もうすぐ実写AITuber登場。Stable Diffusionでリアルタイム画像生成をしてみた

こんにちは、テリーです。ChatGPTに並んで進化の激しい「画像生成AI」を使ってみたことはありますか?ほしい画像を文章で指定すると、それに沿った画像を出力するAIです。かなりの計算量を必要とするため、画像1枚を出力するのに10~60秒かかりますが、世界中の技術者たちがより速く出力する方法を模索して、今まさに日進月歩の進化の最中です。
画像生成AIにもたくさんの種類があり、「Midjourney(ミッドジャーニー)」「DALL・E2(ダリツー)」「Stable Diffusion(ステーブルディフュージョン)」「Adobe Firefly(ファイアフライ)」の4つが特に有名です。この中で「Stable Diffusion」はオープンソースかつ商用利用可能なため、できたばかりのホットな関連技術を取り入れた使い方や、学習済みモデルの差し替え、自作モデルの生成など、自分好みの調整とカスタマイズの楽しさで人気です。
さて、今回はStable DiffusionにWebカメラの映像を関連づけ、カメラに写っている自分と同じポーズを取るAIキャラクターをリアルタイムに表示するサンプルプログラムを紹介します。
目次
対象読者
- Stable DiffusionをColabまたはローカルで実行したことがある人
- Stable Diffusionが生成するキャラを動かしたい人
※ 本記事はStable Diffusionの入門ではないため、解説を省略している箇所があります。
動作確認環境
今回の記事は環境にかなり依存します。環境によっては動作しなかったり、速度が違いすぎることが十分にありえるので、適宜読み替えてください。
- Windows 11 22H2
- CPU Core i7-12700H (メモリ32GB)
- GPU NVIDIA Geforce RTX 3060 Laptop (メモリ6GB)
- Stable Diffusion WebUI 1.3.0
- sdwebuiapi 0.9.0
- ControlNet 1.1.201
- Pytorch 2.0.1+cu118
- CUDA 11.8
- Python 3.10.11
- MediaPipe 0.10.0
- OBS 29.0.2
Stable Diffusion WebUIのセットアップ
まずStable Diffusion WebUIをインストールし、動作確認をします。インストールコマンドは下記のとおりです。すでに環境構築済みの方は、ライブ配信専用に生成速度を優先した設定を行えるように、別フォルダに新規インストールするのがオススメです。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git初回実行、2回目以降の実行は同じコマンドです。関連ライブラリはwebui-user.batを初回実行時に自動的にインストールされます。
cd stable-diffusion-webui
.\webui-user.bat初回実行時のインストールが終わったら、ログをよく見ると http://127.0.0.1:7860/ へのアクセスを促すような表示が出ます。ブラウザを開き、そのURLにアクセスします。当該ポートが使用済みの場合は7861になることもあります。
まずはtext2imgタブで簡単な画像を生成して速度を測ってみましょう。プロンプトに簡単なテキストを入れます。下記は入力したテキストの例です。
masterpiece, best quality, 1girl, face, simple white background下記のような画像が生成されることを確認します。筆者の環境では20stepsで約4秒、約6.6it/sでした。正面を向いていることもあれば、やや首をかしげて肩も斜めになることもあります。
※it/s=iterations per second。1秒あたりのステップ数。

ControlNetのセットアップ
次にControlNetをインストールします。ブラウザのページ上部のタブ一覧の最後尾「Extensions」タブをクリックします。その下段の「Available」タブをクリックし、「Load from:」と書かれたボタンをクリックします。

すると大量の拡張機能がテーブルで一覧表示されます。「sd-webui-controlnet」というタイトルのプラグインを検索します。同列右端の「Install」ボタンを押し、インストールが完了したら、Stable Diffusion WebUIを再起動します。他のExtensionは本当に必要なもののみインストールしてください。拡張機能をインストールするほど、メモリ消費が増える傾向にあるため、ライブに使用しない単なる便利ツールは別のフォルダにインストールするのがオススメです。

次に、ControlNetに必要なモデルファイルの入手です。HuggingFaceのこちらから「control_v2p_sd15_mediapipe_face.safetensors 1.45 GB」をダウンロードします。ダウンロードしたファイルを「extensions/sd-webui-controlnet/models」に移動します。
再起動が終わったらブラウザをリロードし、「Extensions」タブ左隣の「Settings」タブをクリックします。画面左端に並んでいるたくさんのメニューの中から「ControlNet」を探します。最後の方にいるので下から探した方が早いです。
ControlNetの設定ページを開いたら、中央付近の「Multi ControlNet: Max models amount (requires restart)」を探します。値をデフォルトの「1」から「4」にします。ここで設定した数字より多いControlNetは後半が無視されます(詳細は後述)。「Apply settings」ボタンを押し、Stable Diffusion WebUIをもう一度再起動します。

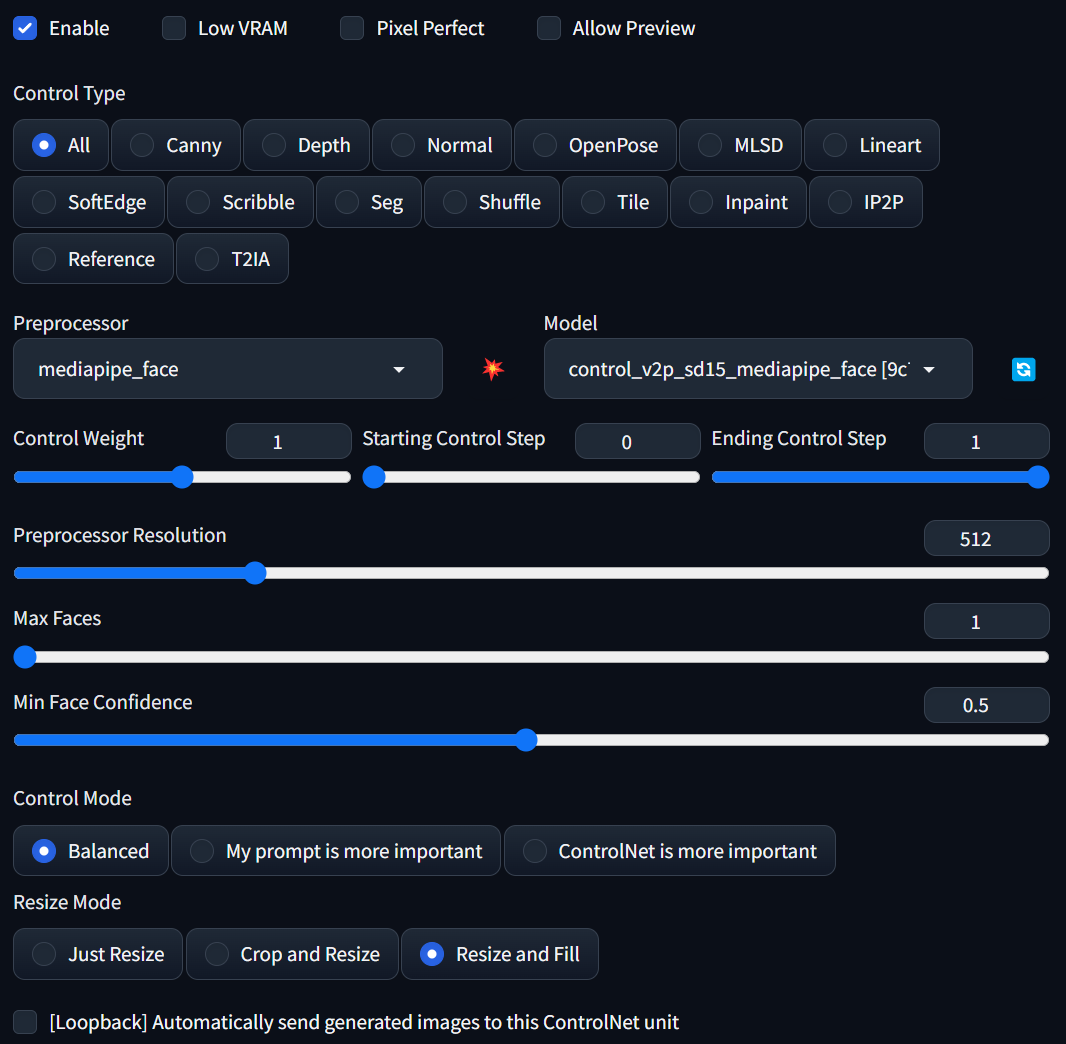
ブラウザをリロードすると、ControlNetの設定エリアが画面左下付近に現れます。ここに顔が写っている何かの画像をアップロードし、「Enable」にチェックを入れ、「Preprocessor」のドロップダウンでは「mediapipe_face」、「Model」のドロップダウンでは「control_v2p_sd15_mediapipe_face [9c7784a9]」を選択します。「Resize Mode」は「Resize and Fill」を選びます。
この状態で、プロンプトに前述の画像を作成したときと同じテキストを入力して、「Generate」ボタンを押してください。
masterpiece, best quality, 1girl, face, simple white backgroundすると、何枚画像を生成しても必ず真正面を向く画像になります。髪型や髪色は毎回異なりますが、目の間隔、顔の位置、あごのラインは毎回ほぼ同じになります。これがControlNetの仕事です。Preprocessor「mediapipe_facemesh」が参考画像の顔の輪郭、目、眉、口の輪郭を取得し、Model「Control_v2p_sd15_mediapipe_face」は、その情報を元に生成画像に強い指示を出すことができます。

ここまででStable Diffusion WebUIとControlNetの動作確認ができたことになります。
API機能の有効化
Stable Diffusion WebUIにはブラウザ外から同等の操作が可能な「WebAPI機能」があります。Stable Diffusion本体を直接呼ぶのはパラメータもファイルも多すぎてよくわからなくても、必要最小限のデータ(例えばプロンプトのみ)を送って、数秒後に生成された画像を受け取れるとプログラムが描きやすくて便利です。Python以外のプログラムからも気軽に呼べますし、呼び出し元と画像生成が別のコンピュータという構成も可能になります。また複数台の画像生成サーバを一括で管理するようなプログラムも組みやすくなります。
デフォルトで無効になっているAPI機能は「--api」をコマンドラインオプションに追加することで有効になります。具体的には「webui-user.bat」(下記プログラム)の6行目 COMMANDLINE_ARGS の値に--apiを追加します。このファイルを修正したらStable Diffusion WebUIを再起動します。
1. @echo off
2.
3. set PYTHON=
4. set GIT=
5. set VENV_DIR=
6. set COMMANDLINE_ARGS=--api --opt-sdp-attention
7.
8. call webui.bat自作Pythonプログラムから画像生成
さて、Stable Diffusion WebUIを触っている人の中で、自作プログラムから呼び出したことがある人は少ないのではないでしょうか? あまりにも多機能すぎて、どの引数に何を指定すればブラウザで操作するのと同等の画像が生成されるのか、引数のスペルが間違っていないかなど、考えるだけでおっくうです。そんな人向けにAPI呼び出しをさらに簡単にするPython用ラッパーライブラリsdwebuiapiがあります。
このライブラリを使うと、デフォルトパラメータがイイ感じに指定されていますので、気軽にプログラムを組むことができます。とても軽量なラッパーなので、もし機能に不満があれば書き換えることも容易です。
VSCodeでstable-diffusion-webuiのフォルダを開いたあと、VSCodeのTerminalの中から下記のコマンドを実行してsdwebuiapiをインストールします。
pip install webuiapi次に、stable-diffusion-webuiをインストールしたフォルダ直下に、自作プログラム用のフォルダとファイルを生成します。本サンプルでは「myapp/myapp.py」とします。
下記のプログラムをmyapp.pyに記述し、VSCodeのTerminal内で実行します。するとStable Diffusion WebUIを実行しているTerminalでゲージが動き出し、10秒ほどするとカレントフォルダにtest.pngができていることが確認できます。
1. import webuiapi
2. api = webuiapi.WebUIApi()
3. PROMPT="masterpiece, best quality, 1girl, face, simple white background"
4. result1 = api.txt2img(prompt=PROMPT)
5. result1.image.save("test.png")プログラムの解説です。
2行目:APIを呼び出すクラスWebUIApiのインスタンスを作成しています。ホストやポートがデフォルトの値ではない場合はここで指定します。
4行目:APIを呼び出している箇所です。引数はpromptただ一つです。この関数の戻り値のimageメンバはPIL Image型なのでPillowの関数が普通に呼べます。
5行目:Pillowのsave関数でファイルに保存しています。
画像の生成と保存の確認ができたら徐々に引数を増やしていきましょう。次はnegative_promptです。
1. from pprint import pprint
2. import webuiapi
3. api = webuiapi.WebUIApi()
4. PROMPT="""
5. masterpiece, best quality, 1girl, face, simple white background
6. """.strip()
7. NEGATIVE_PROMPT="""
8. easynegative
9. """.strip()
10. result1 = api.txt2img(prompt=PROMPT, negative_prompt=NEGATIVE_PROMPT)
11. result1.image.save("test.png")
12. pprint(result1.info)他にも、steps, width, height, seeds, restore_facesなどのオプションがありますので、VSCodeの補完機能を利用してお好みで追加します。スペルから想像される項目そのままの値を入れることができます。意図した設定で出力されているかどうかは12行目のログ出力を見て判断します。
次にControlNetのための引数を追加します。sdwebuiapiのドキュメントがControlNetの最新版の更新に追いついていないため、若干難易度が高いです。
1. from PIL import Image
2. import webuiapi
3. api = webuiapi.WebUIApi()
4. PROMPT="""
5. masterpiece, best quality, 1girl, face, simple white background
6. """.strip()
7. NEGATIVE_PROMPT="""
8. easynegative
9. """.strip()
10. controlnet_units = []
11. controlnet_image0 = Image.open("test.png") # PIL Image
12. controlnet_unit0 = webuiapi.ControlNetUnit(
13. input_image = controlnet_image0,
14. module = "mediapipe_face",
15. model = "control_v2p_sd15_mediapipe_face [9c7784a9]",
16. threshold_a=1,
17. threshold_b=0.5,
18. )
19. controlnet_units.append(controlnet_unit0)
20. result1 = api.txt2img(prompt=PROMPT, negative_prompt=NEGATIVE_PROMPT, controlnet_units=controlnet_units)
21. result1.image.save("test2.png")ControlNetの設定は複数可能なため、txtimgの引数には配列型式でデータを渡します。
10行目:複数のControlNetオブジェクトのリスト用変数確保
11行目:ControlNetの入力に指定する画像をPIL Image型式でロード
12行目:ControlNet個別の設定をひとまとめにするクラスControlNetUnitのインスタンス化
13行目:ControlNetで参照する入力画像(PIL Image型式)
14行目:プリプロセッサ名
15行目:Model名
16行目:プリプロセッサの個別設定1(mediapipe_faceの場合、顔を検出する最大数)
17行目:プリプロセッサの個別設定2(mediapipe_faceの場合、顔を有効だと判定するしきい値)
19行目:リストに追加
20行目:controlnet_units引数にリストを指定
上記サンプルでは1つのControlNetを指定していますが、動作確認ができたら12~19行目を複数定義することで、意図した動作になります。たとえばreference_onlyとnormal_baeなど。reference系のような、プリプロセスのみのControlNetはmodel引数を省略します。openposeやscribbleで使われるような、すでにプリプロセス済みの画像がある場合は、module引数を省略します。
ControlNetUnitクラスにはブラウザで指定するのと同じ名前のweightやresize_modeと、ブラウザ上には出てくるがその名前のメンバがいないものがあります。プリプロセッサ固有の設定はthreshold_a, threshold_bメンバに値を指定します。2023年5月にできたばかりのreference系のStyle Fidelityは、ControlNetUnitクラスのthreshold_aメンバが該当します。threshold_a,bは未指定時のデフォルトが64ですが、fidelityは0~1の間でなければならないため、threshold_a,bにはほぼ必ず値を指定する必要があります。
Webカメラの画像をControlNetに指定
次はWebカメラの画像をOpenCVのVideoCaptureで読み込み、その画像をControlNetの入力画像(PIL Image型式)に指定して、画像を出力します。
1 import cv2
2 import numpy as np
3 from PIL import Image
4 from pprint import pprint
5 import webuiapi
6
7 cap = cv2.VideoCapture(0)
8 while cap.isOpened():
9 ret, frame = cap.read()
10 if ret:
11 break
12 cap.release()
13 input_image = np.fliplr(frame)[:, :, ::-1] # flip & BGR=>RGB
14
15 api = webuiapi.WebUIApi()
16 PROMPT="""
17 masterpiece, best quality, 1girl, face, simple white background
18 """.strip()
19 NEGATIVE_PROMPT="""
20 easynegative
21 """.strip()
22 controlnet_units = []
23 controlnet_image0 = Image.fromarray(input_image)
24 controlnet_unit0 = webuiapi.ControlNetUnit(
25 input_image = controlnet_image0,
26 module = "mediapipe_face",
27 model = "control_v2p_sd15_mediapipe_face [9c7784a9]",
28 threshold_a=1,
29 threshold_b=0.5,
30 )
31 controlnet_units.append(controlnet_unit0)
32 result1 = api.txt2img(prompt=PROMPT, negative_prompt=NEGATIVE_PROMPT, contro lnet_units=controlnet_units)
33 controlnet_image0.save("test3_input.png")
34 result1.image.save("test3_output.png")
35 result1.images[1].save("test3_output_controlnet0.png")
36 pprint(result1.info)13行目:OpenCV型式の画像はBGR型式でピクセルが並んでいるため、RGBに変換します。また、インカメラの場合は動作確認しやすいように左右反転し、鏡面画像を元に進めます。
23行目:OpenCV型式の画像をPIL Image型式の画像に変換します。
下図のように画像が生成されます。左から「カメラに写った画像」「mediapipe_faceプリプロセッサで生成された顔の輪郭画像」「Stable Diffusionで新たに生成された画像」です。

ここまでで、Webカメラで取得した画像を元にStable Diffusionで画像を生成することができました。
Webカメラの画像取得と画像生成をループ処理
最後にWebカメラの画像取得と画像生成をループ処理させます。
1 import cv2
2 import numpy as np
3 from PIL import Image, ImageTk
4 from pprint import pprint
5 import threading
6 import tkinter as tk
7 import webuiapi
8 import mediapipe as mp
9 import os
10 import sys
11 sys.path.append(os.path.dirname(os.path.dirname(__file__)) + "/extensions/sd-webui-controlnet/annotator/m ediapipe_face")
12 import mediapipe_face_common
13
14 SIZE = 256
15 SEED = 12345
16 PROMPT="""
17 masterpiece, best quality, 1girl, face, simple white background
18 """.strip()
19 NEGATIVE_PROMPT="""
20 """.strip()
21
22 def draw_landmarks(
23 img_rgb,
24 results,
25 ):
26 empty = np.zeros_like(img_rgb)
27 if results is not None:
28 for face_landmarks in results:
29 mediapipe_face_common.mp_drawing.draw_landmarks(
30 empty,
31 face_landmarks,
32 connections=mediapipe_face_common.face_connection_spec.keys(),
33 landmark_drawing_spec=None,
34 connection_drawing_spec=mediapipe_face_common.face_connection_spec
35 )
36 mediapipe_face_common.draw_pupils(empty, face_landmarks, mediapipe_face_common.iris_landmark_ spec, 2)
37 return empty
38
39 class App:
40 def __init__(self):
41 self.cap = cv2.VideoCapture(0)
42 self.api = webuiapi.WebUIApi()
43 pprint(self.api.get_samplers())
44 pprint(self.api.controlnet_model_list())
45 pprint(self.api.controlnet_module_list())
46 options = {}
47 options['CLIP_stop_at_last_layers'] = 1
48 self.api.set_options(options)
49 self.controlnet_image1 = Image.open("test.png")
50 self.create_window()
51 self.facemesh = mp.solutions.face_mesh.FaceMesh(
52 static_image_mode=False,
53 refine_landmarks=True,
54 min_detection_confidence=0.5,
55 )
56 self.processing = False
57 self.result = None
58 self.quit = False
59 self.delay = 15
60 self.update()
61 self.window.mainloop()
62 self.window.quit()
63 self.quit = True
64 self.thread.join()
65
66 def create_window(self):
67 self.window = tk.Tk()
68 self.frame_control = tk.Frame()
69 self.frame_control.pack(side = tk.BOTTOM)
70 tk.Label(self.frame_control, text = "steps").pack(side = tk.LEFT)
71 self.ui_steps = tk.IntVar(value=12)
72 tk.Spinbox(self.frame_control, textvariable = self.ui_steps, from_=0, to=20,
73 increment=1, width=5, justify = tk.CENTER).pack(side = tk.LEFT)
74 tk.Label(self.frame_control, text = "cfg_scale").pack(side = tk.LEFT)
75 self.ui_cfg_scale = tk.DoubleVar(value=7)
76 tk.Spinbox(self.frame_control, textvariable = self.ui_cfg_scale, from_=0, to=7,
77 increment=0.5, width=5, justify = tk.CENTER).pack(side = tk.LEFT)
78 tk.Label(self.frame_control, text = "fidelity").pack(side = tk.LEFT)
79 self.ui_threshold_a = tk.DoubleVar(value=0.5)
80 tk.Spinbox(self.frame_control, textvariable = self.ui_threshold_a, from_=0, to=1,
81 increment=0.1, width=5, justify = tk.CENTER).pack(side = tk.LEFT)
82 self.canvas1 = tk.Canvas(width=SIZE, height=SIZE)
83 self.canvas2 = tk.Canvas(width=SIZE, height=SIZE)
84 self.canvas3 = tk.Canvas(width=SIZE, height=SIZE)
85 self.canvas1.pack(side = tk.LEFT)
86 self.canvas2.pack(side = tk.LEFT)
87 self.canvas3.pack(side = tk.LEFT)
88
89 def update(self):
90 ret, frame = self.cap.read()
91 if ret:
92 input_image = np.fliplr(frame)[:, :, ::-1] # flip & BGR=>RGB
93 left = (640-320)//2+30
94 top = (480-320)//2
95 input_image = cv2.resize(input_image[top:top+256,left:left+256,:], (SIZE,SIZE))
96 detection_result = self.facemesh.process(input_image).multi_face_landmarks
97 self.preprocessed_image = draw_landmarks(input_image, detection_result)
98 self.controlnet_image0 = Image.fromarray(self.preprocessed_image)
99 self.photo_image = ImageTk.PhotoImage(image = self.controlnet_image0)
100 self.canvas1.create_image(0, 0, image=self.photo_image, anchor = tk.NW)
101 if self.result is not None:
102 self.result_images_0 = ImageTk.PhotoImage(image = self.result.images[0])
103 self.result_images_1 = ImageTk.PhotoImage(image = self.result.images[1])
104 self.canvas2.create_image(0, 0, image=self.result_images_0, anchor = tk.NW)
105 self.canvas3.create_image(0, 0, image=self.result_images_1, anchor = tk.NW)
106 if not self.processing:
107 self.processing = True
108 self.thread = threading.Thread(target=self.txt2img)
109 self.thread.start()
110
111 if not self.quit:
112 self.window.after(self.delay, self.update)
113
114 def txt2img(self):
115 controlnet_units = []
116 controlnet_unit0 = webuiapi.ControlNetUnit(
117 input_image = self.controlnet_image0,
118 model = "control_v2p_sd15_mediapipe_face [9c7784a9]",
119 threshold_a=1,
120 threshold_b=0.5,
121 processor_res = SIZE,
122 )
123 controlnet_units.append(controlnet_unit0)
124 controlnet_unit1 = webuiapi.ControlNetUnit(
125 input_image = self.controlnet_image1,
126 module = "reference_only",
127 threshold_a=self.ui_threshold_a.get(),
128 threshold_b=0,
129 processor_res = SIZE,
130 )
131 controlnet_units.append(controlnet_unit1)
132 self.result = self.api.txt2img(
133 prompt=PROMPT,
134 negative_prompt=NEGATIVE_PROMPT,
135 seed=SEED,
136 steps=self.ui_steps.get(),
137 cfg_scale=self.ui_cfg_scale.get(),
138 width=SIZE, height=SIZE,
139 sampler_name = 'Euler',
140 controlnet_units=controlnet_units)
141 pprint(self.result.info)
142 self.processing = False
143
144 App()サンプルとしてはやや長いですが、半分を占めているUI関連のコードは読み飛ばしてください。
まず、リアルタイム処理の重要なコツを7つご紹介します。
1つ目のコツは、mediapipeをビデオ認識モードで動作させることです。ControlNetに付属しているmediapipe_face_commonは1枚の静止画の中から顔を検出させる前提の処理をしていますが、ビデオ映像の場合は直前に認識した状態と近い位置・大きさ・角度で同じ顔がいる可能性が高いため、静止画認識モードをオフにすることで顔検出が速くなり安定します。52行目のstatic_image_mode=Falseがそれに該当します。
2つ目のコツは、プリプロセスをStable Diffusionの処理と別スレッドにすることです。これにより、画像生成の時間がコンマ数秒短縮されます。
3つ目のコツは、ステップ数の削減です。一般的にはステップ数は20~30が使われますが、画像生成の処理時間はステップ数にほぼ比例するので、このステップ数をいかに小さくするかが重要になります。モデル次第では12で安定するものもありますし、顔に特化すれば7で安定する場合もあります。(136行目)
4つ目のコツは、出力解像度です。解像度を標準の512ではなく256にすると、一目でわかるくらい速くなります。それより小さくするとStable Diffusionの仕組み上、画像が破綻します。(14行目、121行目、138行目)
5つ目のコツは、LORA、Texual Inversion、VAEを使わないことです。これらは画質向上には役に立ちますが、速度が遅くなります。できるならばCheckpointにまとめましょう。
6つ目のコツは、ControlNetの件数を減らすことです。これは5つ目のコツと同じことですが、追加の処理を増やすごとに計算量が増えて、速度が遅くなります。reference_onlyを使うと顔・髪型が安定するため使いたくなりますが、フレームレートが犠牲になります。
7つ目のコツは、顔を小さくしすぎないことです。画像全体に対しての顔の面積を大きくとると処理が速くなります。(95行目)
結論としては、顔画像(ポートレート画像)に特化した学習済みモデルを使用し、LORAを使用せず、小さいサイズの画像を生成すれば、少ないステップ数でほどほどの速さになります。
最後に僕が撮影したサンプル動画をお見せしましょう。左がWebカメラの映像をMediaPipeで顔検出し、輪郭をリアルタイム描画したもの。中央がStable Diffusionの出力。右はStable DiffusionがControlNetに利用した輪郭画像です。左の画像は30FPSで更新していますが、中央の画像は0.5~1FPSです。計算速度が追いついていないことがよくわかります。使っているGPUはRTX3060 Laptopです。GPU使用率が100%になってないので、チューニングする余地がありそうです。
まとめ
Stable Diffusion WebUIのAPI機能を使って、Webカメラに写っている映像と同じポーズをした画像を生成し、リアルタイムに表示するサンプルをご紹介しました。リアルタイムとは言っても、画像1枚を生成するのに1~2秒かかるため、まったく動画には見えませんが、それは時代がすぐに追いつくでしょう。本記事執筆中に、TensorRTを使うとStable Diffusionが2倍速くなる、というようなニュースも入ってきました。来年の今頃にはこのプログラムで動画っぽくなっていると期待しています。もしくはまったく別の方法で画像を生成する方法も出ていることでしょう。本記事よりもっと速度の出る方法が見つかったらぜひ教えてください。コメントやご質問をお待ちしています。