さくらの高火力コンピューティングで100種類の画像識別をする

さくらインターネット 技術本部アプリケーション アルバイトの伊東道明です。
現在、ディープラーニングを用いた画像認識精度が人間を超えるほどの精度を出していて、とてもホットな話題となっています。画像認識とは、たくさん画像がある中で、これは○○の画像、これは○○の画像と認識することで、私たち人間はごく普通に行なっています。ですが、これをコンピュータに行わせようとすると、とても難しい問題になります。
例えば、以下の写真を見てください。

この写真は、猫の写真でしょうか?それとも犬の写真でしょうか?
私たちは耳の形や色、毛、尻尾の形等の特徴から「猫の写真」と認識することができます。ですが、これをコンピュータに認識させるためには、自分でそれらの特徴を取ってきて、その特徴をもとに犬ではなく猫であると識別させる「識別器」が必要があります。この識別器を作るために、様々な手法が提案されてきましたが、どれも人間に遠く及ばない精度でした。
ここ数年、その「識別器」を作るとても有効な手段の1つとして、ディープラーニングが注目されています。ディープラーニングのアルゴリズムをベースに、様々な調整を行うことで高精度でコンピュータが画像を識別可能な識別器を作成できます。
この画像識別技術は、自動車の自動運転や植物の病気を自動診断するシステムなど様々な分野で活躍しています。
画像認識精度をはかる際、「CIFAR-100」と呼ばれる画像のデータセットを用いていることが多いです。CIFAR-100とは、100種類の画像がそれぞれ600枚ずつ、合計60000枚用意されているデータセットです。どんな画像があるかは後ほど紹介いたします。
この記事では、さくらの高火力コンピューティング上でCIFAR-100を画像の種類によって識別する画像識別器を作成してみます。
この記事を読んでいただくことで、実際に人間の精度に近い画像識別器を作成することが出来るようになり、どれくらい識別器を作るのに時間がかかるのかを知ることができます。
また、ここでは実践編、解説編と章立ててそれぞれ説明します。とりあえず手を動かしたい方は実践編を、何をやってるか先に知りたい方は解説編を先に読むことをオススメします。
また、解説編で意味のわからない単語などがあればこの記事を参考にしてください。
実践編
環境セットアップ
この記事の動作環境は、Ubuntu16.04, CUDA 8, cuDNN v5.1, Python 2.7.11です。
さくらの高火力コンピューティングを利用している方向けの記事となっていますが、動作環境を満たしていれば正常に動作します。
まず、GPUを使用するためにCUDA 8のインストールが必須で、加えて綺麗な環境を整えるためにpyenv環境の構築をします。こちらの記事を参考にして構築してください。
さらに、cuDNN v5.1というライブラリが必要なので、インストールします。
NVIDIAのページにアクセスし、会員登録をします。
すると、以下の様なダウンロードページにたどり着くことが出来るので、赤く囲ったところをクリックしてファイルを自分のPCにダウンロードしてください。
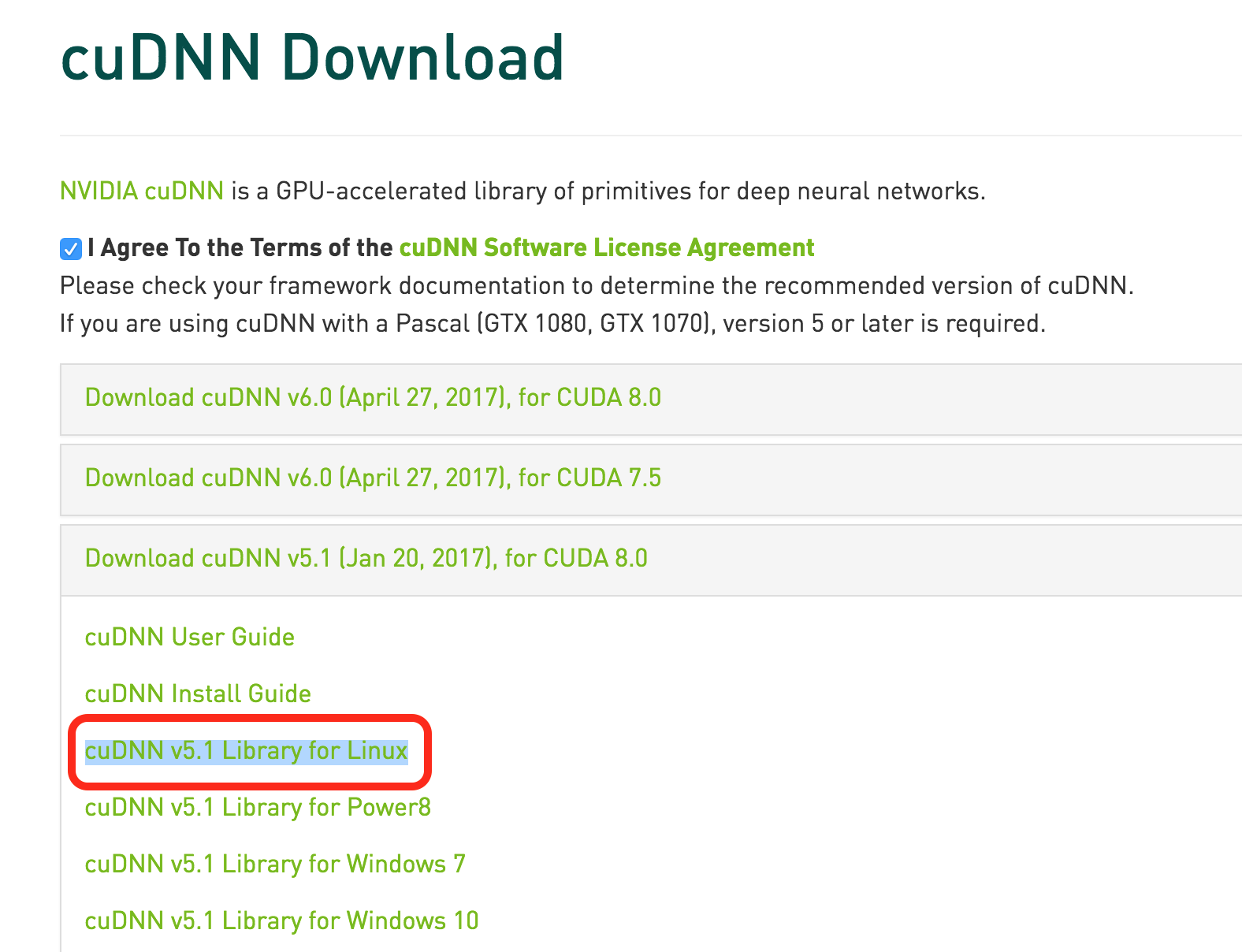
ダウンロードが完了したら、ファイルをscpコマンドなどで高火力サーバーのホームディレクトリに移動します。
その後、以下の順にコマンドを打ちます。
$ tar xzvf cudnn-8.0-linux-x64-v5.1.tgz $ sudo cp -a cuda/lib64/* /usr/local/cuda-8.0/lib64/ $ sudo cp -a cuda/include/* /usr/local/cuda-8.0/include/ $ sudo ldconfig
これでcuDNN v5.1のインストールは完了です。
続いて、Chainerのインストールをします。
pyenvでPythonのバージョンを2.7.11にしたあと、インストールコマンドを1つ打てば終了です。
$ pyenv install 2.7.11 $ pyenv local 2.7.11 $ pip install chainer
サンプルコードの実行
今回は、Chainerの中に入っているサンプルを使います。
まず以下のコマンドでGithubからChainerのソースコードをダウンロードしてください。
$ git clone https://github.com/pfnet/chainer.git
そのあと、サンプルコードのディレクトリへ移動し、サンプルコードを実行します。
$ cd chainer/examples/cifar $ pyenv local 2.7.11 $ python train_cifar.py -g 0 -d cifar100
これで、サンプルコードが動き出して以下の様に学習が始まると思います。
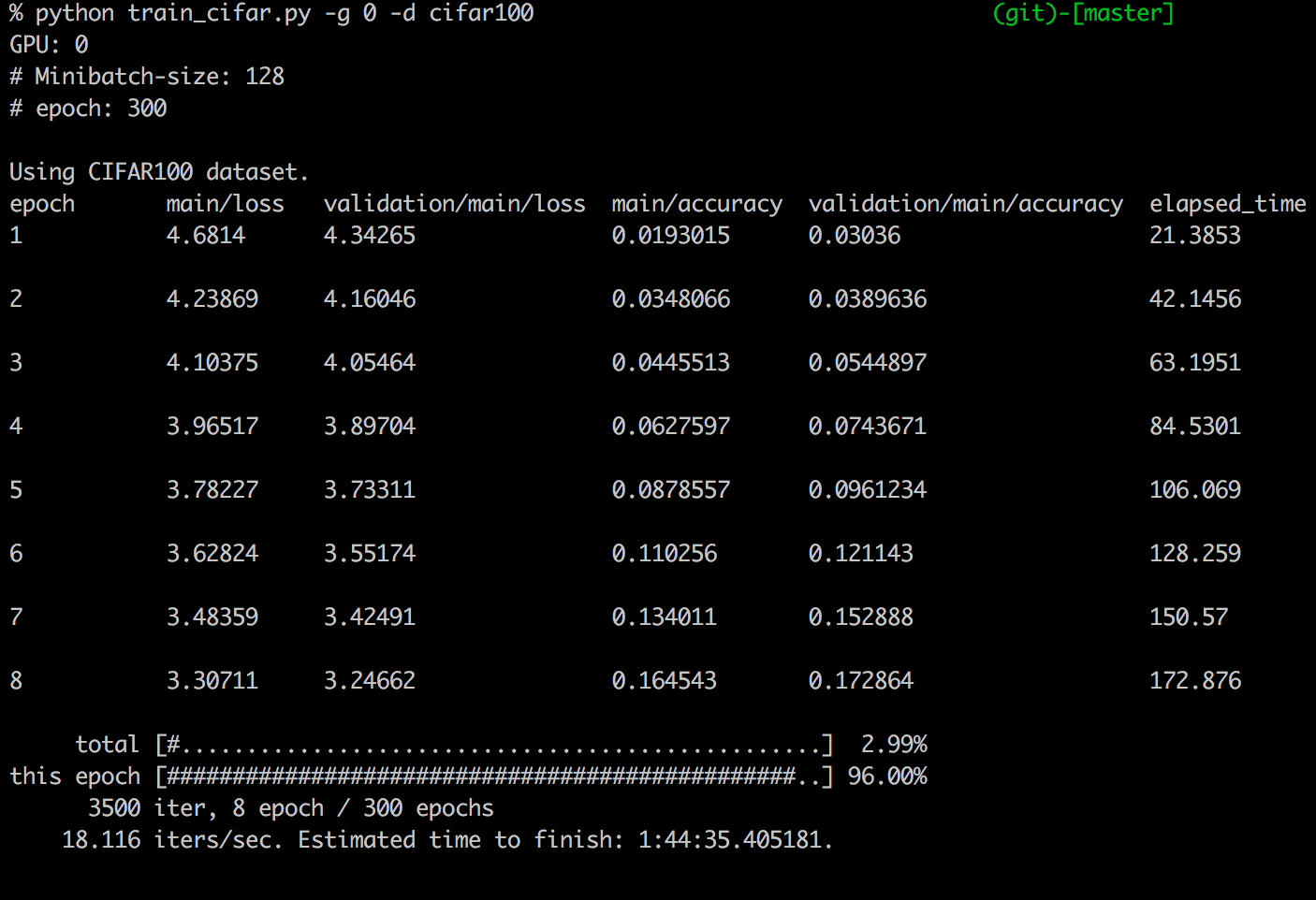
左から順に
- エポック数
- 学習用データのロス(エラー率の様なもの)
- バリデーションデータ(各エポック内での精度検証用データ)のロス
- 学習用データの精度
- バリデーションデータの精度
- ラップタイム(経過時間)
となっています。
さくらの高火力コンピューティングのpascal世代の「Titan X」1枚で行なっている場合、2時間弱ほど学習に時間がかかるためテレビでも見て気長に待ちましょう。
ちなみに、このサンプルではバリデーションデータの精度が大体65%くらいになるはずです。
世界最高精度は約75%なので、そこそこいい精度であると言えるのではないでしょうか。
解説編
では、プログラムが回せたということで、実際に何をやっているのかを見ていきましょう。
データセット
CIFAR-100と呼ばれるデータセットは、100種類の画像がそれぞれ600枚ずつ、合計60000枚用意されています。
以下のように、様々な画像があります。

100種類の画像を識別するのは非常に難しく、7割程度識別できればかなりいい方だと言われています。
今回は、このデータセットをVGGと呼ばれるモデルを用いて画像識別を行なっています。
VGG
VGGとは、2014年にILSVRCと呼ばれる画像認識コンペティションで優勝したCNNのモデルです。画像識別でよく用いられています。
16~19層のモデルがよく使われており、学習するデータの内容などによって調整しています。
今回は、以下のようなVGGモデルを用いました。
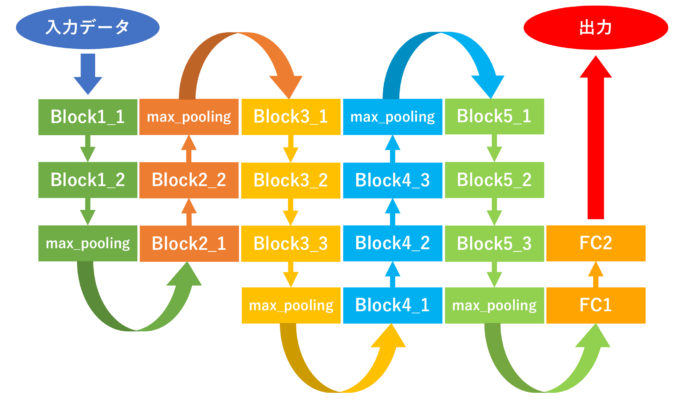
図中のFCは全結合層を示しています。
また、Blockの中身は以下のようになっています。
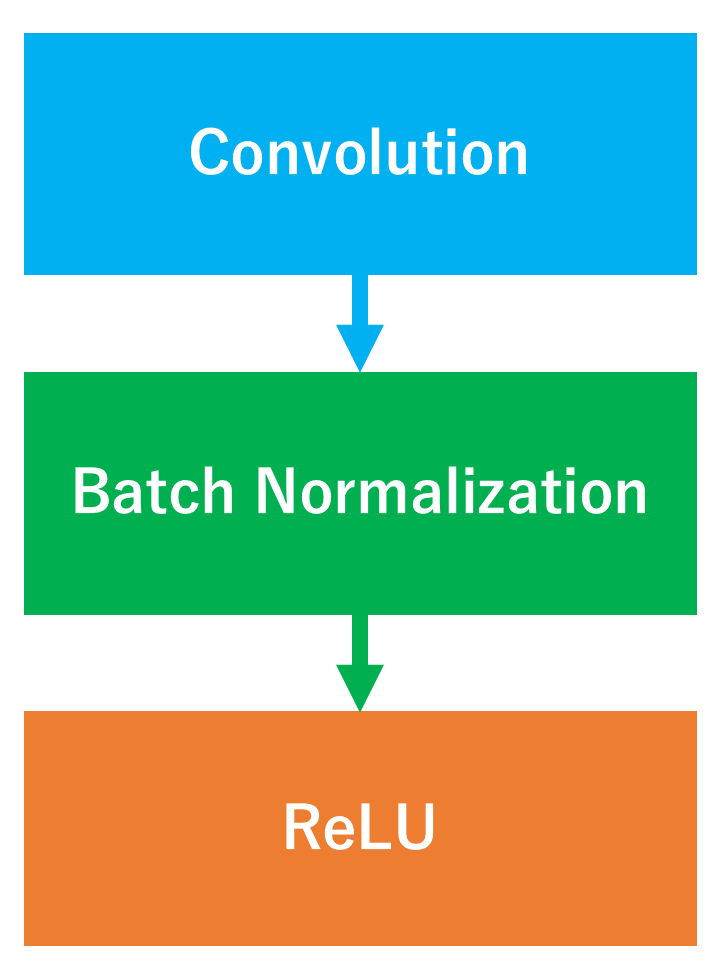
また、活性化関数は各畳み込み層でReLU関数が用いられています。
層の大きさなど詳細はソースコードを見ながら説明していきます。
ソースコード
今回は、Chainerのサンプルをそのまま使用しました。
では、ソースコードのモデルの部分に焦点を当てて解説していきます。
こちらにモデル部分は定義されています。
上から順に読んでいきましょう。
class Block(chainer.Chain):
"""コメントは省略"""
def __init__(self, out_channels, ksize, pad=1):
super(Block, self).__init__(
conv=L.Convolution2D(None, out_channels, ksize, pad=pad,
nobias=True),
bn=L.BatchNormalization(out_channels)
)
def __call__(self, x, train=True):
h = self.conv(x)
h = self.bn(h, test=not train)
return F.relu(h)
ここでは、呼び出すと畳み込み層の後にBatch Normalizationと呼ばれるミニバッチ内の出力を平均0/分散1にする手法を適用しています。
Batch Normalizationを用いることで、学習係数をあげることによる勾配消失問題などが解決され、学習係数をあげてより早く学習を進めることができます。
また、学習結果が重みの初期値にあまり依存しなくなるなどのメリットがあります。
その後、活性化関数であるReLU関数に値を通しています。
そして、畳み込み・Batch Normalization・活性化関数の一連の処理をBlockというクラスでひとまとめにしています。
では、モデル全体を見ていきましょう。
class VGG(chainer.Chain):
"""コメントは省略"""
def __init__(self, class_labels=10):
super(VGG, self).__init__(
block1_1=Block(64, 3),
block1_2=Block(64, 3),
block2_1=Block(128, 3),
block2_2=Block(128, 3),
block3_1=Block(256, 3),
block3_2=Block(256, 3),
block3_3=Block(256, 3),
block4_1=Block(512, 3),
block4_2=Block(512, 3),
block4_3=Block(512, 3),
block5_1=Block(512, 3),
block5_2=Block(512, 3),
block5_3=Block(512, 3),
fc1=L.Linear(None, 512, nobias=True),
bn_fc1=L.BatchNormalization(512),
fc2=L.Linear(None, class_labels, nobias=True)
)
self.train = True
ここでは、先ほど定義したBlockクラスのオブジェクトをVGGのモデルに沿って宣言しています。
各Blockのオブジェクトを生成する際、引数に出力するチャンネルの数と畳み込み層のカーネルサイズを決めています。
そして、最後に全結合層のfc1・fc2と全結合層用のBatch Normalizationを定義しています。
続いて、全体のつながりをみてみます。
def __call__(self, x):
# 64 channel blocks:
h = self.block1_1(x, self.train)
h = F.dropout(h, ratio=0.3, train=self.train)
h = self.block1_2(h, self.train)
h = F.max_pooling_2d(h, ksize=2, stride=2)
# 128 channel blocks:
h = self.block2_1(h, self.train)
h = F.dropout(h, ratio=0.4, train=self.train)
h = self.block2_2(h, self.train)
h = F.max_pooling_2d(h, ksize=2, stride=2)
# 256 channel blocks:
h = self.block3_1(h, self.train)
h = F.dropout(h, ratio=0.4, train=self.train)
h = self.block3_2(h, self.train)
h = F.dropout(h, ratio=0.4, train=self.train)
h = self.block3_3(h, self.train)
h = F.max_pooling_2d(h, ksize=2, stride=2)
# 512 channel blocks:
h = self.block4_1(h, self.train)
h = F.dropout(h, ratio=0.4, train=self.train)
h = self.block4_2(h, self.train)
h = F.dropout(h, ratio=0.4, train=self.train)
h = self.block4_3(h, self.train)
h = F.max_pooling_2d(h, ksize=2, stride=2)
# 512 channel blocks:
h = self.block5_1(h, self.train)
h = F.dropout(h, ratio=0.4, train=self.train)
h = self.block5_2(h, self.train)
h = F.dropout(h, ratio=0.4, train=self.train)
h = self.block5_3(h, self.train)
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.dropout(h, ratio=0.5, train=self.train)
h = self.fc1(h)
h = self.bn_fc1(h, test=not self.train)
h = F.relu(h)
h = F.dropout(h, ratio=0.5, train=self.train)
return self.fc2(h)
先ほど宣言した層を繋げ、各ブロックにDropoutという層を挟んでいます。
Dropoutは、学習時に層の出力の一部をランダムでゼロにすることで過学習を防ぎます。
引数ratioにドロップアウトさせるユニットの数を割合で指定しています。
以上がモデルの定義部分になります。
速度比較
まず、個人的に使用している2年前の最新GPUであった「GTX980」1枚で学習をして見たところ、実行時間は以下のようになりました。
3時間11分43秒
次に、さくらの高火力コンピューティングpascal世代の「Titan X」1枚の学習時間は以下の様になりました。
1時間52分54秒
なんと1時間以上も早くなっていました。
研究や開発をするときには、何回もプログラムを実行します。プログラムを実行する度に1時間以上時間が節約できるため、時間をかけたくない方は是非高火力コンピューティングを使ってみてください。
まとめ
いかがだったでしょうか。
この記事では、100種類の画像を識別してみました。
現在世界最高精度が約75%なので、パラメータを変える、ネットワークを変えるなどして75%越えを目指してください!
本記事は後述の関連記事とは異なる機械学習フレームワークを用いたので、関連記事の方も読んでいただいた方は、両方体験してどちらの方が自分にとって使いやすいかを比較することができたか思います。
他にも様々なフレームワークがあるので、興味のある方は是非触って見てください。