高火力 PHY H100プランの8ノードで叶うこと


株式会社フィックスターズでパフォーマンスエンジニアリングラボ長を務めている吉藤です。今回フィックスターズでは、さくらインターネットと共同で「高火力 PHY H100プラン」の8ノードを使って、その実力を検証してみました。
TL;DR:
- 高火力 PHYのOS初期化からAI用環境構築までをすべて自動化できることを示しました
- 学習処理において、費用対効果が約2倍という結果を得ました
- 推論処理において、巨大モデル(480B)の巨大長(1Mトークン)が動作し、既存の推論APIサービスより費用対効果が3倍であるという結果を得ました
背景
さくらインターネット様とは、以前にH200の性能検証を実施し、「H100の2.5倍高速化」という結果を得ることに成功しています。この結果と詳細な内容は、プレスリリースやホワイトペーパーとして公開しています。このときは、新しいハードウェアに置き換えた時にパフォーマンスエンジニアリングを行うことで、その性能をさらに引き出す具体的な手法を解説しました。
一方、同機種であってもノード増設時も、パフォーマンスエンジニアリングを実施する絶好の機会です。ノードが増えることで、性能特性には次のような変化が起こります。
- 合計性能が増える:単純に2倍のノード数を用意すれば、演算性能もメモリ容量もすべて2倍になります。
- オーバーヘッドが増える:協調動作するノードが増えるので、同期して通信するために時間がかかるようになります。
前者により、大きなモデルを動かしたり処理時間が単純に減るというメリットが得られます。一方で後者の影響により、そのまま単純に2倍のノード数で2倍の実効性能が出ることはほとんどありません。これは演算と通信の比が変化するためで、ノード数Nに対して演算性能はO(N)で増えますが、通信コストはO(N log N)で増えることに起因します。
そこで今回は、H100を8ノード使い、複数ノードの実力を引き出すためのパフォーマンスエンジニアリングを実施してみました。
パフォーマンスエンジニアリングを始める前に:AI処理用の環境構築の自動化
検証に先立ち、まず環境構築の自動化に着手しました。環境構築を自動化することで、システムレベルでのパフォーマンスエンジニアリングを繰り返し試せるようにするためです。こうしたことができるのも、高火力 PHYのベアメタルサーバーならではです。
フィックスターズではAIBoosterというパフォーマンスエンジニアリングプラットフォームを提供しています。ツールやソフトウェアではなく”プラットフォーム”として提供している中には、「AI処理のパフォーマンスが最大化される環境」の構築支援も含まれているのですが、これまでは手順書とスクリプトによる半自動化の形で提供していました。このような提供の仕方をしていたのは、元々ユーザー自身が環境構築を実行できるようにと考えていたためです。重要な変更については、ユーザー自身に実行内容を理解してもらい、目視確認の上で実行してもらうことを意図していました。しかし、高火力 PHYを熟知しているフィックスターズが環境構築を実行するのであれば、全自動にするほうが効率的です。
そして今回、8ノードという、手動ではやや手間のかかる台数を環境構築する機会に恵まれたため、自動化の検証もしてみました。
自動化の際にはいくつかの方法を検討したのですが、結果的にAnsibleを使うこととしました。Ansibleの他にも、bashスクリプトを書く方法から、k8sまで、さまざまな方法を検討したのですが、大鉈を振るいすぎず今後の保守性・拡張性が悪くないというちょうど良い塩梅を考えています。また最近ではAI補助(いわゆるバイブコーディング)に対応していることも必須になるため、社内利用可能なLLMにとってどのツールが一番得意かという視点も加えた結果、Ansibleが妥当ということにしました。今回のAnsibleによる自動化では、ひとまず手順書からの移植を優先させたため、今後、テストなどを充実させつつ、再現性の高い、より洗練された自動化を目指していきます。
この自動化によって、主に以下のような環境構築が完全に自動化されました。
- 高火力 PHYのOS初期化(再インストール)
- 再インストール後の電源投入
- ssh, ufwなどのセキュリティ設定
- 非OS用ストレージ(NVMeの4枚)の設定、特に複数ノード時の分散共有ストレージ化
- GPU動作用ソフトウェア(ドライバ・CUDA・ACS無効化等)のインストールと動作確認
- 標準的なHPC用ソフトウェア(MPI・NVIDIA Container Toolkit・Singularity等)のインストールと動作確認
- インターコネクトの接続設定および動作確認
これにより、ノード数にかかわらず2時間程度で初期化&環境再構築の作業が完了するようになりました。
今回の検証では、システムレベルのパフォーマンスエンジニアリングを試す時間がなくなってしまったので、この自動化Ansibleを繰り返し実行する機会はありませんでした。ただ、この自動化の成果はFixstars AIBoosterの機能(infra)に取り込まれました。つまり、これから高火力 PHYをご利用になる方は、AIBoosterの本機能をご利用いただくことで、コマンドひとつでAI用の環境を立ち上げられるようになりました!
実践1:学習で2倍の費用対効果
パフォーマンスエンジニアリングの最初の課題として、以前にH100、H200の検証の際にも用いた「Llama3 70Bの継続事前学習」を用います。
過去に行ったH100×2ノードでの検証では、以下の設定でなんとか学習が実行可能という状況でした。
- 学習中に1度に処理するサンプルは1つだけ:マイクロバッチサイズ(MBS)=1
- 70Bのモデルを16GPU全部で分割並列実行する:テンソル並列(TP)=8、パイプライン並列(PP)=2、データ並列(DP)=1
- 演算器幅を16bitだけで計算する:BF16
- すべての活性値を保存せず再計算する:recompute-granularity=full
- メモリ消費量の少ない最適化器(optimizer)を使う:SGD-SaI
H100からH200へ、新機種への乗り換え時には、H200で増えたメモリ容量を使ってこれらの値を改善するパフォーマンスエンジニアリングを実施しました。その詳細はホワイトペーパーで公開しています。
今回は同機種でノード数が増えることになるので、別の施策が必要になります。そこで以下のような3段階でパフォーマンスエンジニアリングを実施しました。
- グローバルバッチサイズの検討:ハードウェアリソースの使用効率の観点から、増えたノード数に見合う負荷をかけるのが望ましいため、16から256に増やしました
- マイクロバッチサイズと三次元並列の傾向調査:ノードが増えて選択肢の幅が広がったため、検討しました
- ハイパーパラメーター自動チューニング:上記1,2を最終的には自動探索し、最終的な性能を検証しました
これらのパフォーマンスエンジニアリングを経て、最終的な性能として606[TFLOP/s/GPU]を得ることができました。これは2ノードの時と比較しておよそ2倍の性能です。
以下では1つずつ解説します。
1. グローバルバッチサイズの検討
グローバルバッチサイズ(Global batch size; GBS)とは、「1回のパラメーター更新(イテレーション)に使うサンプルの合計数」です。
一般的に、AI学習におけるパフォーマンスエンジニアリングの観点からは、グローバルバッチサイズの変化は以下のような影響があります。
- 小さくすると、1イテレーションにかかる時間は短くなる
- 大きくすると、学習が安定する(発散しにくくなる)
- 大きくすると、ハードウェアの利用効率(演算時間比率や演算スループット)は向上する
- 利用できるノード数(データ並列の数)は、グローバルバッチサイズが上限となる
- 1イテレーションでのモデル改善効果=損失(loss)の減少量が変化する
以前は、グローバルバッチサイズは16に設定していました。これは以前の環境は2ノード=16GPUであったため、最大でもDP=16という理由で設定された値でした。
※実際には2ノードではDP=1か2しか実行できませんでした。
今回、8ノード=64GPUという環境になったので、このままのグローバルバッチサイズ16ではあまり効率が良くないことが懸念されました。そこで各パフォーマンスエンジニアリングを実施する前に、グローバルバッチサイズの適切な値を判断するため、実験を行いました。
実験では単純にグローバルバッチサイズを8から4096まで変化させた時の各種計測値を見てみます。なお、本来であればグローバルバッチサイズが変わるのであれば学習率なども総合的に調整する必要がありますが、今回はパフォーマンスエンジニアリングが主目的であるのでいったん同じ値としています。また、パフォーマンスエンジニアリングを実施する前の予備実験であるので速度に関する設定は以下のように固定しています。
- マイクロバッチサイズ:4
- テンソル並列:8
- パイプライン並列:8
- データ並列:1
- 演算器幅:fp8
- 再計算:なし
まず精度面を検証するため、損失曲線がどうなるかを見てみました。
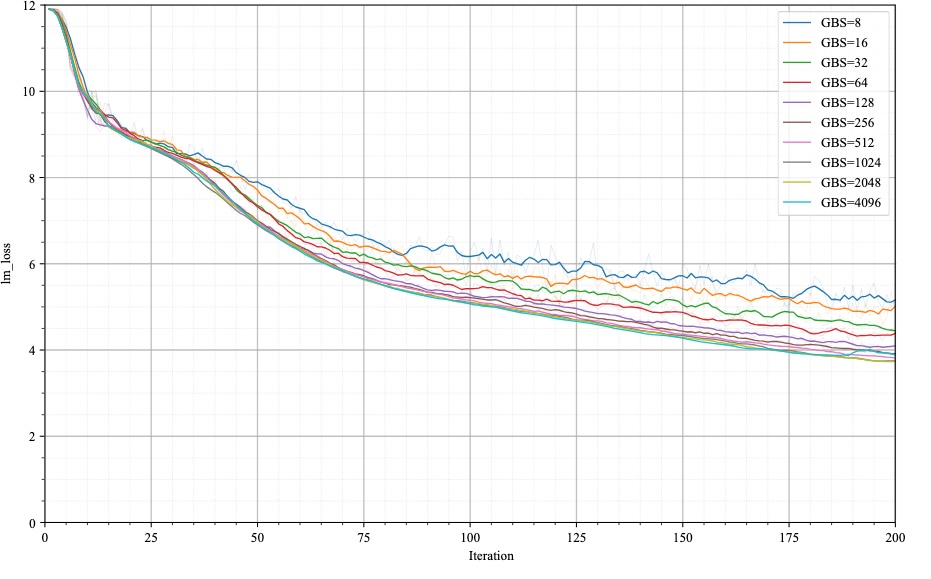
このグラフからは以下の結果が読み取れます。
- グローバルバッチサイズが大きいほうが、同じイテレーションの学習をした時に良い(=損失の小さい)モデルとなる
- ただし改善効果には頭打ちがあり、概ね256(グラフ上の茶線)以上では同程度に近い
これにより、256より大きなサイズにすることにしました。では大きければ大きいほうが良いでしょうか? これを確かめるには「1イテレーションのコスト(≒所要時間)」も勘案してみる必要があります。
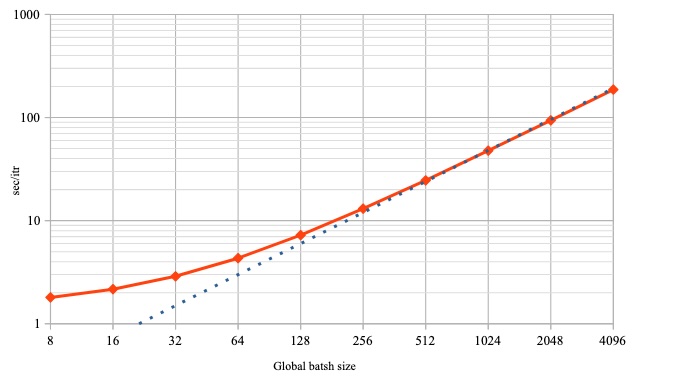
この通り、256以上においては、グローバルバッチサイズを2倍にすると所要時間も2倍に伸びてしまっています(青点線に乗っている)。
以上の2点を総合すると、
- グローバルバッチサイズは大きいほうが精度に優れる
- ただし、2倍のコストをかけても精度が2倍になるわけではない
- よって、大きくしすぎるとコスト効率が低下する
という傾向が読み取れました。そのため今回はグローバルバッチサイズに256という値を採用し、以降のパフォーマンスエンジニアリングに利用しました。
再注:今回はあくまでパフォーマンスエンジニアリングの一例に使うためなので、グローバルバッチサイズの検討は簡易的な実施に留めました。実際に学習を行う際は、先述の通り学習率などを含む広範な検討を行なって決定する必要があります。
2. マイクロバッチサイズと三次元並列の傾向調査
H200の性能検証の際にはマイクロバッチサイズと三次元並列の値によって性能が大きく変化し、最終的にMBSは最大にして、三次元並列はH100の時と同じものを採用しました。
今回はノード数が増えたことで、この点について変化があるという予想があり、改めていくつかの設定を試してみました。
実験条件はグローバルバッチサイズの検討と同じですが、グローバルバッチサイズは256に固定し、代わりに、マイクロバッチサイズ(MBS)、テンソル並列(TP)、パイプライン並列(PP)を変化させた時の演算スループット[TFLOP/s/GPU]を計測しました。なお、データ並列(DP)については、GPU枚数=TP×PP×DPから逆算して自動算出されていることにご注意ください。
結果をクロス集計すると下記のようになりました。
TP=4:
| PP\MBS | 1 | 2 | 4 |
|---|---|---|---|
| 2 | OoM | OoM | OoM |
| 4 | 550.4 | OoM | OoM |
| 8 | 463.1 | 593.0 | OoM |
TP=8:
| PP\MBS | 1 | 2 | 4 |
|---|---|---|---|
| 2 | 322.1 | 509.9 | OoM |
| 4 | 311.4 | 539.4 | 565.9 |
| 8 | 238.8 | 450.0 | 534.0 |
この表においては、最速の上位3つを抽出すると以下のようになっています。
| 順位 | TP | PP | DP | MBS | 演算スループット[TFLOP/s/GPU] |
|---|---|---|---|---|---|
| 1 | 4 | 8 | 2 | 2 | 593.0 |
| 2 | 8 | 4 | 2 | 4 | 565.9 |
| 3 | 4 | 4 | 4 | 1 | 550.0 |
これらの結果から読み取れる傾向は以下の通りです。
- H200の時とは傾向が変わり、TP, PPを減らす代わりにDPを2に上げるという方針が取られています
- 2ノードの時にはDPを増やす余裕がなかったことから、DPを増やすのは困難でした。今回ノード数が増えた恩恵でDPを増やすことができました
- ただし無理やりDPをたくさん増やして(クロス集計の同列上段)も、OoMになったり性能が出ないため、適度な値(DP=2)にすることが重要のようです
- 原理的には、同条件ならDPが多いほうが良いはずなのですが、そのようになっていないので、その理由は次の機会に調査したいと思います
- TPとPPを比べると、TPを減らしてPPを増やす方が高速でした
- 速い順に並べた表を見るとTP,PP=4,8の方がTP,PP=8,4より高速でした。
- これはちょっと予想外でした。なぜなら、TP=8までであればノード内で完結するのであまりオーバーヘッドがないはずで、逆に無理にPPを増やすとパイプラインバブルが起きやすいはずだからです。
- もしかするとプロセスのノード/GPU割当にチューニングの余地があるかもしれません(今はMegatron-LMにおまかせ)。次の機会にはそのあたりを確認してみたいと思います。
ということで、2ノードの時とやはり違う傾向が見られました。総じて「何かに極端に振るよりは、すべてを平均的に高くする」という設定で、8ノードでは高速になる傾向にあったようです。
3. ハイパーパラメーター自動チューニング
前節では「他の条件を固定した中で、グリッドサーチをした」という結果でした。しかしMegatron-LMで速度に関するハイパーパラメーターは他にもあります。そこで今回は「もっと良い組み合わせがあるかもしれない」という目論見で、以下のパラメーターチューニングを試みました。
- 演算器幅:fp8の方が高速ですが、bf16の方がメモリ消費量は少ない
- マイクロバッチサイズ(MBS):大きいほうが効率は良いがメモリ消費量が増える
- テンソル並列数(TP):小さいほうがオーバーヘッドは少ないがメモリ消費量が増える
- パイプライン並列数(PP):小さいほうがオーバーヘッドは少ないがメモリ消費量が増える
- データ並列数(DP):※先述の通りこれはTPとPPによって自動的に決まるので自由パラメーターではありません
- 活性値再計算の粒度(recompute_granularity):None(再計算しない)、selective(注意機構のコア部分のみ)、full(すべて)
- 活性値再計算の分割方法(recompute_method):None(再計算しない)、uniform(全層を均等に)、block(最後の後ろの方だけ)
- 活性値再計算の層数(recompute_num_layers):
- uniformの場合は「何層ごとの塊を再計算するか」
- blockの場合は「後ろの何層を再計算するか」
- キャッシュメモリの解放頻度(empty_unused_memory_level):0(全く解放しない)、1(低頻度)、2(高頻度)
ただし、これらすべてのパラメーターをグリッドサーチするには探索空間が広すぎて現実的ではありません。そこでAIBoosterの自動チューナーを使った結果、以下のような結果を得ることができました。
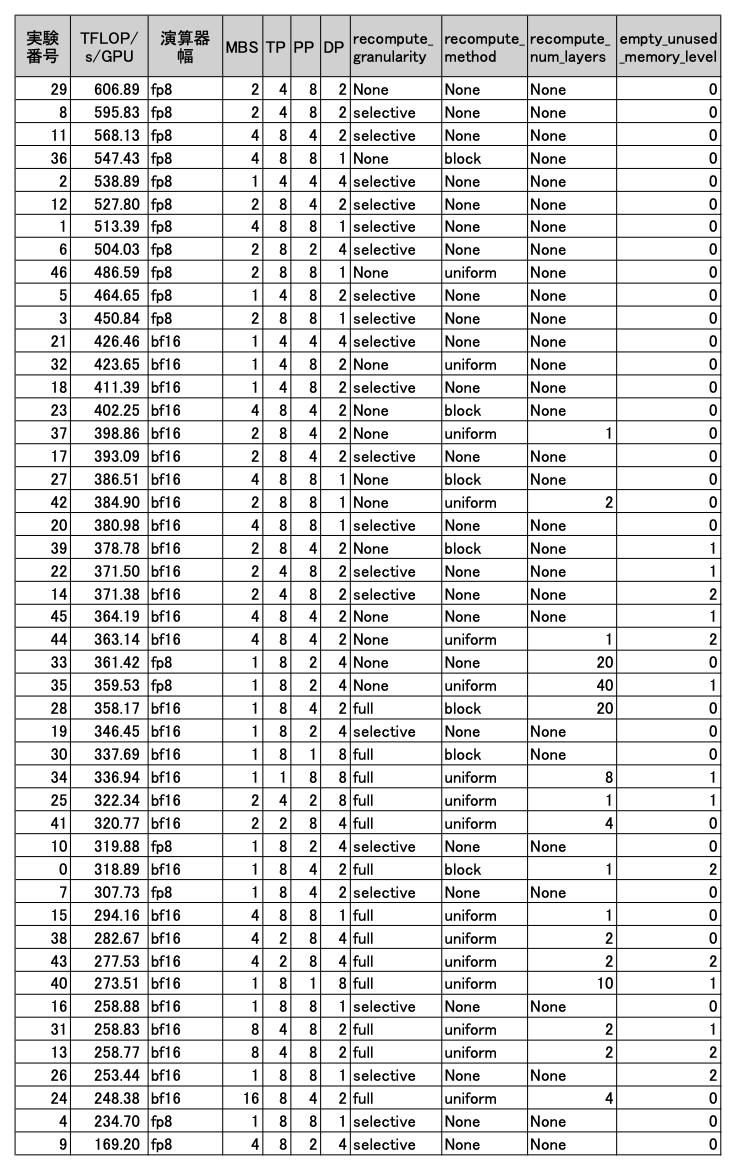
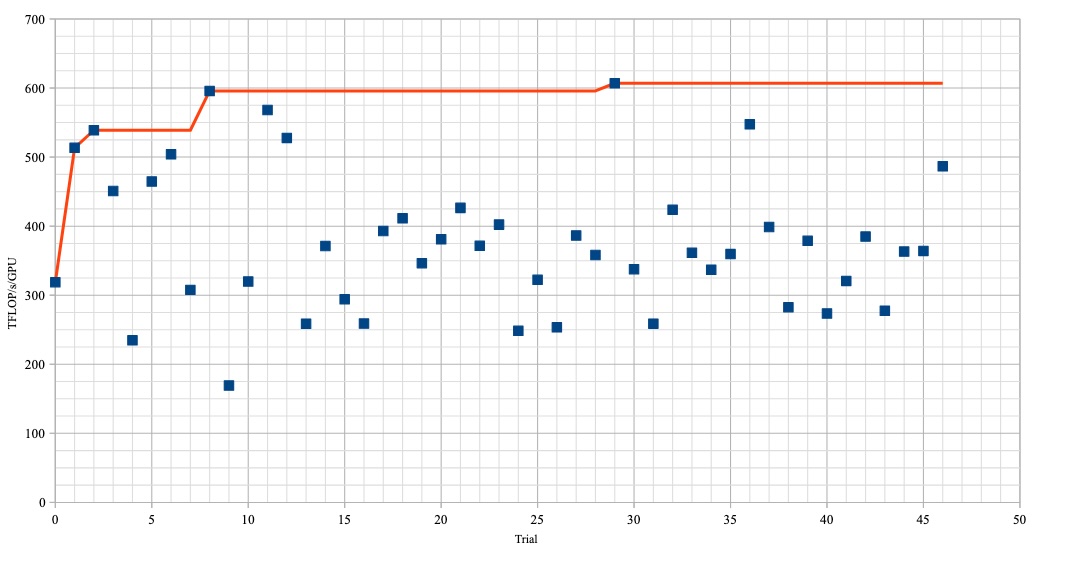
このように、最高で607[TFLOP/s/GPU]という結果を得ました。
この結果からわかる各パラメーターの特性は以下のようなものでした。
- 演算スループット[TFLOP/s/GPU]は、多くの場合300-400あたりにあり、最高値に近い値はごく狭い範囲でのみ得られる。つまり「ハイパーパラメーターを適当に設定してしまうと、大体悪いところになってしまう可能性が高い」ことを示唆しており、ピンポイントでパラメーターを決めなければ良い性能が得られないということを意味していそうです。
- 上位にfp8が固まっていますので、やはり概ね8bitにしたほうが良さそうです。ただし下手な8bitよりしっかり設定した16bitの方が速いこともあります。
- マイクロバッチサイズ・三次元並列については、前節で述べた通り「どれかを極端に振る」のではなく、それぞれちょうど良い塩梅のバランスの取れた値にすることが良いようです。
- 活性値再計算は可能な限り控えたほうが良さそうです。
- 特に、下位のほうを見ると、fullが固まっています。fullにすることで、MBSが16(24番)だったりDPが8(40番)にできたりと極端な値を取れていますが、性能が低いためこの選択肢はあまり取らない方が良いようです。
- キャッシュ解放は「しない」方が上位に固まっているので、しなくて済むならやはりしないほうが良さそうです。
- ただし探索の様子を見ていると、どうやら自動チューナーが「それほど性能に大きく影響しない」と判断したようで、そもそも1や2を設定している実験が少ないです。影響を調査するには、これだけを自由パラメーターとして影響を追加検証する事が必要そうで、今後の課題としたいと思います。
総じて予想通りの結果を得られており、従来の知見通りに設定すれば良いですが、高性能が出る範囲は狭いのでチューニングと検証を頑張る必要はありそうです。
2ノードとの比較
最後に、以前行った2ノードによる結果と比較してみます。
自動チューニング時の初期値(実験番号0)は、2ノードの時の設定になるべく近いものにしており、この値は319[TFLOP/s/GPU]だったことが分かります。一方、今回は最高で607[TFLOP/s/GPU]という値を得られたことから、演算スループットはおよそ1.9倍速になったと言えます。
この数字は1GPUあたりの性能ですから、ノード数も4倍に増えていることを考えると、4倍のノード(コスト)で、約8倍の高速化を得られたということになります。費用対効果で約2倍と言い換えても良いでしょう。
改めて2ノードと8ノードの設定値を並べると以下のような変化が見られます。
| パラメーター | 2ノード(実験番号0) | 8ノード(実験番号29) |
|---|---|---|
| 演算スループット[TFLOP/s/GPU] | 319 | 607 |
| 演算器幅 | bf16 | fp8 |
| マイクロバッチサイズ | 1 | 2 |
| テンソル並列数 | 8 | 4 |
| パイプライン並列数 | 4 | 8 |
| データ並列数 | 2 | 2 |
| 活性値再計算 | 最後の1層は再計算 | 全く再計算しない |
| キャッシュ解放頻度 | 高頻度 | 全く解放しない |
- まず、16bitから8bitに変更することができました。高速な演算器を使うことができるため、処理性能は有利になりました。
- 精度面の変化はほとんどないことの確認はH200の記事をご覧ください。
- マイクロバッチサイズは2倍にできました。これによりGPUが一度に処理できる数が多くなったため、処理性能は有利になりました。
- 三次元並列については、1つ前の実験の通りやはりTPよりPPを優先するほうが高速なようです。これまでの知見とは少しずれているので、原因究明は今後の課題です。
- 活性値再計算は、実行しなくて良くなったので、処理性能の向上につながったようです。
- キャッシュ解放もまったくせずによくなったので、これも処理性能の向上につながったようです。
ノード数をN倍に増やした時、チューニングをしないままなら性能もN倍止まりになるところですが、パフォーマンスエンジニアリングを施すことで、費用対効果を大きく向上させることができる実例となりました。
実践2:巨大推論で3倍の費用対効果
今日現在、LLMの推論能力は、他の条件が同じであれば、
- パラメーター数が大きい方が精度が良い
- 処理可能なトークン数が大きいほうが便利に使える
と言われています。そこで現時点で最大級である480Bパラメーターのモデルの1Mトークン推論に挑戦してみました。
今回対象にしたのは、Qwen3-Coder-480B-A35B-Instructです。このモデルはQwen社が開発し公開しているコーディング用LLMで、他のLLMに比べて高い性能が出ていることで知られています。特徴は、エージェント的に動作させられることと、長い処理トークン数です。特に処理トークン数については、基本的には260KトークンですがYarnに対応しており、1000K=1Mトークンに対応しています。
今回、このような条件、つまり「480Bのモデルの1Mトークン推論」を、vLLMを使うことで4ノードで動作することを確認しました。またこの時、推論スループット(出力トークンの生成速度)は30[token/s]となりました。
そもそもこのようなサイズと長さの推論というのは、他ではあまり例のない大きさです。しかし、大きさと長さは直接的に精度と利便性に影響を与えるパラメーターでもあります。
このような巨大推論を使うことで、現実のタスクがどのように、どれぐらい良くなっていくのかは、今後このモデルが世の中で使われていくことで明らかになっていくことと思います。近年のモデルサイズの巨大化傾向は止まる様子がないので、今後数年間のLLM利用を考えた時、このような最先端のモデルを動かすことができたのは、重要なマイルストーンの達成と言えるでしょう。
今回は動作させたところで時間切れになってしまい、この推論をパフォーマンスエンジニアリングでさらに高速化することはできませんでした。これは次の機会があれば試してみたいと思います。
既存APIとの比較
これを既存の結果と比べてみましょう。今回はLLMの推論APIを外部提供しているサービスと比較するためOpenRouterの表と比較してみることにします。
この表から、そもそも1Mトークン以上を提供している推論サービス・モデルは、ChatGPTやGeminiを除くと、2025年08月20日時点では以下の5つです。
また、これらを提供しているサービスのうち、GPUで提供していそうなサービスにだけ絞って推論スループットが最高値のものを抽出してみると、以下のような条件であることがわかりました。
| model | param | token | fastest provider | token/s | $/1M-input | $/1M-output |
|---|---|---|---|---|---|---|
| Llama 4 Maverick | 400B | 1.05M | GMI | 250 | 0.25 | 0.80 |
| Llama 4 Scout | 109B | 1.05M | Baseten | 132 | 0.13 | 0.80 |
| MiniMax-01 | 456B | 1.00M | Minimax | 26 | 0.20 | 1.10 |
| MiniMax M1 | 456B | 1.00M | Novita | 16 | 0.55 | 2.20 |
| Qwen-Turbo | *7B | 1.00M | Alibaba | 96 | 0.05 | 0.2 |
ここから、まず今回の480Bに近いパラメーター数を持つモデルがMiniMax系(456B)になることが分かります。この生成速度はそれぞれ16または26[token/s]ということなので、今回の成果である30[token/s]はこれに比べて同程度以上の性能になったことが分かります。
次に価格も考えてみます。まず、入出力の比率は9:1と仮定します。つまり、900Kトークンを入力し、100Kトークンを生成して出力するということです。これは、特にコーディング用途で「手元のプロジェクトのソースコードの全ファイルをそのまま入力トークンに入れて、それに対して指示応答する」ということを考えた時に、なるべく多くのファイルを入力したいという想定によるものです。
これをMiniMaxの価格でみると、1Mトークンの推論に$0.3か$0.7ぐらいかかることになります。対ドル150円換算で、日本円ではおおよそ1回の1Mトークン推論に50円から100円程度かかるということです。
ここで、仮にこのサービスを、フィックスターズが使ってみるとどうなるかシミュレーションしてみましょう。
- まず、MiniMax-01はマルチモーダルモデルなので純粋な言語モデルであるM1の方を考えると、1回の推論に100円かかるとします
- 次に、どれぐらいの頻度使うかを考えてみます。使い方など個人によるところが大きいのですが、一旦著者をモデルに考えてみると、日頃の業務でLLMを使う頻度が概ね10分に1回程度であることが記録上分かっています
- つまり著者は1時間あたり600円程度の推論をしていると考えてよいでしょう
- そして1ヶ月に1日8時間で20日稼働していると考えると、単純に月額で10万円程度を使うことになっています
- そしてフィックスターズには私のようなエンジニアが300人います。みんな同じ程度使うと考えると、もし仮にこのMiniMaxの推論サービスを使っていると、フィックスターズ全体で月額3000万円ぐらいを支払うことになりそうです
高火力 PHYの価格については、最初のプレスリリース時の価格を参考にすると、最安値で月額250万円/ノード程度でした。つまり4ノードだと月額1000万円ぐらいです。
ということは、シミュレーションの結果と比較すると、同じ性能のものを提供する時に、高火力 PHYの方が価格が1/3程度で済むということです。逆数で言えば、高火力 PHYでこの規模の推論をする場合、既存のAPI提供サービスと比較して「費用対効果が3倍良い」と言えるでしょう。
追加実験:fp8で2ノード動作
本実験の後、フィックスターズ社内で改めて2ノードで確認したところ、fp8に量子化されたモデルが2ノードで動作することを確認しました。生成速度は変わらず30[token/s]程度でした。生成速度が変わらないのは、ノード数が半分になった代わりに演算器幅も半分になって演算速度が倍になったことで、打ち消しあったのだと考えられます。
推論時には量子化の影響を大きく受けることがあるので精度評価は必要になりますが、もしfp8でも十分な精度が出るのであれば、実はこの動作には2ノードで十分で、その場合の費用対効果は6倍になります。
まとめ
今回、高火力 PHYのH100を8ノード使ってみることで、
- 学習時に2ノードに比べて費用対効果が2倍良くなったこと
- 巨大推論で既存サービスに比べて費用対効果が3倍良いこと
を確かめることができ、AI処理をより効率よく、高い費用対効果を得て実行できるという実例が示せました。
ただし、今後の課題とした未究明箇所も残る結果ではありました。まだまだパフォーマンスエンジニアリングの余地はありそうです。
フィックスターズではさくらインターネット様との共同研究開発などを通じて、引き続き、高火力 PHYの最大性能を引き出していきます。
(参考: さくらインターネットより) ホワイトペーパーのご紹介
さくらインターネットが提供している高火力シリーズ「PHY」「VRT」「DOK」を横断的に紹介する資料です。お客様の課題に合わせて最適なサービスを選んでいただけるよう、それぞれのサービスの特色の紹介や、比較表を掲載しています。

