AIスパコン「さくらONE」で挑むLLM・HPCベンチマーク (3) 「さくらONE」で挑戦するTOP500

目次
はじめに
AIとHPCが急速に融合するいま、単に速いだけでは「使える計算機」にはなりません。学習・推論・数値計算が同居する現場では、演算性能だけでなく、メモリ帯域やネットワーク、ソフトウェアスタック、電力効率、そして可用性までを含む総合力が問われます。では、ベンチマークは何を測り、どこまで現実を映すのでしょうか。TOP500のHPL(High-Performance LINPACK)は理論ピークに迫る上限値を、HPCGは通信とメモリアクセスの制約下での実効性能を、HPL-MxPは混合精度によるAI時代の処理能力を、それぞれ異なる角度から照らし出します。
ここでは、これらの指標の「読み方」と注意点を整理し、行列サイズやブロック分割、プロセスグリッド、疎行列データ構造、反復改良や通信重畳といった設計・運用の勘所を、「さくらONE」での取り組みを手がかりに具体的に紹介します。目的はスコア獲得そのものではなく、実アプリケーションで再現できる性能を引き出すこと。TOP500に挑む過程で得られる知見を、ユーザ価値へ直結するAI/HPCの実務性能へ還元していきます。
TOP500とは
TOP500は、世界の高速スーパーコンピュータを年2回(ドイツで行われる6月開催のISC/アメリカが行われる11月開催のSC)にランキング形式で公表するプロジェクト(1993年開始)です。ランキングを決めるのにはHPLでのスコアが用いられ、倍精度浮動小数点演算による連立一次方程式の解法速度(Rmax)で計算能力を比較します。上位を狙うには、単なるピーク性能だけでなく、長時間の高負荷を安定維持できる信頼性と、ハードウェア・ソフトウェアの綿密な最適化が不可欠な事が知られています。
HPL:密行列で理論ピークに迫る標準ベンチマーク
HPLは、密行列の連立一次方程式 Ax=b をLU分解(部分ピボット)で解く計算をモデル化し、BLAS Level-3(DGEMM)中心の高い演算強度でマシンの能力を引き出します。行列サイズやブロックサイズ、プロセスグリッドなどを最適化し、理論ピーク(Rpeak)にどこまで迫れるかをRmaxで評価します。HPLは計算密度が高く、アクセス・通信が規則的で最適化効果が出やすい一方、実アプリの不規則なメモリアクセスや通信を必ずしも代表しない事が指摘されています。そのため、実効性能の把握にはHPCGなどの補完指標と併用します。HPLのスコアのサブミット時に参考値としてHPCGの結果も報告するのは、そのような背景があります。
HPCG:より実アプリに近い通信・メモリアクセスを反映
HPCG(High Performance Conjugate Gradients)は、実アプリで多用される疎行列を対象に、共役勾配法で連立一次方程式を解く処理をモデル化します。スパース演算、間接参照、近傍通信、メモリ帯域・レイテンシの影響が顕在化しやすく、現実に近い計算負荷と通信パターンを反映します。2014年よりランキングとして公表され、HPLだけでは見えにくい実用性重視の性能指標として位置づけられています。
HPL-MxP(旧称 HPL-AI):AI時代の混合精度ベンチマーク
AI分野では混合精度(低精度で大部分を計算し、必要箇所を高精度で補正)が主流になりつつあります。HPL-MxPはLINPACKの構造を活かしつつ、低精度演算を主体に計算を進め、反復改良(Iterative Refinement)で最終精度を確保する手法で、AI向けアクセラレータの実力を測りやすくします。これにより、倍精度中心のHPL/HPCGと並び、AIワークロードでの処理能力を示す補完指標として活用されます。
ベンチマークの種類のまとめ
これまで上げた3つのベンチマークをまとめると次の様な表にまとめる事ができます。
| ベンチマーク | 主な目的・対象 | 手法/評価項目 | 補足 |
|---|---|---|---|
| TOP500 | HPC全体の計算性能 | 倍精度演算(HPL/Rmax) | 長年使われている定番ランキング |
| HPCG | 実アプリに近い負荷 | 疎行列 × 共役勾配法/近傍通信・メモリアクセス評価 | 通信・メモリの制約を反映 |
| HPL-MxP | AI/HPCハイブリッド | 低精度+反復改良(Iterative Refinement) | AI 向けチップの性能も反映 |
ベンチマーク対象のさくらONEのシステム構成について
ベンチマーク対象の「さくらONE」の構成についてここで整理しておきます。対象のシステム構成を理解することは、チューニングをする上でとても大切です。さくらONEでは、高火力 PHYのH100搭載モデルとして提供されているノードに対してインターコネクトのネットワークを改良しました。具体的にはもともと4本のインターフェースで構成されていたところを2倍の8本にし、ストレージ用にさらに2本のインターフェースを整備して、ノードあたり10本の400GbEの高速ネットワークインターフェースを備えています。両者の比較表を示しておきます。
| 比較表 | 高火力 PHY | 高火力 PHY(改) |
|---|---|---|
| CPU | Intel Xeon Platinum 8480+ x 2CPU | Intel Xeon Platinum 8580 x 2CPU |
| CPUコア数 (per CPU) | 112 (56) | 120(60) |
| ノード内のGPU | NVIDIA H100 SXM 80GB x 8GPU | NVIDIA H100 SXM 80GB x 8GPU |
| システムメモリ | 2.0 TB | 1.5TB |
| インターコネクト | 400GbE x 4 | 400GbE x 8 (+2 for Storage NW) (Edgecore AIS800-64O) |
インターコネクトの構成は、性能に大きく影響を与えるノード間通信に関わる部分なので、その構成を改めてここで提示します。さくらONEのインターコネクトは、800GbEのインターフェースを備えた51.2Tbpsの転送能力を持つスイッチをClosネットワーク構成で24シャーシをLeaf-Spine構成にしています。ネットワークトポロジーとしてはRail-Optimized構成をとっており、Network congestionに対して優れた耐性を持つ特徴を備えています。
| item | contents |
|---|---|
| Network technology | Gigabit Ethernet (GbE) |
| Ethernet switch speed grade | 800GbE |
| Protocol | RoCEv2 (RDMA over Converged Ethernet) |
| Network topology | Rail-Optimized Topology |
| Switch Chassis | Edgecore networks AIS800-64O |
| Switch Capability | 51.2Tbps fullduplex |
| Software Stack | SONiC (Software for Open Networking in the Cloud) |
| Switch Chip | Tomahawk 5 chipset powered by Broadcom |
| Leaf Switch | 16 chassis |
| Spine Switch | 8 chassis |
HPLで行われていること
HPLは、スーパーコンピュータ(以下スパコン)の「全力疾走の持久力」を測るための代表的なテストです。やっていることは、ガウス消去法を用いた密行列連立1次方程式の求解なのですが、巨大な連立一次方程式をできるだけ速く、正しく解く際に実行された“足し算・掛け算”の回数をもとに、1秒あたりの計算回数(FLOPS)を算出します。その対象は密行列で表された問題 Ax=b (倍精度=FP64)となります。この行列の大きさは非常に大きく、たとえば100万×100万だと要素が個になり倍精度では約8TBのメモリを消費します。実際の測定では、OSなどが利用する分を差し引いた総メモリの7~8割程度を目安にサイズNを決めるのが定石です。ちなみにさくらONEのISC2025の時に使ったNのサイズは2,706,432でした。
このような巨大な連立方程式問題をそのまま力技で解くのではなく、HPLは部分ピボット付きLU分解という手順で解きやすい形に変形して扱います。ざっくり言えば、表(行列)をうまく並べ替えて2つの三角形の形に分解し、最後は前進代入と後退代入という単純な手順で解を取り出します。こうした分解の過程で必要になる重たい計算の多くは、行列×行列の掛け算(DGEMM)に集約されます。DGEMMは計算密度が高く、ハードウェアの性能を引き出しやすいため、HPLが高い持続性能を示しやすいのは、この「重たい掛け算を長時間ひたすら回し続ける」設計になっているからです。
もちろん、現在のスパコンは1台の計算機ノードで構成されているわけでなく、多数のノードが集合体として構成されて同期的に機能させることで実現しています。HPLでは、たくさんのCPU/GPUコアを持つノードに公平に仕事を分けることで計算規模のスケールアップを行っているので、課題として与えられる行列を小さな正方ブロックに切り分け、それらを2次元の囲碁盤のような配置で各プロセスに配ります(これを2Dブロック循環分散と呼びます)。この分割するブロックサイズNBが重要なパラメータとなっています。さくらONEでは1024を最終的なブロックサイズとして計測を行いました。CPUやGPUの計算能力に応じて調整してバランスの良い値を見つける事になります。
このプロセス(≒並列で動く作業ユニット)をP行×Q列のグリッド状(格子状)に並べて「プロセス格子」として管理します。
P(行数):たて方向にプロセスを並べた数
Q(列数):よこ方向にプロセスを並べた数
合わせて、P×Q個のプロセスで計算を行います。
たとえば、8個のプロセスを使う場合、次のように配置できます:
P=2, Q=4(2行4列)
P=4, Q=2(4行2列)
P=1, Q=8(1行8列)
P=8, Q=1(8行1列)など
この配置は計算性能や通信効率に影響する重要な設計ポイントになります。このプロセス格子を単位にして、N×Nの巨大な行列を複数の正方形ブロックに分割して、2次元プロセス格子に対してブロックサイクリックに割り当てます。
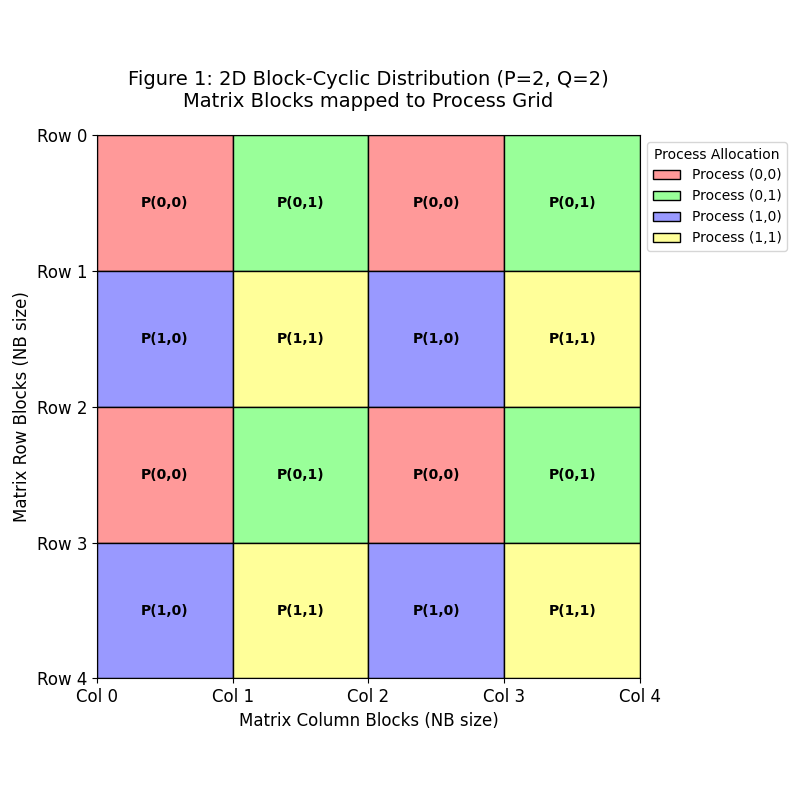
行列ブロック配置(4プロセス格子例 P=2,Q=2)
図1は、巨大なN×Nの行列が、どのようにして各プロセス(P=2, Q=2の計4個)に割り振られるかを示しています。行列全体をNB×NBの小さな正方ブロックに切り分け、プロセス格子(2行×2列)に沿って「囲碁盤」のように繰り返し配置します。色の意味として、同じ色のブロックは同一のプロセスが担当していることを示します。例えば、左上のブロックを担当するプロセスP(0,0)は、1つ飛ばした右隣や下のブロックも担当します。この方式のメリットとして、このように分散させることで、LU分解が進むにつれて計算対象のデータが減っていっても、特定のプロセスに仕事が偏らず、最後まで全プロセスが均等に計算を継続できるようになります。ロードバランスを図っているとも言えます。
HPLでは、全体の行列をPxQの格子に沿って分割して配置して、それぞれのプロセスが担当の部分を計算します。計算の中には、
・行方向に情報を送る(Qに依存)
・列方向に情報を送る(Pに依存)
といった通信(データのやり取り)が発生します。つまり、PとQのバランスによって、通信が効率的にできるかや、計算の負荷が均等に分散されるのかが決まってきます。一般的には、PとQの比率が偏りすぎない(例えば、P≒Qのように近い値)の方が良いとされています。ただ、ここは実際のプロセスが配置されている物理的な配線のトポロジーやレイテンシーなどにも影響を受ける部分で、HPLを動かす時にプロセスがどのように配置されているのかなど、最適なHPLのパラメータを探る際にイメージしておく必要があります。
加えて、HPLではプロセス間通信に「バイナリ交換(binary exchange)」のアルゴリズムが使用されています。このアルゴリズムは、プロセス数の2の累乗の場合に最も効率的に動作します。具体的にはプロセス数の2の累乗であると、通信ステップ数が最小限に抑えられ、全体の通信時間が短縮されます。
分割イメージ(NxNの行列の分割イメージ)
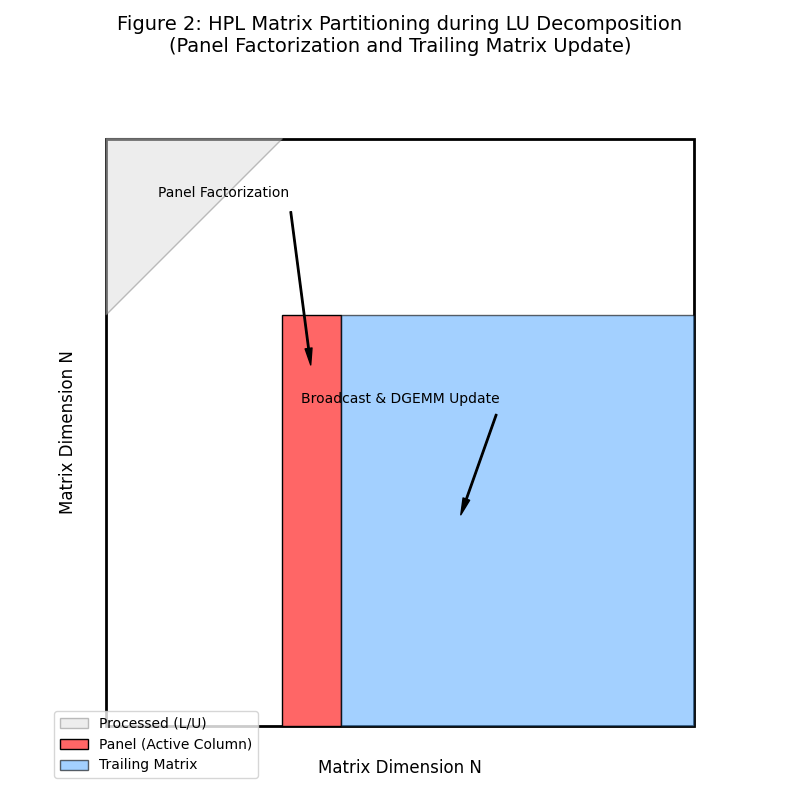
図2は、計算の各ステップにおける行列の論理的な分割状態を示しています。
- 細長い帯(Panel): 計算は左上から右下に向かって進みます。現在処理対象となっている縦長の領域を「パネル」と呼び、ここで「因数分解(Factorization)」が行われます。
- 残りの大部分(Trailing Matrix): パネルの計算結果が横方向のプロセスに回覧(ブロードキャスト)された後、右側の大きな未処理領域に対して、一括して行列計算(DGEMM)による更新を行います。
- 見越し実行(Lookahead): 図では単純化していますが、実際のHPLでは「現在のDGEMM」を計算している裏で「次のパネル」の通信や準備を進めることで、通信による待ち時間を隠蔽(オーバーラップ)し、高い実効性能を実現しています。
少し分かりにくいので、動きがわかるように、図3を用意しました。
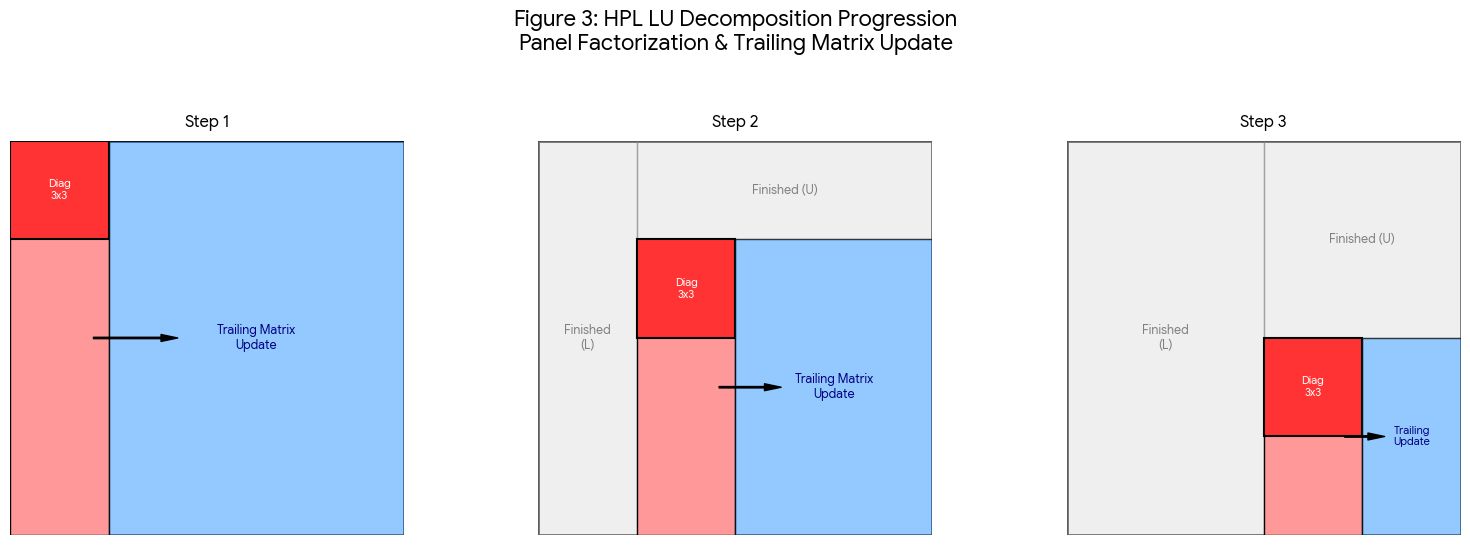
全体の行列N×Nが、ブロックサイズNB単位で左上から順次処理されていく3つのステップ(Step 1〜3)を示しています。
- Finished (L) / Finished (U) [グレー領域]: すでに計算が完了し、LU分解の結果が確定した部分です。ステップが進むごとに、左側と上側からこの領域が拡大していきます。
- Current Panel [薄い赤色領域]: 現在、処理対象となっている縦長の領域(幅NB)です。
- Diagonal Block [濃い赤色領域]: パネルの最も上にあるNB×NBの正方ブロックです。このブロックは、パネル全体を処理するための基準(ピボット)として最初に因数分解されます。
- Trailing Matrix [青色領域]: パネル(および対角ブロック)の計算結果を使って更新される、残りの未処理領域全体です。
矢印は、パネルの計算結果がブロードキャストされ、Trailing Matrix全体に対して行列積(DGEMM)による更新が行われることを示しています。反復プロセス図が示すように、各ステップで以下のサイクルが繰り返され、未処理の青い領域(Trailing Matrix)が右下へと徐々に追い詰められていきます。
- Step 1: 左上の最初のNBパネルを処理 → 残りの大きなTrailing Matrixを更新。
- Step 2: 1つ右にずれた次のNBパネルを処理 → 一回り小さくなったTrailing Matrixを更新。
- Step 3: さらに右のパネルを処理 → さらに小さくなったTrailing Matrixを更新。
この繰り返しにより、最終的に行列全体がLU分解されます。この図は、HPLが巨大な問題を小さなブロックに分割し、組織的かつ反復的に計算を進めている様子を明確に表しています。イメージとしては、巨大なジグソーパズルを適度な大きさに分け、必要なピースを上手に交換しながら、全員で同時並行に組み上げていく感じになります。
HPL実行におけるクラスターの事前検証の重要性
HPLのスコアを最大化させるための鍵は、単なる個々のノードの演算性能だけでなく、クラスター全体の均一性(Homogeneity)にあります。数千のGPUが密に連携する環境下では、クラスター内に存在するわずか1台の性能の低いノード(ストラグラー)が、システム全体のパフォーマンスを引き下げてしまいます。
先に説明したように、HPLのアルゴリズムは、行列をブロックに分割してプロセス格子に配分し、パネル分解の結果を列方向や行方向にブロードキャストしながら、計算を進めます。この過程で行う通信は同期的な性質を持つため、プロセス格子内のノードで通信遅延が発生すると、他の全てのノードはその完了を待たなくてはなりません。つまり、HPLの実効性能は、クラスター内で最も遅いノードの性能に引きずられる「ボトルネックの原理」に支配されています。
NCCL-testsによる「健康診断」
HPLの実行には膨大な電力と計算リソースを消費しますので、本番実行の前にNCCL-tests、特にAll-reduceベンチマークを実施することは有効です。NCCL(NVIDIA Collective Communications Library)(ニッケルと発音)はGPU間の通信を最適化するライブラリであり、All-reduceテストを行うことで以下の問題を事前にあぶり出すことができる便利なツールです。
- ハードウェアの不具合: インターコネクトのリンク速度の低下、ケーブルの半挿し、あるいはPCIeバスの帯域不足。
- ノードの個体差: サーマルスロットリング(熱による速度低下)が発生しやすいノードや、メモリ性能が微妙に低い個体の特定。
- OS/ドライバの設定不備: GPUドライバやネットワークスタックの設定が全ノードで統一されていない状況の確認。
「均一な母集団」の形成
NCCL-testsの結果から得られる「帯域幅(Bus-bandwidth)」や「レイテンシ」の分布を確認し、平均から大きく外れるノードを一時的に計算対象から切り離す(デコミッションする)ことで、クラスターを「健康で均一な母集団」に整えることができます。
実務的には、たとえノード総数が数%減ったとしても、異常な低速ノードを含んだまま計算を行うよりも均一な性能を持つノード群だけで構成した方が、最終的なHPLのFLOPS値(実効性能)は向上する場合が多いです。とはいえ、ここは一番悩ましいところで、利用できるノード数が変わるとPとQも変わるので、いろいろと試行錯誤が伴います。限られた時間の中で、不調なノードを治すことに時間をかけるか、切り離すかの判断は難しいです。
HPLのパラメータの決定方法
NVIDIAが提供するHPC-benchmarks(GPU最適化版HPL)は、標準的なNetlib版HPLとは異なり、GPUの演算性能を極限まで引き出すために内部ルーチンが高度に最適化されています。そのため、一部の伝統的なパラメータ(RFACTやPFACTなど)は内部で固定されていたり、無視されたりします。
さくらONEの構成である、H100を800基(100ノード × 8基)搭載したクラスターを例に、勝利(実効性能の最大化)を掴むためのガイドラインを4つのステップで解説します。
ステップ1:プロセス格子(P×Q)の決定
まず、計算ユニットをどう並べるかを決めます。基本ルールは「1 GPU = 1 MPI Rank」です。
- 合計プロセス数(P×Q): 800
- 配置の方針: P≦Qかつ、PとQは近い値にするのが定石です。
- HPLでは「パネル分解」の結果が横方向(Q方向)にブロードキャストされるため、Qをやや大きく取ると通信効率が上がることが多いです。
- 800の場合、有力な候補は20×40または25×32です。
- 推奨: 通信のバイナリ交換効率を考慮し、可能な限り2の累乗に近い数値を組み合わせます。まずはP=20, Q=40からスタートするのが一般的です。
ステップ2:行列サイズ(N)の計算
Nはスコアに直結する最も重要な値です。GPUのメモリを「溢れさせず、かつギリギリまで使う」必要があります。Nを算出する計算式は以下のようになります。
H100(80GB)のケースで上記に基づいて試算すると以下のようになります。
- 総メモリ:
- 利用率: 通常、OSやNCCLのバッファ分を除いた85%〜90%を狙います。
- 試算:
設定のコツとして、Nは後述するNBの倍数に設定する必要があります。さくらONEの事例(N=2,706,432)は、非常に攻めた(メモリ利用率90%超の)設定と言えます。
ステップ3:ブロックサイズ(NB)の設定
ここがGPU版の「特殊」なポイントです。
- 定石: 標準HPLではNB=128や256が使われますが、NVIDIA版では128や256、またはそれ以上(例:512, 768, 1024) が推奨されます。
- 理由: GPUのコア数が膨大であるため、1つのブロックを大きくしないと行列積(DGEMM)の計算密度が上がらず、GPUが「遊び」を起こしてしまうからです。
- ケーススタディ: H100クラスターではNB=1024で固定して考えるのが現在のスタンダードな最適解です。
ステップ4:NVIDIA版特有の挙動と調整
NVIDIA版HPLでは、HPL.datの後半にあるパラメータの多くが、環境変数によって上書きされたり無視されたりします。
無視される/重要度が低い項目
- PFACT, RFACT, NBMIN: これらはGPU内のカーネルで最適化されたアルゴリズムが動くため、何を指定しても性能への影響は軽微、あるいは無視されます。
- Depth (L1): 通信の「見越し実行(Lookahead)」の深さです。通常1または2を設定します。
HPLの実行時について
HPLの実行時においては、2つの事に注意しておいた方が良いです。
1つ目は、環境変数に何を指定しているのか、必ず関係する環境変数を全て確認しておいた方が良いです。スケジューラではデフォルトの環境変数が設定されているケースもあり、自分が設定していなくても、意図しない環境変数がセットされていない事を必ず確認してください。
2つ目は、HPLの実行時に「Testing HPL components 」というフェーズがあります。これはHPLの中で重要な演算の性能を測ってくれて、問題のあるノードなどを教えてくれるフェーズです。このログに現れるノード名は要注意のノードです。複数の項目で同時に現れる場合には、そのノードを外す際の判断材料を提供してくれます。情報量が多いので慣れるまでは利用が難しいですが、この部分をLLMに問い合わせるだけでも有用なアドバイスを受ける事ができます。システムにより値の分散は異なりますが、非常に有効ですので、試してください。
H100 100ノードクラスター(800 GPU)構成例
これまでの内容をまとめると、最初の計測用の HPL.dat 設定は以下のようになります。
| 項目 | 設定値 | 備考 |
|---|---|---|
| N | 2,703,360 | NBの倍数かつ 80GB×800の約90% |
| NB | 1024 | GPU計算効率を最大化するサイズ |
| P | 20 | 縦方向のプロセス数 |
| Q | 40 | 横方向のプロセス数 |
| P-MAP | Row-major | 標準的な行優先配置 |
チューニングの進め方
- 安全圏から開始: まずはメモリ利用率 80% 程度のNで完走を確認します。
- 不均一ノードの排除: 前述の通り、NCCL-testで遅いノードを特定し、もしあれば切り離します。
- 限界への挑戦: NをNB単位で徐々に増やし、"Out of Memory" が出る直前を攻めます。
- P:Q比率の微調整: 3で安定したら、ネットワークトポロジーに応じてP,Qの値の入れ替えなども試して、数%の改善を狙います。
おわりに
HPCクラスターを評価するベンチマークはHPL-MxPやHPCGといったものもありますが、今回はHPLについて紹介を行いました。どの場合でも共通しているのは、クラスターとして一体となって動作するベンチマーク(アプリケーション)では、常に均一の性能が出ているノード群を母集団になるように準備する事となります。その上でHPLの実行パラメータやNCCLの環境変数などを調整し、ベンチマークの実行を安定化させてベストなスコアになるように条件を詰めていく事が、良いスコアを出すための基本的な流れです。
最近のTOP500の上位はGPUを利用しているクラスターが大部分を占めていて、その多くはNVIDIAが提供するGPU用のHPLを使って測定する事が多いと思いますが、近年のNVIDAのGPUのアーキテクチャのBlackwell UltraやRubinではFP64/FP64 Tensor Coreの性能が極端に低くなり、代わりにFP16/BF16やFP8などのAIでの利用にシフトしたハードウェアの設計に移行しています。それをうけて、尾崎スキームなどの低精度演算を活用する手法が注目されていますが、現状のHPLルールではその利用は許されてはいません(NVIDIAのHPLには、機能としてはすでに実装済みです)。これからも大規模なクラスターが設計されHPLで評価をされると思いますが、FP64のハードウェア性能が高くない最新のGPUを採用した場合には、HPL(TOP500)のランキングは少し様変わりするのではないかと予想しています。
一方、AI用のベンチマークであるHPL-MxPが今後の主戦場となると思えるのですが、そちらでも利用できるのはFP16までのルールになっています。したがって、これから数年は、ハードウェアの進化の方向性や、これまで長くHPCのベースの性能評価指標であったHPLの位置づけが変わるかもしれない、目の離せない時期に来ていると思います。