Terraform for さくらのクラウド スタートガイド (第五回)〜サービス提供用のリソースと応用編〜

前回はスイッチ/ルーター/ブリッジなどのネットワーク関連のリソースを中心に扱いました。今回は前回の続きとしてVPCルータを扱い、その後DNSやGSLB、監視といったサービスそのものを提供するリソースを扱います。
また、応用編としてこれまでの連載で扱ってきたリソースやテクニックを駆使して複数リージョンにまたがる冗長構成を構築してみます。
仮想プライベートクラウド構築
まずは仮想プライベートクラウド構築のためのリソースであるVPCルータについて扱います。
VPCルータ
VPCルータとは、その名の通りVPC(Virtual Private Cloud)環境を構築するための、仮想ルータアプライアンスです。
[TIPS] VPCとは?
クラウド上に仮想的なネットワークを構築し、手元のプライベートネットワーク(いわゆる社内LANなど)とVPN接続を行うことで、クラウド上の資源をあたかもプライベートネットワーク上にあるものとして扱うための技術です。
以下のような機能を持っています。
- IPマスカレード(Forward NAT)
- ポートフォワーディング(Reverse NAT)
- DHCPサーバー
- トラフィックモニタ
- ファイアウォール
- VPN(L2TP/IPSec, PPTP)
- サイト間VPN(Cisco,Juniper,ヤマハなどのハードウェアVPNアプライアンスとも相互接続可能)
ルータ+スイッチがグローバルIPアドレスの確保に重点が置かれているのに対し、VPCルータはルータ機能+VPN機能に重点が置かれています。両方を組み合わせて利用することも可能です(プレミアム/ハイスペックプランではルータ+スイッチが必須です)。
また、冗長化の有無や性能の違いにより3つのプラン(スタンダード/プレミアム/ハイスペック)が用意されています。詳細は以下のページなどを参照ください。
今回は簡単な例として、VPCルータ配下にプライベートネットワークを構築し、L2TP/IPSecへVPN接続可能な構成を行ってみます。
以下のような構成となります。
- VPCルータの上流ネットワークは共有セグメント(インターネット)に接続
- VPCルータ配下にプライベートネットワーク用のスイッチを接続(192.168.15.0/24とする)
- L2TP/IPSecでプライベートネットワークへVPN接続可能にする
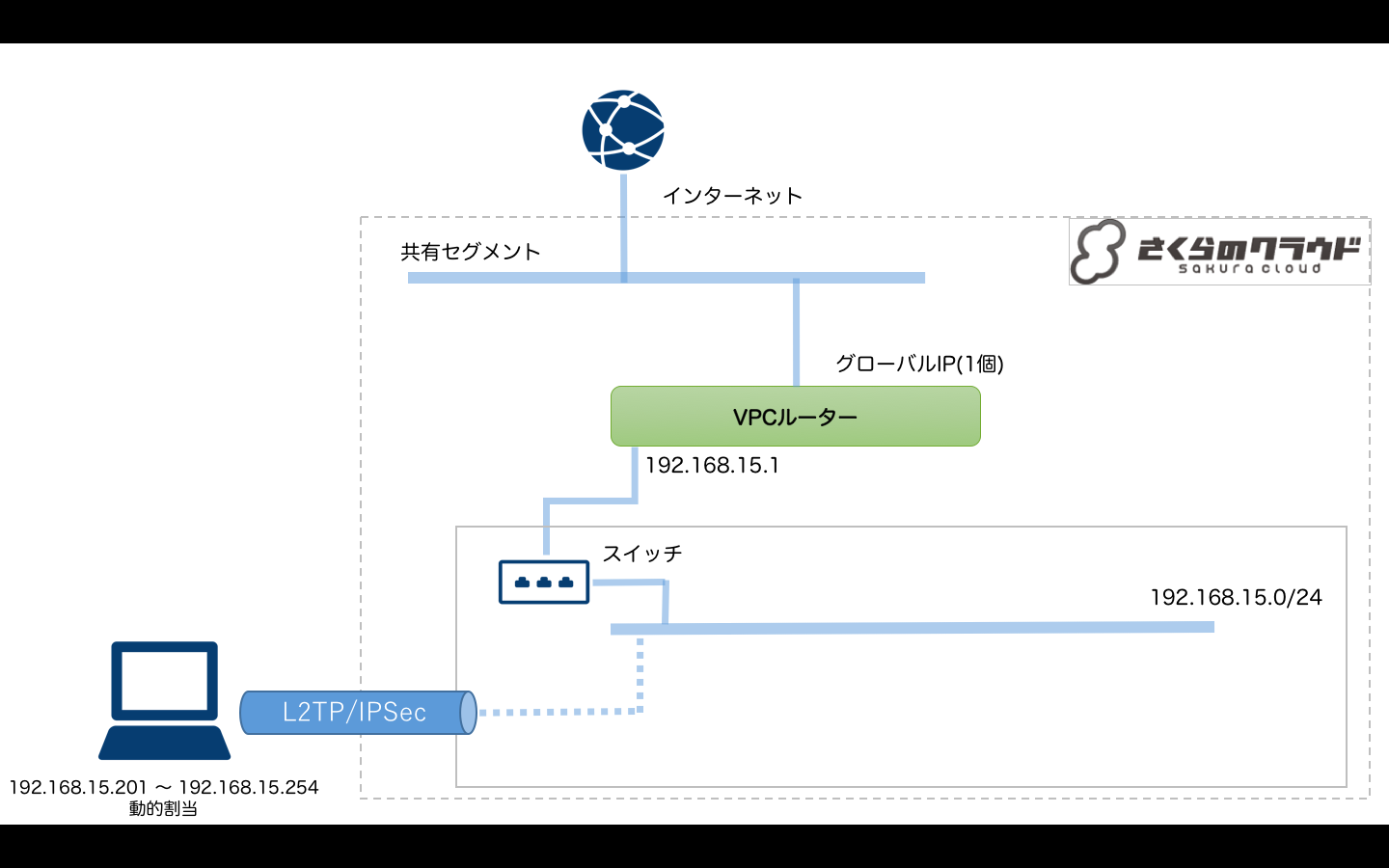
tfファイルは以下のようになります。
#--------------------------------------- # 変数定義(ログイン情報など) # -------------------------------------- # L2TP/IPSec 事前共有キー variable pre_shared_secret { default = "PutYourSecret" } # L2TP/IPSec ユーザ名/パスワード variable vpn_username { default = "PutYourName" } variable vpn_password { default = "PutYourPassword" } # -------------------------------------- # スイッチの定義 # -------------------------------------- resource "sakuracloud_switch" "switch"{ name = "switch" } # -------------------------------------- # VPCルータの定義 # -------------------------------------- # VPCルータ本体 resource "sakuracloud_vpc_router" "vpc" { name = "vpc_router" } # インターフェースの定義 resource "sakuracloud_vpc_router_interface" "eth1"{ vpc_router_id = "${sakuracloud_vpc_router.vpc.id}" index = 1 # NICのインデックス(1〜7) switch_id = "${sakuracloud_switch.switch.id}" # スイッチのID ipaddress = ["192.168.15.1"] # 実IPリスト nw_mask_len = 24 # ネットマスク長 } # リモートアクセス:L2TP/IPSec resource "sakuracloud_vpc_router_l2tp" "l2tp" { vpc_router_id = "${sakuracloud_vpc_router.vpc.id}" vpc_router_interface_id = "${sakuracloud_vpc_router_interface.eth1.id}" pre_shared_secret = "${var.pre_shared_secret}" # 事前共有シークレット range_start = "192.168.15.201" # IPアドレス動的割り当て範囲(開始) range_stop = "192.168.15.254" # IPアドレス動的割り当て範囲(終了) } # リモートユーザアカウント resource "sakuracloud_vpc_router_user" "user1" { vpc_router_id = "${sakuracloud_vpc_router.vpc.id}" name = "${var.vpn_username}" # ユーザ名 password = "${var.vpn_password}" # パスワード }
VPCルータの定義
今回のVPCルータの定義は以下のリソースから構成されています。
- VPCルータ本体
- インターフェース
- リモートアクセス(L2TP/IPSec)
- リモートユーザアカウント
# VPCルータ本体 resource "sakuracloud_vpc_router" "vpc" { name = "vpc_router" } # インターフェースの定義 resource "sakuracloud_vpc_router_interface" "eth1"{ vpc_router_id = "${sakuracloud_vpc_router.vpc.id}" index = 1 # NICのインデックス(1〜7) switch_id = "${sakuracloud_switch.switch.id}" # スイッチのID ipaddress = ["192.168.15.1"] # 実IPリスト nw_mask_len = 24 # ネットマスク長 } # リモートアクセス:L2TP/IPSec resource "sakuracloud_vpc_router_l2tp" "l2tp" { vpc_router_id = "${sakuracloud_vpc_router.vpc.id}" vpc_router_interface_id = "${sakuracloud_vpc_router_interface.eth1.id}" pre_shared_secret = "${var.pre_shared_secret}" # 事前共有シークレット range_start = "192.168.15.201" # IPアドレス動的割り当て範囲(開始) range_stop = "192.168.15.254" # IPアドレス動的割り当て範囲(終了) } # リモートユーザアカウント resource "sakuracloud_vpc_router_user" "user1" { vpc_router_id = "${sakuracloud_vpc_router.vpc.id}" name = "${var.vpn_username}" # ユーザ名 password = "${var.vpn_password}" # パスワード }
前回のロードバランサの場合と同じく、より下流(子供側)のリソースが上流(親)のIDを持つという形になっています
各リソースに指定できる値などの詳細は以下のドキュメントを参照してください。
参考:Terraform for さくらのクラウド - 設定リファレンス - VPCルータ
リソースが細かく分割されていますが全て使う必要はなく、必要に応じてチョイスすればOKです。(実質的には今回の例に出てくる各リソースは必須だと思います。)
サービス提供のためのリソース
続いてサービス提供のためのリソースを扱います。
さくらのクラウドには、IaaS(計算リソースやディスク、ネットワークといったインフラストラクチャの提供)以外にも、監視やバックアップといったサービスそのものを提供するためのリソースとして以下のようなものが提供されています。
- 自動バックアップ
- GSLB
- DNS
- シンプル監視
今回はこの中からシンプル監視を扱ってみます。
(なお、DNSとGSLBについては後ほど応用編で登場します)
シンプル監視
シンプル監視とは、サーバーの外部からネットワーク疎通性やアプリケーションの死活を監視できる、いわゆる外部監視(外形監視)を行うためのリソースです。
pingやhttpといった様々な監視方法が用意されています。また、通知方法としてはメールとslackでの通知が用意されています。
シンプル監視についての詳細は以下のページなどを参照ください。
今回は例としてサーバへのping監視を行い、通知をメールで行うようにしてみます。
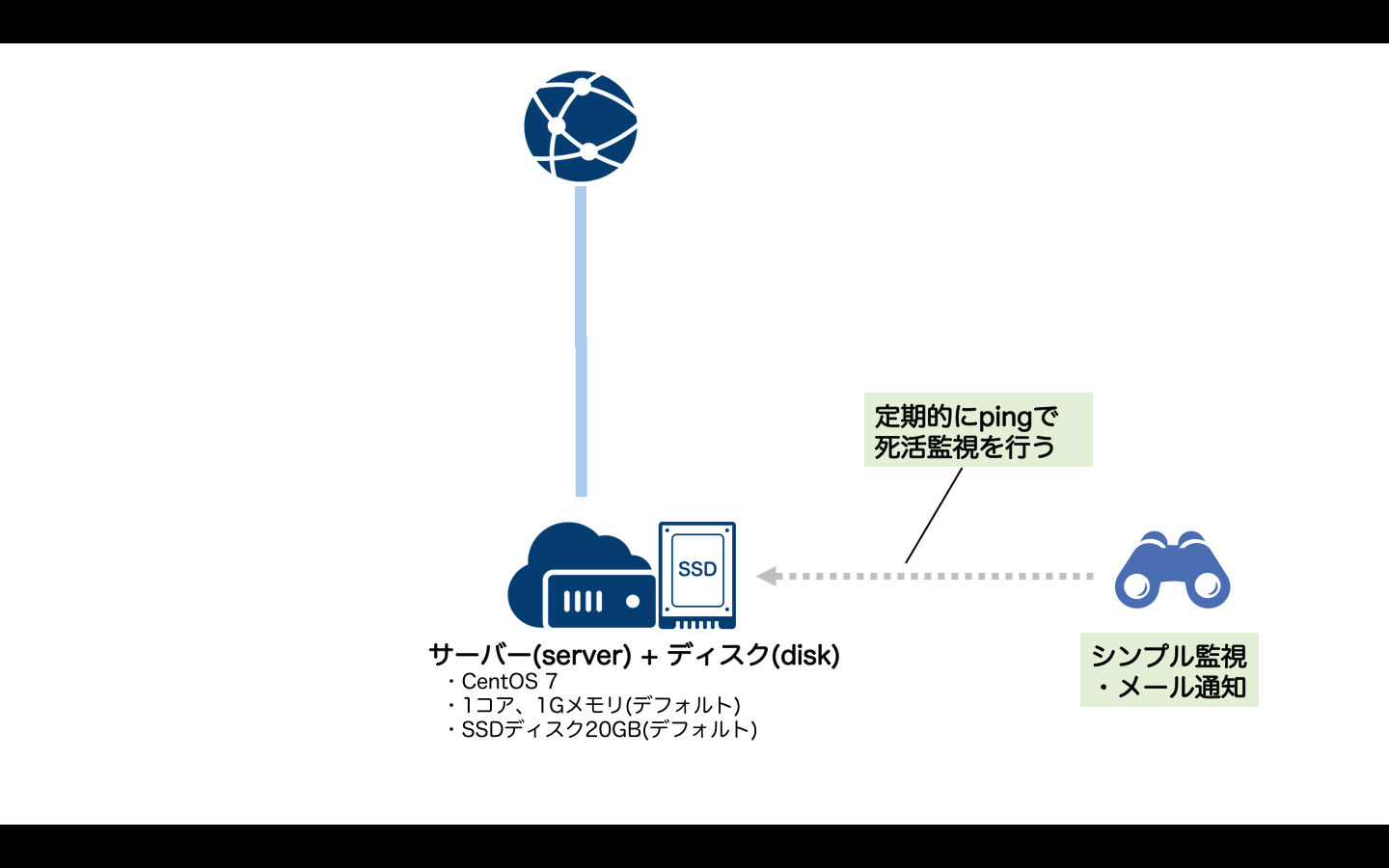
tfファイルは以下のようになります。
# データソース(アーカイブ) data sakuracloud_archive "centos" { os_type="centos" } # ディスク resource "sakuracloud_disk" "disk"{ # ディスク名 name = "disk" # コピー元アーカイブ(CentOS7を利用) source_archive_id = "${data.sakuracloud_archive.centos.id}" # パスワード password = "YOUR_PASSWORD_HERE" } # サーバー resource "sakuracloud_server" "server" { # サーバー名 name = "server" # 接続するディスク disks = ["${sakuracloud_disk.disk.id}"] # タグ(NICの準仮想化モード有効化) tags = ["@virtio-net-pci"] } # シンプル監視 resource "sakuracloud_simple_monitor" "monitor" { # 監視対象IPアドレス target = "${sakuracloud_server.server.base_nw_ipaddress}" # 監視方法 health_check = { protocol = "ping" } }
シンプル監視の定義
シンプル監視は以下のように定義します。
# シンプル監視 resource "sakuracloud_simple_monitor" "monitor" { # 監視対象IPアドレス target = "${sakuracloud_server.server.base_nw_ipaddress}" # 監視方法 health_check = { protocol = "ping" } }
監視対象のIPアドレス(またはFQDN)と監視方法を指定するだけでOKです。通知はデフォルトでメールが利用されます。Slack通知への切り替え/併用も可能です。
指定できる値の詳細は以下のドキュメントを参照ください。
参考:Terraform for さくらのクラウド - 設定リファレンス - シンプル監視
なお、監視対象はさくらのクラウド以外の外部のリソースでもOKです。
例えば、以下の例ではArukas上のコンテナの監視を行っています。
# Arukas上のコンテナ(NGINX) resource "arukas_container" "ct" { name = "arukas-with-simple-monitor" image = "nginx:latest" ports = { protocol = "tcp" number = "80" } } # シンプル監視 resource "sakuracloud_simple_monitor" "demo_monitor" { # 監視対象(Arukas側で割り当てられたエンドポイント(FQDN)を指定) target = "${arukas_container.ct.endpoint_full_hostname}" # 監視方法(https) health_check = { protocol = "https" path = "/" status = 200 } }
複数のプロバイダをまたぐ定義というTerraformらしいサンプルとなっています。
ここまででTerraform for さくらのクラウドがサポートするリソースを一通り扱ってきました。一部扱っていないリソースについては設定リファレンスなどのドキュメントを参考にしてみてください。
参考:Terraform for さくらのクラウド - ドキュメントトップ
応用編:複数のリージョンを使った冗長構成
連載の最後に応用編としてTerraform for さくらのクラウドで実用的な構成を組む例を紹介します。
これまで扱ったテクニックやリソースを駆使しているため、ここまでの連載やTerraformのドキュメント、Terraform for さくらのクラウドのドキュメントを参考しながら読み解いてみてください。
応用編では、さくらのクラウドのドキュメントで紹介されている冗長構成をTerraform for さくらのクラウドで構築してみます。
参考:さくらのクラウド - 構成例2 複数のリージョンを使った冗長構成
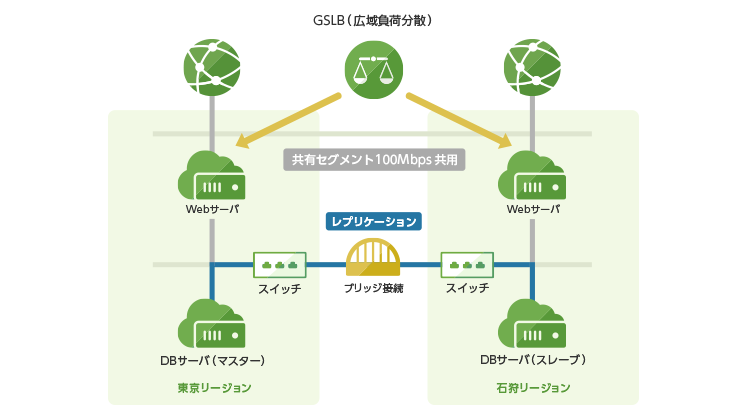
構成要素は以下の通りです。管理アクセスのためにVPCルータも利用するようにしています。
- GSLB(広域負荷分散)を用いて東京/石狩で冗長化
- 各ゾーンに2台Webサーバを配置(共有セグメントに接続、計4台)
- 各ゾーンにスイッチで配置(プライベートネットワーク用)
- 各ゾーンのスイッチをブリッジ接続
- 各ゾーンにDBサーバを配置、レプリケーションなどで冗長化
- VPCルータを配置しプライベートネットワークに接続
- 管理作業用にL2TP/IPSecでのVPN接続を行う
なお、今回はWebアプリケーションのデプロイなどのサーバ内部のプロビジョニングについては本筋から外れるため簡略化/省略しています。実運用環境を構築する際は各自の環境に合わせたプロビジョニングをご検討ください。
また、今回は構成要素が多くtfファイルが肥大化してきたため、tfファイルをいくつかに分割することにしました。
以下のリポジトリでtfファイルを公開しています。
https://github.com/yamamoto-febc/terraform_for_sakuracloud_start_guide/tree/master/example5-advanced
分割後のtfファイルは以下のような構成になります。
/ ├── variables.tf # 1) 変数の定義 ├── terraform.tfvars # 変数への値設定用ファイル ├── network.tf # 2) ネットワーク(スイッチとブリッジ)定義 ├── gslb.tf # 3) GSLBの定義 ├── ssh_key.tf # 4) SSH公開鍵の定義 ├── web.tf # 5) Webサーバの定義 ├── db.tf # 6) DBサーバの定義 ├── vpc_router.tf # 7) 管理アクセス用VPCルータ定義 └── output.tf # アウトプット
ポイントごとに解説していきます。
1) 変数の定義 + 変数の設定(variables.tfとterraform.tfvars)
まずは変数の定義部分と、変数への値設定部分を見てみましょう。
変数の定義はvariables.tfで行なっています。以下のような内容となっています。
#-------------------------------------- # 変数定義 #-------------------------------------- # Webサーバ 管理者パスワード variable web_server_password {} # Webサーバ定義 variable web_servers { type = "list" } # DBサーバ 管理者パスワード variable db_server_password {} # DBサーバ定義 variable db_servers { type = "list" } # VPCルータ リモートアクセス ユーザー名 variable vpn_username {} # VPCルータ リモートアクセス パスワード variable vpn_password {} # VPCルータ 事前共有鍵 variable vpc_pre_shared_secret {} # VPCルータ 配置ゾーン variable vpc_zone { } # スイッチを配置するゾーン variable switch_zones { type = "list" }
ここでは変数の定義のみ行いました。実際に投入する値はterraform.tfvarsファイルで指定しています。このファイルにはパスワードなどが直接記載されていますので各自で適切に置き換えてください。
#-------------------------------------- # 変数への投入値 #-------------------------------------- # Webサーバ 管理者パスワード web_server_password = "PUT_YOUR_PASSWORD_HERE" # Webサーバの定義 web_servers = [ { name = "web-is1b-01" zone = "is1b" private_ipaddr = "192.168.0.101" private_mask_len = 24 private_gateway = "192.168.0.254" }, { name = "web-is1b-02" zone = "is1b" private_ipaddr = "192.168.0.102" private_mask_len = 24 private_gateway = "192.168.0.254" }, { name = "web-tk1a-01" zone = "tk1a" private_ipaddr = "192.168.0.201" private_mask_len = 24 private_gateway = "192.168.0.254" }, { name = "web-tk1a-02" zone = "tk1a" private_ipaddr = "192.168.0.202" private_mask_len = 24 private_gateway = "192.168.0.254" } ] # DBサーバ 管理者パスワード db_server_password = "PUT_YOUR_PASSWORD_HERE" # DBサーバの定義 db_servers = [ { name = "db01" zone = "is1b" ipaddr = "192.168.0.51" mask_len = 24 gateway = "192.168.0.254" is_master = true # DBレプリケーション用 }, { name = "db02" zone = "tk1a" ipaddr = "192.168.0.52" mask_len = 24 gateway = "192.168.0.254" is_master = false # DBレプリケーション用 } ] # VPCルータ リモートアクセス ユーザー名 vpn_username = "PUT_YOUR_USER_NAME" # VPCルータ リモートアクセス パスワード vpn_password = "PUT_YOUR_PW_HERE" # VPCルータ 事前共有鍵 vpc_pre_shared_secret = "PUT_YOUR_SECRET_HERE" # VPCルータ 配置ゾーン vpc_zone = "is1b" # スイッチを配置するゾーン switch_zones = ["is1b", "tk1a"]
特徴的なのはWeb/DBサーバ用の値を定義している部分でリスト型変数の値としてマップ型を利用している部分です。
# Webサーバの定義 web_servers = [ { name = "web-is1b-01" zone = "is1b" private_ipaddr = "192.168.0.101" private_mask_len = 24 private_gateway = "192.168.0.254" }, [...省略...]
関連のある定義はなるべく一箇所にあった方がわかりやすいですので、今回は各サーバーで固有の値についてはここにまとめています。
こうして定義した値は以下のようにlookup関数との組み合わせなどで利用可能です。
# web_servers変数のcount.index番目の要素(マップ型)から # nameというキーの要素を検索 name = "${lookup(var.web_servers[count.index], "name")}"
リスト型変数の要素にマップ型を利用する方法は、count属性を利用するリソースとの相性が良いです。先ほどの例のようにcount.index番目の要素を参照するという形にするとtfファイルがシンプルになります。
2) ネットワークの定義(network.tf)
次にネットワーク用のリソース定義を見てみます。ここでは各ゾーンにスイッチを配置し、それぞれをブリッジで繋ぐようにしています。
tfファイルは以下の通りです。
#-------------------------------------- # ネットワークの定義 #-------------------------------------- # スイッチ resource sakuracloud_switch "switch" { name = "switch" bridge_id = "${sakuracloud_bridge.bridge.id}" count = 2 zone = "${var.switch_zones[count.index]}" } # ブリッジ resource sakuracloud_bridge "bridge" { name = "bridge" }
各ゾーンにスイッチをひとつ、今回は東京(tk1a)と石狩(is1b)を利用しますので、スイッチのcountには2を指定しました。
3) GSLBの定義(gslb.tf)
続いて広域負荷分散用のGSLBの定義を見てみます。
tfファイルは以下のようになっています。
#-------------------------------------- # GSLBの定義 #-------------------------------------- # GSLB本体の定義 resource "sakuracloud_gslb" "gslb" { name = "gslb" health_check = { protocol = "ping" } } # GSLB配下のサーバ定義 resource "sakuracloud_gslb_server" "servers" { count = "${length(var.web_servers)}" gslb_id = "${sakuracloud_gslb.gslb.id}" ipaddress = "${sakuracloud_server.web_servers.*.base_nw_ipaddress[count.index]}" }
注目はGSLB配下のサーバ定義でのcountの書き方です。
count = "${length(var.web_servers)}"
length関数は引数で指定されたリスト型変数の要素数を返すものです。length関数を利用しておくことで、Webサーバの定義を増やすだけでGSLBの設定も動的に変更されることになります。汎用性の高い関数ですので利用方法をしっかり押さえておくのがオススメです。
4) SSH公開鍵(さくらのクラウド上で生成)の定義
続いてはサーバに登録するSSH公開鍵の定義を見てみます。
当記事執筆時点のTerraform for さくらのクラウドの最新版(v0.8.1)においてSSH公開鍵をさくらのクラウド上で生成する機能がリリースされましたので早速利用しています。
#-------------------------------------- # SSH公開鍵の定義 #-------------------------------------- # SSH公開鍵 resource "sakuracloud_ssh_key_gen" "key" { name = "example-key" # 生成した秘密鍵をローカルマシンに保存 provisioner "local-exec" { command = "echo \"${self.private_key}\" > id_rsa; chmod 0600 id_rsa" } }
今回はパスフレーズなしの公開鍵を生成し、local-execプロビジョナを利用してローカルマシンに秘密鍵を保存するようにしました。
サーバにSSH接続する際はこの秘密鍵を利用するようにします。
5) Webサーバの定義(web.tf)
いよいよWebサーバの定義です。これまで定義した各種リソースとの接続やWebサーバのプロビジョニングを含んでいます。tfファイルは以下の通りです。
#-------------------------------------- # Webサーバの定義 #-------------------------------------- # OS(CentOS 7.3) data sakuracloud_archive "web_os" { os_type = "centos" count = "${length(var.web_servers)}" zone = "${lookup(var.web_servers[count.index], "zone")}" } # ディスクの定義 resource sakuracloud_disk "web_disks" { name = "${lookup(var.web_servers[count.index], "name")}" source_archive_id = "${data.sakuracloud_archive.web_os.*.id[count.index]}" hostname = "${lookup(var.web_servers[count.index], "name")}" password = "${var.web_server_password}" # 生成した公開鍵のIDを指定 ssh_key_ids = ["${sakuracloud_ssh_key_gen.key.id}"] # SSH接続時のパスワード/チャレンジレスポンス認証を無効化 disable_pw_auth = true count = "${length(var.web_servers)}" zone = "${lookup(var.web_servers[count.index], "zone")}" } # サーバーの定義 resource sakuracloud_server "web_servers" { name = "${lookup(var.web_servers[count.index], "name")}" disks = ["${sakuracloud_disk.web_disks.*.id[count.index]}"] tags = ["@virtio-net-pci"] # 追加NIC(スイッチに接続) additional_interfaces = ["${ lookup( zipmap( var.switch_zones, sakuracloud_switch.switch.*.id ), lookup(var.web_servers[count.index], "zone") ) }"] # プロビジョニング connection { user = "root" host = "${self.base_nw_ipaddress}" private_key = "${sakuracloud_ssh_key_gen.key.private_key}" } # プライベートIP設定 provisioner "remote-exec" { inline = [ <<EOS nmcli connection add \ type ethernet \ con-name local-eth1 \ ifname eth1 \ ip4 ${lookup(var.web_servers[count.index], "private_ipaddr")}/${lookup(var.web_servers[count.index], "private_mask_len")} \ gw4 ${lookup(var.web_servers[count.index], "private_gateway")} nmcli connection up local-eth1 EOS ] } # 動作確認用にApache(httpd)インストール + ファイアウォール(tcp:80)開放 provisioner "remote-exec" { inline = [ "yum install -y httpd", "hostname >> /var/www/html/index.html", "systemctl enable httpd.service", "systemctl start httpd.service", "firewall-cmd --add-service=http --zone=public --permanent", "firewall-cmd --reload" ] } count = "${length(var.web_servers)}" zone = "${lookup(var.web_servers[count.index], "zone")}" }
ちょっと大きめの定義ですので、ポイントごとに解説します。
countとzoneの定義
各リソースとも共通して以下のようにcountとzoneを指定しています。
count = "${length(var.web_servers)}"
zone = "${lookup(var.web_servers[count.index], "zone")}
前述のlength関数でのcount指定とlookup関数の合わせ技です。アーカイブ/ディスク/サーバはゾーンをまたいでお互いに接続できない(例えば石狩ゾーンのディスクを東京のサーバに接続することができない)ため、各リソースから共通の変数定義(web_servers変数)を参照することで同一ゾーンにリソースが作成されるようにしています。
スイッチIDの参照方法
ちょっと手の込んだテクニックを利用しているのがスイッチIDを参照する部分です。
# 追加NIC(スイッチに接続)
additional_interfaces = ["${
lookup(
zipmap(
var.switch_zones,
sakuracloud_switch.switch.*.id
),
lookup(var.web_servers[count.index], "zone")
)
}"]
ここでは、各サーバが属するゾーンに作成したスイッチIDを参照するようにしています。スイッチIDを参照する方法として、
- 1) キーにゾーン名、値にスイッチIDを持つマップ型変数を作成
- 2) サーバのゾーン名を利用してlookup関数で検索
という方法をとりました。
まず1)のマップ型変数を作成するためにzipmap関数を利用しています。
zipmap(
var.switch_zones,
sakuracloud_switch.switch.*.id
),
この関数は、2つのリスト型変数を引数に受け取り、各引数の各要素から第1引数(の要素)をキーに、第2引数(の要素)を値にしたマップ型変数を作成してくれます。なお、引数に指定したリスト型変数のそれぞれの要素数が異なる場合はエラーとなります。
こうして得られたマップ型変数に対して2) lookup関数で検索することでスイッチIDを検索することが出来ます。
プロビジョニング(SSH接続設定)
SSHで接続してプロビジョニングを行うための設定が以下の部分です。
# プロビジョニング connection { user = "root" host = "${self.base_nw_ipaddress}" private_key = "${sakuracloud_ssh_key_gen.key.private_key}" }
${self}はその名の通り自分自身を参照するための構文です。ここでのselfはサーバリソース(sakuracloud_server)をさしています。今回はSSH接続先となるホストのグローバルIPアドレスを参照するためにselfを利用しています。
次に、SSH接続時に利用する秘密鍵を"${sakuracloud_ssh_key_gen.key.private_key}"で指定しています。
これらの設定でSSH接続でプロビジョニングを行えるようになります。
ヒアドキュメントの利用
SSH接続後にプロビジョニングで実行される内容はremote_execプロビジョナに記述されています。ここでは長い文字列をtfファイル上で扱うためにヒアドキュメントを利用しています。
# プライベートIP設定
provisioner "remote-exec" {
inline = [ <<EOS
nmcli connection add \
type ethernet \
con-name local-eth1 \
ifname eth1 \
ip4 ${lookup(var.web_servers[count.index], "private_ipaddr")}/${lookup(var.web_servers[count.index], "private_mask_len")} \
gw4 ${lookup(var.web_servers[count.index], "private_gateway")}
nmcli connection up local-eth1
EOS
]
}
remote-execプロビジョナで実行するスクリプトを指定するためにinline属性を指定しています。inline属性は実行したいコマンドを文字列の配列で指定することでそれぞれのコマンドを実行するようになっているのですが、ここではヒアドキュメントを用いて記述した文字列を配列のただ一つの要素として指定しています。
実際にはnmcliコマンドを2回実行する内容となっていますので、それぞれのコマンドを個別に配列の要素としても問題ありません。
6) DBサーバの定義(db.tf)
続いてDBサーバの定義です。Webサーバとの違いとして、VPN接続後でないとSSH接続できないため、プロビジョニングにはスタートアップスクリプトを利用しています。プロビジョニングの内容もDBに特化したものとなります(ただし今回は省略しています)。tfファイルは以下の通りです。
#-------------------------------------- # DBサーバの定義 #-------------------------------------- # OS(CentOS 7.3) data sakuracloud_archive "db_os" { os_type = "centos" count = "${length(var.db_servers)}" zone = "${lookup(var.db_servers[count.index], "zone")}" } # ディスクの定義 resource sakuracloud_disk "db_disks" { name = "${lookup(var.db_servers[count.index], "name")}" source_archive_id = "${data.sakuracloud_archive.db_os.*.id[count.index]}" hostname = "${lookup(var.db_servers[count.index], "name")}" password = "${var.web_server_password}" # 生成した公開鍵のIDを指定 ssh_key_ids = ["${sakuracloud_ssh_key_gen.key.id}"] # SSH接続時のパスワード/チャレンジレスポンス認証を無効化 disable_pw_auth = true # スタートアップスクリプト(DBセットアップ + master/slaveそれぞれ固有の処理) note_ids = [ "${sakuracloud_note.setup_database.id}", #DBセットアップ "${lookup(var.db_servers[count.index], "is_master") ? sakuracloud_note.setup_master.id : sakuracloud_note.setup_slave.id }" ] count = "${length(var.db_servers)}" zone = "${lookup(var.db_servers[count.index], "zone")}" } # サーバーの定義 resource sakuracloud_server "db_servers" { name = "${lookup(var.db_servers[count.index], "name")}" disks = ["${sakuracloud_disk.db_disks.*.id[count.index]}"] tags = ["@virtio-net-pci"] base_interface = "${ lookup( zipmap( var.switch_zones, sakuracloud_switch.switch.*.id ), lookup(var.db_servers[count.index], "zone") ) }" base_nw_ipaddress = "${lookup(var.db_servers[count.index], "ipaddr")}" base_nw_gateway = "${lookup(var.db_servers[count.index], "gateway")}" base_nw_mask_len = "${lookup(var.db_servers[count.index], "mask_len")}" # 直接SSH接続できないため、プロビジョニングはスタートアップスクリプトで行う count = "${length(var.db_servers)}" zone = "${lookup(var.db_servers[count.index], "zone")}" } # スタートアップスクリプト(DBセットアップ:master/slave共通部分) resource sakuracloud_note "setup_database" { name = "setup_database" content = <
Master/Slaveでのプロビジョニング処理の切り替え
プロビジョニング用のスタートアップスクリプトを指定している部分は以下の通りです。
# スタートアップスクリプト(DBセットアップ + master/slaveそれぞれ固有の処理) note_ids = [ "${sakuracloud_note.setup_database.id}", #DBセットアップ "${lookup(var.db_servers[count.index], "is_master") ? sakuracloud_note.setup_master.id : sakuracloud_note.setup_slave.id }" ]
ここでは2つのスタートアップスクリプトを実行するようにしています。
最初にDB自体のインストールなどを行うためのスタートアップスクリプトを実行し、次にMaster/Slaveそれぞれの役割に応じたスタートアップスクリプトを実行するようにしています。
MasterなのかSlaveなのかで分岐するために以下のように3項演算子を利用しています。
"${lookup(var.db_servers[count.index], "is_master") ? sakuracloud_note.setup_master.id : sakuracloud_note.setup_slave.id }"
変数定義時にis_masterという値を用意しておきました。この値を3項演算子での判定に利用しています。
7) その他の定義(vpc_router.tf、output.tf)
後はVPCルータの定義とアウトプットの定義です。tfファイルは以下のようになっています。
#-------------------------------------- # VPCルータの定義 #-------------------------------------- # VPCルータ本体 resource "sakuracloud_vpc_router" "vpc" { name = "vpc_router" zone = "${var.vpc_zone}" } # インターフェースの定義 resource "sakuracloud_vpc_router_interface" "eth1"{ vpc_router_id = "${sakuracloud_vpc_router.vpc.id}" index = 1 # NICのインデックス(1〜7) switch_id = "${ lookup( zipmap( var.switch_zones, sakuracloud_switch.switch.*.id ), var.vpc_zone ) }" # スイッチのID ipaddress = ["192.168.0.254"] # 実IPリスト nw_mask_len = 24 # ネットマスク長 } # リモートアクセス:L2TP/IPSec resource "sakuracloud_vpc_router_l2tp" "l2tp" { vpc_router_id = "${sakuracloud_vpc_router.vpc.id}" vpc_router_interface_id = "${sakuracloud_vpc_router_interface.eth1.id}" pre_shared_secret = "${var.vpc_pre_shared_secret}" # 事前共有シークレット range_start = "192.168.0.11" # IPアドレス動的割り当て範囲(開始) range_stop = "192.168.0.20" # IPアドレス動的割り当て範囲(終了) } # リモートユーザアカウント resource "sakuracloud_vpc_router_user" "user1" { vpc_router_id = "${sakuracloud_vpc_router.vpc.id}" name = "${var.vpn_username}" # ユーザ名 password = "${var.vpn_password}" # パスワード }
#-------------------------------------- # アウトプットの定義 #-------------------------------------- # WebサーバへのSSH接続コマンド output "ssh_to_web" { value = "${ zipmap( sakuracloud_server.web_servers.*.name, formatlist("ssh -i id_rsa root@%s", sakuracloud_server.web_servers.*.base_nw_ipaddress) ) }" } # DBサーバへのSSH接続コマンド(VPN接続必須) output "ssh_to_db" { value = "${ zipmap( sakuracloud_server.db_servers.*.name, formatlist("ssh -i id_rsa root@%s", sakuracloud_server.db_servers.*.base_nw_ipaddress) ) }" } # GSLBのFQDN # 本来はロードバランシングしたいホスト名のCNAMEレコードとしてDNSの登録するもの output "gslb_fqdn" { value = "${sakuracloud_gslb.gslb.FQDN}" }
特筆すべき点はなく、これまで扱ったテクニックで十分読み解けるはずです。
なお、今回の構成で動作確認を行うためにGSLBで発行されるFQDNをアウトプットとして定義しています。
# GSLBのFQDN
# 本来はロードバランシングしたいホスト名のCNAMEレコードとしてDNSの登録するもの
output "gslb_fqdn" {
value = "${sakuracloud_gslb.gslb.FQDN}"
}
コメントアウト部分にも記載していますが、本来はこの値を実際にサービスを提供するホスト名のCNAMEレコードとしてDNS登録する必要があります。
GSLBで発行されたFQDNに直接アクセスすることで動作確認は出来ますので今回はDNSレコードの登録部分は扱っていません。
おまけ: GSLBで発行されたFQDNをDNS登録する例
もしさくらのクラウドDNSを利用する場合、以下のようなtfファイルでCNAMEレコードの登録が可能です。
#-------------------------------------- # (付録)DNSサーバの定義 #-------------------------------------- # 新たにゾーンを登録する場合 # 注: ゾーン登録後にネームサーバの設定が必要です。 # 詳しくは以下を参照してください。 # https://www.slideshare.net/sakura_pr/sakuracloud-dns/14 #resource sakuracloud_dns "dns" { # zone = "example.com" #} # すでにゾーン登録済みの場合はデータソースで参照する data sakuracloud_dns "dns" { filter = { name = "Name" values = ["example.com"] } } # レコードの登録 resource "sakuracloud_dns_record" "gslb_cname" { # 新たにゾーンを登録した場合 #dns_id = "${sakuracloud_dns.dns.id}" # 登録済みゾーンをデータソースで参照する場合 dns_id = "${data.sakuracloud_dns.dns.id}" name = "target-host-name" # ロードバランス対象のホスト名 type = "CNAME" value = "${sakuracloud_gslb.gslb.FQDN}." # GSLBで発行されたFQDNを指定(末尾のピリオドに注意) }
動作確認
terraform applyしたら、アウトプット"gslb_fqdn"へブラウザでHTTPアクセスしてみましょう。いずれかのWebサーバに振り分けられているのが確認できるはずです。OSやブラウザでのDNSキャッシュをクリアして再度HTTPアクセスすることで別のホストに振り分けられることも確認できるはずです。(同じホストに振り分けられることもあるため数回試してみてください。)
終わりに
全5回にわたりTerraformの基本からさくらのクラウドでの環境構築までを扱ってきました。
本連載で扱ったサンプルは以下のリポジトリで公開しています。
https://github.com/yamamoto-febc/terraform_for_sakuracloud_start_guide/
本連載などを活用しインフラのコード化を行なっておくことで、インフラ構築の速度/精度の向上や環境の再現/複製の容易化など様々なメリットを享受することができると思います。これらを通じインフラの使い捨てやオンデマンドな調達といった使い方も可能になってきます。
Terraform for さくらのクラウドが、クラウドをよりクラウドらしく使うための一助となれば幸いです。
なお、Terraform for さくらのクラウドは現在も活発に開発中です。
GitHub: Terraform for さくらのクラウド
使い方についての質問やバグ報告、機能要望などがございましたら、いつでも大歓迎しておりますのでお気軽にGitHubのIssueを登録ください。
以上です。