Terraform for さくらのクラウド スタートガイド (第三回)〜さくらのクラウド上にインフラ構築〜


前回まではTerraformの持つ基本的な機能について扱ってきました。今回からは、Terraformからさくらのクラウドを操作するためのプラグイン「Terraform for さくらのクラウド」について扱います。
目次
Terraform for さくらのクラウドとは?
「Terraform for さくらのクラウド」とは、Terraformにてさくらのクラウド上のリソースを扱えるようにするための「プラグイン」です。
Terraformはプラグインで拡張できる
連載第1回で触れましたが、Terraformでは「プロバイダー」という単位でインフラを管理する対象プラットフォームを指定することが出来ます。
参考:Terraformドキュメント:ビルトインされているプロバイダー
様々な種類のプロバイダーがTerraformにビルトインされていますが、ビルトインされていないプロバイダーについては「プラグイン」という仕組みを用いてTerraformを拡張することで利用可能になります。
Terraform for さくらのクラウドの対応範囲
現在、主要なリソースについてはほぼカバーされています。サポートしているリソースの一覧については以下のドキュメントを参照ください。
参考:Terraform for さくらのクラウド:設定リファレンス
参照専用のリソースであるデータソースや、リソースのインポートにも対応しています。また、現在も継続して開発を行なっており、さくらのクラウド上に新機能が追加されたら出来るだけ早く追随するようにしています。
Terraform for さくらのクラウドのセットアップ
それではTerraform for さくらのクラウドのセットアップを行いましょう。
インストール
GitHub上のリリースページにてプラグインのバイナリを配布しています。OS/Archごとにzip化されていますので、各自の環境に合わせて適切なものをダウンロードしてください。
Terraform for さくらのクラウド リリースページ
ダウンロードしたら展開し、terraformバイナリと同じディレクトリ内に配置してください。
以上でインストール完了です。
[TIPS]
Terraform for さくらのクラウドはDockerイメージでの配布も行なっています。
Terraform本体 + プラグインをバンドルしており、Docker上で実行できるようになっています。
Dockerをインストールしておくことが必要ですが、手軽にバージョンアップできることや、動作確認の取れた本体/プラグインのバージョンの組み合わせにて配布しているため安定稼働できる、といった利点がありますので便利にお使いいただけると思います。
各自の利用環境に応じてご利用ください。
詳細な利用方法などは以下のインストールガイドに記載されています。
参考:Terraform for さくらのクラウド:インストールガイド
さくらのクラウド APIキーの準備
Terraform for さくらのクラウドでは、リソースの管理を行うためにさくらのクラウドAPIを呼び出しています。このAPI呼び出しを行うためにAPIキーを発行しておく必要があります。以下のドキュメントなどを参考に、さくらのクラウド コントロールパネルからAPIキーの発行を行ってください。
参考:Terraform for さくらのクラウド:インストールガイド:APIキーの取得
APIキーは後ほど利用しますので控えておいてください。
プロバイダー設定
tfファイルでのさくらのクラウド用プロバイダー設定の記述は以下のようになります。
provider "sakuracloud" {
# APIキー(トークン)
token = "API_TOKEN_HERE"
# APIキー(シークレット)
secret = "API_SECRET_HERE"
# デフォルトゾーン
zone = "tk1a" #(is1a/is1b/tk1a/tk1v)
}
"API_TOKEN_HERE"と"API_SECRET_HERE"の部分はコントロールパネルで発行したAPIキーに置き換える必要があります。なお、APIキーについては直接tfファイルに記載せず、連載第2回で扱ったように変数や環境変数を利用する方法がオススメです。以下のように環境変数に設定しておくことで、プロバイダー設定が行えます。
# APIキー(トークン) $ export SAKURACLOUD_ACCESS_TOKEN="API_TOKEN_HERE" # APIキー(シークレット) $ export SAKURACLOUD_ACCESS_TOKEN_SECRET="API_SECRET_HERE" # デフォルトゾーン $ export SAKURACLOUD_ZONE="tk1a"
この方法を用いた場合、さくらのクラウド用のプロバイダー設定をtfファイルに記載する必要はありません。もちろんtfvarsを使う方法でもOKですので、各自でお好みの設定方法をご利用ください。
(当記事では以降のtfファイルのサンプル内でのプロバイダー記述を省略します。)
プロバイダー設定で利用できる属性や環境変数についての詳細は以下のドキュメントを参照ください。
参考:Terraform for さくらのクラウド:設定リファレンス:プロバイダー設定
Terraform for さくらのクラウドでインフラのビルド
さて、いよいよインフラ構築を行なってみます。
はじめの一歩:シンプルなサーバーの作成
最初はシンプルなサーバー1台のみの構成にしてみます。
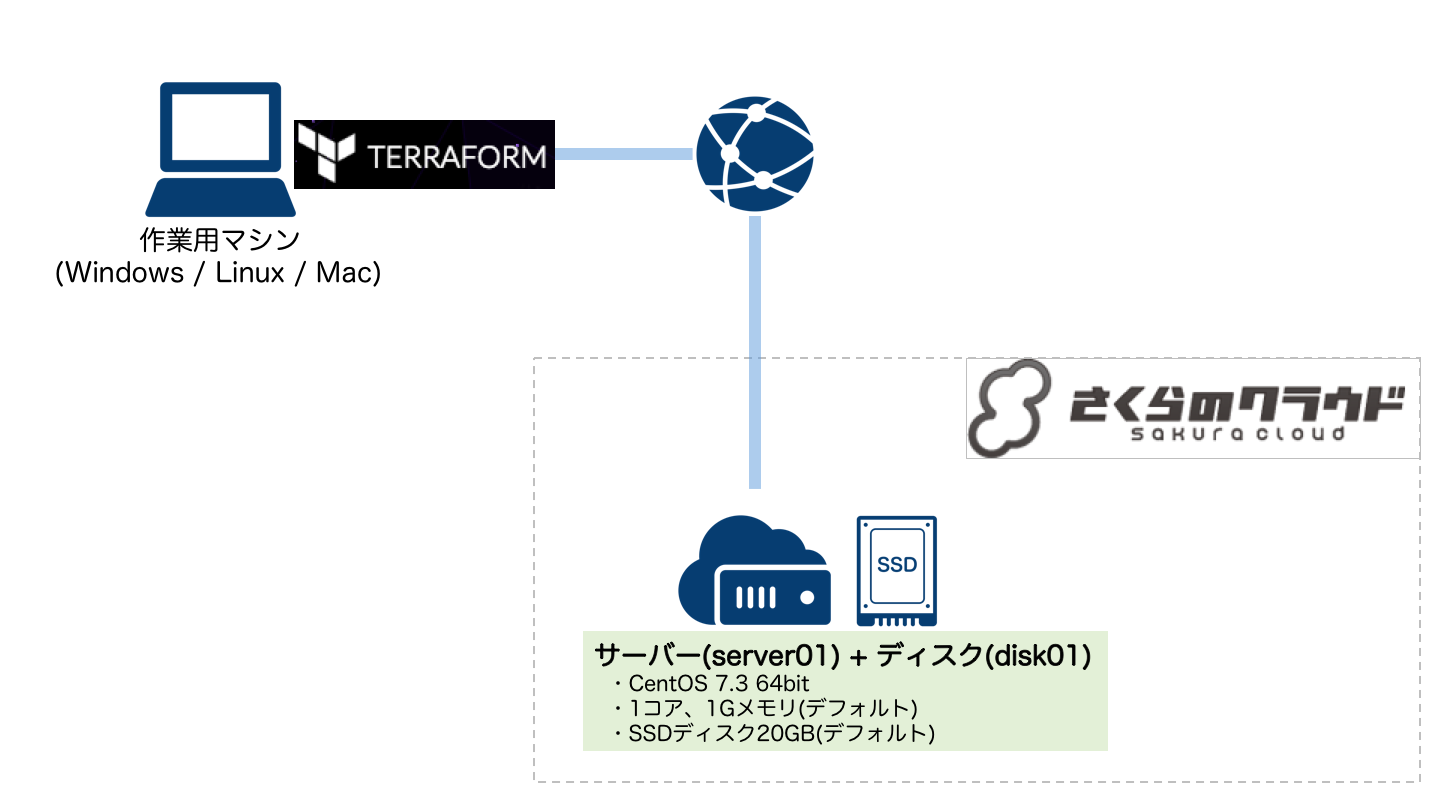
以下のtfファイルを作成します。
(後述しますが、以下のtfファイルではコピー元アーカイブのIDを直接記載しています。
IDは今後変更されることもありますので、本番環境などで実際に利用する際は後述するデータソースを用いる方法がオススメです。)
# ディスク resource "sakuracloud_disk" "disk01"{ # ディスク名 name = "disk01" # コピー元アーカイブ(CentOS 7.3 64bitを利用) source_archive_id = "112900062806" # パスワード password = "YOUR_PASSWORD_HERE" } # サーバー resource "sakuracloud_server" "server01" { # サーバー名 name = "server01" # 接続するディスク disks = ["${sakuracloud_disk.disk01.id}"] # タグ(NICの準仮想化モード有効化) tags = ["@virtio-net-pci"] }
さくらのクラウドでは、ディスク/サーバーがそれぞれ個別のリソースとして提供されています。
このため、ディスク/サーバーを個別に定義し、それぞれを接続する設定(${sakuracloud_server.server01.disks})を記載しています。
"YOUR_PASSWORD_HERE"の部分は管理者パスワードですので、各自で置き換えてください。
[TIPS]
さくらのクラウドでは、AWSのインスタンスストア(インスタンスの運用中のみ維持される一時的なブロックストレージ)相当のものは存在せず、AWSだとEBSに相当する「ディスク」リソースのみが提供されています。
このため、ディスクレスのサーバーでない限りサーバーとディスクを個別に作成し、それぞれを接続するという操作が必要になります。
(さくらのクラウド コントロールパネル上ではこれらの操作を一括で行えるようになっています。)
参考:さくらのクラウド:機能・仕様「ディスク」
[TIPS]
マシンイメージの雛形(AWSだとAMI)については「アーカイブ」リソースが提供されています。
ディスクの作成時にコピー元としてアーカイブを指定することで利用できます。
また、アーカイブにはさくらのクラウド側が提供する「パブリックアーカイブ」と、ユーザー自身が作成できる「マイアーカイブ」があります。
参考:さくらのクラウド:機能・仕様「アーカイブ」
それではリソースごとに詳細を見てみましょう。
ディスクリソース
ディスクは以下のように定義されています。
# ディスク resource "sakuracloud_disk" "disk01"{ # ディスク名 name = "disk01" # コピー元アーカイブ(CentOS 7.3 64bitを利用) source_archive_id = "112900062806" # パスワード password = "YOUR_PASSWORD_HERE" }
必要最小限の項目のみ記述しています。ポイントは"source_archive_id"の部分です。
さくらのクラウドで(OS込みの)ディスクを利用する場合、
- アーカイブ(マシンイメージの雛形)をコピーしてディスク作成
- 他のディスクをコピーしてディスク作成
- ブランクディスクを作成し後からISOイメージなどを利用してOSをインストール
というような方法があります。
今回はさくらのクラウドで提供されているパブリックアーカイブ(CentOS 7.3 64bit)のIDをコピー元として指定しました。
ディスクリソースにはこの他にも様々な属性が指定可能です。
詳細は以下のドキュメントを参照してください。
参考:Terraform for さくらのクラウド:設定リファレンス - ディスクリソース
サーバーリソース
続いてサーバーリソースについて見ていきます。
# サーバー resource "sakuracloud_server" "server01" { # サーバー名 name = "server01" # 接続するディスク disks = ["${sakuracloud_disk.disk01.id}"] # タグ(NICの準仮想化モード有効化) tags = ["@virtio-net-pci"] }
こちらのポイントは"disks"属性です。
サーバーには複数のディスクを接続可能であるため、接続したいディスクのIDを配列で指定するようになっています。
今回は${}記法で、別途定義されているディスクリソースのIDを指定しています。
サーバーリソースについても様々な属性が指定可能です。
詳細は以下のドキュメントを参照してください。
参考:Terraform for さくらのクラウド:設定リファレンス - サーバーリソース
ビルド実施
それではまずはterraform planを実行しましょう。もしエラーが出た場合はAPIキーの設定やtfファイルの記述を確認してみてください。
$ terraform plan [...] + sakuracloud_disk.disk01 connection: "virtio" name: "disk01" password: "YOUR_PASSWORD_HERE" plan: "ssd" server_id: "<computed>" size: "20" source_archive_id: "112900062806" zone: "<computed>" + sakuracloud_server.server01 base_interface: "shared" base_nw_address: "<computed>" base_nw_dns_servers.#: "<computed>" base_nw_gateway: "<computed>" base_nw_ipaddress: "<computed>" base_nw_mask_len: "<computed>" core: "1" disks.#: "<computed>" macaddresses.#: "<computed>" memory: "1" name: "server01" tags.#: "1" tags.0: "@virtio-net-pci" zone: "<computed>"
ディスクサイズやコア数/メモリ数などのtfファイル上で明示していない項目についてはデフォルト値が利用されているのが確認できるかと思います。必要に応じて適宜変更してみてください。
続いてterraform applyを実行してみましょう。
$ terraform apply sakuracloud_disk.disk01: Creating... connection: "" => "virtio" name: "" => "disk01" password: "" => "YOUR_PASSWORD_HERE" plan: "" => "ssd" server_id: "" => "<computed>" size: "" => "20" source_archive_id: "" => "112900062806" zone: "" => "<computed>" sakuracloud_disk.disk01: Still creating... (10s elapsed) [...] sakuracloud_disk.disk01: Creation complete sakuracloud_server.server01: Creating... base_interface: "" => "shared" base_nw_address: "" => "<computed>" base_nw_dns_servers.#: "" => "<computed>" base_nw_gateway: "" => "<computed>" base_nw_ipaddress: "" => "<computed>" base_nw_mask_len: "" => "<computed>" core: "" => "1" disks.#: "" => "1" disks.0: "" => "999999999999" macaddresses.#: "" => "<computed>" memory: "" => "1" name: "" => "server01" tags.#: "" => "1" tags.0: "" => "@virtio-net-pci" zone: "" => "<computed>" sakuracloud_server.server01: Still creating... (10s elapsed) [...] sakuracloud_server.server01: Creation complete Apply complete! Resources: 2 added, 0 changed, 0 destroyed. The state of your infrastructure has been saved to the path below. This state is required to modify and destroy your infrastructure, so keep it safe. To inspect the complete state use the `terraform show` command. State path: terraform.tfstate
これでサーバーが作成されているはずです。コントロールパネルなどから確認してみてください。
SSH接続用コマンドを出力するアウトプットを追加
作成したリソースの情報はterraform showコマンドでも確認できます。コマンドを実行すると様々な属性が表示されると思いますが、その中でもサーバーリソースの"base_nw_ipaddress"属性に注目してみましょう。これはサーバーに割り当てられたグローバルIPアドレスを示す属性で、SSHで接続する際などに利用することになります。SSH接続の都度terraform showを実行して確認しても良いのですが、大量の属性が表示されるため、その中から特定の属性(グローバルIPなど)を探すのは若干面倒です。
そこで、tfファイル上に「アウトプット」を追加してみます。
単純にグローバルIPを表示するだけでも良いのですが、より便利にするためにグローバルIP向けにSSH接続するコマンド文字列を表示できるようにしてみましょう。
以下をtfファイルに追記してください。
# アウトプット(SSHコマンド)
output "ssh_command" {
value = "ssh root@${sakuracloud_server.server01.base_nw_ipaddress}"
}
追記したらterraform planを実施することでアウトプットが利用できるようになります。
$ terraform apply
sakuracloud_disk.disk01: Refreshing state... (ID: xxxxxxxx10xx)
sakuracloud_server.server01: Refreshing state... (ID: xxxxxxxx10xx)
Apply complete! Resources: 0 added, 0 changed, 0 destroyed.
Outputs:
ssh_command = ssh root@xxx.xxx.xxx.xxx
作成したアウトプットは以下のように利用します。
# terraform outputを実施することでアウトプットを表示できる $ terraform output ssh_command ssh root@xxx.xxx.xxx.xxx # 以下のようにバッククォート演算子や$()と共に利用すると便利 $ `terraform output ssh_command` # SSH接続 # または $ $(terraform output ssh_command) # SSH接続
インフラの変更(SSH公開鍵の追加)
続いて、サーバーをよりセキュアにするために、さくらのクラウドで提供されているSSH公開鍵機能を利用してみます。
この機能は、SSH接続時に(登録した)公開鍵での認証を行うようにサーバーを設定してくれるもので、パスワード/チャレンジレスポンスでのSSHログインを禁止する機能と組み合わせることでサーバーをよりセキュアにすることが可能です。
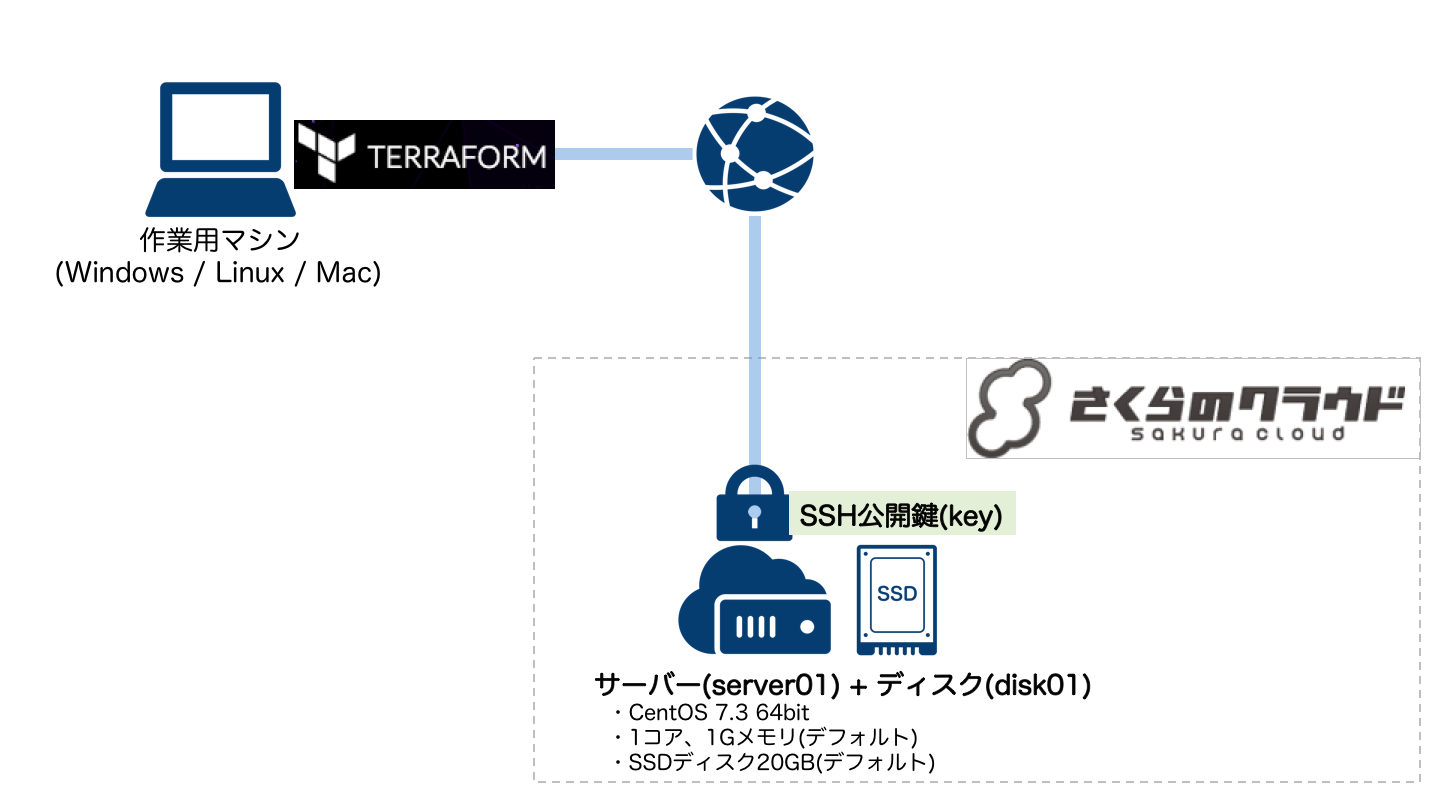
まずは手元のマシンで以下のコマンドを実行し、キーペアを生成します。
(bashの場合の例です。それ以外の環境の場合は適宜読み替えてください。)
$ ssh-keygen -f id_rsa Generating public/private rsa key pair. # パスフレーズを聞かれるので任意で設定(空にもできる) Enter passphrase (empty for no passphrase): # パスフレーズの確認入力 Enter same passphrase again: Your identification has been saved in id_rsa. Your public key has been saved in id_rsa.pub. The key fingerprint is: SHA256:xmCayJi1CaiuTQ8PH9jS1gDcII6N76odTo+WwPoaHpc The key's randomart image is: +---[RSA 2048]----+ |. . | |+= o | |=.= . o | |.B = + o | |= * + S | |oo +.o . | |o+XE= . | |+O=% . | |*=* = | +----[SHA256]-----+
これで"id_rsa"(秘密鍵)と"id_rsa.pub"(公開鍵)が作成されているはずです。この公開鍵をさくらのクラウド上で利用できるようにするために、tfファイルにSSH公開鍵リソースの定義を追記します。
以下の内容を追記してください。
# SSH公開鍵 resource "sakuracloud_ssh_key" "key"{ name = "sshkey" public_key = "${file("id_rsa.pub")}" }
見慣れない記述${file("id_rsa.pub")}というものが出てきましたね。これはTerraformが用意しているfile関数の呼び出しを行なっています。file関数は指定のパスのファイルを読み込み、その内容を文字列で返す関数です。今回はカレントディレクトリにある"id_rsa.pub"ファイルの内容をpublic_key属性に設定しています。
file関数などのTerraformが提供している関数については以下のドキュメントに記載されていますので必要に応じて参照してください。
参考:Terraformドキュメント:INTERPOLATION SYNTAX
SSH公開鍵リソースで指定可能な属性などの詳細は以下のドキュメントを参照してください。
参考:Terraform for さくらのクラウド:設定リファレンス - 公開鍵
続いてこのSSH公開鍵を利用するように定義を変更します。tfファイルのディスクの定義へ以下のように追記してください。ついでにSSH用のアウトプットについても秘密鍵を利用するように変更します。
# ディスク resource "sakuracloud_disk" "disk01"{ # ディスク名 name = "disk01" # コピー元アーカイブ(CentOS 7.3 64bitを利用) source_archive_id = "112900062806" # パスワード password = "YOUR_PASSWORD_HERE" # 以下を追記する # SSH公開鍵のID(公開鍵は"~/.ssh/authorized_keys"などにコピーされる) ssh_key_ids = ["${sakuracloud_ssh_key.key.id}"] # パスワード/チャレンジレスポンスでのSSHログイン禁止 disable_pw_auth = true } # アウトプット(SSHコマンド) output "ssh_command" { # 秘密鍵を使うように-iオプションを追加 value = "ssh -i id_rsa root@${sakuracloud_server.server01.base_nw_ipaddress}" }
その後terraform planを実行すると以下のようになると思います。
$ terraform plan [...] sakuracloud_disk.disk01: Refreshing state... (ID: xxxxxxxx10xx) sakuracloud_server.server01: Refreshing state... (ID: xxxxxxxx10xx) [...] ~ sakuracloud_disk.disk01 disable_pw_auth: "" => "true" ssh_key_ids.#: "0" => "" + sakuracloud_ssh_key.key fingerprint: "" name: "sshkey" public_key: "ssh-rsa ..." Plan: 1 to add, 1 to change, 0 to destroy.
ディスクリソースが更新され、SSH公開鍵リソースが追加になる予定となっていますね。確認できたらterraform applyを実行して適用します。適用後は公開鍵を利用してSSHログインができること、パスワード/チャレンジレスポンスでのSSHログインができなくなっていることが確認できるはずです。
データソースを利用してIDの埋め込みを無くす
ここまでのtfファイルではアーカイブのIDをtfファイルに直接記載していました。アーカイブのIDは同じOSでもゾーンが違うと異なるIDとなります。また、今後のバージョンアップなどで変更になる可能性もあります。このため、さくらのクラウドから「CentOS」「安定版」「最新バージョン」といった条件を指定して動的にアーカイブのIDを取得できると便利です。これを実現するためにTerraformには「データソース」という機能が用意されています。
データソースとは
データソースとは読み取り専用のリソースで、主にIDなどを動的に参照するために利用されます。
参考:Terraformドキュメント:Data Sources
どのリソースがデータソースとして利用できるかは各プロバイダーの実装次第です。
Terraform for さくらのクラウドでは主要なリソースはほぼ全てデータソースとして利用できるようになっています。
サポートしているリソース一覧は以下のドキュメントに記載されています。
参考:Terraform for さくらのクラウド:設定リファレンス - データソース
リソース名やタグなど、さくらのクラウド上のリソースの様々な属性を条件にして参照することが可能です。
アーカイブIDをデータソース経由で取得
早速データソースを利用してみましょう。
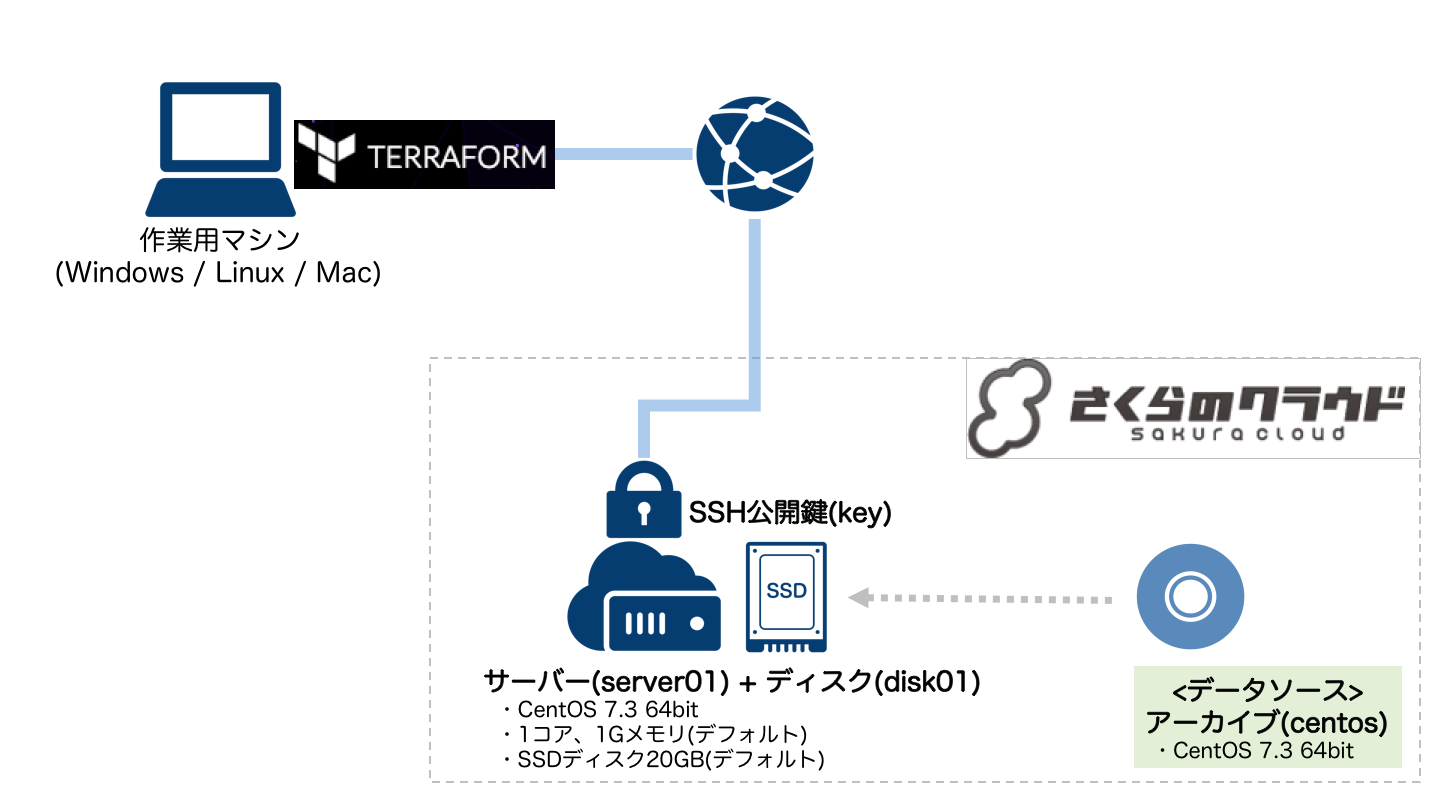
アーカイブ参照用のデータソースを追加
tfファイルにデータソースの定義を追記します。
# データソース(アーカイブ) data sakuracloud_archive "centos" { # 検索条件をfilter属性に指定する(複数指定可) filter = { name = "Tags" #タグで検索 # 最新安定板、64bit、centosを示すタグ全てを持ったもの values = ["current-stable", "arch-64bit", "distro-centos"] } }
通常のリソース定義の場合、定義の先頭は"resource"となっていましたが、
今回は"data"となっていますね。
データソースの定義は以下の書式となっています。
data "リソースタイプ" "リソース名" {
検索条件(リソースの実装次第)
}
検索条件はリソースの実装により指定する内容が異なりますので、各リソースのドキュメントを参考に記載していくことになります。
Terraform for さくらのクラウドでサポートしているデータソースでは"filter"属性が指定可能になっています。
"filter"属性に検索対象の属性と値を設定することでデータソースが利用できるようになっています。
[TIPS]
"filter"属性で検索した結果、複数件ヒットした場合はヒットしたデータの先頭が利用されます。この挙動は今後の実装やさくらのクラウドAPIの更新などで変更される可能性がありますので、この挙動に依存しないようになるべく絞り込めるような条件を利用するのがオススメです。
ここではタグを利用してアーカイブを絞り込んでいますが、リソース名(Name属性)で絞り込むことも可能です。用途に合わせて調整してください。
データソースを参照するようにID埋め込み部分を変更
アーカイブのIDを埋め込んでいる部分を以下のように変更します。
# コピー元アーカイブ(CentOS 7.3 64bitを利用) source_archive_id = "${data.sakuracloud_archive.centos.id}"
データソースを参照する場合は"${data.リソースタイプ.リソース名.属性}"という形式で記載します。今回は、
- リソースタイプはアーカイブ(sakuracloud_archive)
- リソース名は"centos"
- 参照したい属性は"id"
ですので、"${data.sakuracloud_archive.centos.id}"という記述になっています。
これでIDの埋め込みを無くすことができました。
[TIPS]
データソースが参照しているリソースについての情報はカレントディレクトリの"terraform.tfstate"ファイルに格納されています。
もしこのファイルが存在しない場合、terraform applyを実行すれば作成されます。
"terraform.tfstate"ファイルが存在する状態でterraform showコマンドを実行することで情報を表示可能です。
もし表示できない場合はterraform refreshコマンドを実行することで"terraform.tfstate"ファイルが更新されますので、その後terraform showを再実行することで表示できるようになるはずです。
まとめ
最終的なtfファイルは以下のようになりました。
# SSH公開鍵 resource "sakuracloud_ssh_key" "key"{ name = "sshkey" public_key = "${file("id_rsa.pub")}" } # データソース(アーカイブ) data sakuracloud_archive "centos" { filter = { name = "Tags" values = ["current-stable", "arch-64bit", "distro-centos"] } } # ディスク resource "sakuracloud_disk" "disk01"{ name = "disk01" source_archive_id = "${data.sakuracloud_archive.centos.id}" password = "YOUR_PASSWORD_HERE" ssh_key_ids = ["${sakuracloud_ssh_key.key.id}"] disable_pw_auth = true } # サーバー resource "sakuracloud_server" "server01" { name = "server01" disks = ["${sakuracloud_disk.disk01.id}"] tags = ["@virtio-net-pci"] } # アウトプット(SSHコマンド) output "ssh_command" { value = "ssh -i id_rsa root@${sakuracloud_server.server01.base_nw_ipaddress}" }
今回は以下の内容を扱いました。
- Terraform for さくらのクラウドのセットアップ
- さくらのクラウドのリソース(サーバー/ディスク/SSH公開鍵)の定義
- Terraformが用意している関数の利用(file関数)
- データソースの利用
さくらのクラウドでシンプルなサーバーのみという構成をTerraformを通じて構築しました。小規模なサービスであればこの構成でも十分実用的です。実際に本番運用する際にはサーバーのプロビジョニングなど、もう少し作業が必要となりますが、それらは次回以降で扱います。
次回は中規模~大規模な構成には不可欠なネットワーク関連のリソースを扱う予定です。スイッチによるネットワークの構築や、VPCでのプライベートネットワーク構築、ロードバランサーでの負荷分散などを行うことでクラウドらしい構成を取ることができます。
お楽しみに!