人工知能フレームワーク入門(第4回):TensorFlowのデータフォーマット「TFRecord」を使う

TensorFlowでは、学習などに使用するデータを読み書きするための「TFRecord」というデータフォーマットが用意されている。今回はこのTFRecordを使って学習データを準備したり、TFRecord形式のデータを読み込む方法を紹介する。
目次
学習データなどの保管用フォーマット「TFRecord」
前回までの記事ではTensorFlowを使って3層のニューラルネットワークを実装し、簡単な画像認識処理を行わせていた。これらでは学習に使用するデータを表計算ソフトなどで使われているCSV(カンマ区切りテキスト)形式で準備し、学習時にはテキスト形式でデータを読み込んだあと、パース処理を行ってリスト形式のデータに変換していた。しかし、学習に使用するデータが大規模になるとCSV形式では扱いにくくなるほか、TensorFlowでCSVファイルを読み出してパースする処理はやや冗長だ。そのため、より大規模なデータを扱うようなアプリケーションではバイナリ形式で学習データを用意することをおすすめする。その際に推奨されるのが、「TFRecord」と呼ばれるデータ形式だ。
TFRecordはProtocol Buffersと呼ばれるプラットフォーム非依存のデータシリアライズ技術をベースに実装されている。Protocol Buffersでは独自の言語でデータ形式を宣言したファイル(.protoファイル)を用意し、それをコンパイラで指定した言語向けのコードに変換するという仕組みになっている。そのため、作成したデータはPythonだけでなくさまざまな言語で利用できる。
TensorFlowではこのTFRecord形式でデータを読み書きするためのモジュールが提供されており、簡単にデータを読み書きできるようになっている。さらに、Dataset APIと呼ばれるAPIと組み合わせることで、学習時には簡潔なコードでデータの読み出しや変形を行う処理を実装できる。
たとえば強化学習においては学習データからランダムに一定数のデータを取り出すといった操作が求められることがあるが、TFRecordとDataset APIを利用することでこういった処理が容易に実装できるようになる。
TFRecordの使い方
TensorFlowでTFRecordを利用してデータを読み込みたい場合、まずは事前に画像など必要なデータファイルをTFRecord形式のファイルに変換しておく必要がある(図1)。
現状では画像などの学習データをTFRecordに変換するツールなどは用意されていないため、独自に学習データをTFRecord形式に変換するツールを用意する必要がある。Pythonではさまざまな形式のデータを扱えるライブラリが用意されているため、対象とするデータの形式さえ把握できていればこのような変換処理の実装は難しくない。TensorFlowにも画像データを扱うためのAPIが用意されており、これらを利用することもできる。
また、TFRecordでは複数の学習データを1つのファイルにまとめることも可能だ。もちろんデータ数に応じてファイルサイズは大きくなるものの、これによって学習時のデータファイルの管理が容易になるというメリットがある(図2)。

TFRecordを利用する際の注意点
続いて、TFRecordの制限についても説明しておこう。TFRecordの現時点での最新APIであるAPI r1.4では、次の3つのデータ型のみがサポートされている。
- int64
- float
- bytes
「int64」は64ビットの符号付き整数、「float」は32ビットの単精度浮動小数点、「bytes」はバイト列だ。これ以外のデータ型をTFRecordファイルに格納したい場合、これら3つのどれか(一般的にはbytes型)にキャストして格納する必要がある。
また、前述のとおり1つのTFRecordファイルには複数のデータを格納することが可能だが、その場合各データは同じ形式である(同一のデータ要素を持つ)必要がある。たとえば1つのTFRecordファイルに2つ以上の画像データを格納する、といったことは可能だが、たとえば10個の画像と20個のテキストデータを格納する、といった使い方をしようとするとコードが複雑になってしまう。
JPEG画像をTFRecord形式に変換する
それでは、例として指定したディレクトリ内にあるJPEG画像を1つのTFRecordファイルにまとめて格納する、というプログラムを紹介しよう。
このプログラム(convert_tfr.py)では、次のような形式で指定したディレクトリ内のJPEGファイルを読み込み、指定したサイズにリサイズしてTFRecord形式で指定した出力ファイルに格納する。また、このとき画像データとともに整数(int)形式で指定したラベルもファイル内に格納される。対象とするディレクトリは複数が指定できる。
convert_tfr.py <リサイズ後の幅>x<リサイズ後の高さ> <ラベル> <出力ファイル名> <対象とするディレクトリ1> [<対象とするディレクトリ2> ...]
次の例は、「./cat」というディレクトリ内にある複数のJPEG画像を100×100サイズに変換して「0」というラベルを付け、「teach_cat.tfrecord」というTFRecord形式ファイルに出力するものだ。
$ ./convert_tfr.py 100x100 0 teach_cat.tfrecord ./cat
TensorFlowを使った画像の読み出し・デコード・変換処理
このプログラムでは、画像のリサイズ処理を行うための計算グラフを定義する_create_comp_graph()関数と、メインの処理を実行するmain()関数の2つが定義されている。
まず_create_comp_graph()関数だが、ここではpathnameという名前を持つプレースホルダで画像ファイルのパス名を受け取り、そのファイルを読み込んでリサイズして出力する、という計算グラフを定義している。具体的には、まず与えられた画像ファイルをtf.read_file()で読み出し、これをtf.image.decode_jpeg()を使ってデコードする。
# 指定したファイルを読み出して指定したサイズにリサイズする
def _create_comp_graph(width, height):
filepath = tf.placeholder(tf.string, name="pathname")
content = tf.read_file(filepath)
raw_image = tf.image.decode_jpeg(content, channels=3)
# raw_imageのデータ型はuint8
tf.image.decode_jpeg()はuint8(符号なし8ビット整数)形式のテンソルでデコードされた画像を出力するもので、出力されたテンソルの1つめのインデックスが高さ、2つめのインデックスが幅、3つめのインデックスがR/G/B各チャンネルに該当する。
続いて、指定したサイズに収まるよう画像を変形する処理を実行する。これは、図3のような処理となる。

まず、画像のリサイズを行うため、tf.shape()を使って取得したテンソルの形状を求める。これは、読み込んだ画像の高さと幅、チャンネル数に相当する。
# 画像のサイズを[height, width, channels]の形で取得
shape = tf.shape(raw_image)
raw_height = tf.to_float(tf.slice(shape, [0], [1]))
raw_width = tf.to_float(tf.slice(shape, [1], [1]))
続いて取得した画像サイズの縦横比と出力する画像サイズの縦横比を比較し、出力する画像サイズ内に収まるよう取得した画像を縦横比を変えずにリサイズする。ここでは、tf.cond()を使って条件分岐を行っている。tf.cond()では、第1引数の値がTrueであれば第2引数で与えた処理、Falseであれば第3引数で与えた処理を返すような計算グラフを構築できる。
# 画像サイズと出力サイズのアスペクト比を比較し、
# 画像サイズのほうが大きければ高さを、
# 小さければ幅を出力サイズにそろえるよう
# 拡大縮小比を求める
# 幅/高さは整数(int)型データなので、適宜float型に変換する
aspect_ratio = float(height) / width
raw_aspect_ratio = raw_height / raw_width
scale = tf.cond(tf.reduce_any(raw_aspect_ratio > [aspect_ratio]),
lambda: [height] / raw_height,
lambda: [width] / raw_width
)
# 求めた比率で画像をリサイズする
# resized_imageはfloat32型となる
new_size = tf.to_int32(tf.concat([raw_height, raw_width], 0) * scale)
resized_image = tf.image.resize_images(raw_image, new_size)
また、tf.concat()は第1引数で与えたテンソルを結合して新たなテンソルを作成するもの、tf.image.resize_imagesは第1引数で指定した画像を第2引数で指定したサイズにリサイズするものだ。
さて、上記の処理では画像の縦横比を変えずにリサイズを行っているため、この時点で出力される画像は幅方向もしくは高さ方向のどちらかが指定したサイズよりも小さい可能性がある。そこで、 最後にtf.image.resize_image_with_crop_or_pad()を使ってパディングを行う(余白に0を入れる)ことで、指定したサイズの画像に変換する。
# 余白を0で埋めて指定したサイズにそろえる
padded_image = tf.image.resize_image_with_crop_or_pad(
resized_image,
height,
width
)
return (filepath, padded_image)
続いて、メインの処理を行っているmain()関数について見ていこう。この関数の前半部分は、Pythonの標準モジュールであるargparseを使って引数のパースを行っている。
def main():
# 引数をパースする
p = argparse.ArgumentParser(description='convert images to TFRecord format')
p.add_argument('dimension',
type=lambda x: [int(r) for r in x.split("x")],
help='image dimension. example: 10x10')
p.add_argument('label',
type=int,
help='label.')
p.add_argument('output',
#type=argparse.FileType('w'),
help='output file')
p.add_argument('target_dir',
nargs='+',
help='target directory')
args = p.parse_args()
if len(args.dimension) != 2:
raise argparse.ArgumentTypeError("dimension must be <num>x<num>")
次に、先に説明した_create_comp_graph()関数を呼び出して計算グラフを構築する。
# 計算グラフを構築する
(width, height) = args.dimension
(filepath, padded_image) = _create_comp_graph(width, height)
TFRecord形式でのデータの書き出し
TFRecord形式でデータを書き出すには、まずtf.python_io.TFRecordWriterというクラスのインスタンスを作成する。ここで、引数には出力ファイルのパス名を指定する。
# 出力先の用意
writer = tf.python_io.TFRecordWriter(args.output)
続いて計算グラフを利用するためのセッションを起動し、計算グラフにファイル名を与えてファイルの読み出しと変形を実行する。
# セッションを実行
sess = tf.Session()
# 指定したディレクトリ内のファイルを列挙する
for dirname in args.target_dir:
for filename in os.listdir(dirname):
pathname = os.path.join(dirname, filename)
print("process {}...".format(pathname))
try:
image = sess.run(padded_image, {filepath: pathname})
except tf.errors.InvalidArgumentError:
# 読み込みに失敗したらメッセージを出力して継続する
print("{}: invalid jpeg file. ignored.".format(pathname))
continue
ここでは、引数として与えられたディレクトリ内のファイル一覧を取得し、そこに含まれているファイルの名前を与えて計算グラフを実行するという処理をforループを使って繰り返し実行している。計算グラフを実行すると、sess.run()の戻り値として画像データを含む配列が返される。続いてこの配列をTFRecord形式で出力する処理を行う。
TFRecord形式での出力には、どのような形式のデータを扱うかをtf.train.Featuresクラスを使って定義しておく必要がある。これは、インスタンスの生成時に引数として辞書型のデータを与えることで行う。この辞書には扱うデータのラベル(名称)をキー、それに対応するデータを次のいずれかのクラスのインスタンスとして格納しておく。
これらクラス名から分かるとおり、int64形式のデータを格納するにはtf.train.Int64List、float32形式のデータを格納するにはtf.train.FloatList、bytes形式のデータを格納するにはtf.train.BytesListを使用する。今回はラベルおよび画像の幅、高さがint型、画像データがfloat32型なので、次のように定義した。
features = tf.train.Features(feature={
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[args.label])),
'height': tf.train.Feature(int64_list=tf.train.Int64List(value=[height])),
'width': tf.train.Feature(int64_list=tf.train.Int64List(value=[width])),
'raw_image': tf.train.Feature(float_list=tf.train.FloatList(value=image.reshape(width*height*3))),
})
なお、tf.train.Int64List()やtf.train.FloatList()、tf.train.BytesList()の引数には1次元のリスト(配列)を与える必要がある。画像データが格納されているimage変数は3次元のリスト(正確にはnumpy.ndarrayオブジェクト)になっているので、ここではこれをreshape()メソッドで1次元のリストに変換している。
ちなみに、int64もしくはfloat32以外のデータを格納したい場合、numpy.ndarryクラスのtobytesメソッドを利用すればbytes型のデータが得られるので、これをtf.train.ByteList()に与えれば良い。たとえば画像データをbytes型で保存するには、次のようにする。
'raw_image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image.tobytes()]))
さて、データを実際にファイルに出力するには、tf.train.Exampleというクラスを作成し、これをシリアライズしたものを与えてtf.python_io.TFRecordWriterクラスのwrite()メソッドを実行する。tf.train.Exampleクラスは単にtf.train.Features型のプロパティを持つだけのラッパーで、インスタンス生成時にfeaturesプロパティの値を設定する。
example = tf.train.Example(features=features)
writer.write(example.SerializeToString())
書き込みがすべて完了したら、最後にtf.python_io.TFRecordWriterクラスのclose()メソッドを実行する。
# 終了
writer.close()
print("done")
TFRecord形式で保存したデータを使った学習処理
続いて、TFRecord形式で保存したデータを読み込む例を紹介しよう。紹介するコードは、前回解説した3層のニューラルネットワークを使用した画像認識プログラムだ。
今回はまずインターネットで公開されているさまざまな猫、犬、猿の画像を集めたものを入力データとして学習を行い、それとは別の画像データを入力して分類を試みる。画像データは説明したconvert_tfr.pyプログラムを使って100×100サイズにリサイズし、猫、犬、猿毎にTFRecord形式のファイルとして事前に保存しておく。学習用のデータはそれぞれ200件、テスト用のデータは50件とした。それぞれのデータは次のようにして生成している。
./convert_tfr.py 100x100 0 teach_cat.tfrecord <学習用猫画像が入ったディレクトリ> ./convert_tfr.py 100x100 1 teach_dog.tfrecord <学習用犬画像が入ったディレクトリ> ./convert_tfr.py 100x100 2 teach_monkey.tfrecord <学習用猿画像が入ったディレクトリ> ./convert_tfr.py 100x100 0 test_cat.tfrecord <テスト用猫画像が入ったディレクトリ> ./convert_tfr.py 100x100 1 test_dog.tfrecord <テスト用犬画像が入ったディレクトリ> ./convert_tfr.py 100x100 2 test_monkey.tfrecord <テスト用猿画像が入ったディレクトリ>
学習・テストに使用するプログラムで使用するモデルは、基本的には前回説明したものと同じだ。ただし、入力画像がRGBカラー(3チャンネル)、100×100サイズになっているため、入力層のノード数は3×100×100=30000になっている。また、入力数の増加に合わせて中間層(第2層)のノード数は200に設定した。今回は猫、犬、猿の3種類の分類であるため、出力層(第3層)のノード数は3だ(neural_lerning.py)。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import tensorflow as tf
INPUT_WIDTH = 100
INPUT_HEIGHT = 100
INPUT_CHANNELS = 3
INPUT_SIZE = INPUT_WIDTH * INPUT_HEIGHT * INPUT_CHANNELS
W1_SIZE = 200
OUTPUT_SIZE = 3
LABEL_SIZE = OUTPUT_SIZE
TEACH_FILES = ["../data2/teach_cat.tfrecord",
"../data2/teach_dog.tfrecord",
"../data2/teach_monkey.tfrecord"]
TEST_FILES = ["../data2/test_cat.tfrecord",
"../data2/test_dog.tfrecord",
"../data2/test_monkey.tfrecord"]
MODEL_NAME = "./neural_model"
前回コードと異なるのが、TFRecordを使ってデータセットを読み込む部分だ。TFRecordを使ってデータを読み込むには、まずデータのマッピング(変換)を行う関数を定義する。この関数にはシリアライズされた状態の1件分のデータが引数として与えられ、変換後のデータを戻り値として返す。今回与えた関数は次のようなものだ。
# 読み込んだデータの変換用関数
def map_dataset(serialized):
features = {
'label': tf.FixedLenFeature([], tf.int64),
'height': tf.FixedLenFeature([], tf.int64),
'width': tf.FixedLenFeature([], tf.int64),
'raw_image': tf.FixedLenFeature([INPUT_SIZE], tf.float32),
}
parsed = tf.parse_single_example(serialized, features)
# 読み込んだデータを変換する
raw_label = tf.cast(parsed['label'], tf.int32)
label = tf.reshape(tf.slice(tf.eye(LABEL_SIZE),
[raw_label, 0],
[1, LABEL_SIZE]),
[LABEL_SIZE])
image = parsed['raw_image']
return (image, label, raw_label)
ここではTFRecord形式での出力の場合と同様にデータ型をfeaturesというオブジェクトで定義し、それをtf.parse_single_example()関数で取り出している。この関数では、各データをキーとする辞書が戻り値として返される。たとえば今回の場合学習データに与えたラベルは「label」、画像データ本体は「raw_image」というキーでアクセスできる。
なお、tf.parse_single_example()で取り出した値はint64もしくはfloat32、bytesのいずれかの形式の1次元配列となっている。そのため、必要に応じて適切な形に変更する必要がある。今回の例では画像データをfloat形式で保存しているため変換処理は必要ないが、たとえば画像データをbytes形式に変換して保存していた場合、次のようにtf.decode_rawメソッドでデータをデコードする必要がある。
features = {
'label': tf.FixedLenFeature([], tf.int64),
'height': tf.FixedLenFeature([], tf.int64),
'width': tf.FixedLenFeature([], tf.int64),
'raw_image': tf.FixedLenFeature([], tf.string),
}
parsed = tf.parse_single_example(serialized, features)
# 読み込んだデータを変換する
image = tf.decode_raw(parsed['raw_image'], tf.float32)
:
:
この関数はあくまでデータをどう読み出すかを定義するだけのもので、実際にデータを読み出すにはtf.data.TFRecordDatasetクラスを使用する。まずこのクラスの引数にファイル名、もしくはファイル名を含むリストを与えてインスタンスを作成し、次にそのインスタンスに対してデータの取り出し方法や変換を行うメソッドを実行して各種設定を行う。
今回はデータのマッピングを行う関数を指定するmap()メソッドと、1回に取り出すデータの数を指定するbatch()メソッドを使用している。
## データセットの読み込み
# 読み出すデータは各データ200件ずつ×3で計600件
dataset = tf.data.TFRecordDataset(TEACH_FILES)\
.map(map_dataset)\
.batch(600)
さて、作成したTFRecordDatasetクラスのインスタンスのデータ読み出しは、イテレータを経由して行う。イテレータを取得する方法は複数あるが、今回はデータの読み込みを一度だけ行う「ワンショット」読み出し用のイテレータを取得するmake_one_shot_iterator()メソッドを利用する。このメソッドで得たイテレータに対しget_next()メソッドを実行し、それをセッション内で実行することでデータを読み出せる。
# データにアクセスするためのイテレータを作成 iterator = dataset.make_one_shot_iterator() item = iterator.get_next() # セッションの作成 sess = tf.Session() # 変数の初期化を実行する sess.run(tf.global_variables_initializer())
# 学習用データを読み出す (dataset_x, dataset_y, values_y) = sess.run(item)
あとは取り出したデータを使って学習を実行すれば良い。
# 学習を開始
for i in range(10):
for j in range(100):
sess.run(minimize, {x1: dataset_x, y: dataset_y})
# 途中経過を取得・保存
xe, acc, summary = sess.run([cross_entropy, accuracy, summary_op], {x1: dataset_x, y: dataset_y})
print("CROSS ENTROPY({}): {}".format(steps + 100 * (i+1), xe))
print(" ACCURACY({}): {}".format(steps + 100 * (i+1), acc))
summary_writer.add_summary(summary, global_step=tf.train.global_step(sess, global_step))
今回のプログラムでは、最後に学習に使用したデータとテストデータを使って画像の分類を実行し、その精度を算出している。テスト用データセットを読み込む処理も基本的な流れは同じだ。
## テスト用データセットの読み込み
# テストデータは50×3=150件
dataset2 = tf.data.TFRecordDataset(TEST_FILES)\
.map(map_dataset)\
.batch(150)
iterator2 = dataset2.make_one_shot_iterator()
item2 = iterator2.get_next()
(dataset_x, dataset_y, values_y) = sess.run(item2)
# 正答率を出力
print("assumed label:")
print(sess.run(tf.argmax(x3, 1), feed_dict={x1: dataset_x}))
print("real label:")
print(sess.run(tf.argmax(y, 1), feed_dict={y: dataset_y}))
print("accuracy:", sess.run(accuracy, feed_dict={x1: dataset_x, y: dataset_y}))
さて、今回の場合、ノード数や学習のためのデータ数が前回の例よりも多いため、学習にかかる時間も大きく増加している。今回はCPUとしてXeon E3-1230(4コア/8スレッド、3.30GHz)、メモリは16GBを搭載したマシンでテストを行ったが、1000ステップの学習処理を完了させるのに5分ほどの時間が必要だった。
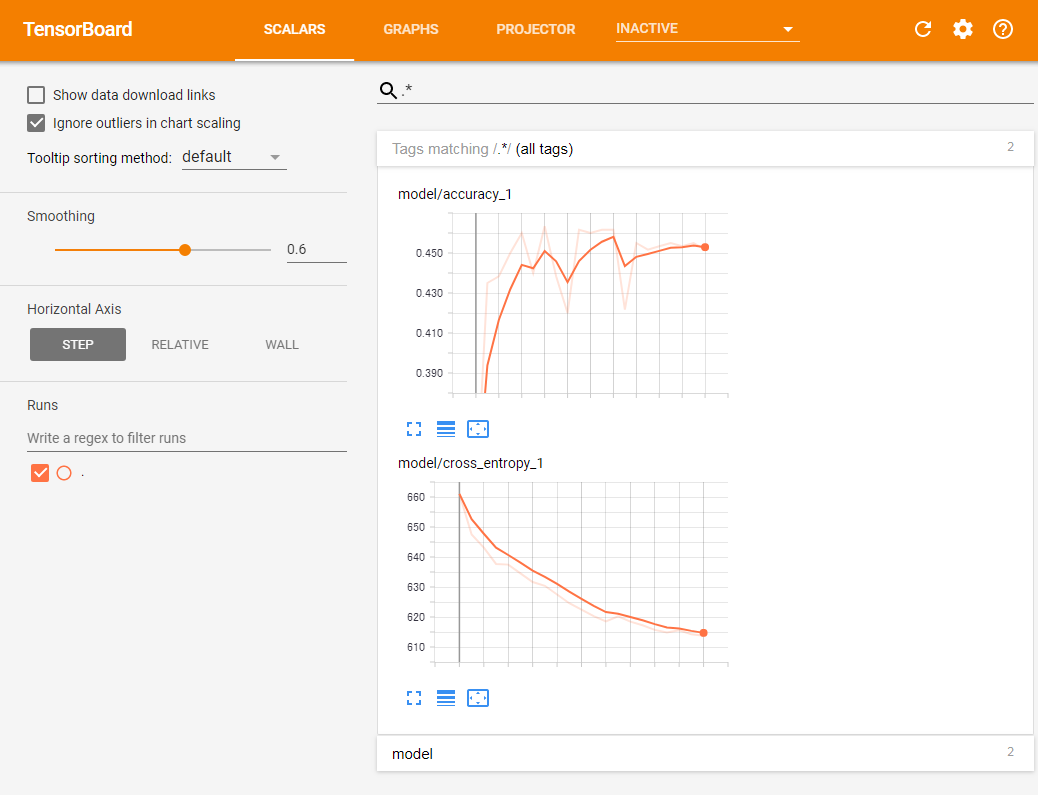
その一方で学習はうまく収束せず、2000回の学習処理のあとのテスト結果では学習に使ったデータに対する正答率は約45.2%、テストデータに対する正答率は36.0%と、有為な分類はできていないという結果となった。
----result with teaching data---- assumed label: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 2 0 0 0 1 0 0 0 0 0 0 0 0 0 0 2 0 1 0 0 2 0 0 0 0 0 0 0 0 2 2 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 1 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 2 1 1 0 0 1 1 0 0 0 0 1 1 1 0 0 1 0 1 0 1 1 1 1 0 0 0 2 0 2 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 1 0 0 0 0 1 0 0 1 1 0 2 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 2 0 0 0 0 1 0 0 1 0 0 2 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 1 0 1 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 1 2 0 0 0 0 0 0 0 0 1 1 0 0 0 1 0 1 0 0 2 0 2 0 0 2 0 2 2 0 0 2 0 2 0 0 0 0 0 2 2 0 2 0 2 1 0 0 0 2 0 2 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 1 2 0 0 2 0 0 0 2 0 0 2 0 0 0 0 0 1 0 0 0 2 1 0 0 0 0 0 0 0 2 2 2 2 2 0 0 0 0 2 0 0 0 0 0 2 0 0 0 0 1 0 0 0 0 0 0 2 0 0 2 0 0 0 2 0 2 2 2 2 0 0 0 2 0 2 0 0 0 0 0 0 0 2 0 0 0 0 0 2 0 0 0 0 1 0 0 2 0 1 0 0 0 2 0 0 0 0 2 2 0 0 0 2 0 0 2 0 0 0 0 0 0 0 1 0 2 0 2 0 0 0 2 2 0 0 0 2] real label: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] accuracy: 0.451667 ----result with test data---- assumed label: [0 0 0 0 2 0 0 1 0 0 0 0 0 1 0 0 2 0 0 2 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 2 1 0 0 0 0 2 0 0 0 0 0 0 0 2 0 0 1 2 0 0 1 0 0 0 0 0 0 1 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0 1 0 2 0 1 0 0 0 1 0 0 1 0 0 2 0 0 0 0 0 0 2 0 0 0 0 2 2 0 1 0 1 0 0 1 0 1 0 1 0 0 1 1 0 0 0] real label: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] accuracy: 0.36
TensorBoardを使ってクロスエントロピーや分類精度の変化を見ても、一定回数以上の試行で精度が頭打ちになっていることが確認できる(図4)
3層のニューラルネットワークの限界と深層学習
このように、3層のニューラルネットワークでは問題によっては適切に学習を行うことが難しいという課題があり、これが実用化へのハードルとなっていた。こういった問題を解決できるのが、昨今話題となっている深層学習(ディープラーニング)だ。次回は、4層以上のニューラルネットワークを使用した深層学習を用いて今回の画像分類問題を解くプログラムを実装していく。