AIスパコン「さくらONE」で挑むLLM・HPCベンチマーク (2) MLPerf GPT-3 175B事前学習性能検証


さくらインターネット研究所の坪内(@yuuk1t)です。
本連載では、AIスパコン「さくらONE」で実施した各種ベンチマーク結果をご紹介しています。前回の第1回の記事では、MLPerfベンチマークの概要と、さくらONEにおけるMLPerf Llama 2 70B LoRAファインチューニングのベンチマーク結果を紹介しました。
AIスパコン「さくらONE」で挑むLLM・HPCベンチマーク (1) MLPerf Llama 2 70Bファインチューニング性能検証
第2回となる本稿では、分散学習とAIスパコンの基本概念を説明したのちに、さくらONEにおいて実施した、より大規模なタスクであるGPT-3 175Bモデルの事前学習(Pre-training)のベンチマーク結果を報告します。本記事は、2025年9月5日に開催された、Cloud Operator Days Tokyo 2025 Closing EventのKeynoteで発表した講演内容を大幅に加筆修正したものです。
AIスパコン「さくらONE」のLLM学習ベンチマークによる性能評価
目次
分散学習のワークロード
GPT-3のような大規模モデルの学習を高速に実行するには、複数のGPUを用いて、分散して並列処理する技術が必要です。ここでは、その基礎となる概念を整理します。
深層学習の処理の流れ
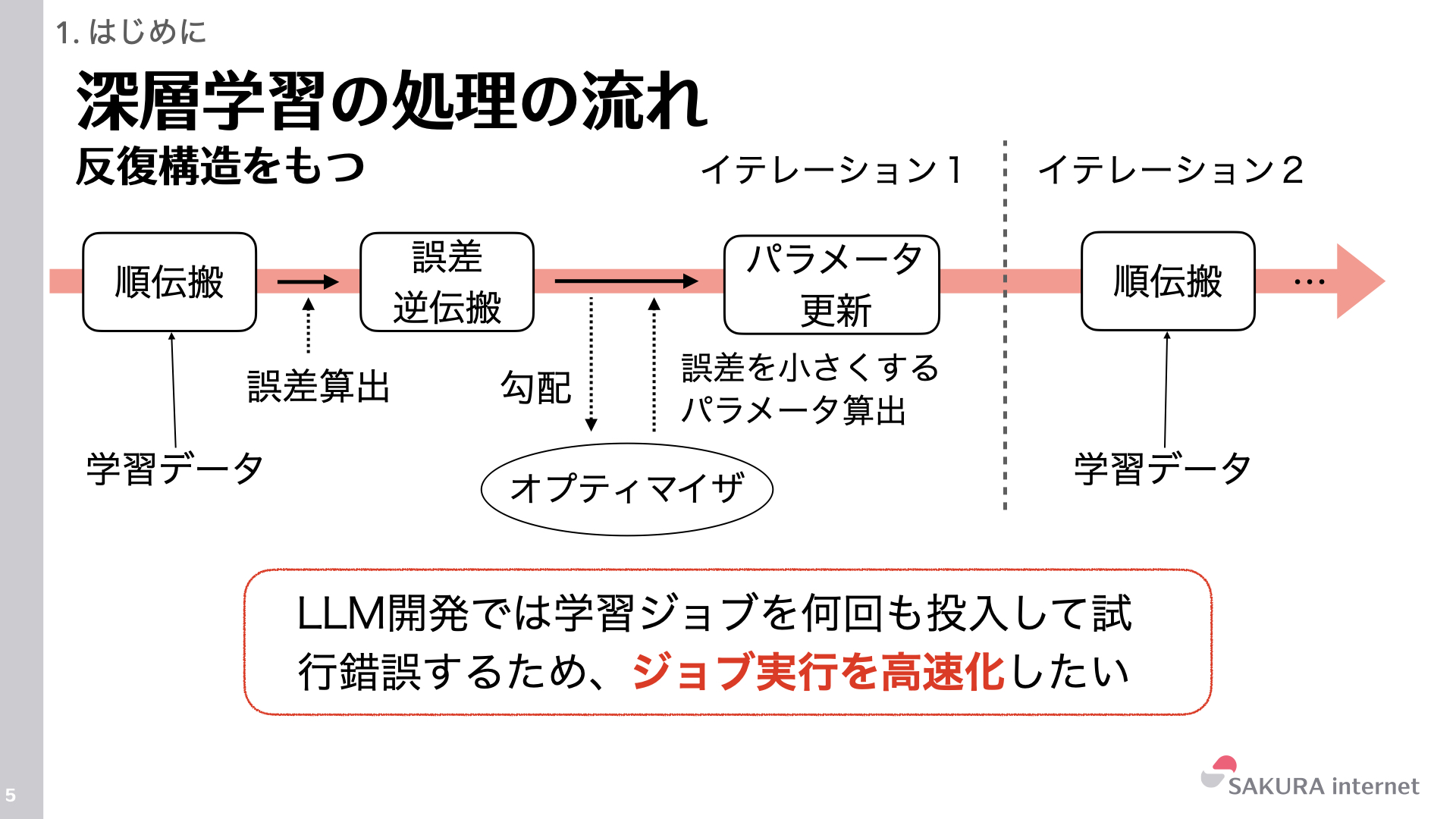
深層学習の学習プロセスは、以下の3つのステップを繰り返すことで進行します。
- 順伝搬 (Forward Propagation): 入力データ(ミニバッチ)をモデルに通して予測値を出力し、正解データとの誤差(Loss)を計算します。この際、逆伝搬での計算のために中間出力(Activations)をメモリに保存します。
- 誤差逆伝搬 (Backward Propagation): 計算された誤差と保存されたActivationsをもとに、モデルの各パラメータが誤差にどの程度影響したか(勾配)を逆向きに計算します。
- パラメータ更新 (Parameter Update): オプティマイザが勾配情報とオプティマイザ状態(Optimizer State)を使って、誤差を小さくする方向にモデルのパラメータ(重み)を更新します。
大規模言語モデル(LLM)の学習では、このサイクルをトークン数に依存して数万〜100万ステップ程度繰り返します。モデル開発では、このようなジョブを何度も試行錯誤するため、ジョブの実行速度が開発効率に直結します。ジョブの実行速度を高速化する手法は、様々な階層で様々な方法がこれまでに考案されています。
本記事では、GPUのようなAIアクセラレーターを複数個搭載したノードを複数個配置して、分散して並列処理する手法である分散学習を説明します。分散学習の主な並列化手法は、第1回の記事でも紹介されていますが、ここでは個々の並列化手法がなぜ必要なのかを説明します。
分散学習
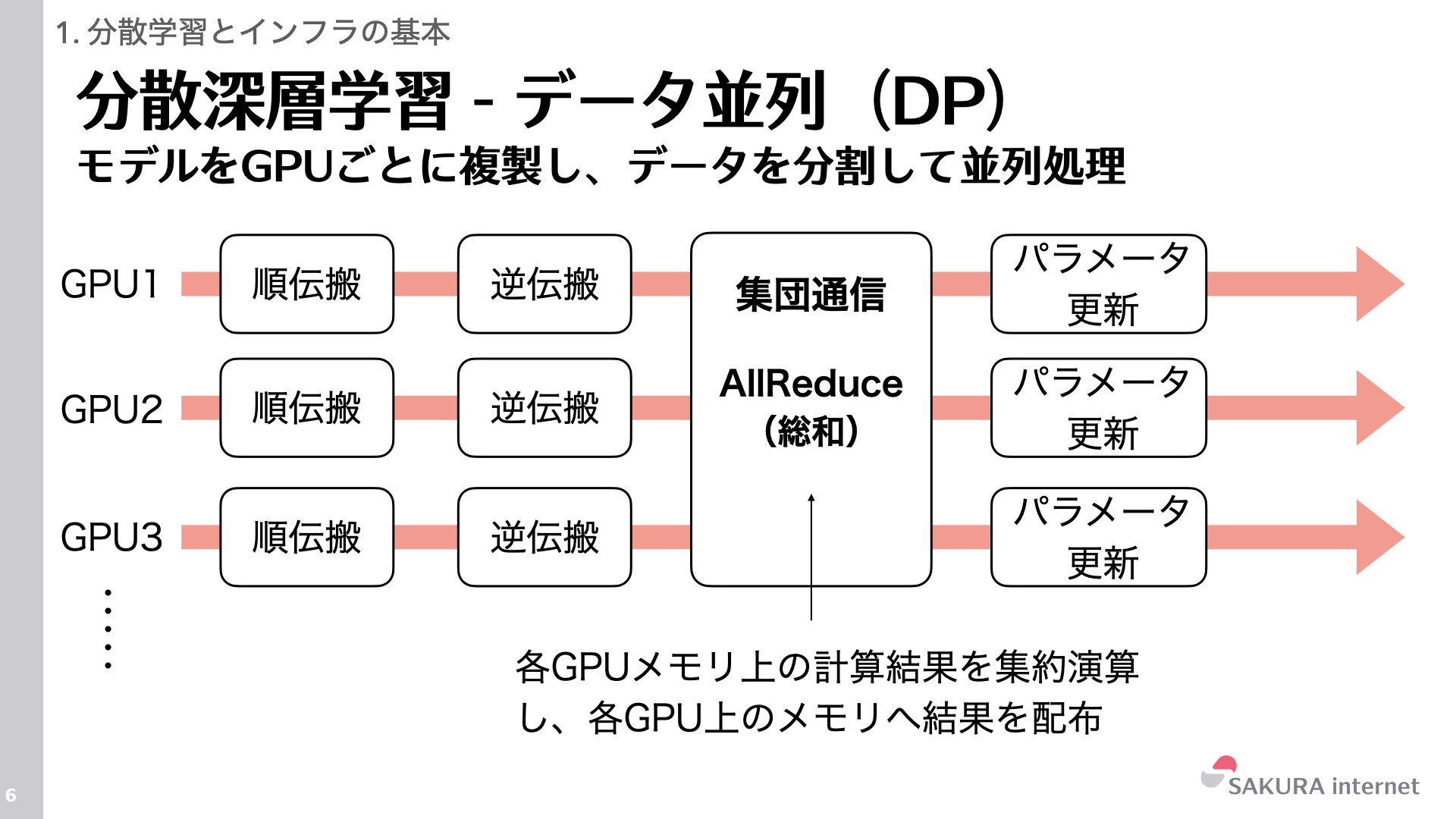
まず、最も基本となる並列化手法は、データ並列(DP: Data Parallelism)です。データ並列ではモデルをGPUの数だけ複製し、学習データセットをGPUの個数分に分割して、分割されたデータセットを各GPUに割り当てます。各GPUは独立して順伝搬、誤差逆伝搬を実行します。
逆伝搬後のパラメータ更新では深層学習のステップごとに各GPUで計算した勾配をGPU間で同期します。この勾配同期のために、グループ内の全プロセス(GPU)が参加して行う通信操作である集団通信(Collective Communication)が実行されます。集団通信にはいくつかの種類の操作があり、データ並列では、全GPUのデータを集約(Sum, Average等)し、結果を全GPUに配布するAllReduceが用いられます。
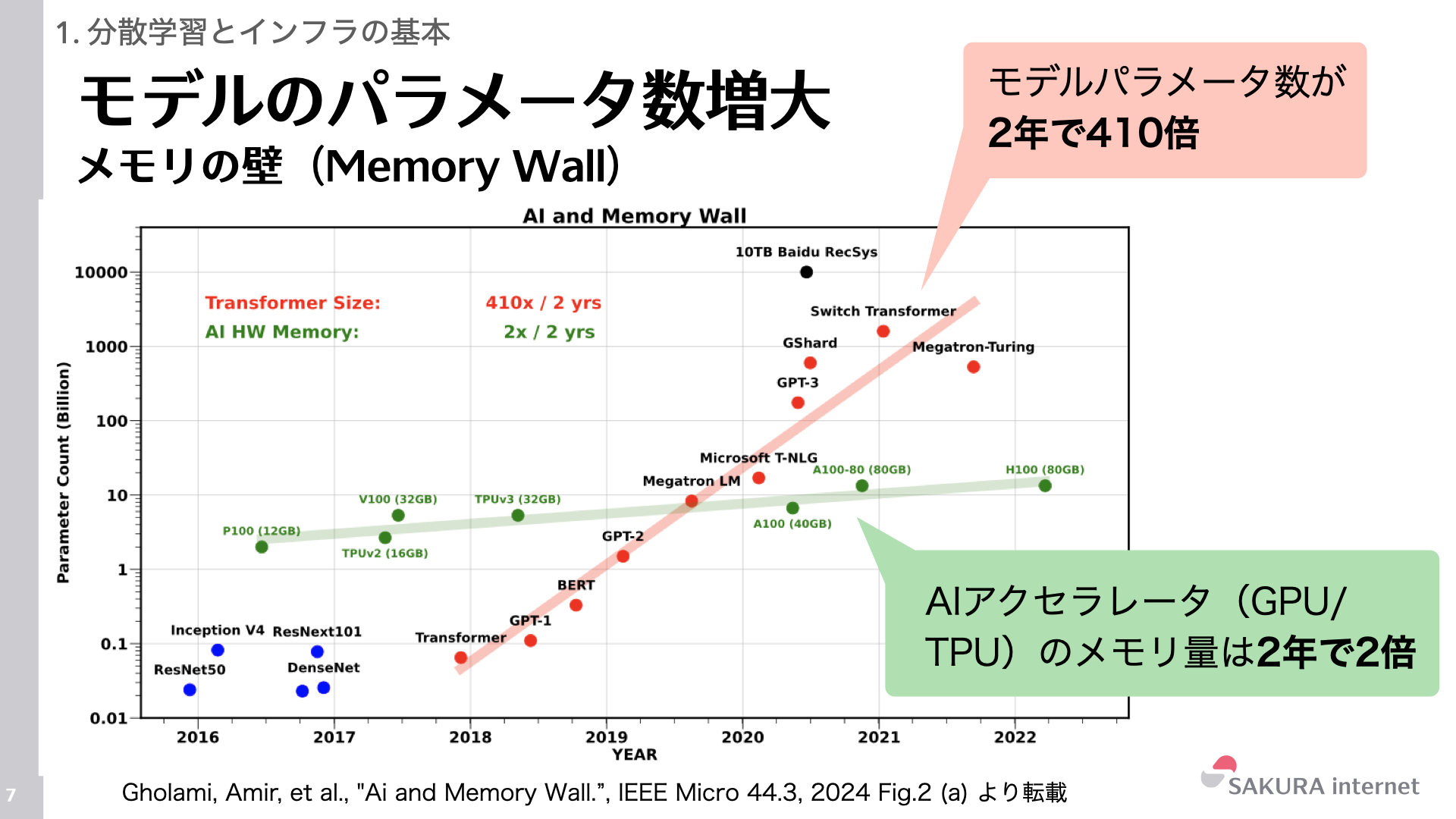
データ並列はモデルを複製するため、モデルパラメータなどのモデルに関する状態が1つのGPUのメモリに格納される必要があります。しかし、モデルパラメータ数は2年で約410倍に増加しているのに対し、GPUメモリ量は2年で2倍程度しか伸びていません。したがって、大規模モデルの状態は1個のGPUメモリには乗り切れません。
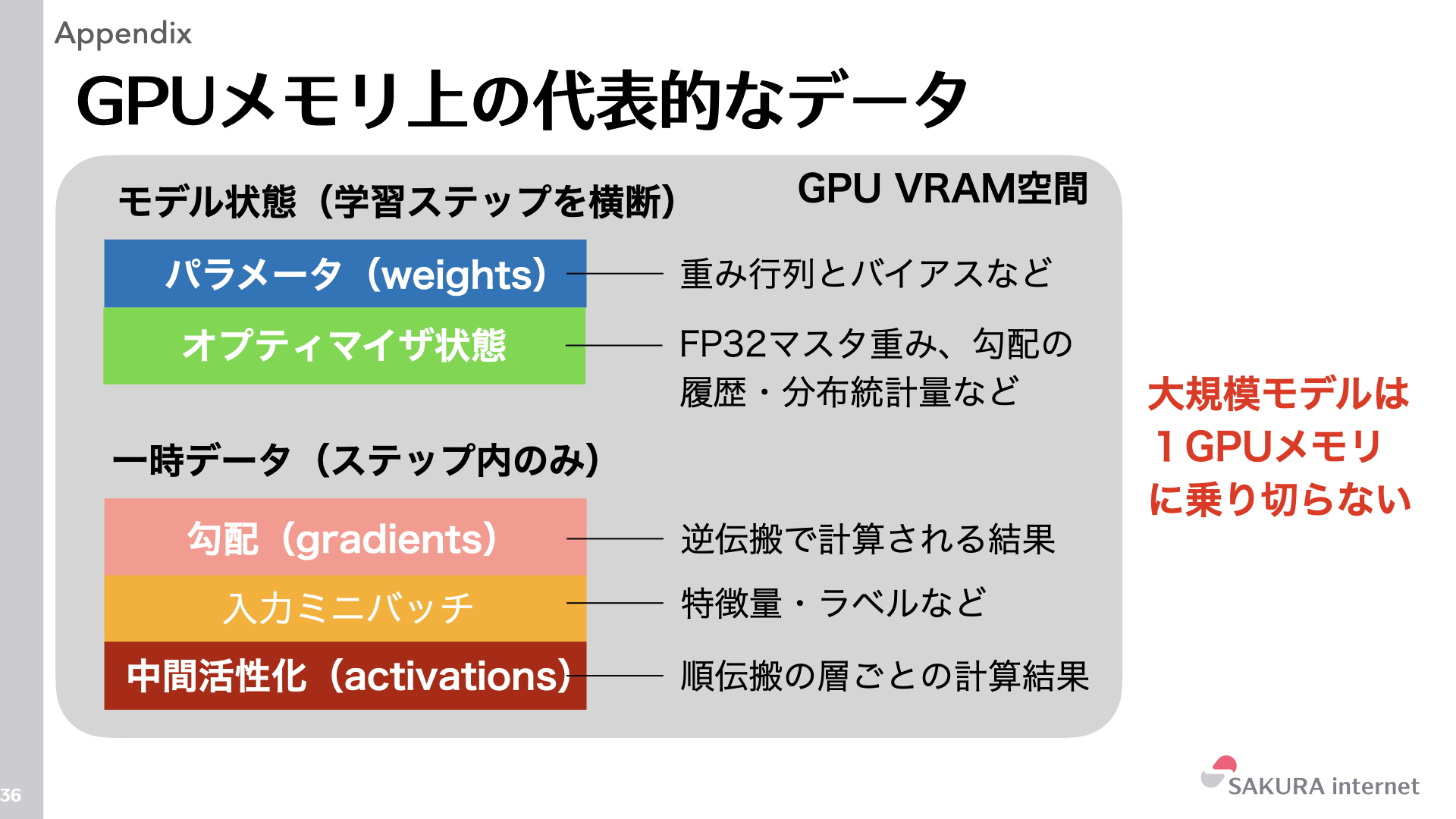
そもそもGPUメモリにはどのようなデータが格納されるのでしょうか?GPUメモリ(VRAM)の内訳は次の通りです。モデル状態(学習ステップを横断して保持)にはパラメータ(weights)とオプティマイザ状態(FP32マスタ重み、勾配の履歴・分布統計量など)が含まれます。一時データ(ステップ内のみ)には勾配(gradients)、入力ミニバッチ、中間活性化(activations)が含まれます。
「メモリの壁」を解決するためには、これらのGPUメモリ上のデータを分散して、複数のGPUメモリ上で並列処理する必要があります。これを達成する方法がモデル並列です。モデル並列の代表例は次のパイプライン並列とテンソル並列です。いずれもTransformerの層を分割する手法ですが、分割する方向が異なります。
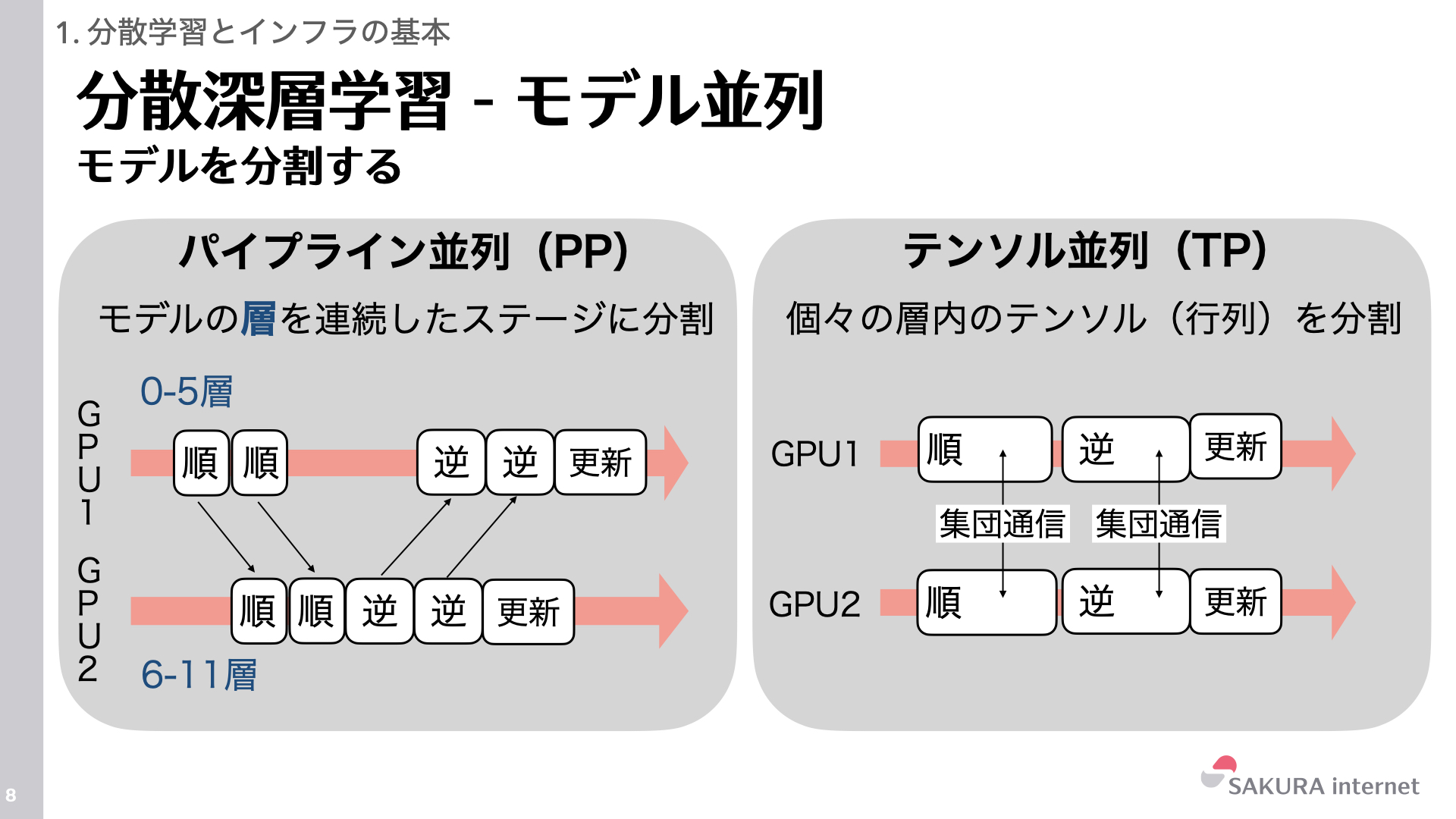
パイプライン並列(PP: Pipeline Parallelism)は、モデルの層を連続したステージに分割し、異なるGPUに配置します(例:GPU1が0-5層、GPU2が6-11層を担当)。分割されたステージ間でデータを渡すためにP2P通信 (Send/Recv) が行われます。パイプライン並列は、指定された切断点での中間活性化テンソルの交換のみを必要とするため、通信の必要頻度が低くなります。したがって、高帯域幅のノード内通信には以下のテンソル並列による通信を割り当て、より低速なノード間通信には、パイプライン並列のためのP2P通信を割り当て最適化することが一般的です。後述するMegatron-LMなどの分散学習フレームワークでは、パイプライン並列の改良手法が採用されています。具体的には、ミニバッチをさらに分割したマイクロバッチ単位でパイプラインに流すことにより、アイドルとなるGPU数を低減させる手法(Gpipe)や、「順伝搬1マイクロバッチ」と「逆伝搬1マイクロバッチ」を交互に実行することで通信を最小限にする手法(1F1B)などです。
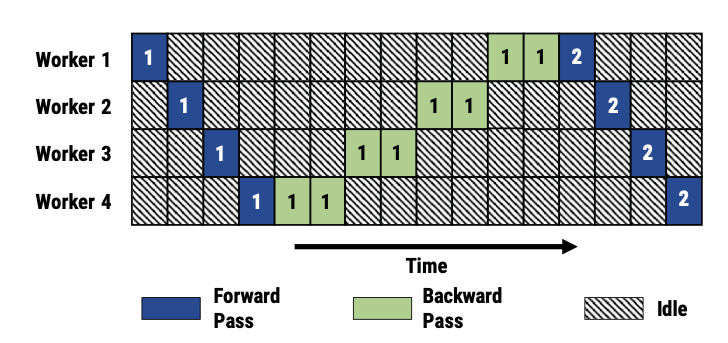
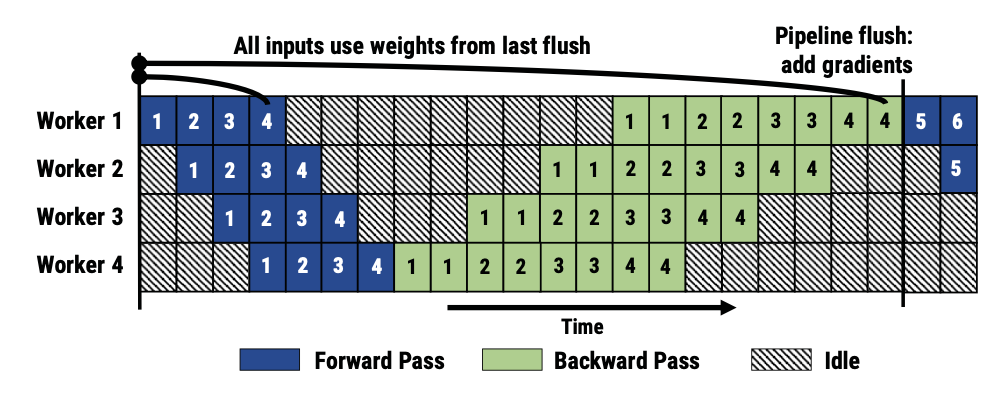
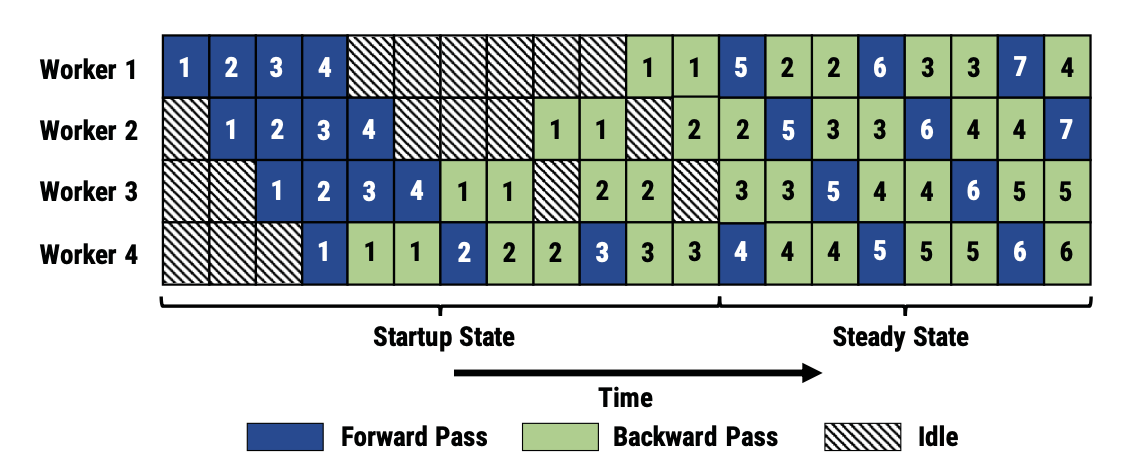
(以上3点の図は、Narayanan, Deepak, et al. "PipeDream: Generalized pipeline parallelism for DNN training.", OSDI 2019. より、Figure 2, Figure 3, Figure 4を転載したものです)
テンソル並列(TP: Tensor Parallelism)は、モデルの個々の層内の行列演算を分割し、異なるGPUに割り当てます。分割された行列演算の結果を統合するため、各層でAllReduceが行われます。通信頻度が極めて高いため、通常は後述するノード内通信で完結させます。テンソル並列では、TransformerにおけるLinear層やSelf Attention層、活性化層などの行列演算をGPU間で分割しますが、正規化層やドロップアウト層では、全GPUが同じ完全な複製を保持していました。この冗長なデータ保持を削減するために、これらの層の処理において、データをトークン方向に分割して各GPUにもたせるシーケンス並列が使用されます。シーケンス並列では、集団通信の操作として、AllGather + ReduceScatterが行われます。AllGatherは各GPUのデータを集め、全GPUが完全なデータを共有します。テンソル並列などで利用されます。ReduceScatterは全GPUのデータを集約し、結果を分割して各GPUに配布します。
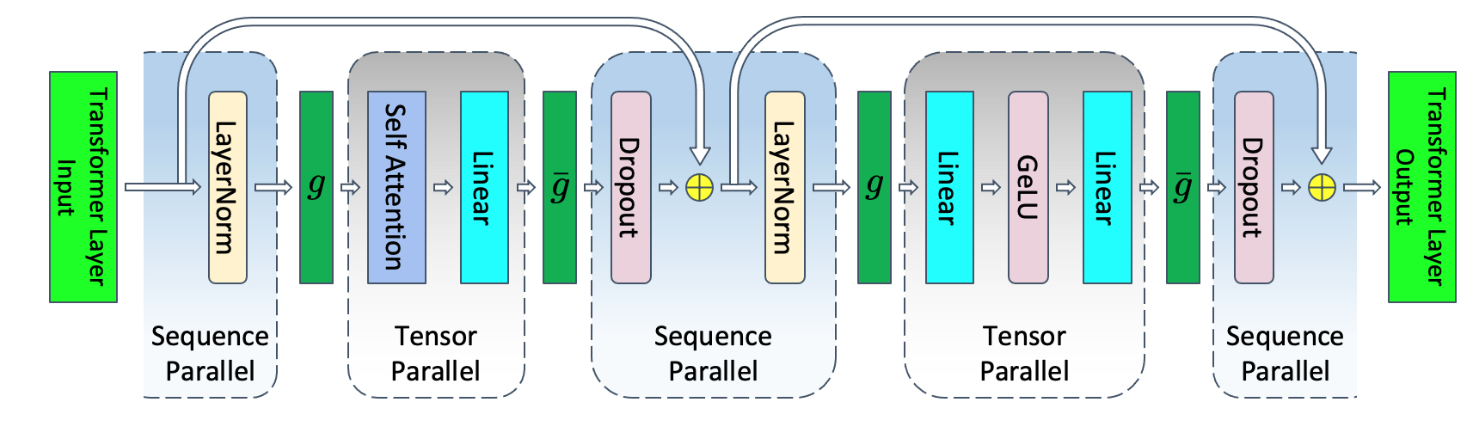
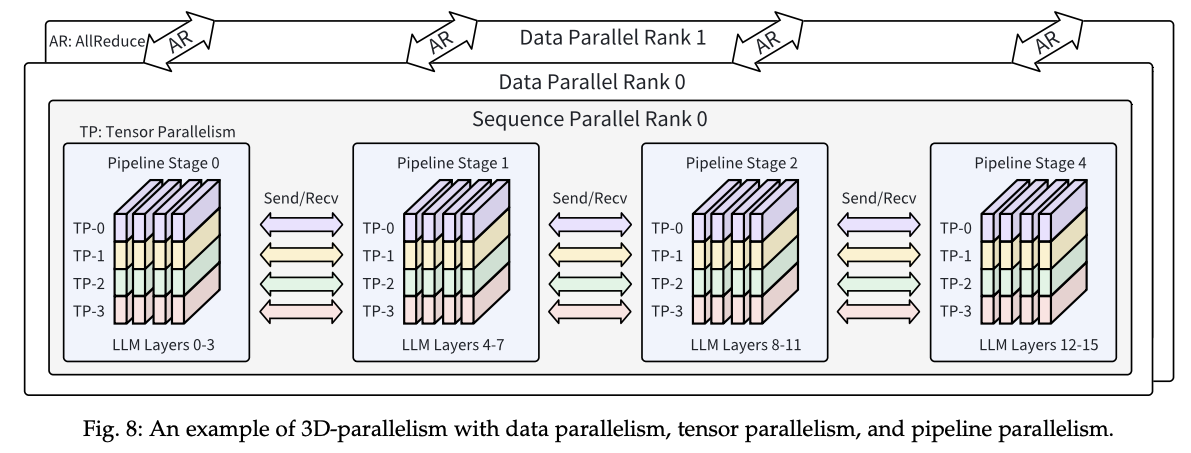
これらデータ並列、テンソル並列、パイプライン並列は互いに直交する概念であり、これら3つを組み合わせた並列化手法は3次元並列(3D Parallelism)(あるいはPTD並列)と呼ばれます。
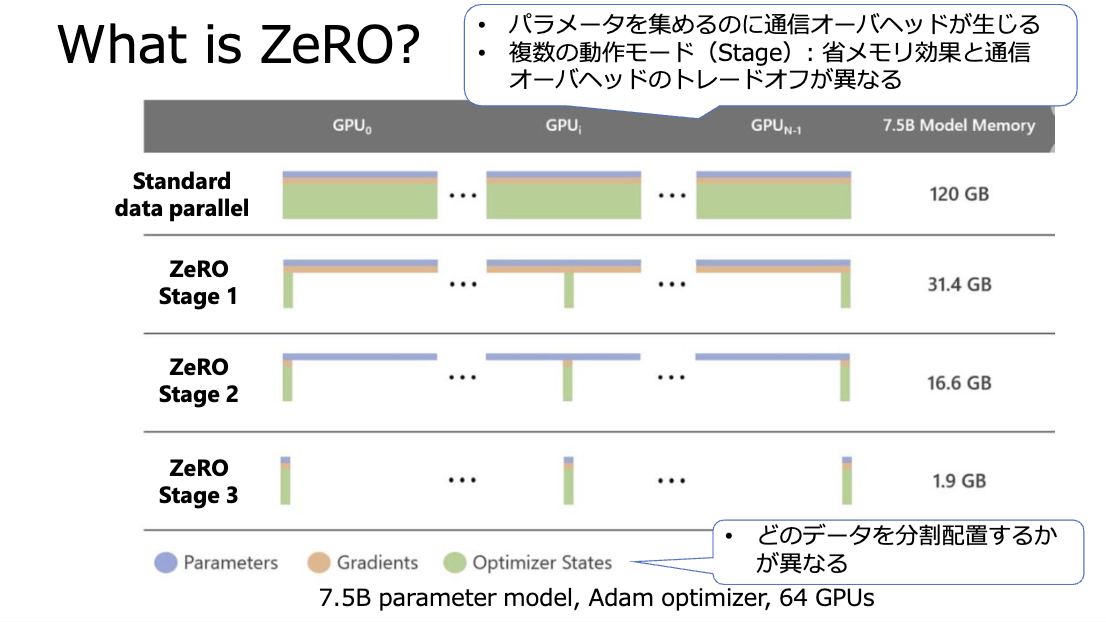
また、データ並列におけるメモリの冗長性を排除する技術としてZeRO (Zero Redundancy Optimizer)があります。通常のデータ並列では、全GPUがモデルパラメータやオプティマイザ状態の完全な複製を保持しますが、ZeROではこれらを各GPUに分割(シャーディング)して保持します。必要になるたびにGPU間通信で分割されたデータを集めます。これにより、各GPUのメモリ消費量を大幅に削減し、モデル並列を必ずしも用いずとも大規模なモデルの学習が可能になります。ZeROは、分割する対象に応じてStage 1(オプティマイザ状態のみ)、Stage 2(+勾配)、Stage 3(+パラメータ)の3段階があります。Stage番号が大きくなるにつれ、メモリ使用量は削減されますが、通信オーバーヘッドは増加します。
ネットワーク通信
演算性能は2.5年で10倍伸びましたが、特にノード間通信のネットワーク帯域の10倍伸長には約10年を要しています。それぞれのハードウェアの性能向上率の差は通信がボトルネックになりやすい傾向を示しています。
深層学習の学習時間に占めるAllReduceの割合推定は、10Gbpsネットワークで約50%、100Gbpsネットワークで20-30%。GPUの浮動小数点演算性能は2.5年で10倍伸びた一方で、ネットワーク帯域の10倍伸長には約10年を要しています。実際、100Gbpsネットワーク環境でも、学習時間の20〜30%を通信(AllReduceなど)が占めると推定されています。
(Sapio, Amedeo, et al. "Scaling distributed machine learning with In-Network aggregation." NSDI 21, 2021. と Klenk, Benjamin, et al. "An in-network architecture for accelerating shared-memory multiprocessor collectives.", ISCA, 2020.を参照)
分散学習における通信は主にノード内通信(Intra-node)とノード間通信(Inter-node)の2種類に大別されます。
ノード内通信 (Intra-node)
各ノードには上限8基のGPUが搭載され、NVLinkのような広帯域なチップ間インターコネクトで接続されます。これにより、ノード内のGPU間では数百GB/s〜TB/s級の高速な通信が可能となり、主にテンソル並列などの頻繁な通信を効率化します。
歴史的には、GPUとCPU、あるいはGPU同士の接続にはPCIe (Peripheral Component Interconnect Express) バスが用いられてきました。しかし、PCIeの帯域幅(Gen5 x16で双方向128GB/s程度)は、近年のGPUの演算性能の向上に追いついておらず、通信がボトルネックとなることが課題でした。これに対し、NVIDIAのNVLinkは、GPU間を直接接続する高速インターコネクト技術であり、PCIeを上回る帯域幅(H100では900GB/s)を提供します。さらに、NVSwitchと呼ばれるスイッチチップを介することで、ノード内の全GPU間をNVLinkでフルメッシュ接続し、どのGPU間でも高速かつ低遅延な通信を実現しています。これにより、テンソル並列のような頻繁なAllReduce通信が必要な処理においても、通信オーバーヘッドを最小限に抑えることが可能になります。
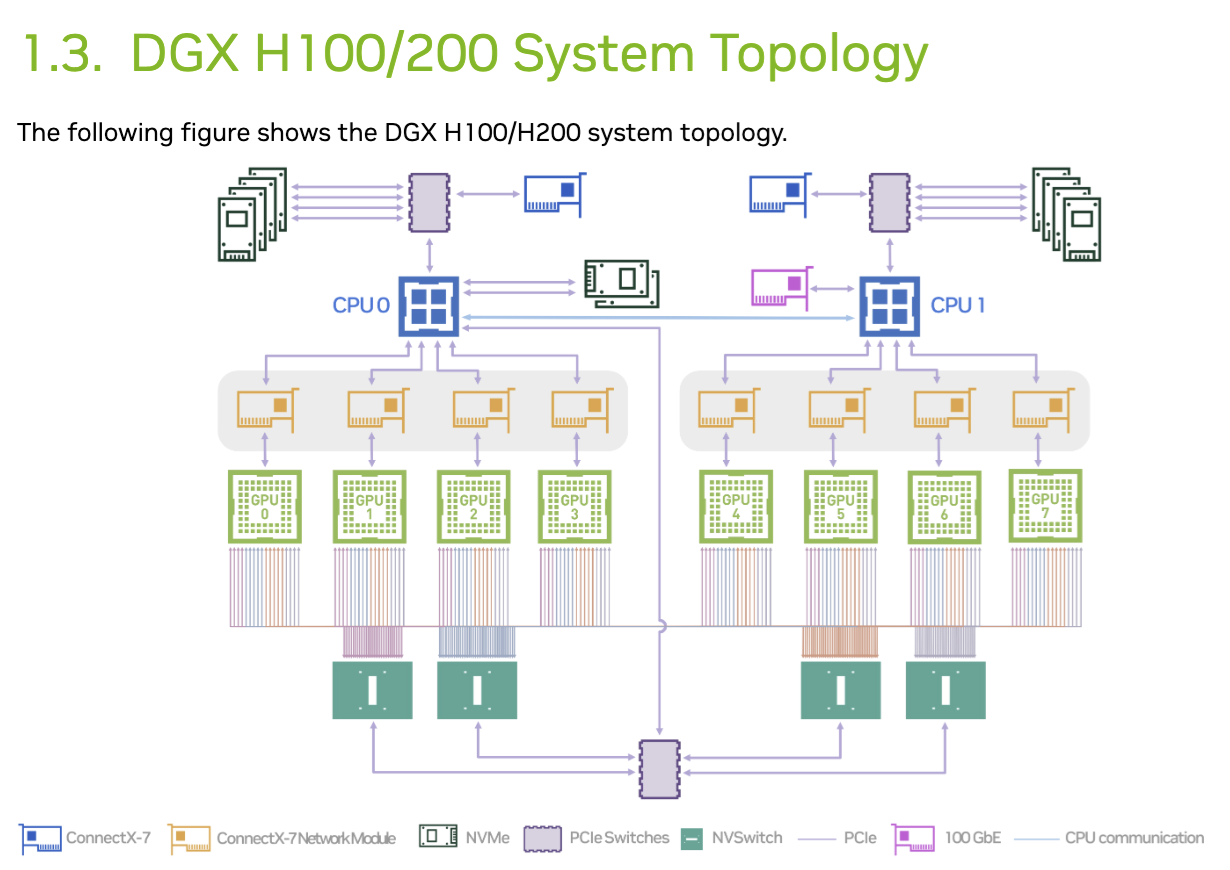
ノード内通信のトポロジの例として、NVIDIA DGX H100/H200の例を図に示します。図の中央下部に GPU 0 から GPU 7 まで、合計8基のH100(またはH200)GPUが配置されています。これらのGPUは、最下段にある4つのNVSwitchを経由して、NVLinkでフルメッシュ接続されています。これにより、CPUやPCIeバスを経由することなく、GPU同士が900GB/sの広帯域で直接データをやり取りします。
GPUの上にある中段のConnectX-7 Network Moduleは合計8枚搭載されており、400Gbps/NDR InfiniBand(またはEthernet)に対応したネットワークインターフェイス(HCA/NIC)です。GPU 1基につき、ネットワークカードが1枚で構成されています。GPUとネットワークカードが同じ「PCIeスイッチ」の下にぶら下がっているため、CPUを通さずにGPUメモリから他ノードへ直接データを転送する技術、つまりGPUDirect RDMAが可能となります。
上段のCPUは2ソケット構成であり、左右のCPUは相互接続されます。PCIeスイッチは、CPU、GPU、ネットワークカード、ストレージをつなぐハブの役割を果たします。上段のConnectX-7は、主にストレージへのアクセスや管理用ネットワークに使用されるネットワークカードです。NVMeはローカルストレージ用の高速SSDです。
ノード間通信 (Inter-node)
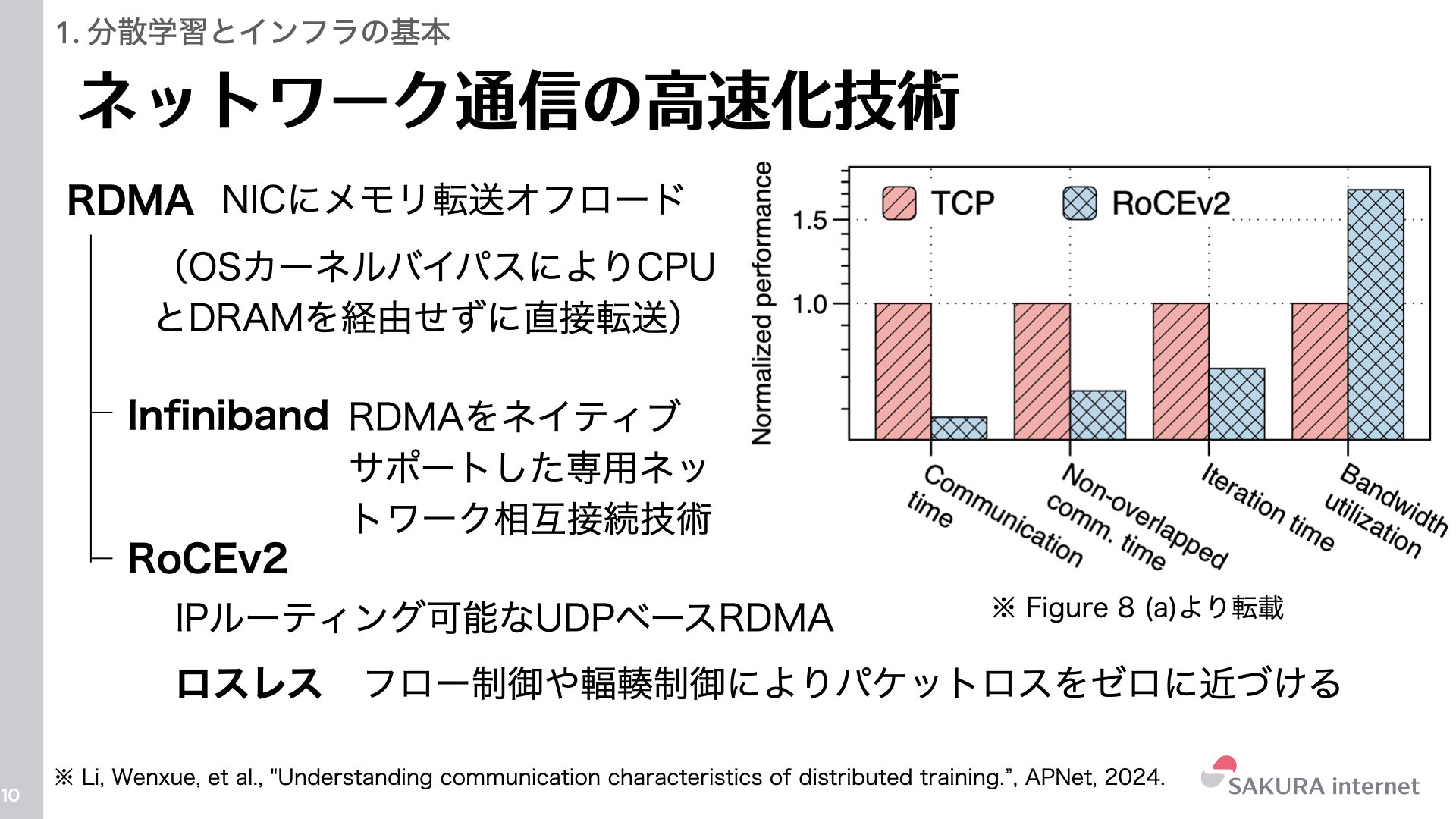
ノード間通信は、ノード間でInfiniBandやRoCE (RDMA over Converged Ethernet) といったRDMA(Remote Direct Memory Access)対応の高速ネットワークで接続されます。通信ボトルネックの解消には、CPUを介さずにメモリ転送を行うRDMAが不可欠です。特に、GPUメモリとNIC間で直接データを転送するGPUDirect RDMAは、ホストメモリを経由しないことで通信遅延を大幅に削減します。
RDMAプロトコルと輻輳制御
RDMAを実現するプロトコルには、主にInfiniBandとRoCEがあります。InfiniBandはHPC専用に設計され、超低遅延と高信頼性を誇りますが、専用のインフラが必要です。一方、RoCEv2はUDP/IPベースで動作し、汎用的なEthernetスイッチを利用できるため、コスト効率と柔軟性に優れています。さくらONEでもRoCEv2が採用されています。
RoCE環境では、パケットロスによる性能低下を防ぐため、PFC (Priority-based Flow Control)によるロスレスネットワークの構築が一般的です。さらに、DCQCN (Data Center Quantized Congestion Notification)などの輻輳制御アルゴリズムを組み合わせることで、ネットワークの混雑状況に応じて送信レートを動的に調整します。
ネットワークトポロジ
大規模クラスタの性能を引き出すには、物理的なネットワーク配線(トポロジ)の設計も重要です。
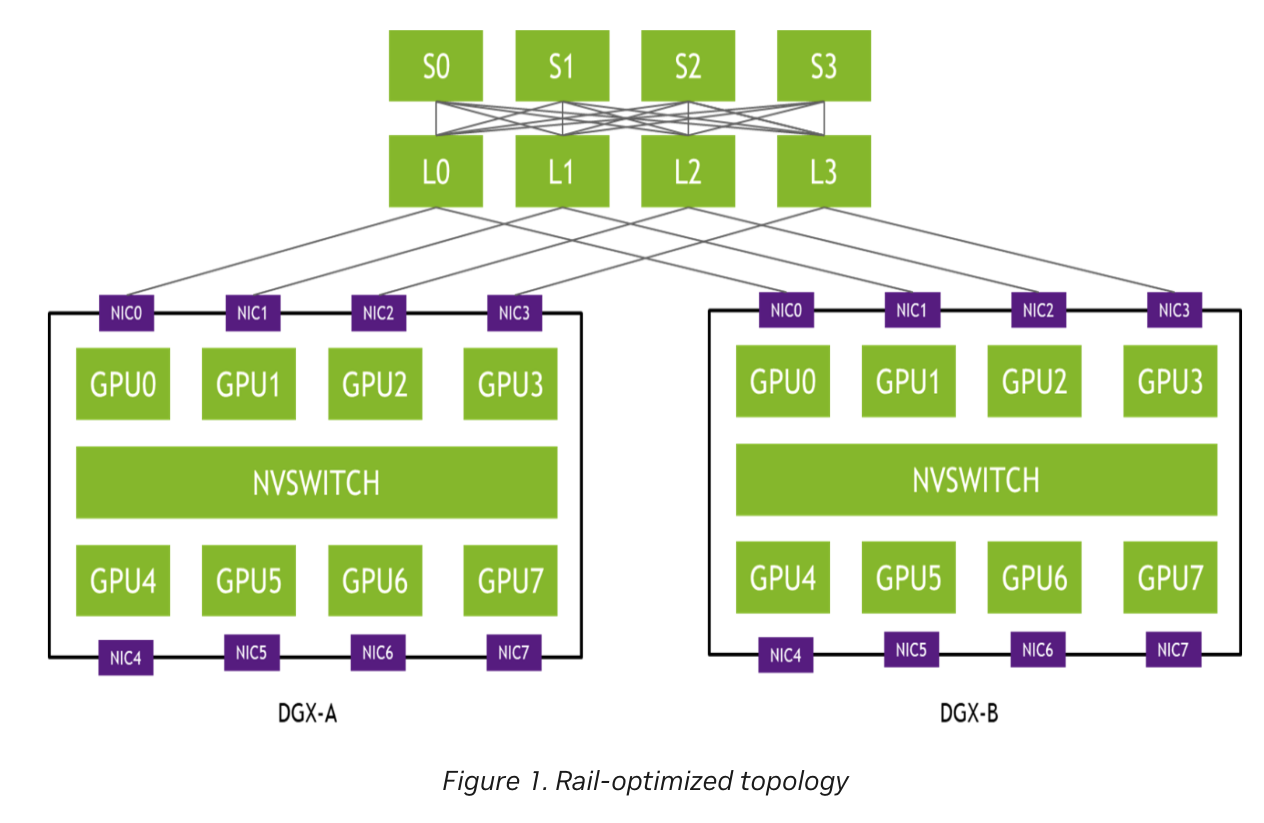
さくらONEでは、LLM学習の通信パターンとNVIDIAのノード内トポロジに最適化されたRail Optimizedトポロジを採用しています。データ並列やパイプライン並列では、異なるノード上の「同じGPU ID(ランク)」を持つGPU間での通信が頻繁に発生します。Rail Optimizedでは、この特性を利用し、異なるノードの同じランクのGPUを同じLeafスイッチに収容されるように配線します。ここでRailとは、GPU間通信におけるデータ転送のパスやリンクを指します。これにより、同一Rail内の通信はLeafスイッチで折り返すことができ、他の通信フローとの干渉を避けながら、通信のホップ数を減らせます。異なるRail間で通信する場合は、上層のSpineスイッチを経由せずに、PXNと呼ばれる集団通信ライブラリ(NCCL)の機能により、NVSwitch経由で対象のランクに紐づくNICを経由して通信します。
以上のように、大規模AIモデルの分散学習には、メモリの壁に加え、ネットワーク通信の壁が存在しており、性能ボトルネックの箇所は、ハードウェア性能やモデルサイズなど様々な要因によって異なります。
ノード間通信に関する詳細は、以下の参考資料を参照してください。
- 大浦 晋, 道下 幹也, ”Rethinking AI Infrastructure: LINEヤフーが描く、内製技術で切り拓くネットワークとエンジニアリングの新時代”, JANOG 55th Meeting, 2025年.
- 深澤 開, 小林 正幸, ”GPUクラスタネットワークとその設計思想(Rethinking AI Infrastructure Part 2)”, LINEヤフー Tech Blog, 2025年.
- 小林 正幸, ”GPUネットワーク設計・運用 基礎勉強会 Lossless Ethernet – PFC/ECN編”, 2024年.
ストレージ
分散学習において、ストレージは主に「学習データの読み込み」と「チェックポイントの保存」という2つの役割を担います。特に大規模言語モデル(LLM)の学習では、数千億パラメータを持つモデルの状態(Model State)やオプティマイザの状態(Optimizer State)を定期的に保存するチェックポイント処理が発生します。このチェックポイント処理により、デバイスの故障などが原因で学習が中断された場合に前回のチェックポイントからモデルの状態を復元し、学習を再開できます。チェックポイントのデータ量は数TB〜数十TBに及ぶことがあり、ストレージへの書き込み時間が学習全体のボトルネックになる可能性があります。そのため、計算ノードとストレージ間を高速なネットワークで接続し、並列ファイルシステム等を用いて広帯域なI/O性能を確保することが重要です。
なお、今回のMLPerf GPT-3事前学習ベンチマーク(Closed Division)では、学習中のチェックポイント保存(ストレージへの書き込み)はベンチマーク規則上行いません。
ソフトウェアスタック
分散学習を支えるソフトウェアスタックは、ハードウェアに近い低レイヤからアプリケーションに近い高レイヤまで、次の表で示すように多層的な構造を持っています。
| 層(レイヤ) | 役割 | 代表的コンポーネント・例 | 特徴 |
|---|---|---|---|
| アプリケーション / モデル実装 | 具体的なモデルと学習コード | ユーザー独自の学習スクリプト、タスク固有コード、評価スクリプトなど | 下位のフレームワーク・並列化ライブラリのAPIを直接呼び出す部分。学習ループ、ログ、チェックポイント制御などもここに含まれる。 |
| 分散学習フレームワーク / ライブラリ | モデル並列・データ並列などをまとめて提供 | PyTorch Distributed(DDP)、Megatron-LM、NeMo、DeepSpeed、FairScale など | テンソル並列・パイプライン並列・データ並列の組み合わせを実装し、GPUクラスタ全体にモデルを分割して配置する。 |
| 機械学習フレームワーク | 自動微分、オプティマイザ、ニューラルネットワークのレイヤ実装 | PyTorch、TensorFlow、JAX など | GPU向けカーネル呼び出しや自動微分、Automatic Mixed Precision (AMP)、チェックポイントなどの基本機能を提供。分散学習はこの層または上位層が担当する。 |
| 通信ライブラリ | GPU間・ノード間通信を抽象化 | NCCL、MPI(OpenMPI, MPICH), Gloo, UCX, NVSHMEM など | 集団通信やその他のGPU-to-GPU通信を効率良く実装。GPUクラスタでは NCCL + RDMA (InfiniBand / RoCEv2) が事実上の標準。 |
| 数値計算ライブラリ / GPUカーネル | 行列演算や深層学習向けの最適化カーネル | cuBLAS, cuDNN, cuSPARSE, TensorRT, Transformer Engine など | GEMMや畳み込みなどの演算を GPUアーキテクチャに合わせて最適化。大規模言語モデルでは GEMM性能とfused kernel(Bias+GeLU, Softmax など)がスループットに直結。 |
| GPU プログラミング環境 | GPU を扱うための基本ランタイム | CUDA(NVIDIA)、HIP/ROCm(AMD)など | ストリーム、イベント、メモリ管理、カーネル起動、GPUDirect RDMAなどを提供。通信ライブラリや深層学習フレームワークはこの上に構築される。 |
| ネットワークスタック / RDMA ミドルウェア | 高速ネットワークの制御・抽象化 | OFED(InfiniBand ドライバスタック)、RDMA verbs、RoCEv2 stack、UCXなど | RDMAによる低レイテンシ通信を提供。NCCLや MPIがこの層を経由して InfiniBand / RoCE NIC を利用する。大規模な All-Reduceの性能を左右。 |
| ジョブスケジューラ / クラスタマネージャ | ノード・GPUの割り当てとジョブ実行管理 | Slurm、PBS、LSF、Kubernetes、Rayなど | 分散学習ジョブに対して「何ノード×何GPU」を割り当てるかを管理し、MPI ランチャや torchrun、deepspeed などを起動。再実行・キューイング・優先度などもここ。 |
| ファイルシステム / ストレージ | データセット・チェックポイントの格納 | Lustre, GPFS, BeeGFS, NFS, オブジェクトストレージ (S3 互換) など | 大規模モデルではチェックポイントが TB 級になるため、高速な並列ファイルシステムが必要。 |
| デバイスドライバ / ファームウェア | GPU・NVLINK/NVSwitch・NIC をOSから利用するための低レイヤ | NVIDIA GPU Driver、NVIDIA Fabric Manager、Mellanox OFED / NIC ドライバ、FW、PCIeスイッチドライバなど | ここが不整合だとNCCL の性能低下やリンクダウン、エラーなどにつながる。CUDAの対応バージョンと組み合わせが重要。 |
分散学習フレームワークの設定
NeMo Framework(Megatron-LM)では、config.yaml などの設定ファイルを通じて、分散学習の挙動を詳細に制御できます。フレームワークのユーザーが処理性能をチューニングする場合は、主にこれらの設定を調整することになります。特に重要となる代表的な設定項目を以下に示します。
並列化設定 (Parallelism)
tensor_model_parallel_size(TP)
テンソル並列の分割数です。通常はノード内のGPU数(例: 8)以下に設定し、NVLinkなどの高速なノード内通信を利用します。pipeline_model_parallel_size(PP)
パイプライン並列のステージ数です。モデルの層をいくつのステージに分割するかを決定します。virtual_pipeline_model_parallel_size
インターリーブ・パイプライン(Interleaved Pipeline)を使用する場合の、1つのパイプラインステージあたりの仮想ステージ数です。これを設定することで、パイプラインバブル(アイドル時間)を削減できます。
バッチサイズ (Batch Size)
https://docs.nvidia.com/nemo-framework/user-guide/latest/nemotoolkit/nlp/nemo_megatron/batching.html
global_batch_size(GBS)
全GPUで1ステップあたりに処理するデータの総数です。学習の収束性能に直接影響します。micro_batch_size(MBS)
各GPUが1回の順伝搬/逆伝搬パスで処理するデータのサイズです。GPUメモリに収まる範囲で最大化することで、演算効率を高めることができます。gradient_accumulation_steps
パラメータ更新を行う前に勾配を蓄積する回数です。通常はGBS / (MBS * DP * PP)で自動計算されます。
メモリ最適化 (Memory Optimization)
activations_checkpoint_granularity/activations_checkpoint_method
Activation Checkpointing(再計算)の設定です。selectiveやfullを設定することで、メモリ使用量を削減する代わりに計算量を増やすトレードオフを制御します。optimizer.namedistributed_fused_adamを指定することで、オプティマイザ状態をデータ並列グループ全体に分散させ、メモリ使用量を大幅に削減できます(ZeRO-2相当)。
通信隠蔽 (Communication Overlap)
overlap_p2p_comm
パイプライン並列におけるP2P通信(Send/Recv)を計算とオーバーラップさせます。overlap_grad_reduce
データ並列における勾配のAllReduce通信を、バックワード計算とオーバーラップさせます。overlap_param_gather
分散オプティマイザ使用時に、パラメータのAllGather通信をフォワード計算とオーバーラップさせます。
さくらONE
システム概要
ベンチマークの対象となる「さくらONE」は、さくらインターネットが自社構築したマネージドHPCクラスタです。2025年6月のTOP500ランキングにおいて世界49位を獲得しました。特徴は、TOP500の上位100位以内で唯一、バックエンドネットワークとしてベンダー中立でオープンな技術(SONiC OSと800GbE Ethernet)を採用している点です。
以下に、さくらONEのシステム概要と簡便な構成図を示します。
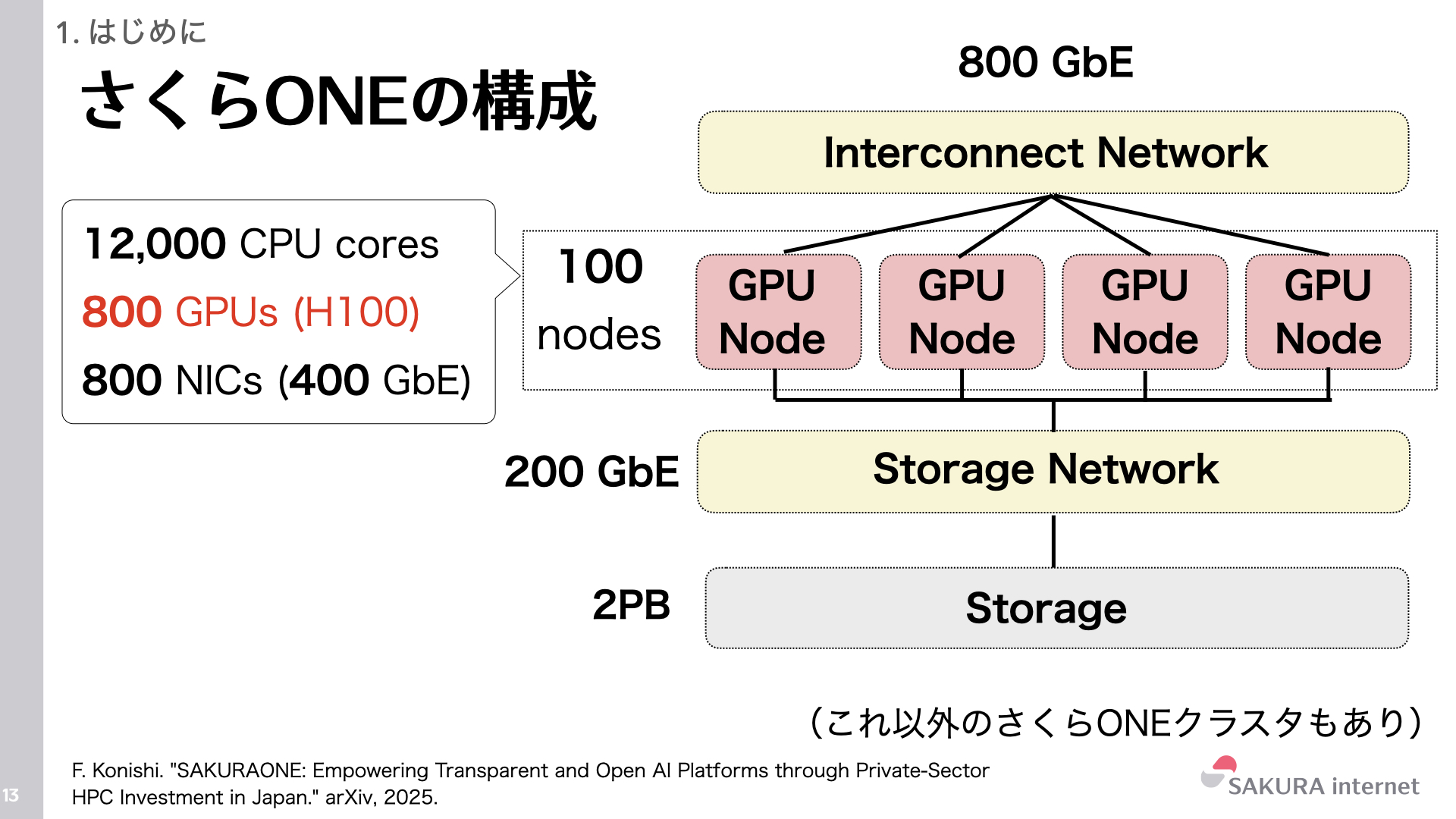
- ノード数: 100 nodes
- CPU: 12,000 cores (Intel Xeon Platinum 8580+ x2 / node)
- GPU: 800 GPUs (NVIDIA H100 SXM 80GB x8 / node)
- NIC: 800 NICs (400 GbE (NVIDIA ConnectX-7))
- バックエンドネットワーク: 800 GbE (RoCEv2) / SONiC OS
- トポロジ: 2層のLeaf-Spine構成、Rail Optimizedトポロジ
- ストレージ: 2PB (Lustre File System on DDN ES400NVX2)
- ストレージネットワーク: 200 GbE
詳細な構成はarXivのホワイトペーパーでも公開されています。
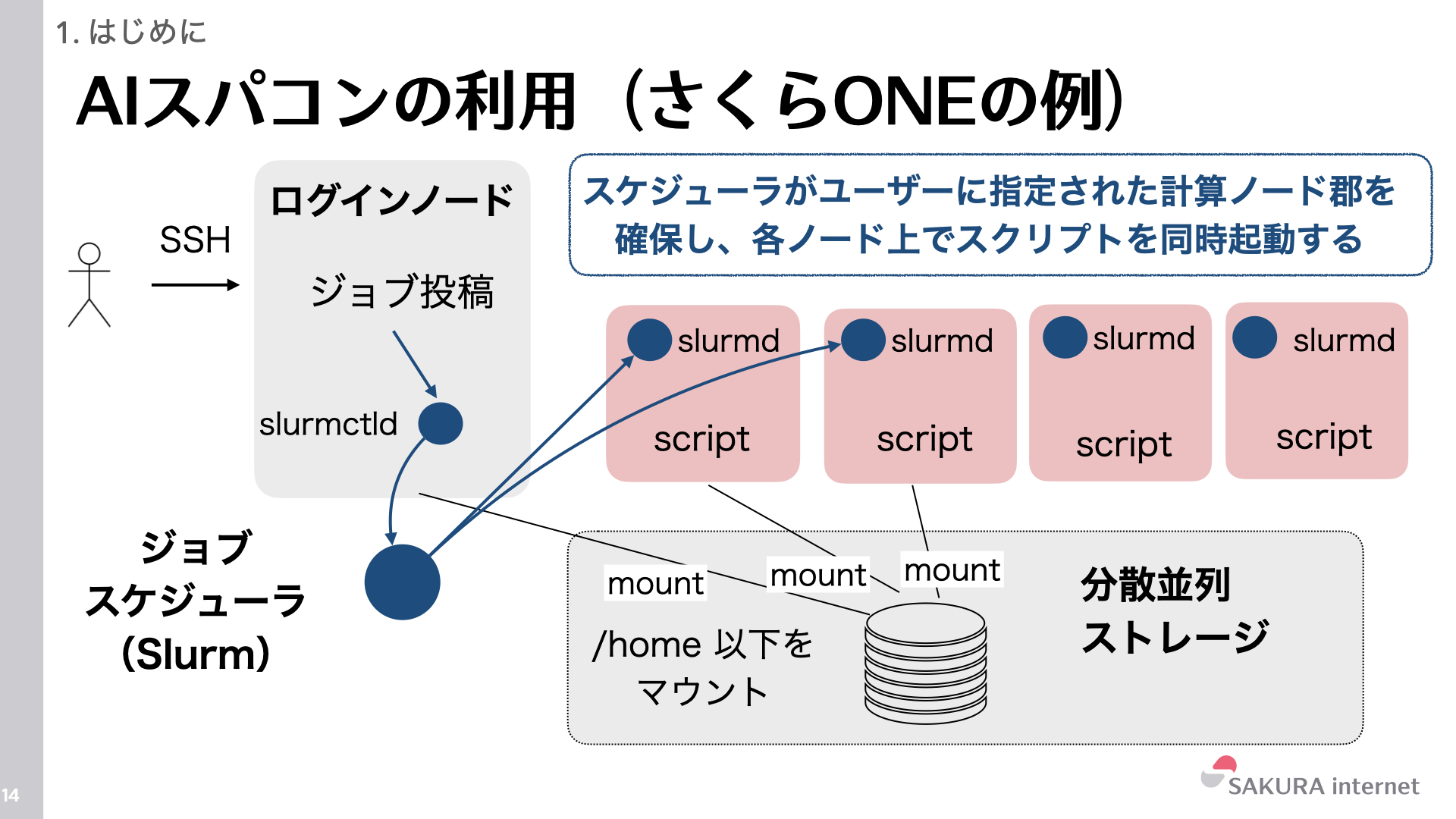
図はさくらONEの利用イメージです。ユーザーはログインノードにSSHで接続し、ジョブスケジューラ(Slurm)に対してジョブを投入します。Slurmは要求されたリソース(GPUノード)を確保し、各計算ノード上でジョブを実行します。全ノードは高速な分散ストレージを共有しており、データセットやコードへのアクセスが可能です。
MLPerf Trainingベンチマーク実施内容
ベンチマーク内容
- 対象タスク: MLPerf Training GPT-3 175B 事前学習
- 評価指標: 学習開始から、評価データセットのLog Perplexityが2.69に到達するまでの実時間(Time to Train)。評価頻度は24,576 サンプル(= 5033万トークン)ごと。
- 規則: Closed Division準拠(ハイパーパラメータ固定、指定データセット使用)
GPT-3 175Bの事前学習タスクは、2022年にMLPerf Trainingに追加され、昨年のv4.1まで現役でしたが、今年のv5.0から退役し、代わりにより大規模なLLama3.1 405B事前学習タスクが追加されました。
GPT-3のデータセットは、GoogleがT5モデルの訓練のためにウェブから収集した大規模でクリーンなテキストデータセットであるC4 (Colossal Clean Crawled Corpus)です。データセットは前処理されたものが与えられます。全体で約331GBのサイズになります。
トークナイザーには、c4_en_301_5Mexp2_spm.model というSentencePieceモデルのトークナイザーが使用されます。
モデルチェックポイントとしてグローバルバッチサイズ1536で4000ステップ分の学習が済んだ状態のものが与えられます。これはおそらく学習初期の不安定さを避けるために、ある程度学習が進んだモデルが与えられていると考えられます。
セットアップ手順はMLCommonsが公開しているリファレンス実装に記載されています。
固定パラメータと調整可能パラメータ
基本的に、計算機をより効率的に動作させるためのパラメータの調整は許可されています。一方で、計算負荷自体を低減させる可能性がある、モデルアーキテクチャに関するハイパーパラメータ、シーケンス長、最適化器の種類などの設定項目の値は、ベンチマーク規則で指定されています。
主要な固定のモデルハイパーパラメータは以下の通りです。
- オプティマイザ: Adam
- Beta 1: 0.9
- Beta 2: 0.95
- Epsilon: 1e-8
- Weight Decay: 0.1
- Gradient Clip Norm: 1.0
- 主要ハイパーパラメータ:
- Dropout: 0.0 (学習中は無効化)
- Sequence Length: 2048
- Global Batch Size (GBS): 1536から8192の間の設定が許可されている。global_batch_sizeの値によって、学習率(opt_base_learning_rate)が変更される。("GPT3 hyperparameter constraints"参照)
- GBS 1536, 2048, 3072 の場合: 2.0e-5
- GBS 4096, 8192 の場合: 3.0e-5
- これ以外のGBSを使用する場合は、新たな基準収束点(RCP)の生成が必要。
- 学習率スケジュール:
- ウォームアップ: 最初の一定ステップ(GBS=1536換算で265ステップ相当)で線形増加。
- 減衰: Cosine Decayを使用し、最終的にベース学習率の10%まで下げる。
- 低精度演算:規則では以下の精度が許可されています(※)。MLCommonsからFP36とBF16でのチェックポイントデータが事前に用意されています。本ベンチ―マークではBF16を使用しました。
(※) The numerical formats fp64, fp32, tf32, fp16, fp8, bfloat16, Graphcore FLOAT 16.16, int8, uint8, int4, and uint4 are pre-approved for use. ("GPT3 hyperparameter constraints"参照)
実装
まず、ベースとなる実装の選定です。今回は、ラウンドv4.1におけるNVIDIA社のEosシステム(H100x8x64ノード)の実装を参考に、さくらONEの環境に合わせて実装を行いました。これは、MLPerf公式のリファレンス実装よりも、各社が過去のラウンドに公式に投稿し、公開した実装の方がよく整理されているためです。
この実装のソフトウェアスタックとして、NVIDIA NeMo Framework(Megatron-LMベース)が採用されています。また、Transformer Engineを用いたFP8(8ビット浮動小数点)混合精度学習が導入されています。並列化戦略としては、Tensor並列(TP=4)、パイプライン並列(PP=8)、データ並列(DP=8)を組み合わせた3D並列が採用され、さらにInterleaved Pipelineスケジュールによりパイプラインバブルを低減しています。
通信隠蔽(Communication Overlap)に関しては、TP_COMM_OVERLAP、MC_TP_OVERLAP_AG(AllGather)、MC_TP_OVERLAP_RS(ReduceScatter)といった環境変数を有効化することで、Tensor並列における通信を計算とオーバーラップさせています。
分散Adam Optimizerにより、前述したZeRO-1/ZeRO-2とほぼ等価のメモリ使用削減技術が使用されています。(参考: Enable Data Parallelism)
また、ジョブスケジューラにはSlurmが使用されていることが前提となっています。SlurmのPyxisプラグインを用いて、学習スクリプトをEnrootコンテナランタイム上で実行します。
学習性能の評価指標
学習性能の評価には、Time to train以外に、主にスループットと演算効率が用いられます。
- 学習スループット:Tokens per second (tokens/sec)
システム全体で1秒間に処理できるトークン数(スループット)です。これが高いほど、同じ学習量を短時間で完了できます。NeMoではSpeedMonitorコールバックモジュールを用いて計測できます。 - 演算スループット:FLOPS (Floating Point Operations Per Second)
1秒間に実行できる浮動小数点演算の回数であり、演算器レベルでのスループットを示す指標です。FLOPSは、ハードウェア仕様上の理論最大性能(カタログスペック)と実際の学習で達成された実効性能の2つに大別されます。1GPUあたりのFLOPSを計測することで、GPUの性能をどの程度引き出せたかを示す指標となります。NeMoではFLOPsMeasurementCallbackモジュールを用いて計測できます。 - 演算効率:MFU (Model Flops Utilization)
GPUの理論ピーク性能(FLOPS)に対して、実際にモデルの演算でどれだけの性能を引き出せているかを示す利用率(効率)です。式で表すと下記の数式1のようになります。
ここで、Achieved FLOPS(実効性能)は、モデルパラメータ数 P とスループットを用いて以下の数式2のように近似計算されます。係数の6は、順伝搬で2P、逆伝搬で4Pの浮動小数点演算が必要であることに由来します(Activation Recomputationを行わない場合)。計算式の詳細は、Transformer FLOPs を参照してください。NeMoではFLOPsMeasurementCallbackモジュールのeval_model_flopsメソッドを用いて計測できます。
(数式1) MFU=Achieved FLOPSTheoretical Peak FLOPS(数式1) \text{MFU} = \frac{\text{Achieved FLOPS}}{\text{Theoretical Peak FLOPS}}
(数式2) Achieved FLOPS=6×P×Tokens/secNumber of GPUs(数式2) \text{Achieved FLOPS} = \frac{6 \times P \times \text{Tokens/sec}}{\text{Number of GPUs}}
これらの指標のNeMoにおける計測方法は次の通りです。ベース実装には計測のためのコードは含まれていないため、自前で計測コードを追加する必要があります。NeMo Framework (Megatron-LM) では、学習ログ(標準出力や dllogger)にステップごとのパフォーマンス情報が出力されます。
- Tokens per second: ログに出力される
samples/sec(またはthroughput)にシーケンス長(GPT-3 175Bでは2048)を乗じることで算出できます。 - FLOPS: ログに出力される
tflops(Tera FLOPS per GPU) がGPUあたりのAchieved FLOPSに相当します。 - MFU: 上記の
tflopsをH100の理論ピーク性能(例:FP8 Tensor Coreで約1979 TFLOPS)で割ることで算出できます。また、TensorBoardやWandBなどの可視化ツールでも確認可能です。
測定結果
さくらONE(SAKURAONE)における測定結果と、MLPerf Training v4.1の公式結果(NVIDIA Eosシステム)との比較を以下に示します。
注: 本稿で紹介するさくらONEにおける測定結果は非公式なものであり、MLCommons Associationによる検証を受けていない(unverified)点にご留意ください。

| 組織 | システム名 | GPU数 | GPUモデル | 学習時間 (分) | 備考 |
|---|---|---|---|---|---|
| SAKURA | SAKURAONE_n96 | 768 | H100-SXM5-80GB | 41.862 (unverified) | TP=8, PP=16, DP=6 |
| NVIDIA | Eos_n64 | 512 | H100-SXM5-80GB | 49.795 | |
| SAKURA | SAKURAONE_n32 | 256 | H100-SXM5-80GB | 105.310 (unverified) | |
| NVIDIA | Eos_n32 | 256 | H100-SXM5-80GB | 96.664 |
学習時間は、学習開始から評価データセットのLog Perplexityが2.69に到達するまでの実時間(Time to Train)を示しています。
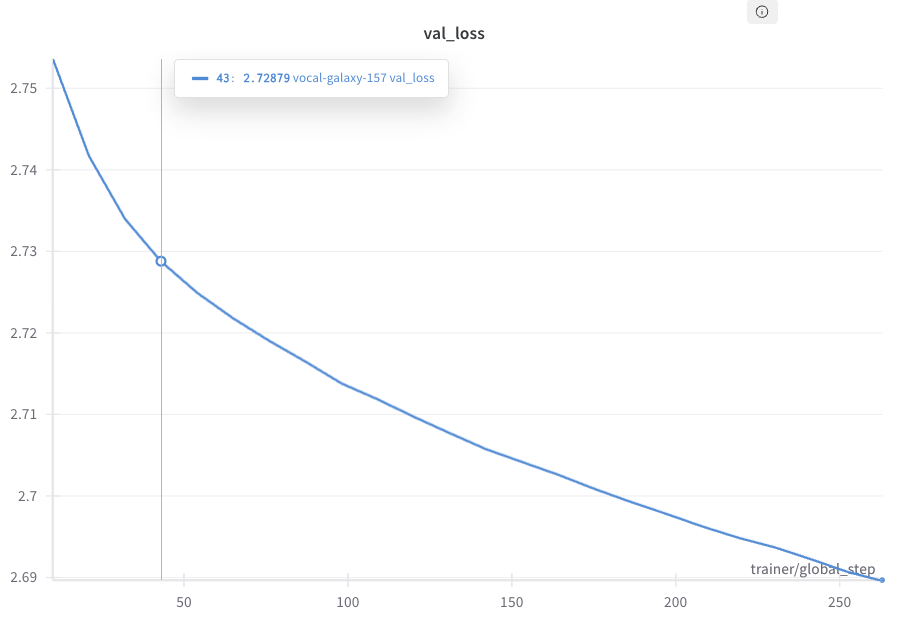
図はSAKURAONE_n96での学習曲線を示しています。Log Perplexityが2.69に到達するまでに263ステップを要しています。
他システムとの比較
同規模比較(256 GPU)
NVIDIA Eos(InfiniBand採用)の96.664分に対し、さくらONE(Ethernet採用)は105.310分でした。これはEosに対して約91.7%の速度であり、オープンなEthernet技術を用いながらも、トップレベルの専用機と概ね同等の性能を発揮していると言えます。

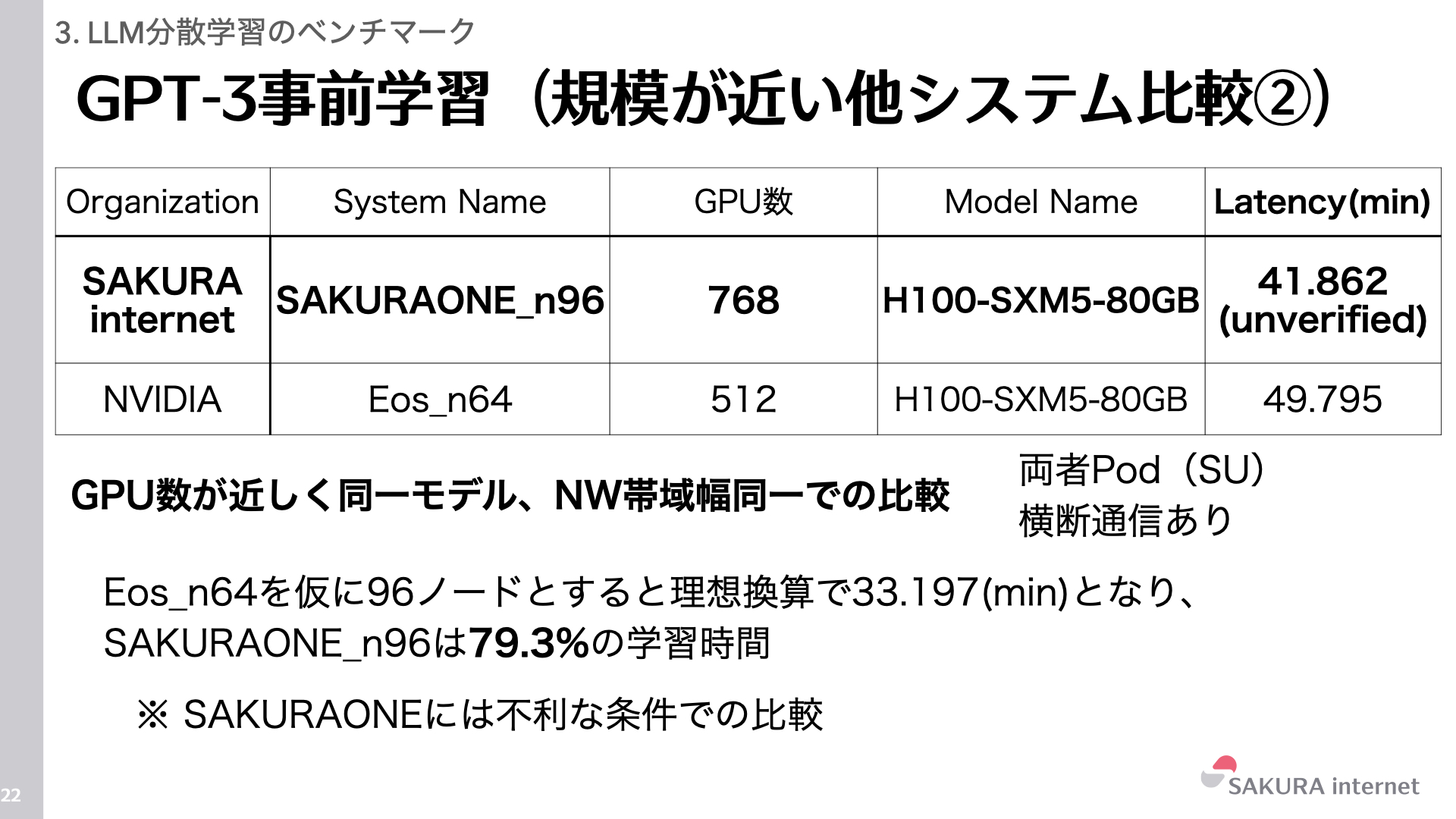
大規模比較(768 GPU vs 512 GPU)
NVIDIA Eosの512 GPUの結果を、仮に96ノード(768 GPU)相当に理想的に換算すると約33.2分となります。これに対し、さくらONEの実測値は41.862分であり、理想値に対して約79.3%の性能(-20.7%の乖離)となりました。この要因としては、RoCEv2かInfiniBandであるかのネットワーク通信規格やネットワークスイッチデバイスの違いによる影響や、ソフトウェアスタックのチューニング不足などが考えられます。GPUの世代やネットワークトポロジなどは同一条件での比較です。
スケーリングと演算効率(MFU)
ノード数を32から96へと3倍に増やした際、学習時間は2.51倍短縮されました。理想的なスケーリング(3倍)に対しては-17%の結果です。
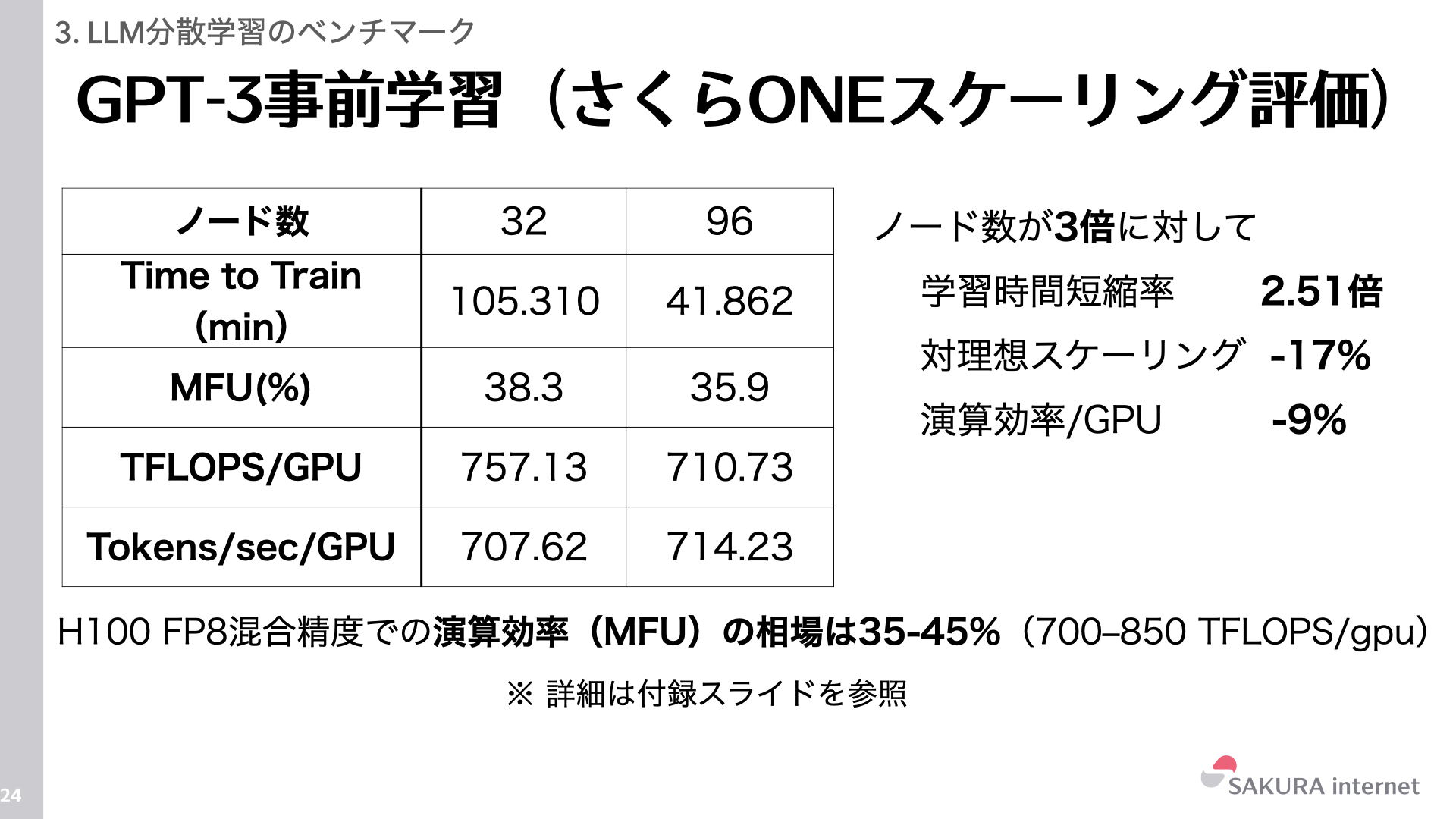
また、GPUあたりの演算効率を示すMFU(Model Flops Utilization)を算出すると、約36〜38%となりました。H100を用いたFP8/BF16混合精度学習におけるMFUの相場は一般的に35〜45%程度と言われており、さくらONEの結果はこの相場の範囲内に収まっています。参考として、様々な文献におけるH100のFP8混合精度学習におけるMFUの値は次の通りです。
- Llama 3.1 70B: MFU 34.96 ~ 36.43% https://catalog.ngc.nvidia.com/orgs/nvidia/teams/dgxc-benchmarking/resources/llama31-70b-dgxc-benchmarking-c (注:記事公開時点ではリンクが切れているのでWeb Archiveでご覧ください)
- Trillion parameter training: MFU 35% https://semianalysis.com/2024/06/17/100000-h100-clusters-power-network/
- Llama 3.1 405B: MFU 43% https://semianalysis.com/2025/08/20/h100-vs-gb200-nvl72-training-benchmarks/
なお、MFUの算出にあたっては、H100のピークFLOPSとして文献で採用されることの多い1,979 TFLOPS(FP8 Tensor Core, Dense)を基準としています(Sparsityありの場合は3,958 TFLOPS)(NVIDIA H100 Tensor Core GPU Datasheetを参照)。これらの比較からも、さくらONEがLLM学習において十分な実用性能を持っていることが確認できました。
パラメータ設定の工夫
96ノード構成において、最も性能が良かったパラメータ設定は以下の通りです。
- TP(テンソル並列)= 8: 通信量が最も多いTPを、サーバー内の高速なNVLinkで完結させるため、GPU搭載数である8以下に設定しました。
- PP(パイプライン並列)= 16
- DP(データ並列)= 6
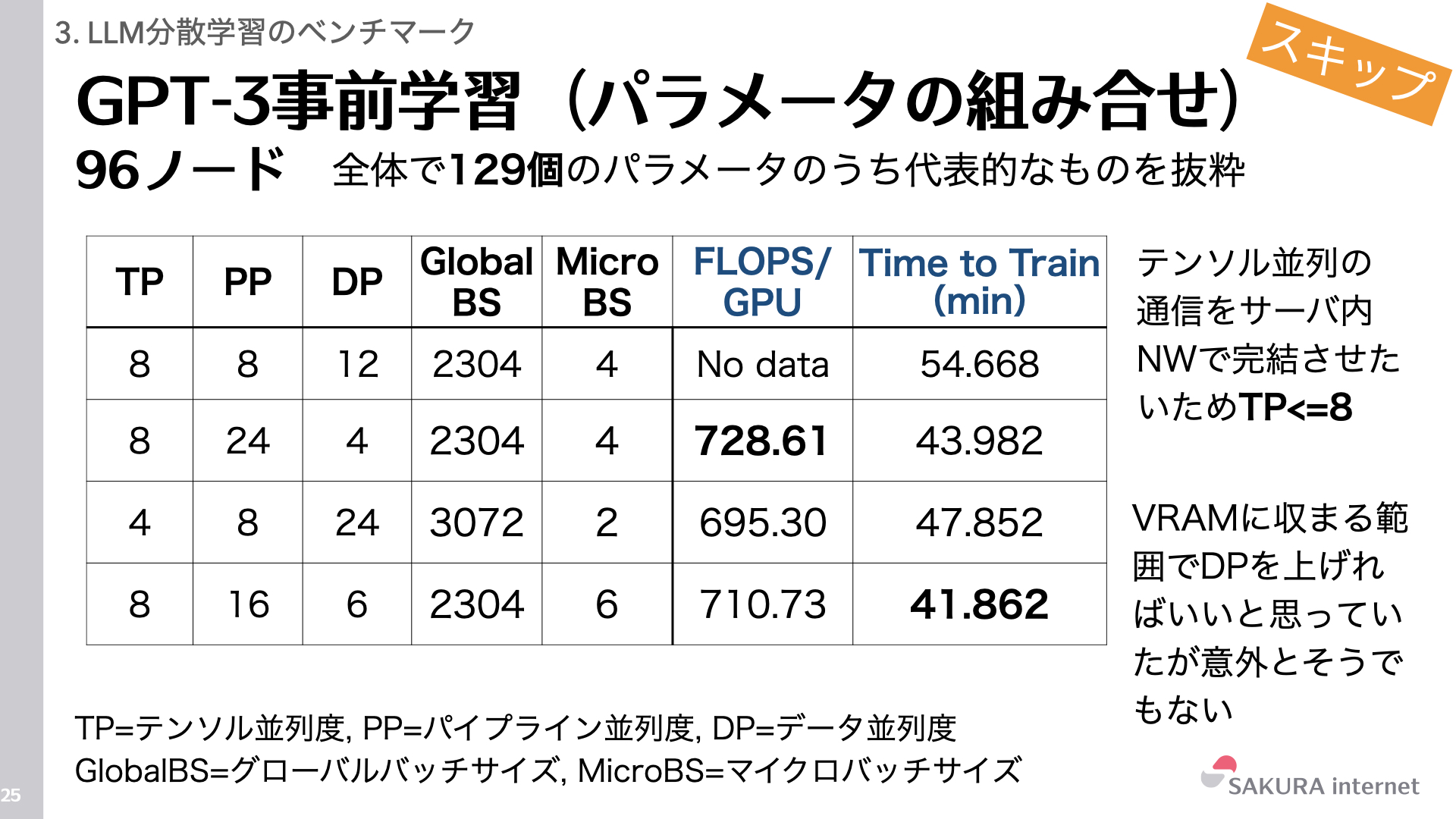
当初の基本戦略は、GPUメモリに収まる範囲でTP+PP数を調整し、DP数を最大化することでしたが、実際にはPP数を増やしたほうが性能が向上する結果となりました。しかしながら、PP数を増やすことにより、パイプラインバブルの影響もまた大きくなっている可能性があり、最適なパラメータを探索する余地がまだあると考えています。
以下の2つの記事では、株式会社フィックスターズさんによる、さくらインターネット提供の高火力PHY H100プランとB200プランを用いたLlama3 70Bの継続事前学習における検証結果が紹介されています。この検証の中でパラメータチューニングの勘所が解説されており、また、パラメータチューニングを自動化するためのサービスであるFixstars AI Boosterも紹介されています。
まとめ
本稿では、LLM学習で必要とされる分散学習やネットワーク技術、ソフトウェアスタックの基本を解説しました。さらに、さくらONEにおけるGPT-3 175B事前学習ベンチマーク実施内容を報告しました。結果として、相場の範囲内の演算効率(MFU 36-38%)を達成することができました。
今後の課題は次の通りです。
- トップダウンアプローチ: アドホックなチューニング方法に依存する試行錯誤だけでなく、モデル構造からメモリ・通信量を理論的に推定し、最適なパラメータの仮説を立てて検証します。
- 自動チューニング: DeepSpeed-Autotuningや、Fixstars社の「AI Booster」などのツール活用により、チューニングの効率化が期待されます。
- オブザーバビリティ: 集団通信の分散トレーシングなど、詳細な分析を行うための環境整備が求められます。オブザーバビリティの詳細については、筆者がObservability Conference Tokyo 2025にて発表した AIスパコン「さくらONE」のオブザーバビリティの資料や録画動画を参照してください。
次回(最終回)は、HPC分野の代表的なベンチマークであるHPLとさくらONEでの計測結果について取り上げます。
なお、さくらインターネットでは、今回ご紹介した「さくらONE」に加え、GPUベアメタルクラウドの「高火力PHY」、GPU仮想マシンの「高火力VRT」、GPUコンテナの「高火力DOK」、そして推論APIサービス「さくらのAI Engine」も提供しています。ぜひご利用ください。
参考文献
全体を通じた参考文献は以下の通りです。
- Konishi, F. "SAKURAONE: Empowering Transparent and Open AI Platforms through Private-Sector HPC Investment in Japan." arXiv:2507.02124 (2025).
- Duan, Jiangfei, et al. "Efficient Training of Large Language Models on Distributed Infrastructures: A Survey." arXiv preprint arXiv:2407.20018 (2024).
- 上野 裕一郎, "PFNにおけるアクセラレータ間通信の実際", MPLS Japan 2024, https://tech.preferred.jp/ja/blog/rdma-in-pfn/.
- 藤井 一喜, "大規模モデルを支える分散並列学習のしくみ Part1", Turing Tech Blog, 2023 https://zenn.dev/turing_motors/articles/0e6e2baf72ebbc.
- 藤井 一喜, ”大規模言語モデルの事前学習知見を振り返る”, Turing Tech Blog, 2023 https://zenn.dev/turing_motors/articles/0f5ac6840f66fe.
- 藤井 一喜, ”GENIAC: 172B 事前学習知見”, tokyotech-llm, 2023 https://zenn.dev/tokyotech_lm/articles/deb8012251bb68.