さくらの高火力 PHYを利用した分散推論基盤の性能検証 〜高火力 PHYで作る分散推論基盤 vol.3〜

はじめに
さくらインターネットで高火力 PHYチームに所属している道下です。
本連載では、高火力 PHYで利用しているサーバーと同種のGPUサーバーを利用し、近年注目度を増しているLLMの分散推論基盤技術に関して詳細な技術調査や性能検証を行う中で獲得したナレッジを紹介しています。これまでの記事では、分散推論基盤に関する基本的な仕組みや考え方、さらにそれを支えるGPUDirect RDMAなどの技術やUCX、NIXLなどのソフトウェアについて詳細に紹介してきました。
今回の記事は、これまで議論を参考にしながら実際にPrefill-Decode Disaggregation(PD Disaggregation / Disaggregated Prefill)の効力について実測した内容を以下の順番で説明していきます。
- 課題設定
- 利用するソフトウェアスタックの詳細
- ベンチマークツールの選定
- ベンチマークパラメータの設計
- 検証環境の整理
- 性能検証の結果と考察
- 議論
上記の話に入っていく前に、これまでのおさらいを簡単にしようと思います1。
これまでのおさらい
SLOベースの最適化とPD Disaggregation
第一回の記事の中で、LLM推論におけるシステムの性能指標と、それに基づいたSLO・SLAの設計の重要さに触れ、このSLO・SLAを軸とする最適化について議論しました。
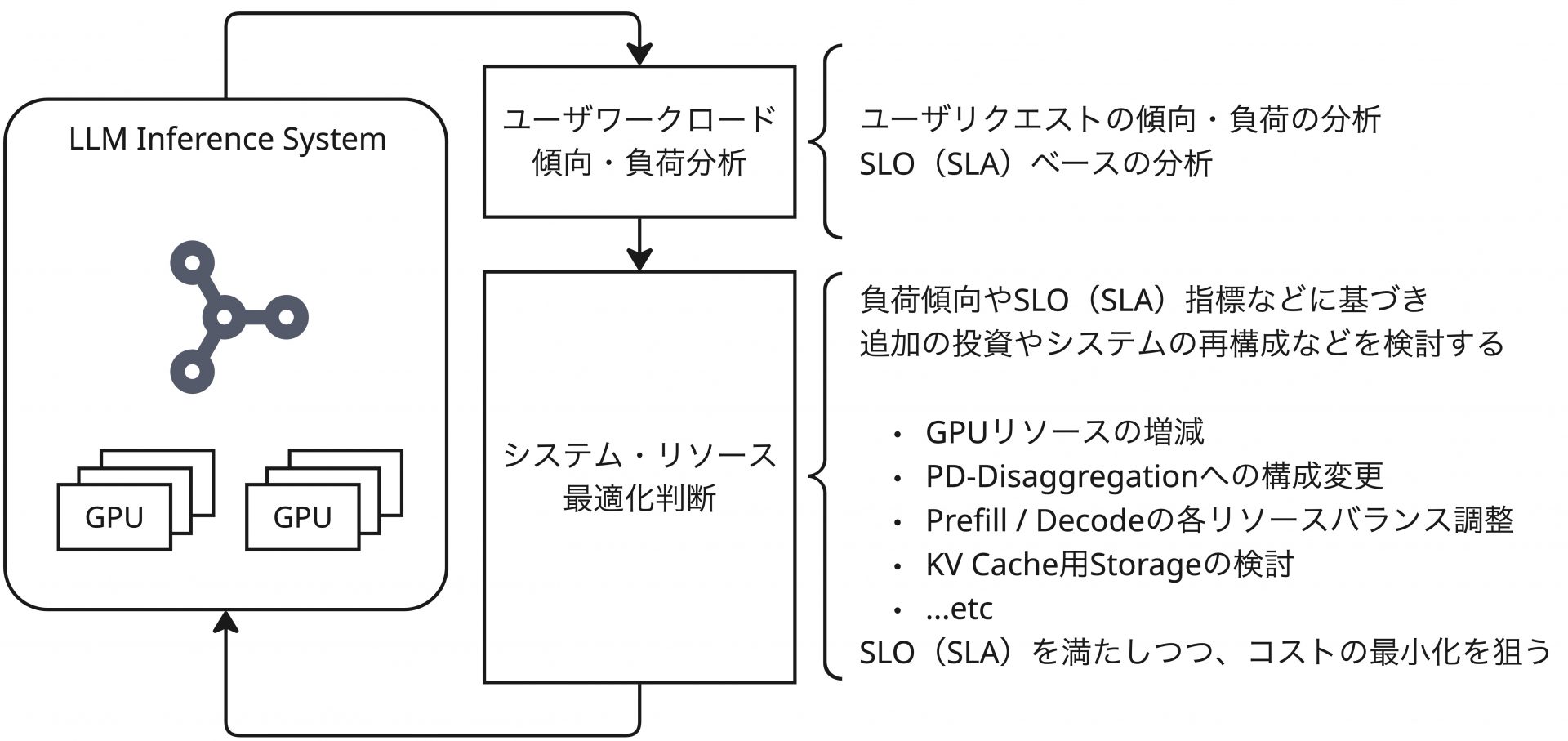
また、具体的な議論として、推論リクエストに対してのバッチ処理の課題と、PD Disaggregationという手法による解決方法について紹介しました。
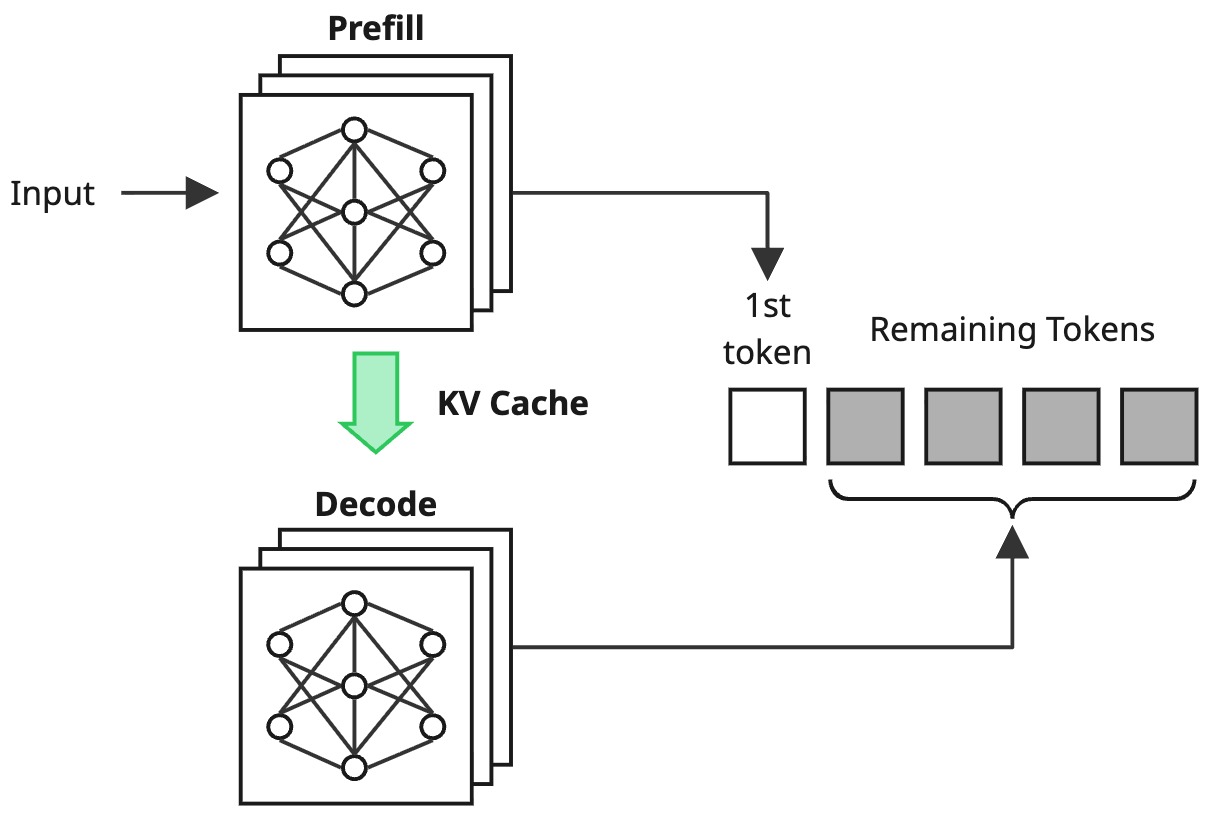
一方で、PD Disaggregationは状況によりコストがかかるソリューションであるため、厳密なSLO、SLAの定義のない環境や小規模環境においてはメリットが薄い点や、KV Cacheの転送に伴うインフラへの追加要求といった側面でも議論しました。この議論を実際のプロダクション環境を構築する際の意思決定に反映するには、より具体的な測定データに基づく判断を行いたくなります。すなわち、「どのような状況では、どの程度の性能を達成でき(= SLO・SLAを守ることができ)、その構成にはどの程度のコストがかかるのか」ということを把握する必要があります。
以降の内容では、私が実際に行ったベンチマークをもとに、これらの内容について踏み込んでいきます。
性能検証における課題設定
PD Disaggregationは、推論処理におけるPrefillとDecodeで明確に異なるボトルネックを分離し、それぞれを最適化可能にする重要な技術でした。また、バッチ処理の観点からITLのTail Latencyに大きく寄与する可能性があるということにも触れてきました。一方で、私はこの技術に対して、素朴に以下のような疑問を抱きました。
- 小規模な環境においても、PD Disaggregationのメリットが十分に出るのか?
- Prefill処理が重い環境と重くない環境では、この構成はどの程度効果が変わるのか?
前者はコスト面を意識した疑問になります。GPUのような非常に高価なリソースを潤沢に保有し、推論用途として好きなように利用できる環境というのは世界的にも限られています。このような企業では、PD Disaggregationの構成の採用はごく自然と言えますが、多くの企業では限られたリソースを利用するという方針から始まるでしょう。その上でビジネスとしてのROIを考慮すると、小さい規模でサービスを立ち上げ、収益性の見通しや収容ユーザー規模によって順次スケールさせていく、という戦略になることが想定されます。この前提では、特に事業の初期フェーズはGPUのリソースは限られることが想定され、そもそもPD Disaggregationするほどのリソースの余裕はない、もしくはPD Disaggregationのために追加のリソースを投資しなければならないというケースは十分考えられます。
後者は現実的なワークロード負荷とPD Disaggregationの有効性についての疑問です。PrefillとDecodeが同一のバッチとして処理されることによって生じる課題は、Prefillの入力長やその際のワークロード負荷に強く依存して顕在化することが想定されます。大規模に多様なユーザーを収容している既存のAIサービスとは異なり、事業初期の環境などにおいては、利用ユーザー数も限られ、ワークロード負荷の高くない散発的な推論リクエストにとどまるという状況は十分に考えられます。この場合、現実問題としてPD Disaggregationによるメリットはどの程度もたらされるのかは冷静に判断するべきだと考えられます。
今回の記事では、これらの疑問を解消するための実測について詳細に解説しながら、実際に得られた結果について議論を行います。推論ベンチマークは考慮すべきパラメータが非常に多いため、ベンチマークの設計が甘いと意図した計測ができていないという形に直結しかねません。従って、以降では「性能検証の設計」についても詳細に議論していきます。表に出ているパフォーマンスベンチマークの結果はもちろん有意義ですが、その計測パラメータが意味しているワークロードを正しく解釈する必要があり、その内容が本当に自身のインフラに対して意味のある測定なのかを理解する必要があります。
性能検証の設計
検証で利用するソフトウェアスタックの詳細
ベンチマーク設計の具体的な議論を始める前に、まずは今回の検証で利用するソフトウェアについて説明します。今回の検証では、大規模な環境を構築するような複雑なソフトウェア構成(NVIDIA Dynamoやllm-dなど)は避けました。これは、想定外のボトルネックを作る可能性を排除したいという意図と、もしソフトウェア自体の解析が必要になった場合、可能な限りそれを容易にしたいという狙いがあったためです。
具体的には過去の連載で紹介した、UCX、NIXL、vLLMの他に、LMCacheというソフトウェアを含めた以下の構成で検証することにしました。
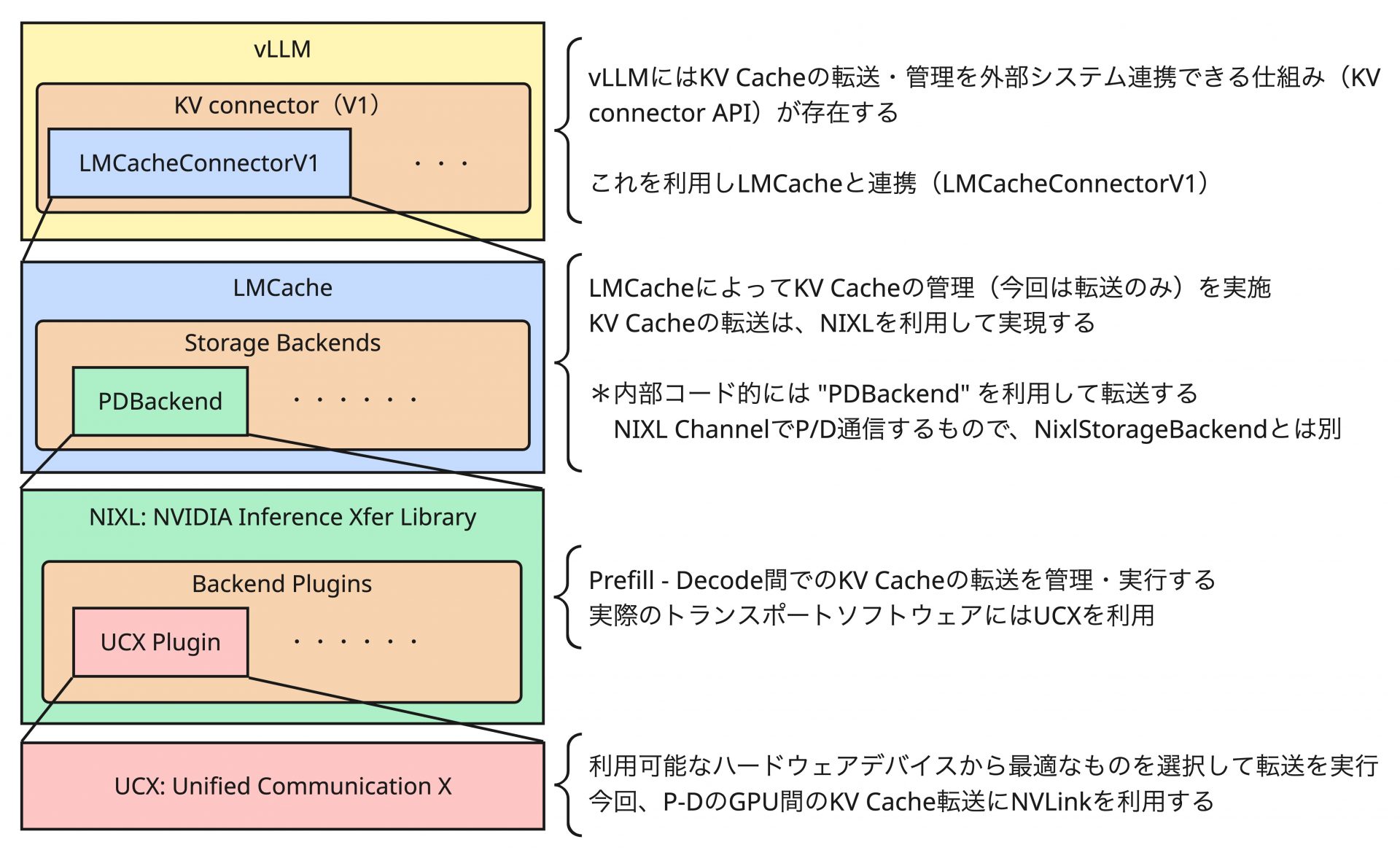
LMCacheはKV Cacheを管理、転送するための高度な機能を提供するソフトウェアになります。今回は、LMCacheが提供する、NIXLを利用したP2Pデータ転送機能のみを利用し、PD Disaggregationを実現しています。実際は、vLLM単体でもNIXLとの組み合わせによってPD Disaggregationは実現可能ですが、LMCacheは次回以降の連載で改めて取り上げる予定があり、記事の一貫性の都合なども踏まえて今回の検証においても採用しています。そのため、今回の検証環境は最小構成というわけではありませんが、プロダクションを意識しつつ、困った時に直接実装を把握し解析が可能な現実的なラインのソフトウェアスタックになっています。
検証環境におけるPD Disaggregationの詳細
ここからは、今回の環境におけるPD Disaggregationの処理について少しだけ踏み込んで解説していきます。LMCacheによるNIXLを利用したPD Disaggregationでは、PrefillとDecode間はNIXLによってデータ転送のチャネルを貼りKV Cacheのデータ転送を行います。NIXLのデータ転送の処理の大まかなフローは前回の記事で紹介した通りであり、これをLMCacheが内部のロジックとして持っています。NIXLでは、メタデータの交換などの都合上、Prefillインスタンス(以降、Prefiller)とDecodeインスタンス(以降、Decoder)の間で通信を行う必要がありますが、LMCacheではこれをZMQを利用して実施しています。Decoder側でZMQ Serverを起動し(LMCacheの設定における、pd_peer_init_port、pd_peer_alloc_portがZMQのポート番号に該当する)、Prefiller側から接続して必要なメタデータの交換やメモリー確保要求などを行います。ただし、Prefiller側のLMCacheの設定にはDecoderのZMQに関する情報はなく、該当の情報は推論リクエスト内部に埋め込まれていることを想定します。
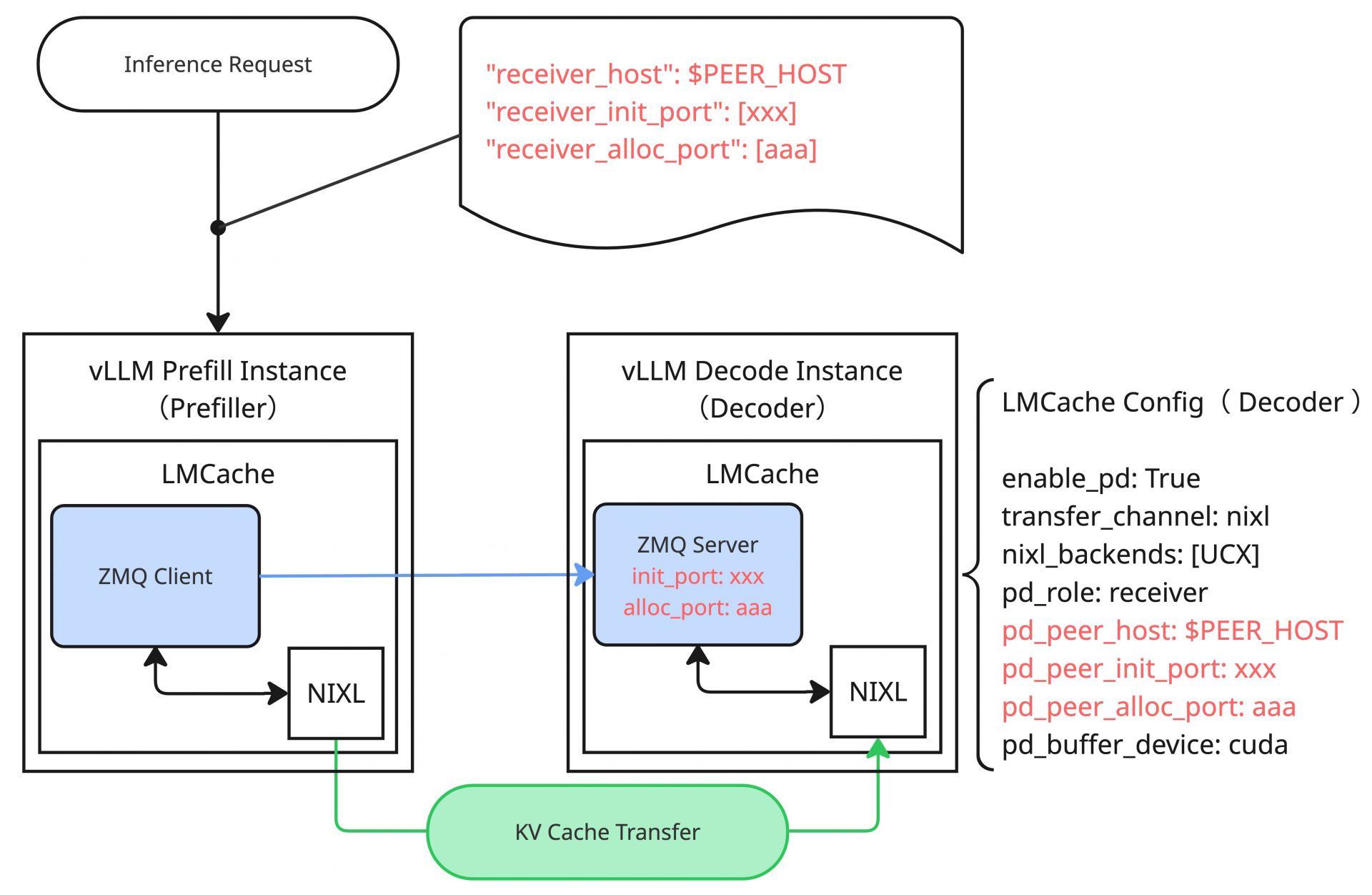
一方で、通常のユーザーの推論リクエストには当然これに該当する情報は含まれません。ここで登場するのがPD Disaggregation用のProxyサーバーという存在です。今回はLMCache公式のexamplesに存在しているdisagg_proxy_server.pyという最もミニマムな実装のProxyサーバーを利用するため、この実装をベースに話を進めていきます。
このdisagg_proxy_server.pyは起動時に次のようなパラメータを伴います。
python3 disagg_proxy_server.py \
--host localhost \
--port 9100 \
--prefiller-host localhost \
--prefiller-port 7100 \
--num-prefillers 1 \
--decoder-host localhost \
--decoder-port 7200 \
--decoder-init-port "7300,7301" \
--decoder-alloc-port "7400,7401" \
--num-decoders 1 \
--proxy-host localhost \
--proxy-port 7500| Parameter | Description |
|---|---|
--host | ユーザーリクエストを受け付けるホスト名/IPアドレス |
--port | ユーザーリクエストを受け付けるポート番号 |
--prefiller-host | ユーザーリクエストをフォワードするPrefillerのエンドポイントのホスト名/IPアドレス(カンマ区切り複数指定可能) |
--prefiller-port | ユーザーリクエストをフォワードするPrefillerのエンドポイントのポート番号(カンマ区切り複数指定可能) |
--num-prefillers | Prefillerの数 |
--decoder-host | Prefillerから処理を委譲するDecoderのエンドポイントのホスト名/IPアドレス(カンマ区切り複数指定可能) |
--decoder-port | Prefillerから処理を委譲するDecoderのエンドポイントのポート番号(カンマ区切り複数指定可能) |
--decoder-init-port | Decoderで起動するNIXLのコントロールパス用のZMQサーバーのポート番号(NIXL初期化に利用) |
--decoder-alloc-port | Decoderで起動するNIXLのコントロールパス用のZMQサーバーのポート番号(Decoderへのメモリー要求リクエストなどに利用) |
--num-decoders | Decoderの数 |
--proxy-host | Prefillerから受け取るKV Cacheに関する通知用ZMQ Serverのホスト名/IPアドレス(基本的には、--hostと一致) |
--proxy-port | Prefillerから受け取るKV Cacheに関する通知用ZMQ Serverのポート番号 |
このProxyサーバーはユーザーからの推論リクエストに対するProxyとして動作するため、リクエストを転送する先のPrefillerやDecoderの接続情報を持ちます。その他に重要なこととして、起動時パラメータにある通り、ProxyサーバーはDecoder側のZMQに関する情報も持っています。また、PrefillerからKV Cacheに関する通知を受け取るために専用のZMQ Serverを内部的に起動します。Prefiller側のLMCacheの設定には、このKV Cache通知用のZMQ Serverの情報(pd_proxy_host、pd_proxy_port)を記載することになります。
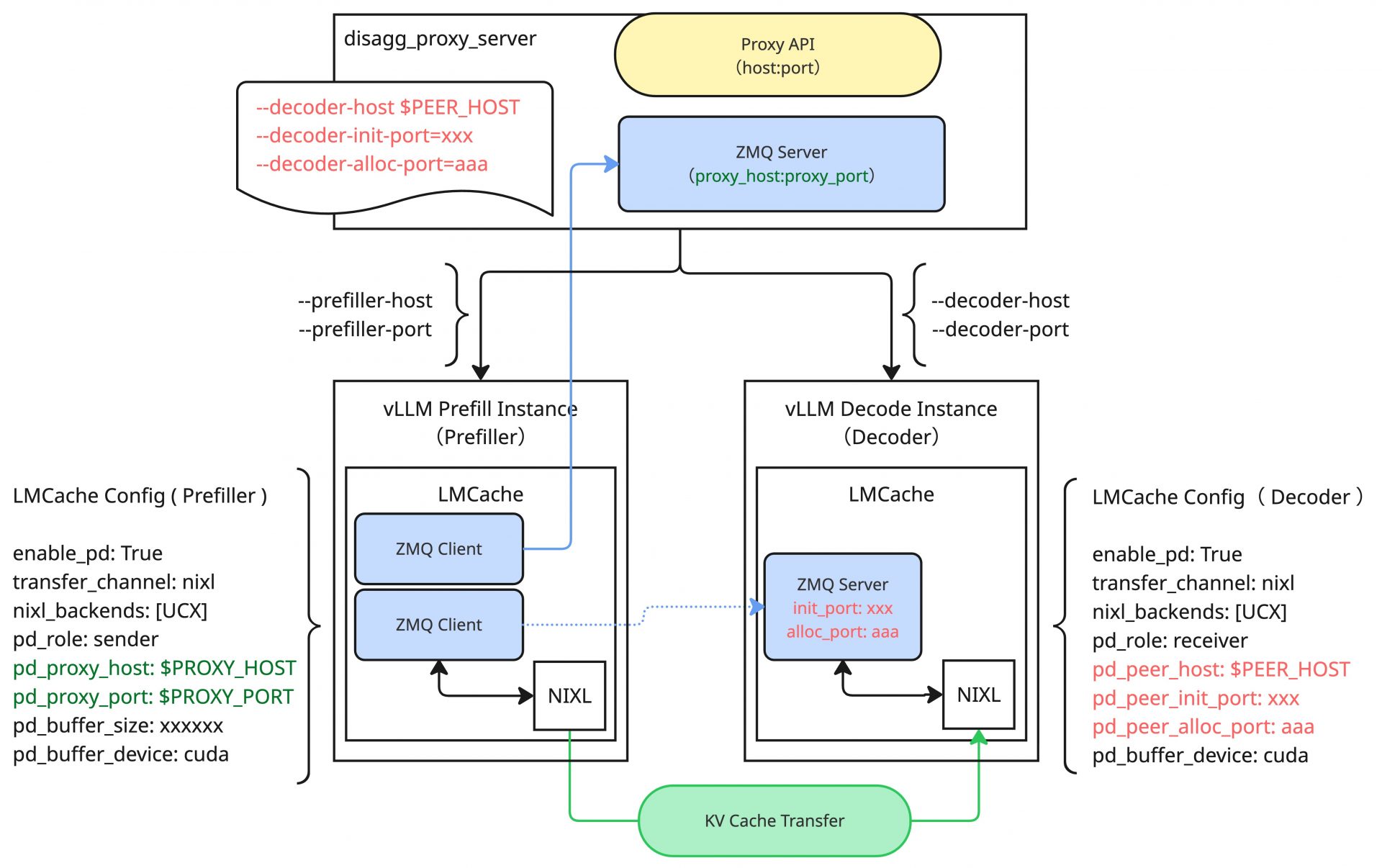
注目すべき点として、この段階ではまだPrefillerはNIXLの通信を実施するために必要なDecoder側のZMQの接続情報を知りません。
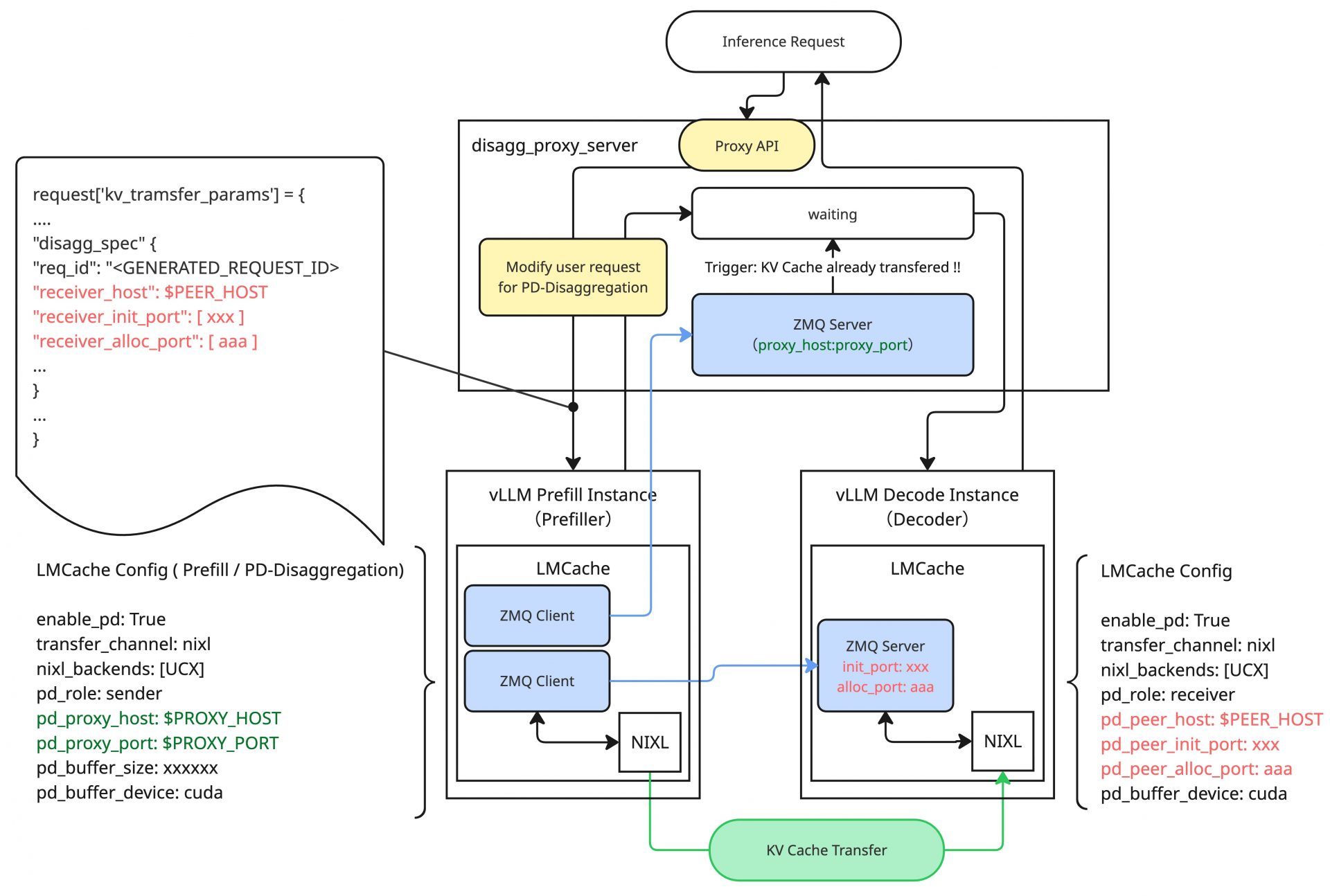
ここで、実際の推論リクエストをProxyサーバーが受けると、その推論リクエストの中身を一部書き換えてPrefiller側にPOSTします。この際に以下のような書き換えを行います。
- リクエストの内容を確認して
max_tokensの値を控え(後段の処理のために)、max_tokens = 1で上書き - DecoderのZMQに関する情報を
kv_transfer_config.disagg_specのパラメータとして書き込む
この変更により、Prefillerの受け取る推論リクエストは「1 Tokenを生成するだけ」になり、かつ「Decoderの情報を保持している」ものになります。Prefillerでは推論処理の過程の中でKV Cacheを作成し、1 Tokenを生成して、Proxyサーバーへ返却します。そして、作成したKV CacheをDecoderに転送するための処理(DecoderのZMQへのコネクションの確立、初期化要求、メモリー確保要求など)を進め、NIXL経由でDecoderにKV Cacheを転送します。推論処理の応答に対して、KV Cacheの転送は別スレッドで行われるため、ProxyサーバーはPrefillerから応答を受け取ったあと、KV Cacheの転送が完了した通知を受け取るまでの間、Decoder向けのリクエストを作成(max_tokensの復元や、生成された1 Tokenのプロンプト末尾への追加など)して待機します。PrefillerはKV Cacheの転送を終えると、ProxyサーバーのZMQに対して通知を送り、これを受け取ったProxyサーバーはDecoder側に待機していたリクエストを実行します。以降は、Decoderから返される内容をそのままユーザーに返却します。
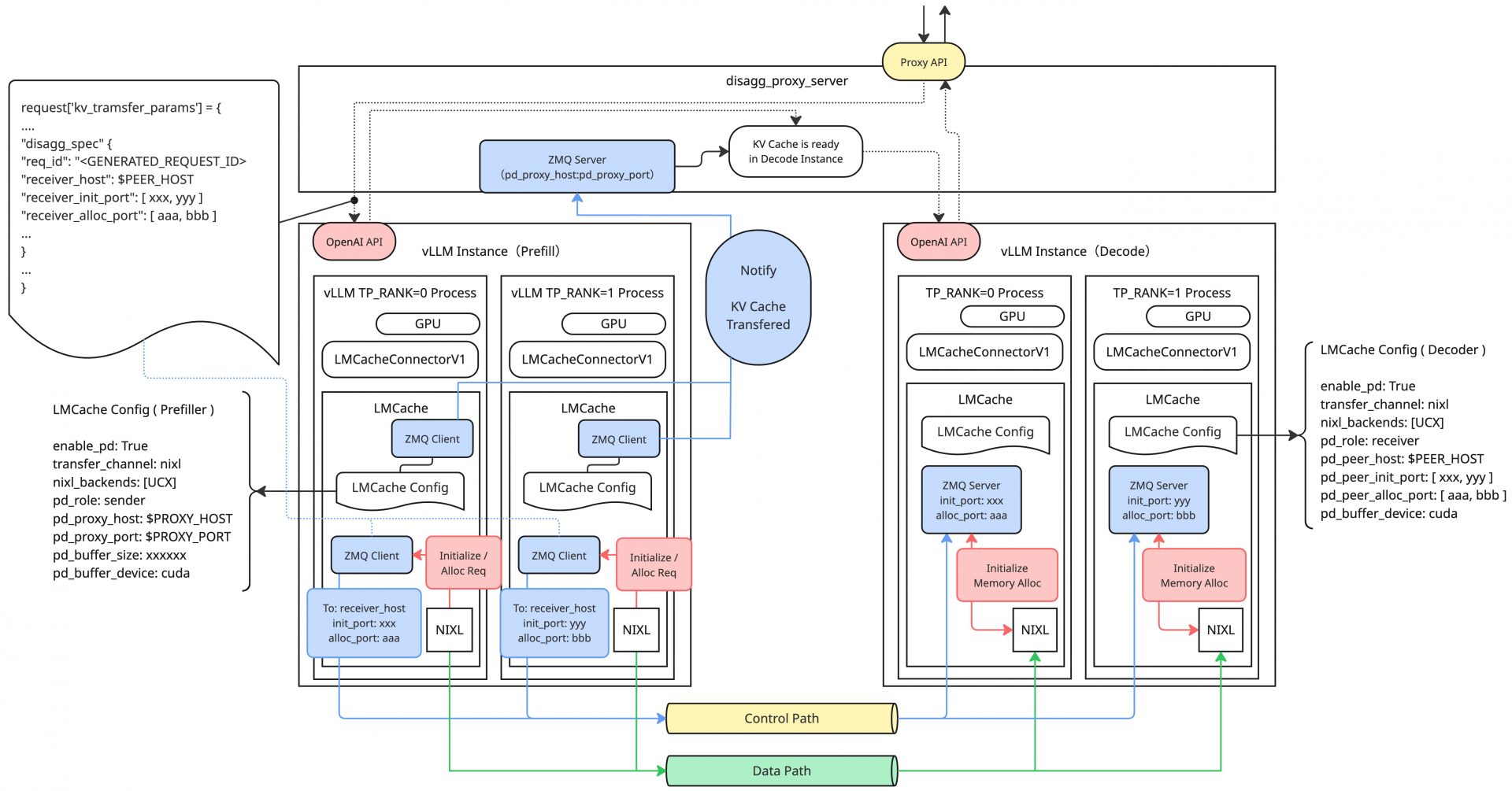
上記の内容を複数GPUを利用する場合(Tensor Parallel / TP)に拡張した全体図は次のようになります。disagg_proxy_server.pyからPrefillに渡されるDecoder側のポート情報はリストの形式で渡されるため、各TPのRank情報を利用して自身が接続するべきポートを一意に特定します。また、説明は省略しますが、複数のPrefiller、Decoderで構成する場合も、基本的には同様の構成になります。
検証環境についてのソフトウェアスタックの整理と説明が終わったので、ここからは具体的なベンチマークに関する話に入ります。まずはベンチマークツールの選定の話、次いでベンチマークパラメータの設計の話に進みます。
ベンチマークツールの選定
性能検証を行うにあたり、まずはベンチマークツールの選定を行う必要があります。推論基盤の性能を測定するためのツールはいくつか存在していますが、今回は「GenAI-perf」「vllm bench serve」「inference-benchmarker」の3種類のベンチマークを選択し、実行可能な処理の内容や一部のツールについては内部実装の確認などの整理を行いました2。
ベンチマーク測定において重要となるいくつかのパラメータについて、それぞれのツールがどの程度対応しているかをまずは確認する必要があります。今回取り上げた3種類のベンチマークツールについて、私の要求するベンチマークパラメータをどの程度サポートしているかを表にすると次のように整理されました。
| Parameter | GenAI-perf | vllm bench serve | inference-benchmarker |
|---|---|---|---|
| 入力長の変更 | ⚪︎ | ⚪︎ | ⚪︎ |
| 出力長の変更 | ⚪︎ | ⚪︎ | ⚪︎ |
| 入力データセットの調整 | ⚪︎ | ⚪︎ | ⚪︎ |
| RPS制御 | ⚪︎ | ⚪︎ | ⚪︎ |
| 同時接続数の制御 | ⚪︎ | ⚪︎ | ⚪︎ |
| ITL測定 | ⚪︎ | ⚪︎ | ⚪︎ |
| TTFT測定 | ⚪︎ | ⚪︎ | ⚪︎ |
| 任意のP値測定 | △ | ⚪︎ | × |
いずれのベンチマークも基本的な測定項目については要件を満たしていますが、それぞれのベンチマークにも特性があるため、細かい部分についてのサポートの有無や、データが容易に取り出せそうかどうかの違いがありました。当然ですがこの違いはベンチマークツールの良し悪しという話ではなく、あくまで「私が測定したい項目、および解析フローに対して最も適しているかどうか」というバイアスの乗った議論です。今回の測定においては、vllm bench serveが最も直感的かつ簡単に利用でき、調整可能パラメータ、取得可能なデータに関して十分カバーしていたため採用に至りました。加えて、vllm bench serveはそもそもvLLMに同梱されているツールであることや、さまざまな場面でよく利用されるツールであることも採用の後押しとなりました。
さて、上記のベンチマークパラメータですが、まだ具体的に説明していません。以降では、その説明に加え、どのようにパラメータを設定し、どのようなワークロードを模擬したかを詳しく解説していきます。
ベンチマークパラメータの詳細設計
ベンチマークツールが決まったので、詳細なパラメータ設計に入ります。改めて、今回の検証の主目的は以下の2項目でした。
- 小規模な環境においても、PD Disaggregationのメリットが十分に出るのか?
- Prefill処理が重い環境と重くない環境では、この構成はどの程度効果が変わるのか?
これらを測定するためには、入力長の調整やワークロード負荷(リクエストレートや同時リクエスト数)を細かく設定できる必要があります。今回は以下のようなパラメータを設計し検証を行いました。
| Parameter | value | Description |
|---|---|---|
--dataset-name | random | リクエストする入力内容のデータセット設定 |
--random-input-len | 1k, 8k | random datasetにおける入力長模擬したいワークロードのリクエスト毎の入力長を定める |
--random-output-len | 1k | random datasetにおける出力長模擬したいワークロードのリクエスト毎の出力長を定める |
--request-rate | inf | リクエスト送信レート(詳細は後述) |
--max-concurrency | 1, 2, 4, 8, 16, 32 | 最大の同時接続数(詳細は後述) |
--num-prompts | ${--max-concurrency} x 10 | ベンチマークで処理するプロンプトの数(終了条件) 今回は「最大の同時接続数 x 10」のプロンプトを処理したら停止としている |
上記のパラメータについて、図を交えて説明します。
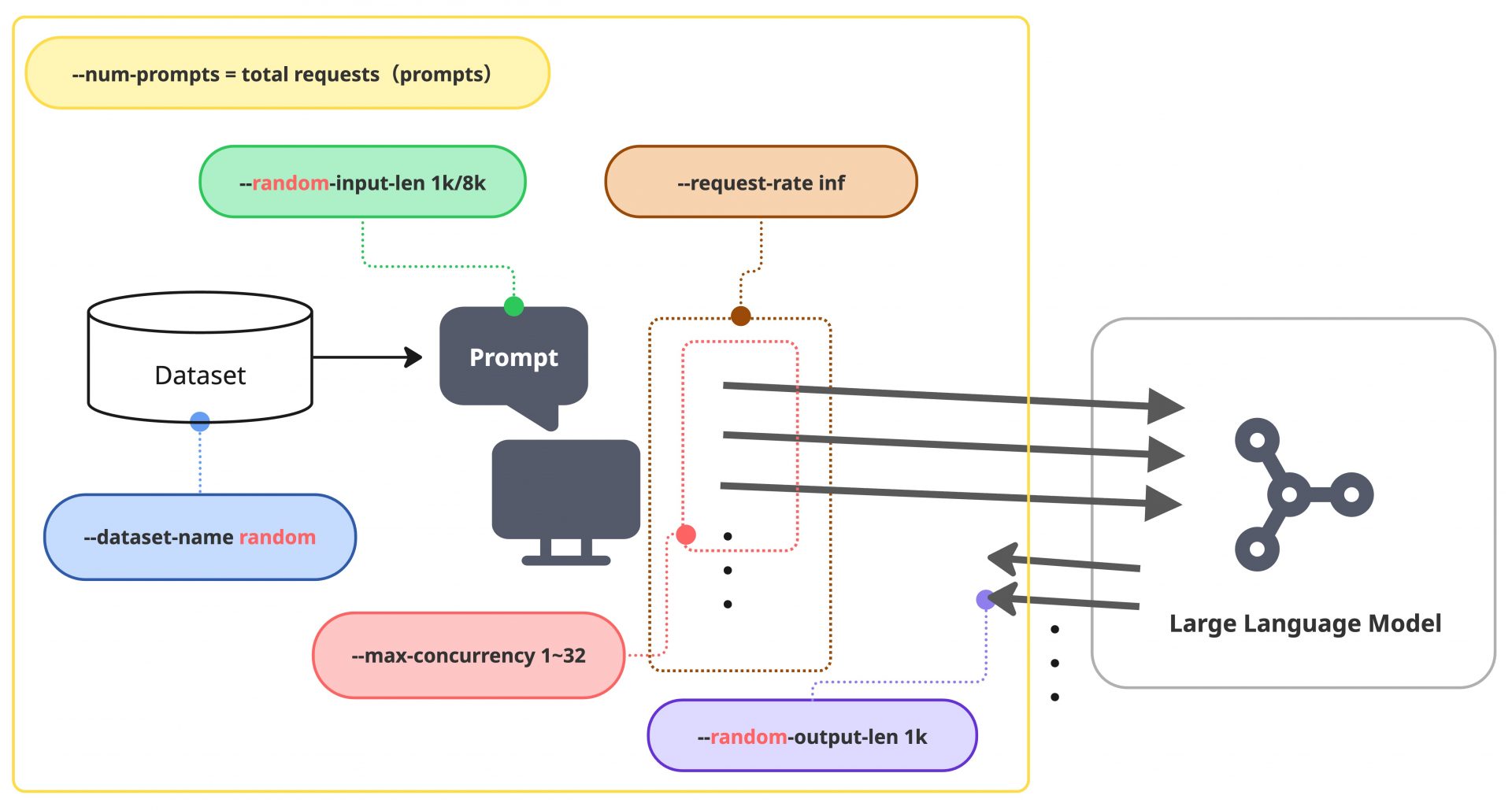
まずは各リクエストに関与する設定として、データセットや入力、出力長に関連するパラメータを決定します。データセットの設定(--dataset-name)は入力Tokenの様相を決定し、入力長、出力長のパラメータ(--random-input-len / --random-output-len)によって、各リクエストの様相を定めます。vllm bench serveで入出力長が変更できるデータセットはrandomかsonnetになります。randomデータセットはその名の通り、乱数をベースとしてToken IDを生成し、指定した長さに一致するようにプロンプトを構築します。一方でsonnetはあらかじめ用意されたテキストファイルからテキストのブロックをサンプリングしてプロンプトを構築するため、自然言語の様相を反映しているものの、指定した入力長には完全に一致せず、指定値に近い長さを持ったプロンプトになります。今回はrandomデータセットを選択し、具体的な入力長の設計として長いケースを8k、短いケースを1kと定め、この二つのパターンで測定することにしました。また、出力長は極端に短くなりすぎない程度を想定して 1k で固定としています。
続いて、ベンチマーク全体のワークロード負荷に関するパラメータについて決定します。ここでは--request-rateと--max-concurrencyは負荷の模擬において極めて重要であり、かつ密接に連動する設定値です。--request-rateはクライアント(送信側)が指定された目標レート(RPS: Requests Per Second)に従って、一定間隔でリクエストを送信しようと試みる設定です。しかし、サーバーの処理能力がこのリクエストの到達レートに追いつかない場合、処理が完了しないリクエストはシステム内に滞留し始めます。これはクライアント側からすると、In-flightなリクエストの数が徐々に増えていくことになります。
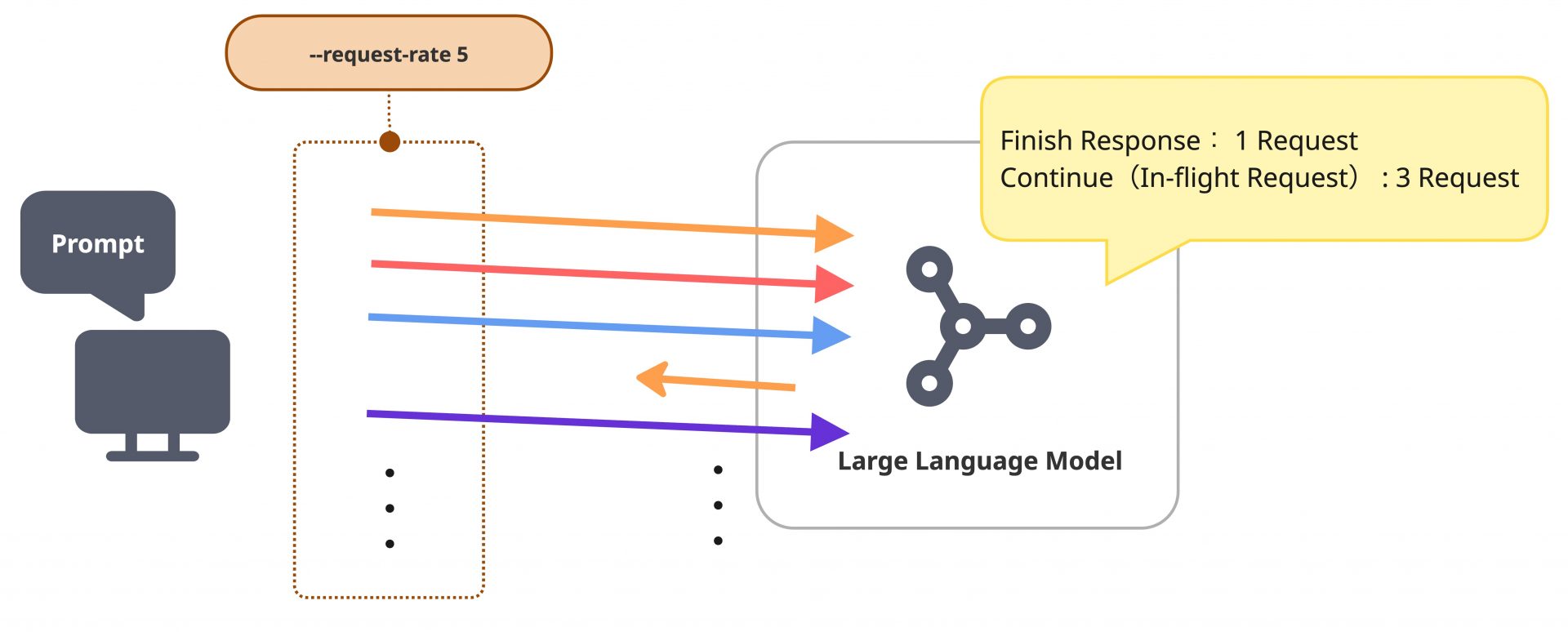
ここで、--max-concurrencyを同時に設定している場合、クライアントが同時に実行できるリクエスト数に上限が設けられます。サーバーの処理遅延によって未完了のリクエスト数がこの上限値に達すると、クライアントは既存のリクエストが完了するまで新しいリクエストの送信を待機します。結果として--request-rateで高い目標送信レートを設定していたとしても、--max-concurrencyによる送信ブロックが継続的に発生することで、実際の送信RPS自体が指定値を下回る現象が発生します。
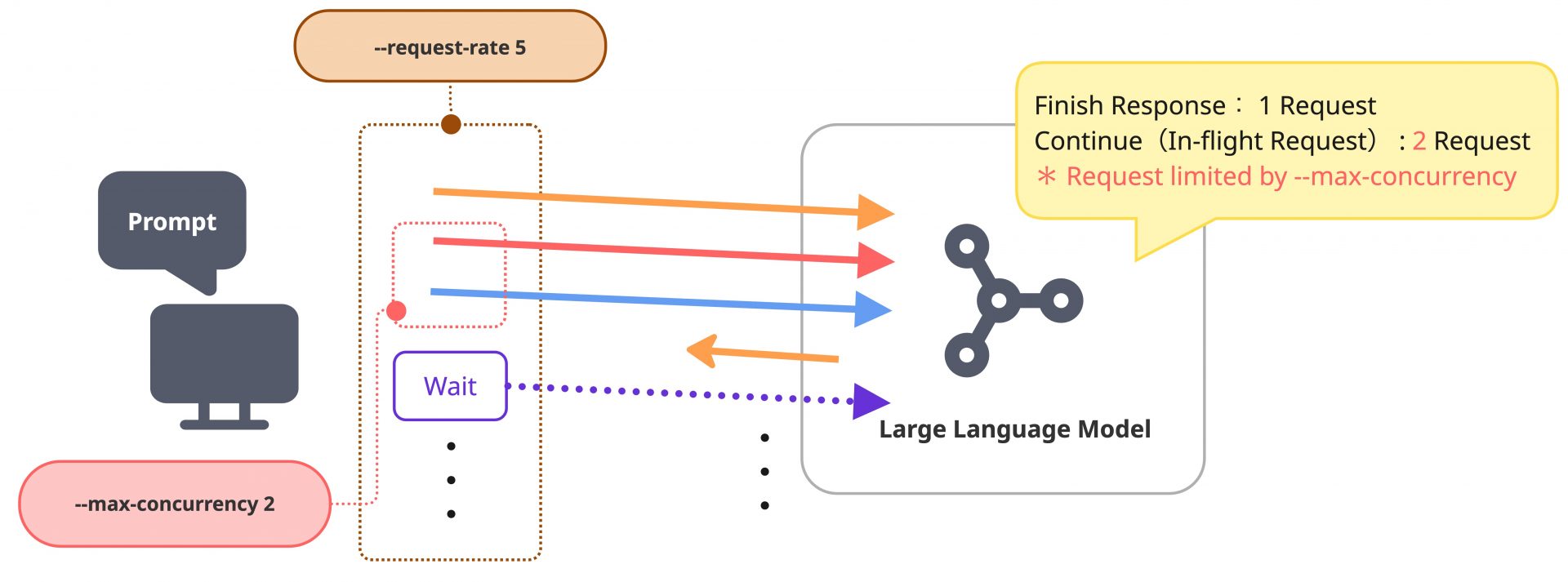
今回は、--request-rate infを指定し、--max-concurrencyは調整パラメータ(1~32)としています。前者の設定は、送信側における時間ごとのレート制限を取り払うもので、送信間隔をおかずにリクエストを送り続けることを意味します。しかし、後者の設定によって、実際はIn-flightなリクエスト数に対して--max-concurrencyで指定した数の制限がかかります。つまり、このパラメータ構成は「システムに対して、指定した同時接続数(並行数)分の処理要求が常に途切れることなくかかり続ける」という連続的な負荷状態を模擬しています。
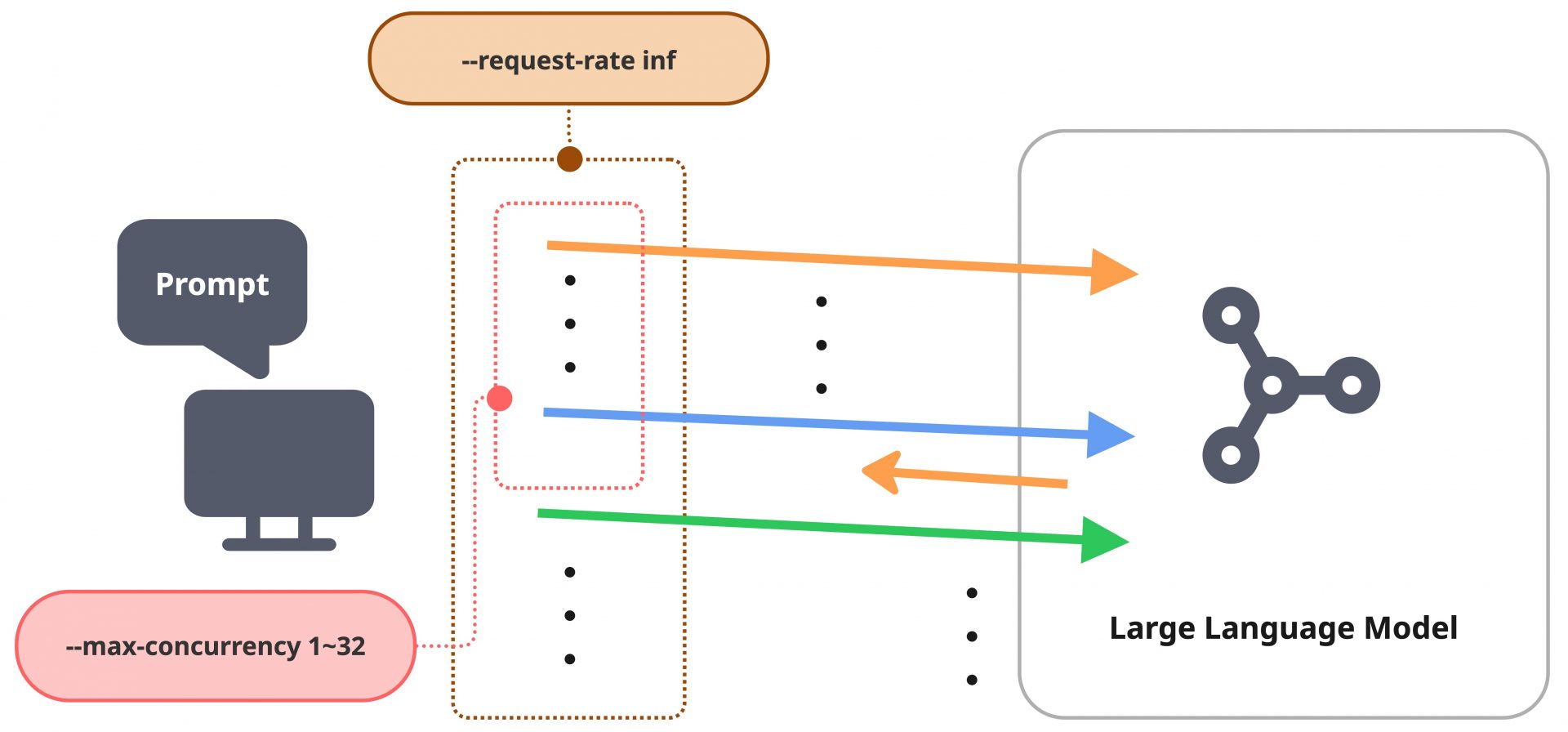
ここまでパラメータ設計について紹介してきましたが、注意すべきこととしては、このベンチマークはあまり現実のユーザーワークロードを模擬していないということです。randomベンチマークの採用や、高ワークロードを負荷を継続的にかけるという設計は、いわゆる負荷試験の意味合いが強いベンチマーク設計になっています。
今回の検証の目的は、あくまでPD Disaggregationという技術を採用することで獲得されるシステムの性能特性にフォーカスした測定項目であるため、上記のようなパラメータ設計にしています。一方で、このパラメータ設計は「実際のユーザーワークロードを模擬したもの」ではないので、その点においては注意して結果を論じる必要があります。「ユーザーワークロードの模擬」という側面に立つと、ShareGPTをデータセットとして採用することや、--request-rateを適切な値に設計すること、--burstinessの調整によるユーザーのリクエスト分布の調整などを行うべきでしょう3。
検証環境
今回の検証では、PD Disaggregationの効果を比較検討するために、PD Disaggregationを採用しない構成(以降、Aggregatedと呼称)で同様のベンチマークを実施します。Aggregatedで測定する場合は、トータルで利用するGPU枚数を揃えて比較するようにしました。いずれの構成においても、上述で設計したパラメータを利用して vllm bench serve でベンチマークを実行します。
検証には、高火力 PHYで提供しているHGX H100サーバー(H100 GPU x 8)と同種のものを利用しています。今回の検証ターゲットは小規模環境ということもあり、1台のサーバー上で実現できる範囲での検証としています。そのため、GPUサーバー間のインターコネクトは利用しませんが、サーバーに搭載されているScale Up Network(NVLink)は利用し、PD DisaggregationにおけるKV Cacheの転送はScale Up Network経由で実現されます。これらの技術的詳細は第二回の記事で言及した通りです。
採用したモデルはgpt-oss-120bであり、量子化なし、コンテキスト長制限なしで起動させることにしました。また、PD Disaggregationの構成ではNIXLのKV Cache転送用のバッファの確保などを行う必要があり、余分な性能上のボトルネックを回避する目的からGPUメモリー上でバッファを確保する設定にしました。この条件下において、vLLMで当該モデルをサーブする最小要求としてはH100 GPUが2枚になりました。従ってPD Disaggregationの構成では、Prefill用に2枚、Decode用に2枚の合計4枚のGPUを最小要求として利用することになり、Aggregatedでもこの枚数に合わせる形で合計4GPUを利用しました。
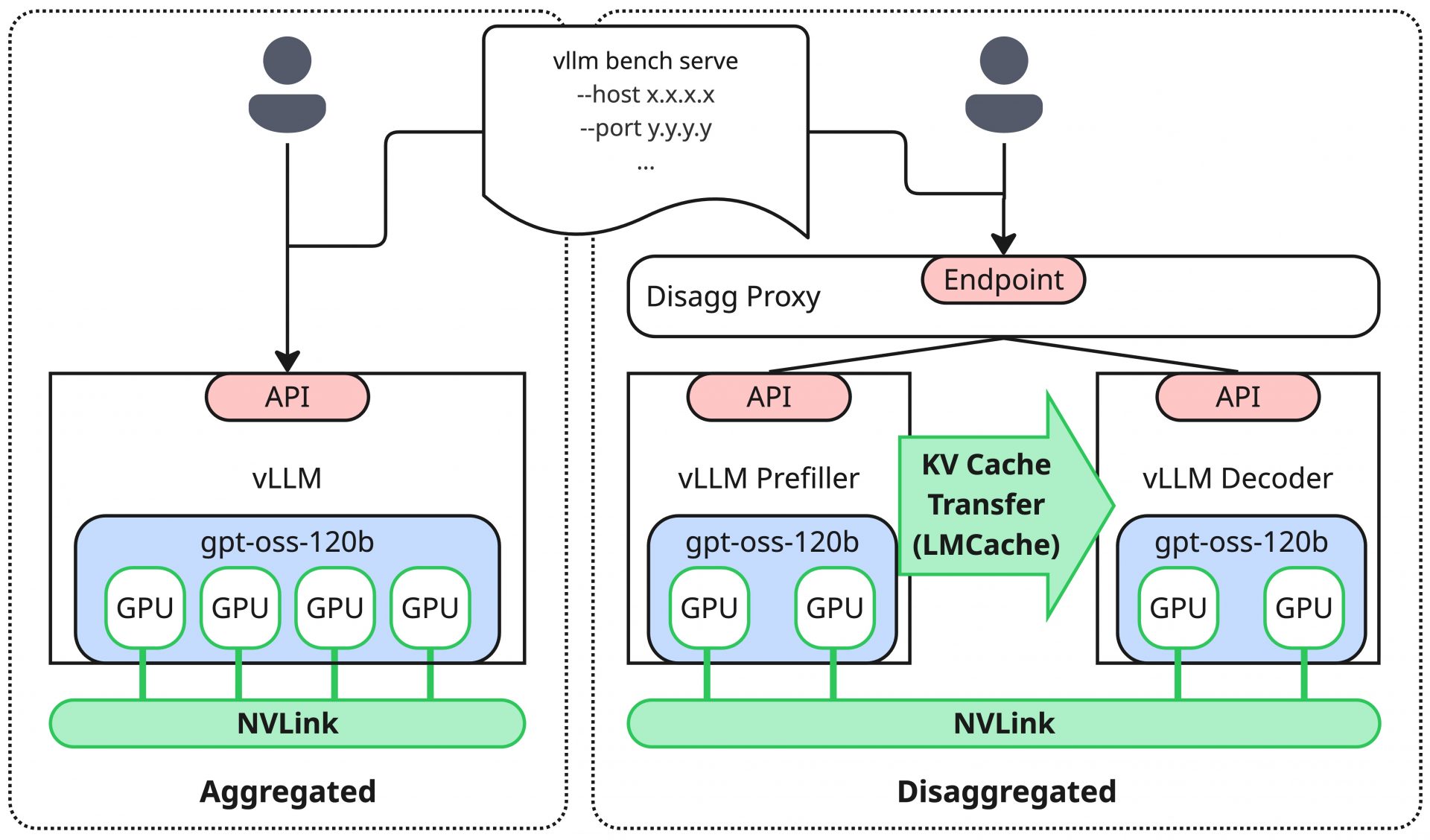
また、今回利用したソフトウェアのバージョンは以下の通りです。基本的には前回記事と同様で、LMCacheを新しく追加しています。LMCacheは検証当時の最新バージョンを利用していますが、現在の最新からはやや離れています。
| Package | Version |
|---|---|
| nvidia-driver-580-server-open | 580.95.05-0ubuntu0.22.04.2 |
| cuda-* | 13.0.88-1 |
| cuda-drivers-fabricmanager-580 | 580.95.05-0ubuntu0.22.04.2 |
| doca-ofed | 3.0.0-058218 |
| UCX | 1.19.0 |
| NIXL | 3daa987(commit number) |
| LMCache | v0.3.10 |
性能検証結果と考察
検証結果を順番に確認していきながら、結果について議論していきます。最初に結論を簡潔に述べると、次のような結果になりました。
- 入力長8k・出力長1kの場合、同時接続数が増え、負荷が上昇するにつれ、AggregatedはITL Tail Latencyが悪化する一方、PD Disaggregationは性能を維持した。
- 入力長1k・出力長1kの場合、基本的にITLのLatency性能はAggregatedの方が良い。同時接続数がかなり多くなると上記と同じ傾向がやや見え始めるが効果は限定的。
- 利用GPU枚数を増やすことで、TTFTには大きな効果があるものの、ITLについてはGPU間のデータ同期による通信オーバーヘッドにより性能がやや悪化する。
入力長8k・出力長1kの測定結果
まずは入力長が8k、出力長が1kの条件における、AggregatedとPD Disaggregationの結果を確認します。
以降に示すグラフの説明は次のとおりです。
- 「agg-tp4」のパターンのグラフがGPU 4枚を利用したAggregatedの構成(上図)
- 「pd-tp2」のパターンのグラフがPrefillにGPU 2枚、DecodeにGPU 2枚の合計4枚を利用した構成(下図)
- 横軸はITL(ms)、縦軸はCDF(Cumulative Distribution Function / 累積分布関数)
- 横軸、縦軸ともに重要な一部の範囲のみ描画
- 同時接続数による性能の変化を異なる色付きのグラフで描画
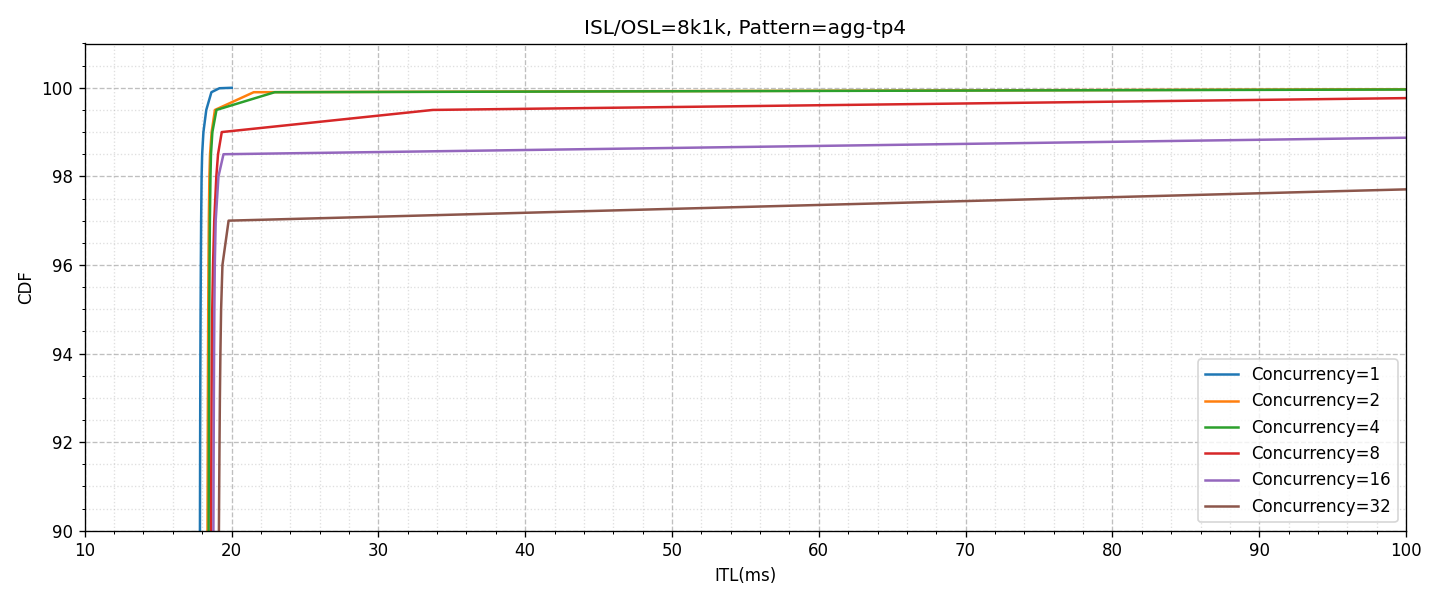
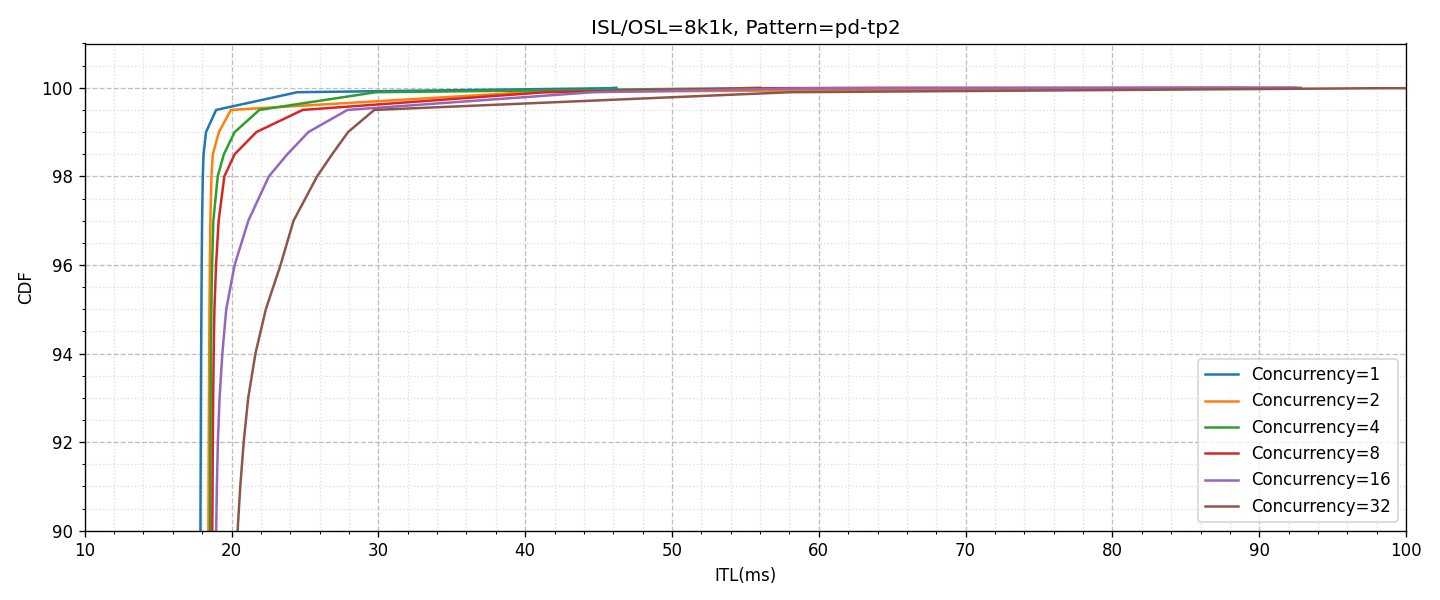
Aggregatedのグラフを見ると、同時接続数が増え、システムの負荷が上がることでITLのTail Latencyの値が低下し、例えば16並列以上になるとP99を100ms以内で満たすことができない状況になります。これに対して、PD Disaggregationの場合では、影響はあるもののかなり抑えられており、32並列であってもP99を30ms以内に抑えられるということがわかります。
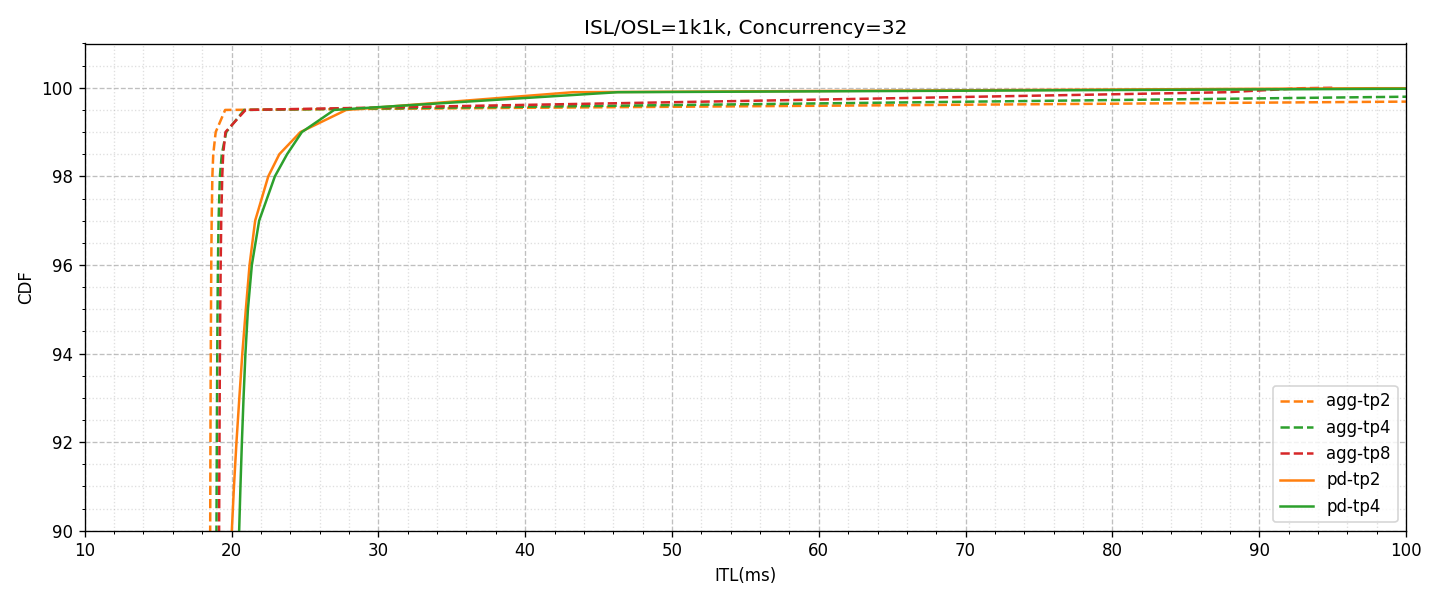
もう少し直接的に比較するために、32並列に関するAggregated、PD Disaggregationの性能を同一グラフ上にプロットします。また同条件において、GPUの利用量を変化させたものを異なる色付きのグラフで表現しています。同じGPU枚数のもの(agg-tp4とpd-tp2、agg-tp8とpd-tp4)は同じ色にしてあるため、同色での比較は同じリソース量での比較になります。
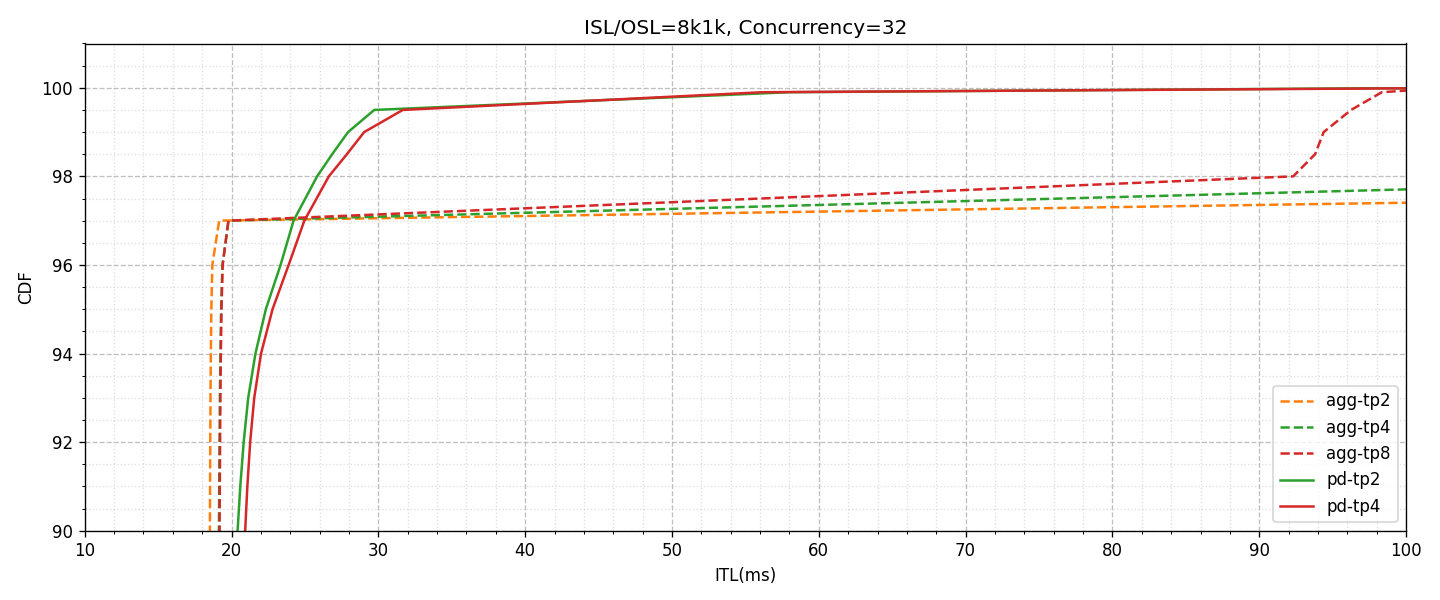
直接比較してみると、先ほど言及した通り、高負荷状況におけるITL Tail Latencyに対しての明確な改善効果がみられます。
一方で気になる点として、同一構成間(Aggregated構成間 / PD Disaggregation構成間)では、微量ではあるものの、GPUリソースの枚数が少ないほど性能が良い傾向にあることがわかります。これはDecodeが計算速度に律速していないことの裏付けでもあり、単に計算資源を増やすことではITLの性能向上に直接的に紐づかないことが読み取れます。また、単一のDecodeインスタンスのGPU資源を増やすほど、GPU間の計算結果同期のための通信コストが上がり、結果としてLatencyを低下させる要因になっていると考えられます。
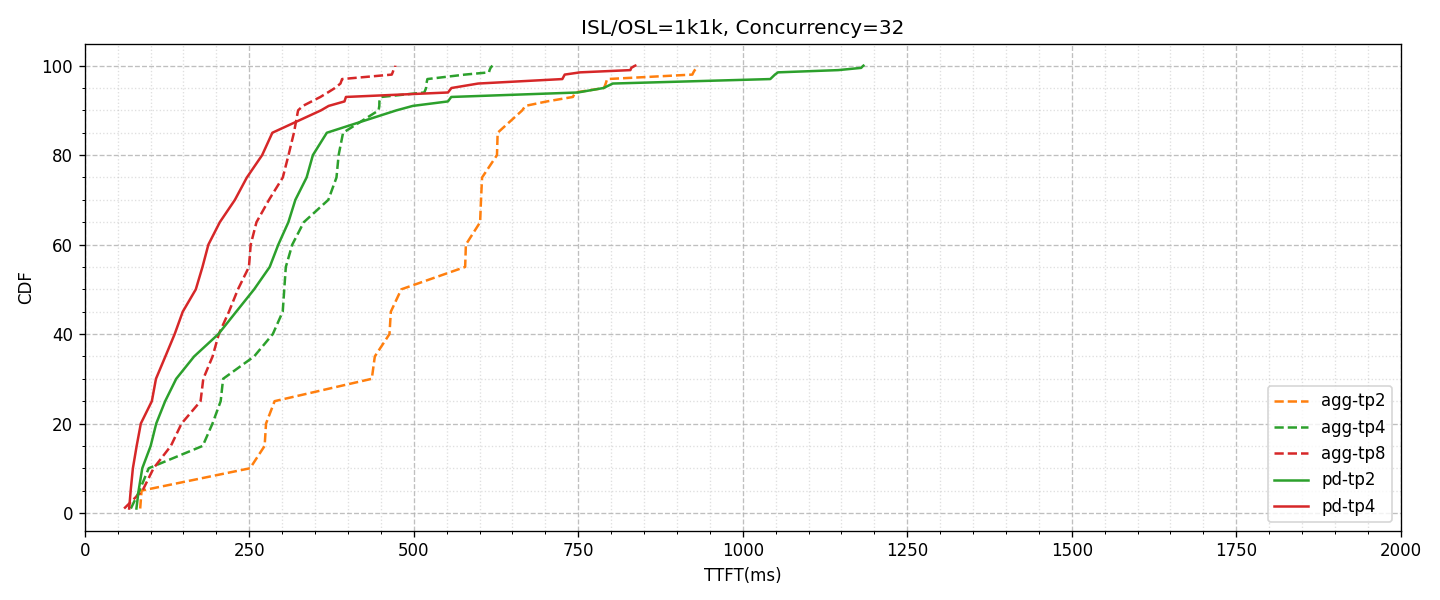
ただし、当然ながら計算資源の増加はPrefillにおいては非常に重要な意味を持つことが想定されます。以下に、同様の形式でTTFTの測定結果をプロットしたグラフを表示します。
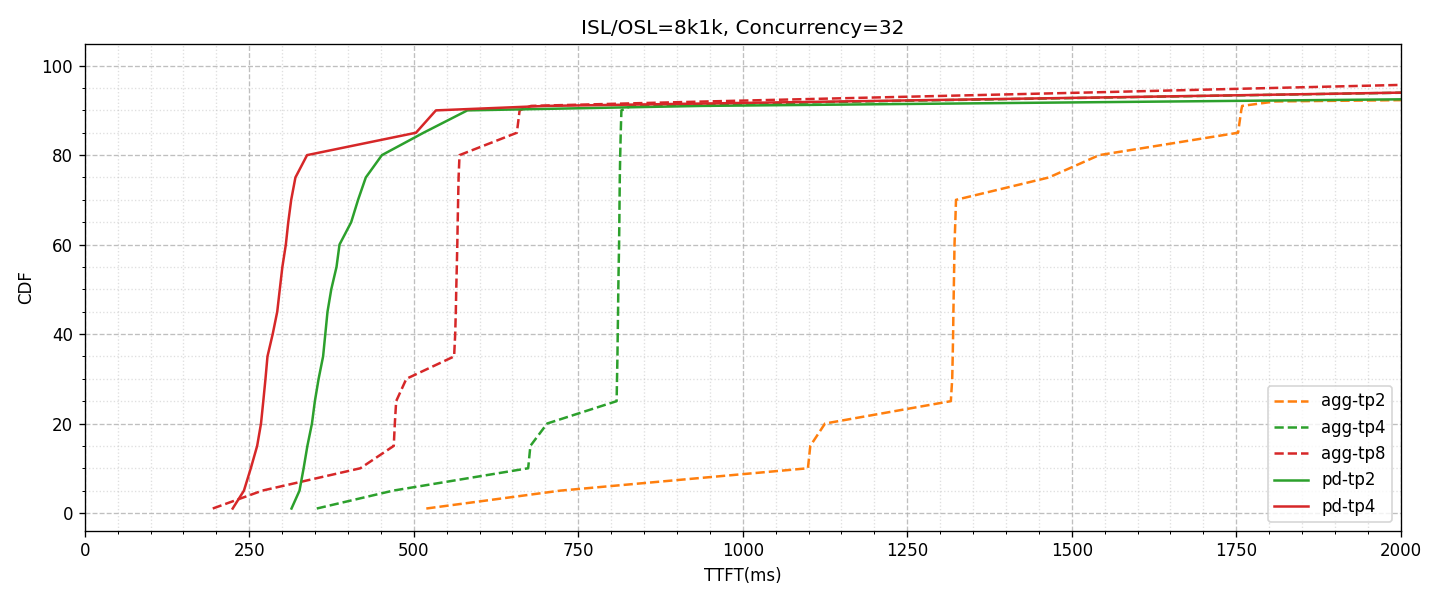
同一構成間において、GPUを投下するほど性能の改善が見られます。Prefillは計算が重い処理であることからも妥当であり、TTFTの全体的なLatency性能の改善に関してはやはりGPUを割り当てると良さそうです。一方で、全体を通してTTFTのTail Latencyについては特に改善傾向はみられませんでした。
言及しておくべきこととして、Aggregatedのグラフは特徴的な階段状の傾向を見せています。前述した通り、今回の設計によるワークロード負荷は、ほぼ同時刻に複数のリクエストが届き、あるリクエストが完了したら都度追加のリクエストを要求する形になります。それぞれのPrefill処理はバッチスケジューラによって制御されるため、同時刻に発生したリクエストの間でも、スケジューリングの都合でキューイングされる可能性があります。また、この測定条件はPrefill処理に時間がかかるパラメータ設計のため、リクエストによっては待ち時間は長期化することも想定されます。加えてAggregated構成では、PrefillとDecodeが同一バッチに混在するため、特定リクエストのPrefillが処理されるまでに遅延が生じる要因になります。これらによって、HoL(Head-of-Line)ブロッキングのような状態が生み出され、特にAggregatedでは特徴的なグラフ傾向になっているものと思われます。
このような負荷状況において、AggregatedからPD Disaggregationの構成に変更すると、見かけ上のGPU枚数はPrefillとDecodeで等分されたとしても、TTFTの値の傾向としても改善が見受けられます。今回のような負荷は実際のワークロードにおいてはあまり想定されないため、この結果のみをもとに判断するのは早計ですが、PD DisaggregationによるPrefill側への影響も注目しておくべきでしょう。
入力長1k・出力長1kの測定結果
入力長が8kの場合ではかなり良い形でPD Disaggregationの効果が観測されましたが、入力長が1kの場合はどうでしょうか? 次のグラフは、入力長のみ1kにし、それ以外は条件を変更せずに取得した結果です。グラフの構成や見方は先ほどと同じです。
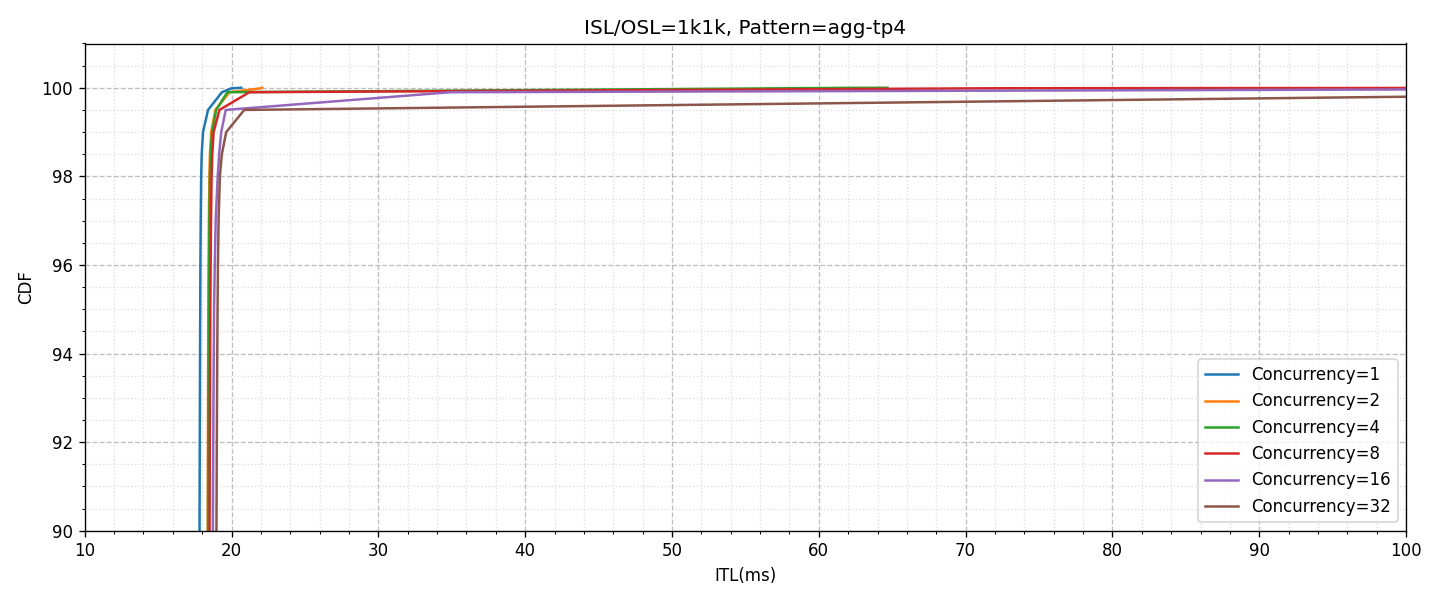
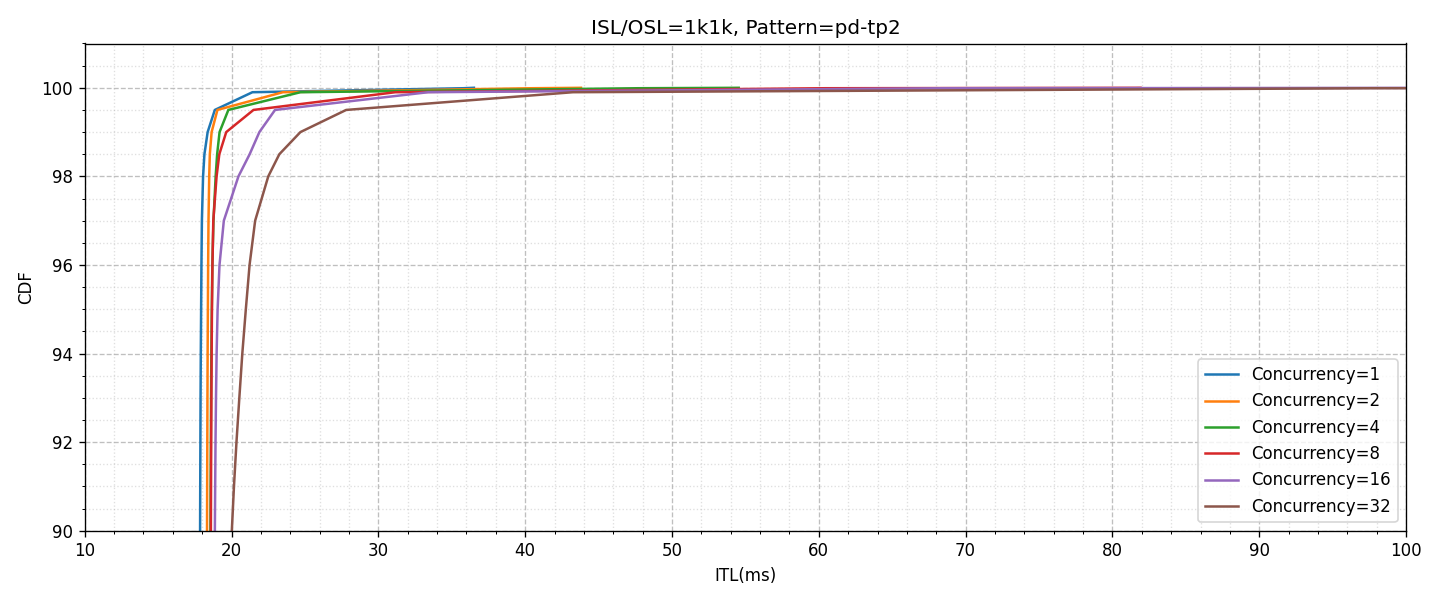
一目しただけでも、多くのケースでAggregatedの方が良いか、ほぼ同程度の性能であるとわかります。先ほどと同様に直接比較のグラフ(下図)を合わせて見ると、32並列ほど接続数が伸びるとP99.5付近で性能が逆転するものの、PD Disaggregationの構成でも性能の悪化が顕著になる部分でギリギリ交わっている程度です。常にリクエストを受け付けるような負荷状況下においてこの程度の効果なので、より散発的なリクエストになると見込まれる現実的なワークロードを前提とするとPD Disaggregationのメリットは限定的であることが想定されます。
TTFTに関しても同様に確認すると、平均的には性能が良さそうに見えますが、先ほどと比べて入力長が短い分Prefillの負荷も低めなので、改善傾向ではあるものの改善幅は限定的になっています。
設計した課題に対する議論
上記の測定結果から、PD Disaggregationの効果がそのワークロード負荷の傾向(入力長が長いことや、同時リクエスト実行数など)に依存して大きく変化するということがわかります。これは非常に重要な情報であり、システムを構成する我々としては正しく把握しておく必要があります。
まず重要なこととして、今回主に着目したTail Latencyのような値は、SLO・SLAなどの指標として利用されやすい傾向にある指標です。Aggregatedの構成では、強い負荷の傾向になってきた場合、単純なリソースの投入を行なってもITL Tail LatencyをベースにしたSLOを達成するのが困難になることが示唆されました。これは小規模な環境であっても例外ではないことが確認できたことも重要です。また、PD Disaggregationによる異なるフェーズ(PrefillとDecode)間の干渉の回避は、TTFTの平均的なLatency性能に改善傾向を示すことがわかりました。TTFTのTail Latencyに対しての改善傾向は見られていませんが、これらの指標への影響を総合的に判断して、PD Disaggregationの可否を検討するのがよさそうです。
また、やや本筋の議論とは外れますが、実際のベンチマークによって、理論通りPrefillとDecodeのボトルネックの違いが明確に存在することも確認できました。Prefill処理では、GPUリソースの追加が大きく性能を改善する一方で、Decode処理では各GPU間での計算結果の同期に通信コストが余分に発生し、性能をかえって悪化させる傾向がありました。それぞれの指標を個別に改善するには、独立したリソーススケーリングを行うことが望ましく、その面でもPD Disaggregationは望ましい構成と言えるかもしれません。
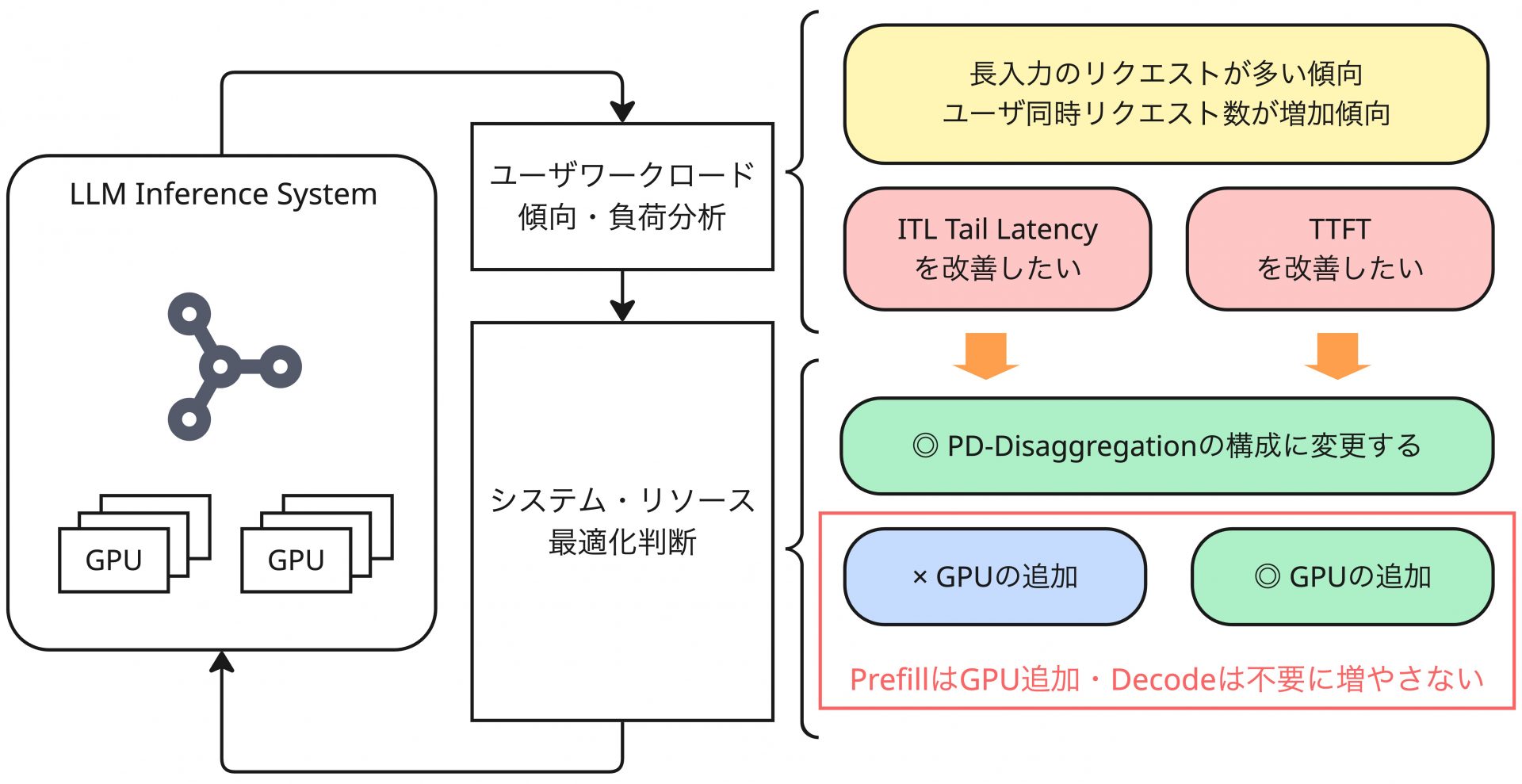
一方で、改めて前提に立ち返ると、上述したメリットがどの程度享受できるかは、ワークロード負荷に依存するという側面があることを忘れてはいけません。特に、入力長が比較的長く、リクエストもそれなりの数が常時飛んでくるような環境においては上述のメリットは得られますが、そうでない場合はPD DisaggregationでなくてもSLO・SLAを満たすことができるということになります。ユーザーワークロードが散発的な場合は最低限のGPU枚数で十分という可能性もあるため、その場合PD Disaggregationは単にコストがかさむだけの構成ということになりかねません。
再三になりますが今回のベンチマークは負荷試験のようなワークロードを模擬しており、現実的なユーザーワークロードが必ずしも今回のような負荷傾向になるわけではありません。PD Disaggregationの効果を見るという目的としては一定の意味のある検証結果になっているとは思いますが、今回確認されたPD Disaggregationによる効果が即時的に実際のシステムに適用されるわけではありません。ユーザーリクエストの入力長などのパラメータは我々がコントロールできるものではなく、システムにかかるワークロード負荷も環境によって異なるため、最適とされる構成やリソース量は状況によって全く異なります。常にユーザーのリクエスト傾向やシステム負荷などを観測しつつ、その基盤が満たすべきSLO・SLAを実現するための情報を集め、継続的に改善するという最適化のループを回し続けるという考え方が重要です。
おわりに
今回は推論基盤のベンチマークを議論の中心に据えながら、現実的な規模感でのメリット・デメリットについて実測結果をもとに議論してきました。推論基盤のベンチマークは、考慮すべきパラメータが多く非常に複雑であるため、注意深くベンチマーク設計を行う必要があります。ベンチマークによって何を得たいかを明確化し、それを把握するためのパラメータ設計を行わなければ、十分に効果のあるベンチマークにならないでしょう。本資料では具体的な例を通して、ベンチマークツールの選定から、パラメータ設計、実施した結果やそれに対する考察までを可能な限り詳細に記載したつもりです。当然、今回の結果は全ての環境に対して有用なものではなく、これは表に出ている概ねの推論ベンチマークに関しても同じことが言えると思います。自身が構築し提供するインフラをより最適化するために、どのような前提があるかはケースバイケースであり、状況も変わります。これを理解した上で、ベンチマークと向き合っていくことが重要だと考えています。
これまでの連載記事の中で、推論基盤として一般的に採用されることの多くなってきたPD Disaggregationに関する基本的な議論は概ね終えました。以降の連載では、KV Cacheの最適化、もしくは再利用に関する話題を中心に取り扱おうと考えていますので、興味がある方はぜひ引き続きお付き合いください。
脚注
- 今回の内容は、第3回 vLLM roundup Community Meetup Tokyoでの発表内容と一部被っていますが、性能検証に関するより詳細な内容を記載した資料となっています。 ↩︎
- 本稿執筆時と実際のベンチマークを行っていた時期にはやや時間差があるため、当時の状況から開発状況などが変わっている可能性があります。例えば現在、GenAI-perfはすでに新機能の開発は行なっておらず、AIPerfがその代替として開発されているようです。ベンチマークを行う場合には、そのタイミングで利用可能なツールを改めて調査し選択することをお勧めします。 ↩︎
- 実際はベンチマークパラメータの調節による「ユーザワークロードの模擬」にも限界はあります。さらに難しいことに、LLMの使い方の違い(ChatBot, RAG, Agentic AI, …etc)によっても、ユーザ負荷の傾向は変化します。これらを把握したうえで「何を測定するか」を見極め、ベンチマークを設計する必要があります。 ↩︎