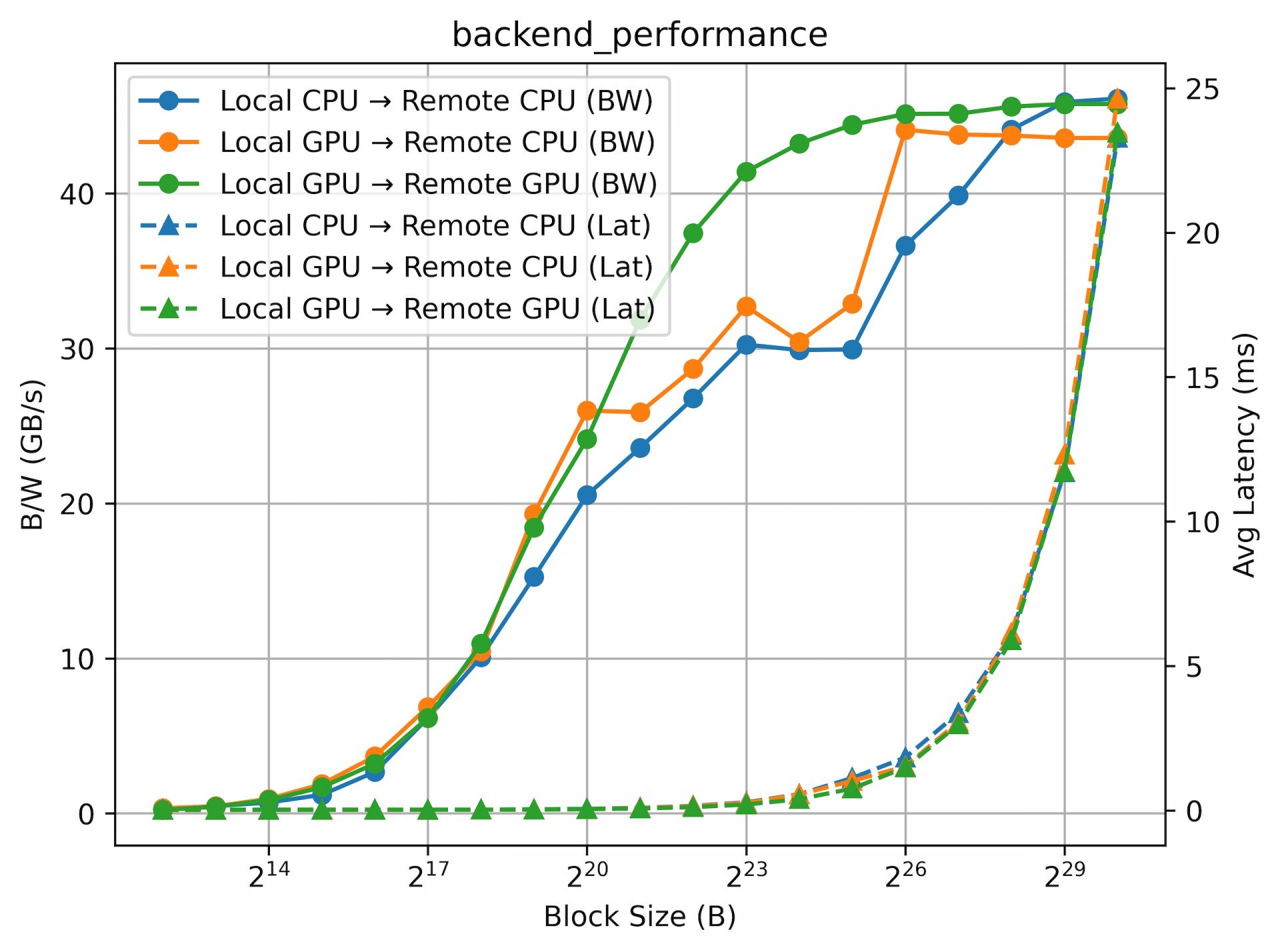
リモートGPUへの転送(緑のグラフ)のBandwidthに関しては、ブロックサイズの増加に伴ってきれいに増加し、50GB/s付近で律速していることがわかります。この律速はインターコネクトの性能(400Gbps = 50GB/s)によるもので、GPUDirect RDMAにより期待性能が達成できていることがわかります。
一方、GPUからリモートCPU、CPUからリモートCPUに関してBandwidthをみてみると、滑らかなグラフではありませんが、こちらもブロックサイズに応じて上昇し、大きいブロックサイズでは40GB/s〜50GB/sほどの性能が出せていることがわかります。レイテンシー傾向としてはいずれも同じよう傾向を示しており、うまくRDMAを利用した通信によってローカル、リモートで直接のデータ転送が実施できていることがわかります。
以上の結果から、NIXL + UCXの組み合わせによって、それぞれのテストケースで適切なトランスポートが選択された結果、概ね期待どおりの性能を実現できることが確認できました。
おわりに
今回は、KV Cacheを転送するためのデータ転送経路とそれにまつわる技術の深掘りを行った上で、実際に性能を測定することで関係するソフトウェアの機能・性能的評価を行った内容を共有しました。普段、おそらくプロダクション環境で構築する場合はより上位のフレームワークを利用し構築するケースがほとんどだと思いますが、一方でインフラ・プラットフォーム提供者としてはその基礎となる技術やソフトウェアの成り立ち、性能などについて正しく理解する必要があると考えています。実際、これらのナレッジはパフォーマンスイシューの発生時にトラブルシューティングなどを行う上で非常に強力なツールになると同時に、エコシステムや周辺技術を理解する上での強力な手助けにもなります。
今回の記事はテクニカルな内容を多めに含んだものになっていたと思います。この記事を読んだエンジニアにとって少しでも持ち帰るものがあれば幸いです。次回の記事では推論フレームワークの話に進みつつ、私が行ったPD-Disaggregationの有効性を確認するベンチマークの話を中心に共有したいと思っています。この領域に興味、関心がある方はぜひ引き続きお付き合いください。