コンテナー型GPUクラウドサービス「高火力 DOK」でOllamaを実行する


高火力 DOKはコンテナー型のGPUサービスで、NVIDIA V100やH100を実行時間課金で利用できるサービスです。
今回はこの高火力 DOKを使って、Ollamaを実行してみます。ローカルにGPUがなくとも、速いレスポンスが得られます。
Ollamaとは
Ollamaは、LLMを簡単に実行できるオープンソース・ソフトウェアです。Llama 3やMistralなど、さまざまなモデルに対応しています。CLIで利用することが多いですが、今回はWeb APIとして立ち上げて、Open WebUIから操作します。
実行する
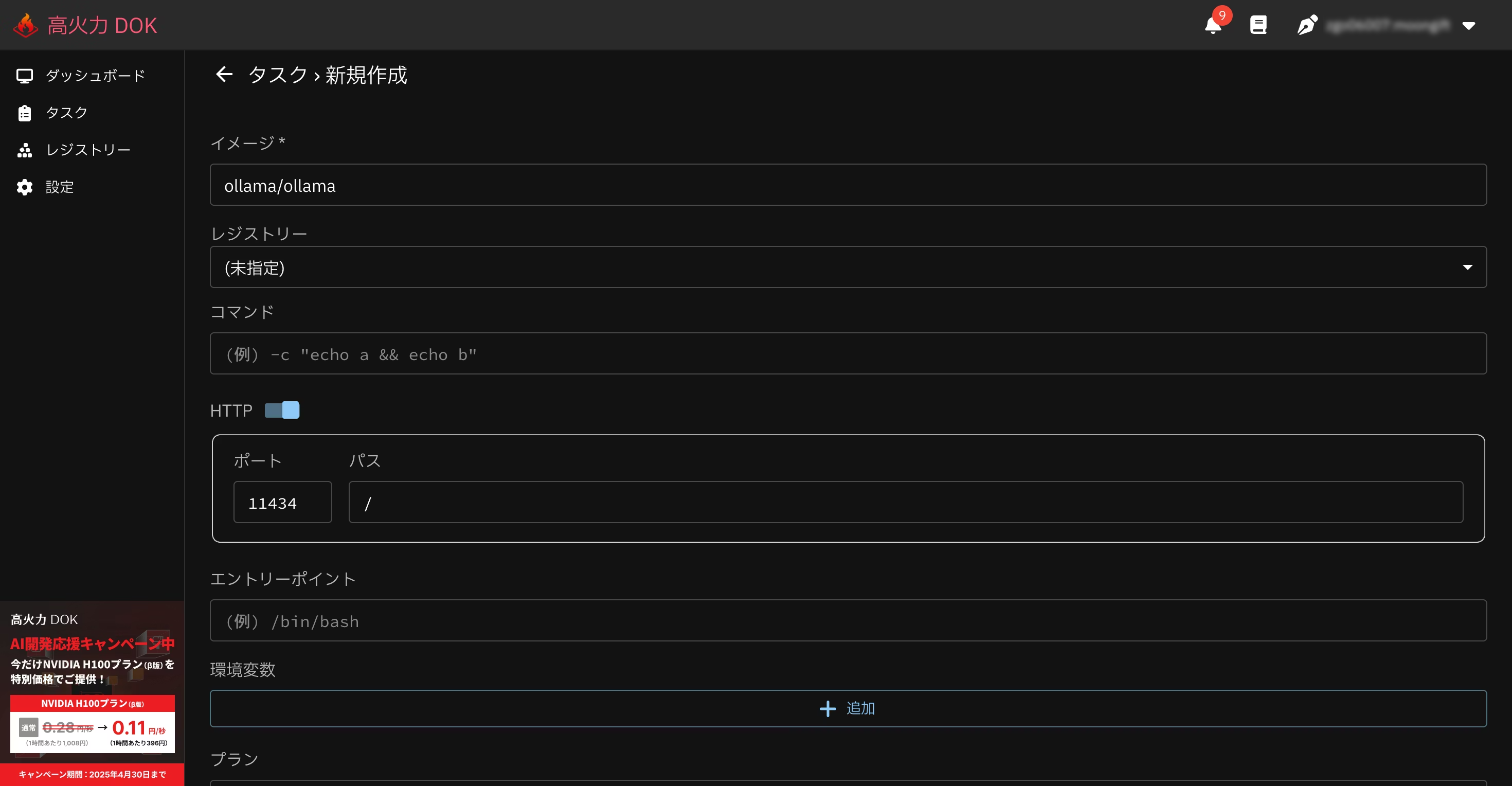
高火力 DOKで、下記の条件でタスクを作成します。
| 項目 | 設定 |
|---|---|
| イメージ | ollama/ollama |
| HTTPポート | 11434 |
実行して、しばらく待つとHTTPアクセスできるURL( https://UUID.container.sakurausercontent.com のような)が発行されます。
Open WebUIで操作する
ローカルで実行します。これはGPUが不要なので、Dockerさえ実行できれば、どこでも実行できます。先ほど出力されたURLを OLLAMA_BASE_URL として指定します。
docker run -p 8080:8080 \
-e OLLAMA_BASE_URL=https://UUID.container.sakurausercontent.com \ # 発行されたURLに置き換え
-v open-webui:/app/backend/data \
--name open-webui --restart always ghcr.io/open-webui/open-webui:mainそして、ブラウザで http://localhost:8080 にアクセスします。以下のような画面が表示されます。
モデルの追加
設定の中にある接続設定から、モデルを追加します。今回はLlama 3.2を追加しました。ダウンロードは高火力 DOK側で行われます。
ダウンロードさえ終われば、チャットが利用できます。
注意点
高火力 DOK上でコンテナが実行されている限り、課金が発生します。使い終わったら、タスクを終了してください。
まとめ
今回は高火力 DOKでOllamaを試しました。v100-32gbを使いましたが、より大規模なモデルを利用するならh100-80gbもあります。大規模LLMの学習や評価に使うと、ローカルのGPUを使うよりも早く結果が得られます。ぜひ試してみてください。
DOKはタスク実行だけでなく、Python実行環境を備えたJupyterLabも利用できます。AIや機械学習の開発にぜひご活用ください。