人工知能フレームワーク入門(第3回):TensorFlowに付属する支援ツール「TensorBoard」を使う
TensorFlowには計算グラフや学習過程を分析するためのツールである「TensorBoard」が付属している。これを利用することで、計算グラフを実際のグラフの形状で表示したり、学習処理の経過によるモデルの変化をグラフで表示するといったことが可能になる。今回はこのTensorBoardについて紹介する。
TensorBoardとは
前回記事ではTensorFlowを使って3層のニューラルネットワークを構築し、画像の分類処理を実行する例を紹介した。本連載では続いてこのニューラルネットワークを発展させた深層学習(ディープラーニング)について解説していく予定だが、その前に少々寄り道して、TensorFlowが備えるいくつかの便利な機能について紹介しておこう。
まず紹介するのは、TensorFlowをインストールすると同時に利用可能になるTensorBoardだ。TensorBoardは学習プロセスやモデルの振る舞いを分析するためのツールであり、次のような機能を備えている。
- 計算グラフをWebブラウザ上に表示する
- 計算グラフ内の変数の変化をWebブラウザ上に表示する
- データをさまざまな形式で表示する
TensorBoardはコマンドラインツール・Webサーバー・Webアプリケーションで構成されており、TensorBoardが実行されているマシンの指定したポート(デフォルトでは6006番ポート)にWebブラウザでアクセスすることにより、GUIで操作が行えるWebアプリケーションを実行できるようになっている。
TensorBoardを利用して計算グラフを表示する
TensorBoardを使った分析を行うには、TensorFlowを利用するプログラム中で事前に対象とする分析データを保存する処理を追加しておく必要がある。まずはTensorBoardを利用する基本的な例として、計算グラフを表示する流れを紹介しよう。
今回使用するサンプルコード(tensorboard_test.py)は、前回紹介した3層のニューラルネットワークによる画像分類処理プログラムをベースとしている。今回のコードが異なるのは、次のようなコードを追加している点だ。
# サマリ情報の出力
summary_writer = tf.summary.FileWriter('./data', graph=sess.graph)
このコードではtf.summary.FileWriterクラスを使用し、TensorFlowで使用する情報をログファイルに出力する処理を行っている。tf.summary.FileWriter()の第1引数にはログファイルの出力先ディレクトリを、第2引数にはログに出力する計算グラフを指定する。今回はセッションオブジェクトのgraphプロパティを指定することで、定義されている全計算グラフに関する情報がログファイルに出力されるようにしている。
このプログラムを実行すると、実行完了後にカレントディレクトリ内にdataディレクトリが作成され、そこにログファイルが出力される。その状態で、次のようにログディレクトリ(今回は「./data」)を指定してtensorboardコマンドを実行する。
$ tensorboard --logdir=./data W0117 20:33:32.279742 Reloader tf_logging.py:86] Found more than one graph event per run, or there was a metagraph containing a graph_def, as well as one or more graph events. Overwriting the graph with the newest event. W0117 20:33:32.281260 Reloader tf_logging.py:86] Found more than one metagraph event per run. Overwriting the metagraph with the newest event. TensorBoard 0.4.0rc3 at http://localhost.localdomain:6006 (Press CTRL+C to quit)
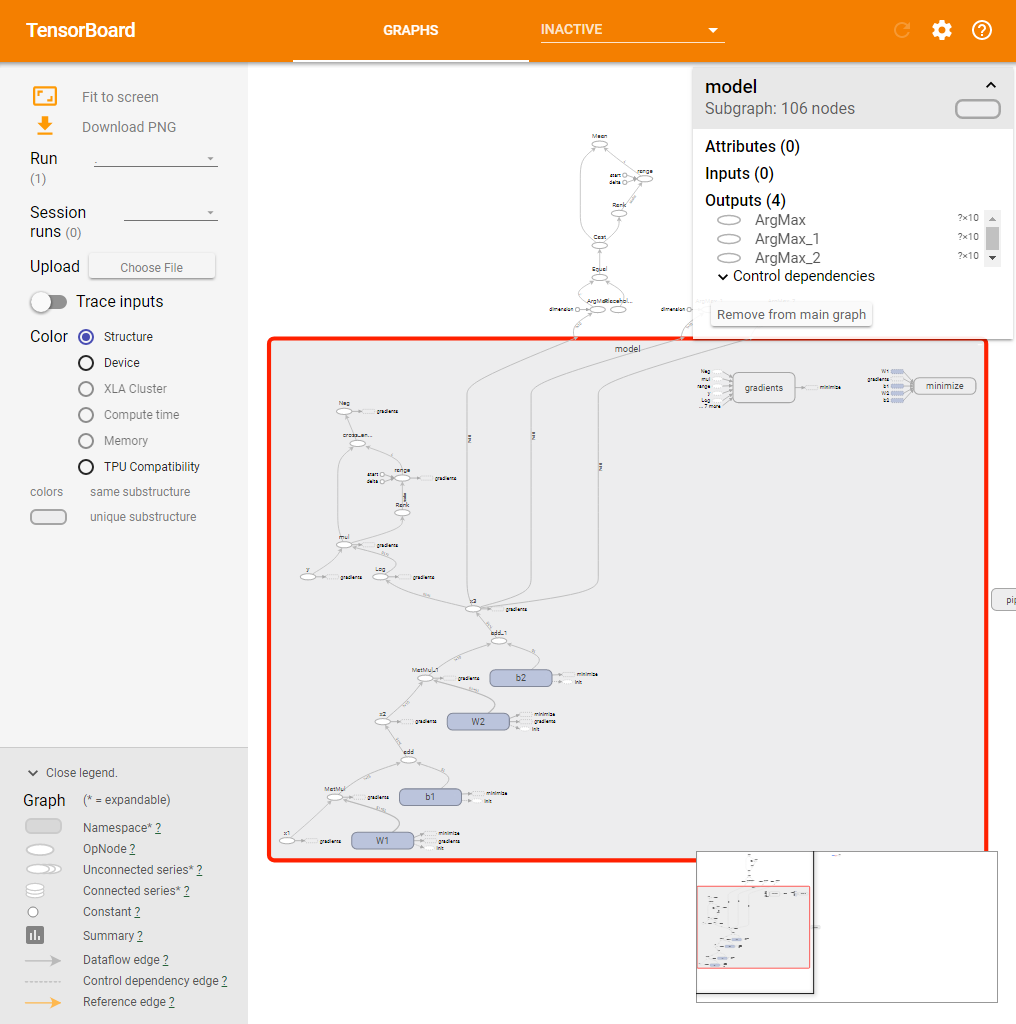
続いてWebブラウザでTensorBoardを実行しているマシンの6006番ポートにアクセスすると、次のような画面が表示される(図1)。
この画面からは、たとえば「x1」というプレースホルダと変数「W1」の積を求め(MatMul)、続いてそれに変数「b1」を加算(add)したものがx2となる、といった計算グラフの情報を確認できる。また、最急降下法アルゴリズムを実装したtf.train.GradientDescentOptimizerクラスによってコスト関数を最小化する処理が計算グラフに追加されていることも確認できる。
ここでグラフのノードをクリックすると、そのノードに関する情報が表示される(図2)。
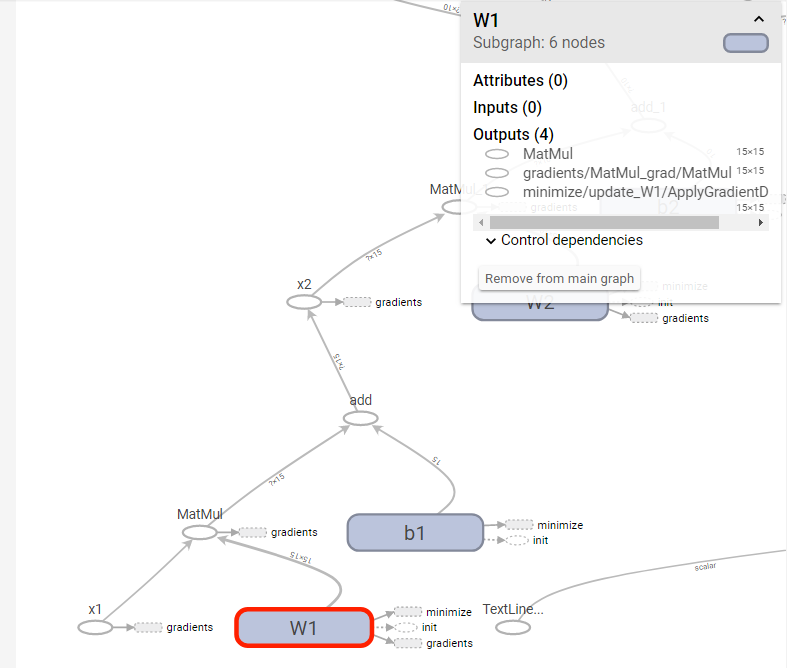
図2の例は「W1」をクリックした場合のものだ。ここから、たとえばW1の値は4つのノードに出力されている、といった情報が確認できる。
グラフを見やすく整理する
TensorFlowには変数の名前空間(namespace)を定義する機能があり、これを利用することで変数を名前空間毎に分離することができる。たとえば次の例は、モデル部分を「model」という名前空間に分離したものだ(tensorflow_test2.py)。
with tf.variable_scope('model') as scope:
# 入力
x1 = tf.placeholder(dtype=tf.float32, name="x1")
y = tf.placeholder(dtype=tf.float32, name="y")
# 第2層
tf.set_random_seed(1234)
W1 = tf.get_variable("W1",
shape=[INPUT_SIZE, W1_SIZE],
dtype=tf.float32,
initializer=tf.random_normal_initializer(stddev=0.05))
b1 = tf.get_variable("b1",
shape=[W1_SIZE],
dtype=tf.float32,
initializer=tf.random_normal_initializer(stddev=0.05))
x2 = tf.sigmoid(tf.matmul(x1, W1) + b1, name="x2")
# 第3層
W2 = tf.get_variable("W2",
shape=[W1_SIZE, OUTPUT_SIZE],
dtype=tf.float32,
initializer=tf.random_normal_initializer(stddev=0.05))
b2 = tf.get_variable("b2",
shape=[OUTPUT_SIZE],
dtype=tf.float32,
initializer=tf.random_normal_initializer(stddev=0.05))
x3 = tf.nn.softmax(tf.matmul(x2, W2) + b2, name="x3")
# コスト関数
cross_entropy = -tf.reduce_sum(y * tf.log(x3), name="cross_entropy")
# 最適化アルゴリズムを定義
optimizer = tf.train.GradientDescentOptimizer(0.01, name="optimizer")
minimize = optimizer.minimize(cross_entropy, name="minimize")
このように、「with tf.variable_scope(<名前空間名>) as scope:」という形でブロックを作ると、そのブロック内で宣言された変数については指定した名前空間内に割り当てられるようになる。
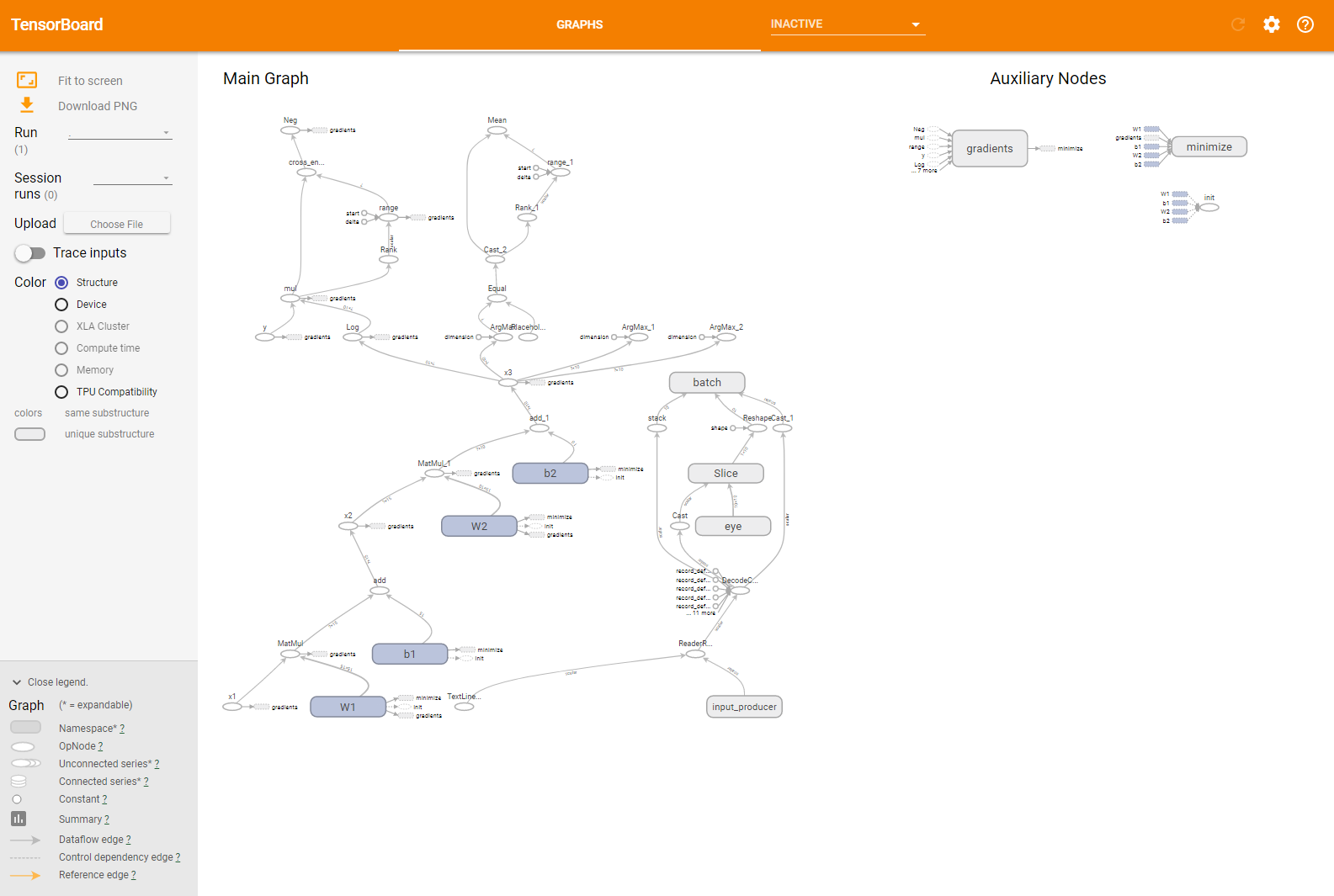
この名前空間による分類は、TensorBoardでの表示にも反映される(図3)。
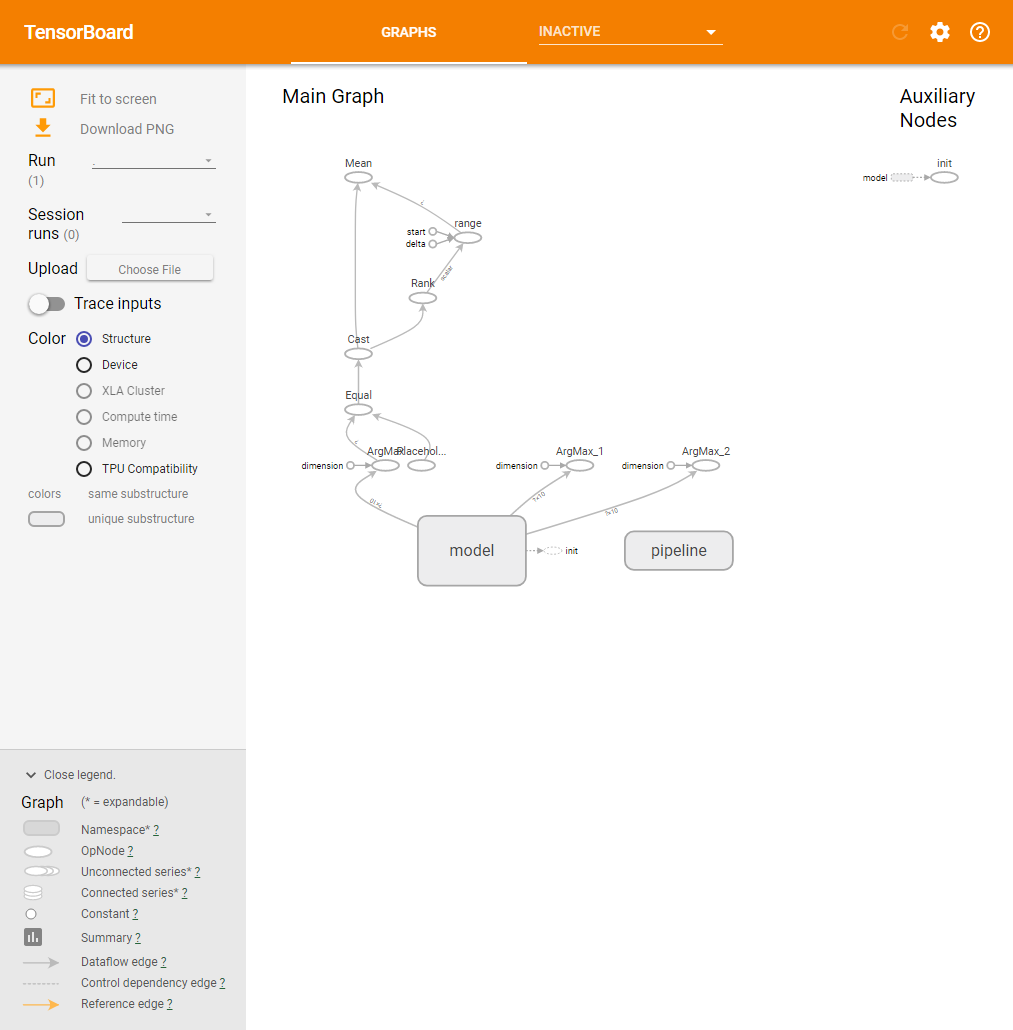
今回のコードでは、モデル部分を「model」という名前空間で、データセットを読み出すためのパイプライン部分を「pipeline」という名前空間で宣言している。その結果、TensorBoardでの計算グラフの表示はこのように簡潔なものになる。
また、ここで「Model」部分をクリックするとその中身を確認できる(図4)。
ちなみに、ここで表示されている「gradients」や「minimize」も名前空間であり、クリックすることでその中身を確認可能だ。
変数の値の変化をグラフ表示する
TensorBoardのもう一つの機能が、計算グラフ内の変数の値をグラフで表示するというものだ。これは、学習処理を繰り返し実行する間にパラメータがどのように変化するかを確認したい場合などに便利だ。
この機能を利用するには、事前にプログラム中で対象とするノードを登録しておく必要がある。手順としては次のようになる。
まず、学習のための反復処理を何回行ったのかを記録する「global_step」と呼ばれる変数を定義し、これをoptimizerのminize()メソッドの引数に与えて登録しておく(tensorboard_test3.py)。
# 最適化アルゴリズムを定義
global_step = tf.Variable(0, name='global_step', trainable=False)
optimizer = tf.train.GradientDescentOptimizer(0.01, name="optimizer")
minimize = optimizer.minimize(cross_entropy, global_step=global_step, name="minimize")
このように登録しておくことで、minimizeが一回実行されるたびにglobal_step変数の値が1ずつ増えるようになる。
続いて、tf.summary.scalar()関数で記録対象とする変数を登録する。たとえば最小化の対象となる「cross_entropy」の値を確認したい場合、次のようにする。
# コスト関数
cross_entropy = -tf.reduce_sum(y * tf.log(x3), name="cross_entropy")
tf.summary.scalar('cross_entropy', cross_entropy)
記録対象の変数は複数を登録できるので、今回はcross_entropy変数に加えて、正答率も同時に記録してみよう。この場合、次のように正答率を求める計算グラフを定義し、それを同様にtf.summary.scalar()で登録する。
# 正答率
correct = tf.equal(tf.argmax(x3,1), tf.argmax(y,1), name="correct")
accuracy = tf.reduce_mean(tf.cast(correct, "float"), name="accuracy")
tf.summary.scalar('accuracy', accuracy)
最後に適当なタイミングでこれらのデータを出力するメソッドを実行すれば良いのだが、これら統計のためのデータに関する計算グラフを個別に実行するのは面倒だ。そこで、tf.summary.merge_all()メソッドを利用して登録しておいた変数に対するサマリ情報をまとめておく。また、出力を行うためのtf.summary.FileWriterクラスのインスタンスも作成しておく。
# セッションの作成
sess = tf.Session()
# 変数の初期化を実行する
sess.run(tf.global_variables_initializer())
# サマリを取得するための処理
summary_op = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter('data', graph=sess.graph)
あとは、学習の実行時に適当な周期でtf.summary.merge_all()で得たテンソルを実行して実際の値を収集し、その結果をデータの出力を行うadd_summary()メソッドに渡して実行すれば良い。なお、add_summary()メソッドの第2引数にはステップ数を指定する。ここでは、global_stepの値を取得するtf.train.global_step()メソッドを利用している。
# 学習を開始
for i in range(100):
for j in range(100):
_, summary = sess.run([minimize, summary_op], {x1: dataset_x, y: dataset_y})
print("CROSS ENTROPY:", sess.run(cross_entropy, {x1: dataset_x, y: dataset_y}))
summary_writer.add_summary(summary, global_step=tf.train.global_step(sess, global_step))
このコードを実行した後TensorBoardを起動すると、「SCALARS」画面で記録したデータのグラフを確認できる(図5)。今回の例では、指定した2つの変数についてステップ数に応じた変化がグラフで表示される。
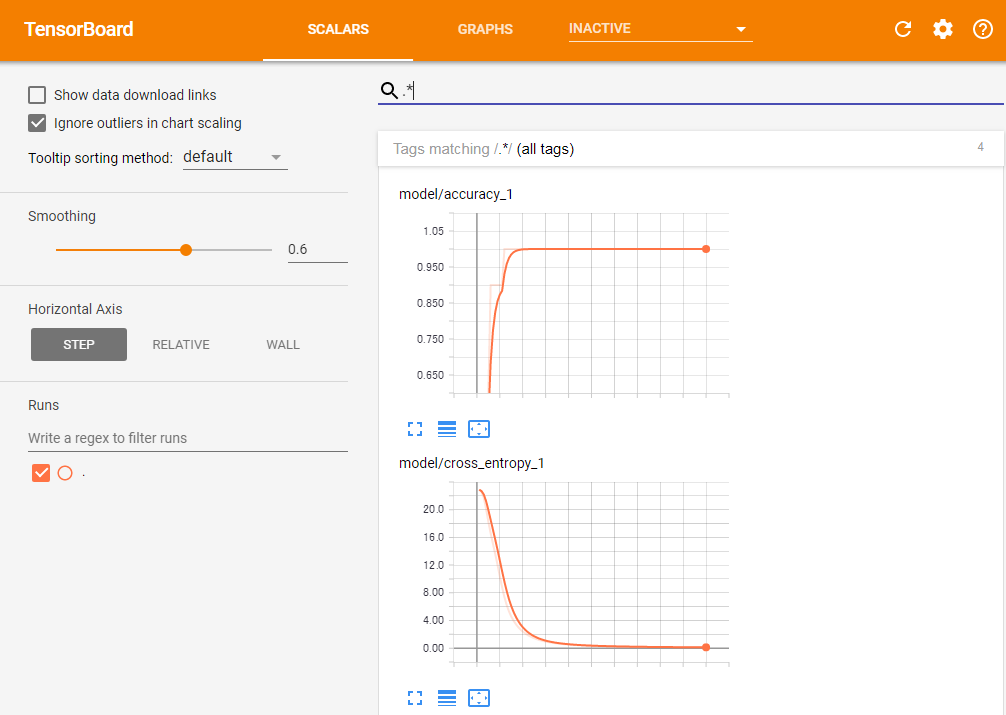
このグラフでは、横軸の1目盛りが1000回の試行を示している。ここから、学習データに対する正答率は2000回程度の試行で100%となり、またクロスエントロピーについては5000回程度の試行でほぼ収束していることが分かる。
ヒストグラム形式でグラフを表示する
TensorFlowでは単純なグラフだけでなく、分布図(ヒストグラム)形式でデータを視覚化することもできる。これは、単純なスカラー値ではなく、ベクトルや行列のような多次元データを分析する場合に便利だ。
たとえば、第1層と第2層の結合重みであるW1の値を確認したい場合、次のようにW1の定義後にtf.summary.histogram()関数を使ってその変数を登録する(tensorbaord_test4.py)。
# 第2層
tf.set_random_seed(1234)
W1 = tf.get_variable("W1",
shape=[INPUT_SIZE, W1_SIZE],
dtype=tf.float32,
initializer=tf.random_normal_initializer(stddev=0.05))
b1 = tf.get_variable("b1",
shape=[W1_SIZE],
dtype=tf.float32,
initializer=tf.random_normal_initializer(stddev=0.05))
x2 = tf.sigmoid(tf.matmul(x1, W1) + b1, name="x2")
# W1のヒストグラムを記録
tf.summary.histogram('W1', W1)
プログラムを実行して学習を行い、続いてTensorBoardを起動すると、新たに「HISTOGRAMS」という項目が増えていることが確認できる(図6)。
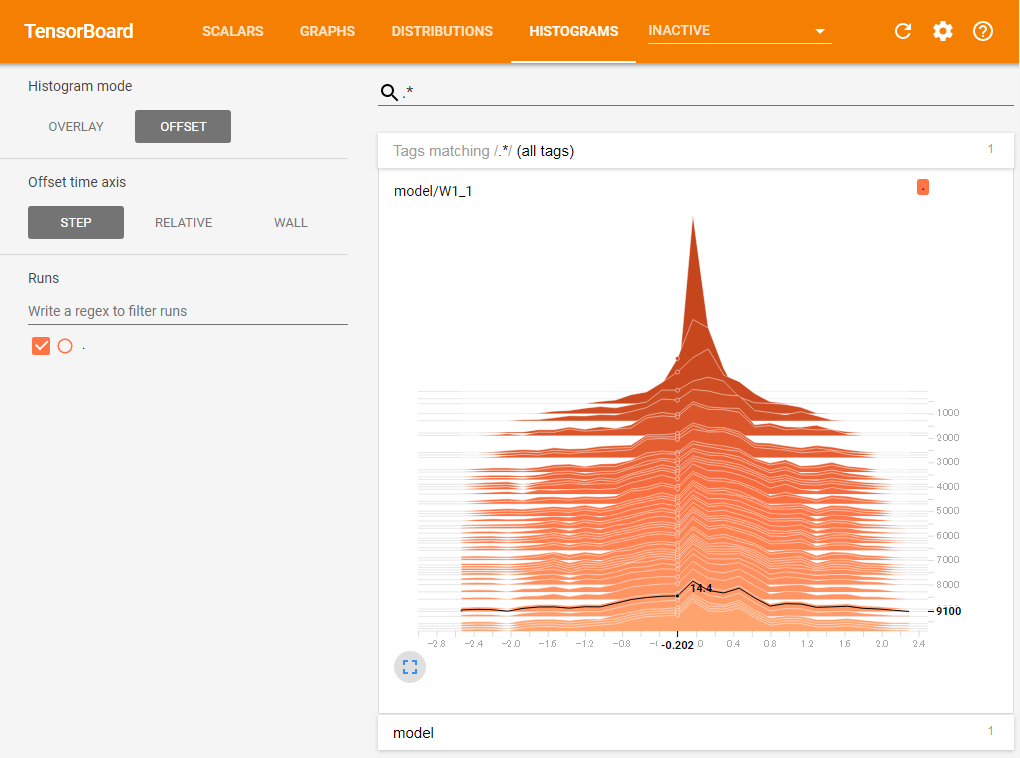
このグラフは擬似的な3次元グラフになっており、手前方面(色が薄いもの)ほど新しいデータとなる。横軸方向はデータの値、縦軸方向はその出現頻度を表しており、たとえばこの例では最初はW1の各要素の値は0付近に集中していたものが、学習が進むにつれて-2.4から2.0前後にまで分散していくことが分かる。
また、ヒストグラムを記録すると同時にそのデータの分散を示すグラフも作成される。これは「DISTRIBUTIONS」項目で確認が可能だ(図7)。
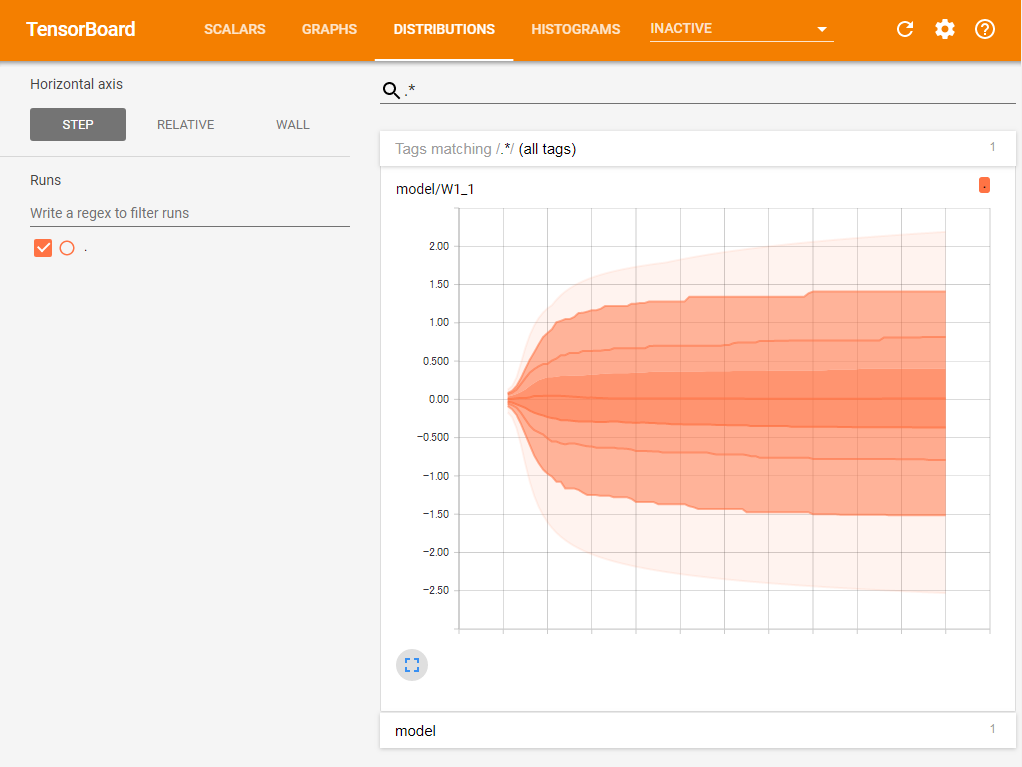
ここでは、ヒストグラムと同様に色の薄いものほど新しいグラフとなる。ここでは、学習が進むにつれてW1の各要素の値の分散が広まっていることが分かる。
学習状況をファイルに保存する
TensorBoardの話とは直接関係はないが、TensorFlowを使った学習プログラムにおいて、学習状況をファイルに保存しておく方法についても紹介しておこう。
今回のサンプルプログラムはシンプルなものであるため学習に必要な時間は少ないが、モデルが複雑になったり学習に使用するサンプル数が増えると、学習にかかる時間も増えていく。そういった場合は学習の途中経過をファイルに保存できるようにしておくと、途中で学習処理を中断した場合でもその続きから学習を再開できるようになり便利だ、また、学習の結果得られたモデルのパラメータを保存しておいて別のプログラムで使いたい、といったケースもあるだろう。
TensorFlowではそういった用途に向けて、計算グラフの状態をファイルに保存したり、それらを読み込んで計算グラフを復元するためのtf.train.Saverというクラスが用意されている。
tf.train.Saverクラスを使って計算グラフの状態を保存するには、まず計算グラフの定義後にtf.train.Saverクラスのインスタンスを作成する。
# 学習結果を保存するためのオブジェクトを用意 saver = tf.train.Saver()
tf.train.Saverクラスでは、インスタンスの作成時点で定義されている計算グラフが保存対象となる。続いて学習などの作業を行い、save()メソッドを実行することで計算グラフの状態がファイルに出力される。このメソッドの第1引数にはセッションオブジェクトを、第2引数には出力するファイル名を指定する。第3引数にはオプションで反復数を示す値(global_step)を指定でき、これを指定するとファイル名の後に「-<global_stepの値>」という接尾辞が付けられる。
# 結果を保存する
save_path = saver.save(sess, "./model", global_step=tf.train.global_step(sess, global_step)))
print("Model saved to {}".format(save_path))
save()メソッドは戻り値としてファイルを出力したパスを返すので、ここではそれを標準出力に出力している。
ファイルに保存しておいたモデル情報を復元するにはrestore()メソッドを使用する。こちらも第1引数にはセッションオブジェクト、第2引数には読み込むファイルのパスを指定する。
ちなみに、最後に保存されたモデルのファイル名はtf.train.latest_checkpoint()関数で取得できる。もしファイルが存在する場合のみデータを読み込むには、次のようにする。
# 学習結果を保存したファイルが存在するかを確認し、
# 存在していればそれを読み出す
latest_filename = tf.train.latest_checkpoint("./")
if latest_filename:
print("load saved model {}".format(latest_filename))
saver.restore(sess, latest_filename)
さて、これらの高速化手法や、モデルの保存・復元機能を実装したプログラムがtensorboard_test5.pyだ。このプログラムを実行すると、学習処理の完了後にモデルの情報を「model-10000.data-00000-of-00001」および「model-10000.index」、「model-10000.meta」というファイルに保存する。また、同時に保存した情報を管理する「checkpoint」というファイルも作成される。この状態で再度このプログラムを実行すると、前回終了時の状態から学習が再開され、完了後にはその結果を「model-20000.data-00000-of-00001」および「model-20000.index」、「model-20000.meta」というファイルに出力する。
次回予告
今回はTensorFlowに備えられている分析ツールであるTensorBoardの使い方と、モデルの保存方法について紹介した。次回は、TensorFlowが推奨する学習用データフォーマットである「TFRecord」について紹介する。