Observabilityをはじめよう!(前編) 〜Observabilityの背景と構成要素〜

この記事は2020年9月8日に行われたCloudNative Days Tokyo 2020における発表を文章化したものです。
はじめに
仲亀と申します。さくらインターネットでエバンジェリストやインフラエンジニアをしています。エンジニアとしてはシステムの監視まわりの仕事をしています。最近は、今回もご紹介するPrometheusとかGrafana Lokiとか、あの辺が結構好きで触っています。
この記事では、監視について興味をお持ちの皆さんに向けて「Observabilityをはじめよう!」ということで、Observabilityの概念や、それが必要となる背景を少し説明した上で、Observabilityを実現するための要素となる、MetricsやLogsやTracesなどをどこから始めていけばいいんだろう、といったところをご紹介していこうと思います。
この記事のゴールとしては、皆さんに「Observability完全に理解した」と言っていただけたらいいかなと思っています。しかし、この記事を読んだだけですぐに皆さんの手元の環境で構築できるわけではありません。あくまでも、それらをやるためのきっかけだと思っていただければ幸いです。
なお、記事は2本組になっています。前編(この記事)では、Observabilityの背景や、その構成要素であるMetrics、Logs、Tracesとは何かを説明します。後編では、Observabilityを実践するためのツール群を紹介します。
Observabilityの背景
ではさっそく、Observabilityの背景について説明していきます。Observabilityを語る上で重要なキーワードは「分散システム」です。分散システムがなぜ関わりがあるのかという背景についてご紹介します。
分散システムと従来のシステムの違い
まず、分散システムと従来のシステムの違いについて紹介していきます。
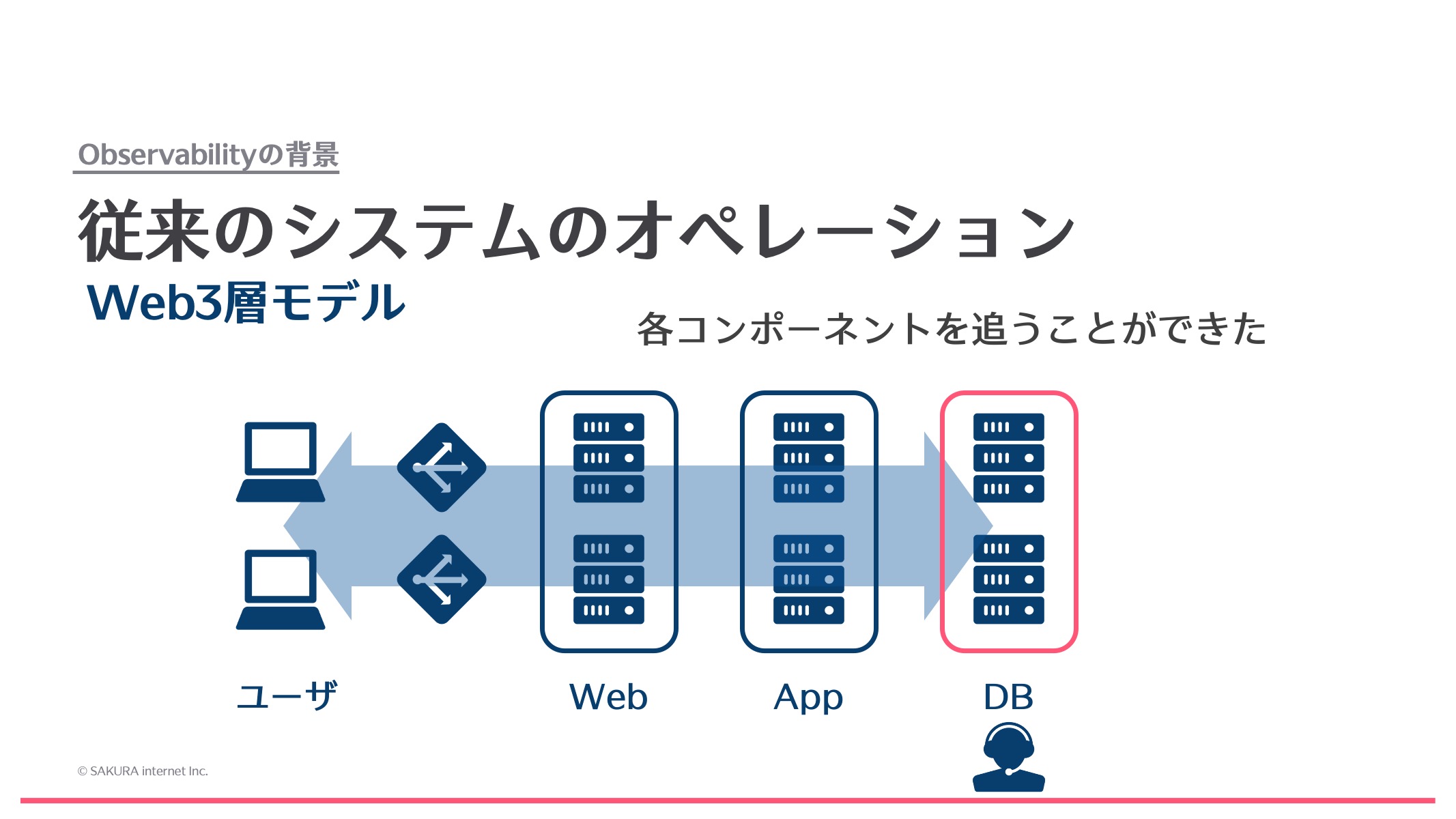
下の図は従来のシステムです。昔はこのようなWeb 3層モデルによるシステムがよく作られました。こういったシステムで障害が起きた場合は、どこで障害が起きているのかわからなくても、ユーザに近い上のレイヤーから、例えばロードバランサー、Webサーバ、アプリケーションサーバ、データベースサーバのように、各レイヤーごとに追っていくことで障害の原因を特定していました。構成がシンプルなので、人間の手でも障害の原因を追うことが比較的容易にできたのです。
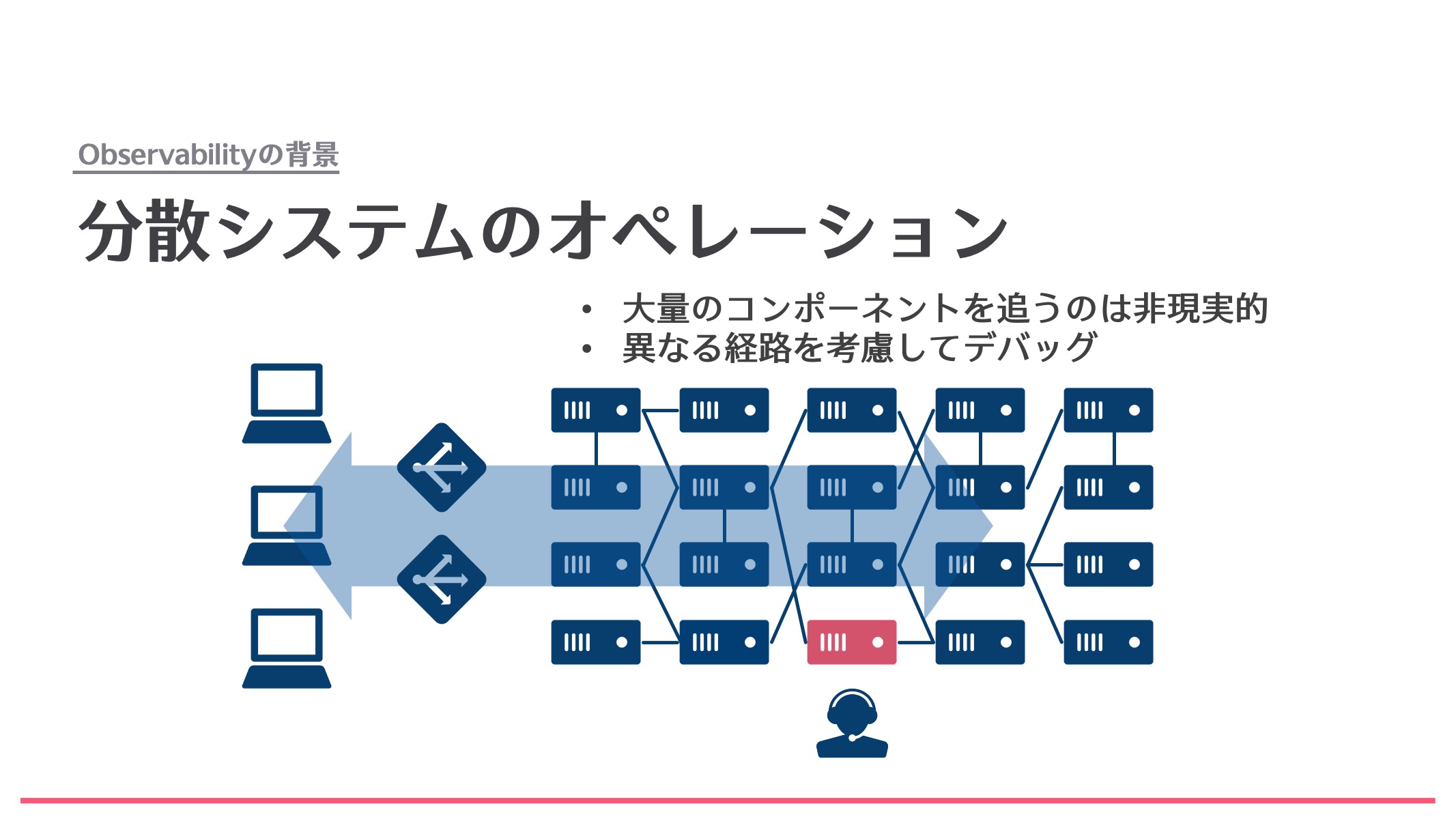
しかし、分散システムになると、下の図のような構成になります。小さいサービスや、いろんな多数のシステムをつなげて1つのサービスを作っていくようなシステムになっています。このように大量のコンポーネントが接続され、シンプルなレイヤー構造ではない複雑なシステムでは、障害の発生箇所や原因を特定するのが難しくなります。ましてやそれを人間の手で追うのは困難です。
このような分散システムの代表的な例として、Twitter社の分散システムの図をご紹介します。円が見えていて、その円の中にたくさんの線があり、円のまわりにトゲトゲが生えているように見えますが、このトゲトゲは実はテキストで、システム名が書かれています。これだけの大量のシステムが、円内の細い多数の線の数だけ連携をしているということです。このシステムに障害が発生したときに、各システムを手当たり次第にチェックして対応していたのでは、復旧に何年かかるかわかりません。
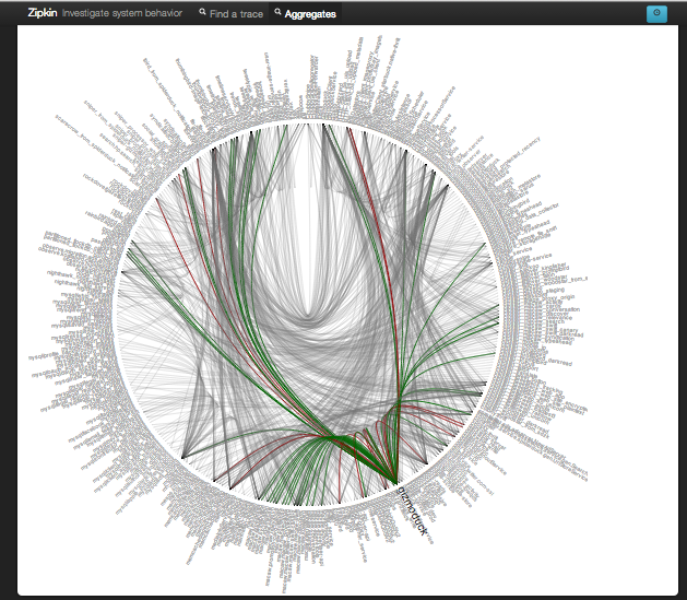
Twitterの分散システム (出典:Observability at Twitter)
分散システムにおける想定外の障害とObservabilityの登場
さらにこの大量のコンポーネント以外にも、分散システムの特徴があります。
今までの監視は、既知の障害に対するアラートを基準に構築していました。例えば、サーバーが落ちたとか、URLのエンドポイント監視が落ちたとか、CPUリソースの使用量が一定の閾値に達したといった、比較的わかりやすい障害でした。また、今までの経験から、それらの障害は想定できるものであり、それに対応できるような監視システムを作っていました。
これが分散システムではどうかというと、まずどんな障害が起きるのかがわかりません。これは各アプリケーション単位の話もそうですが、何よりもこれら大量のアプリケーションが1対1どころか1対100と言ってもいいレベルで連携をしているので、その中の特定の組み合わせだけエラーが起きるということも十分に考えられます。このようなシステムでは、障害のパターンをあらかじめ想定するのは無理があり、想定外の障害が発生することがあります。
そして、このような未知の障害が発生する可能性が非常に高まってきたという背景から、Observabilityという、複雑なシステムを横断的に見る監視の考え方が生まれてきたのです。

Observabilityを実現する
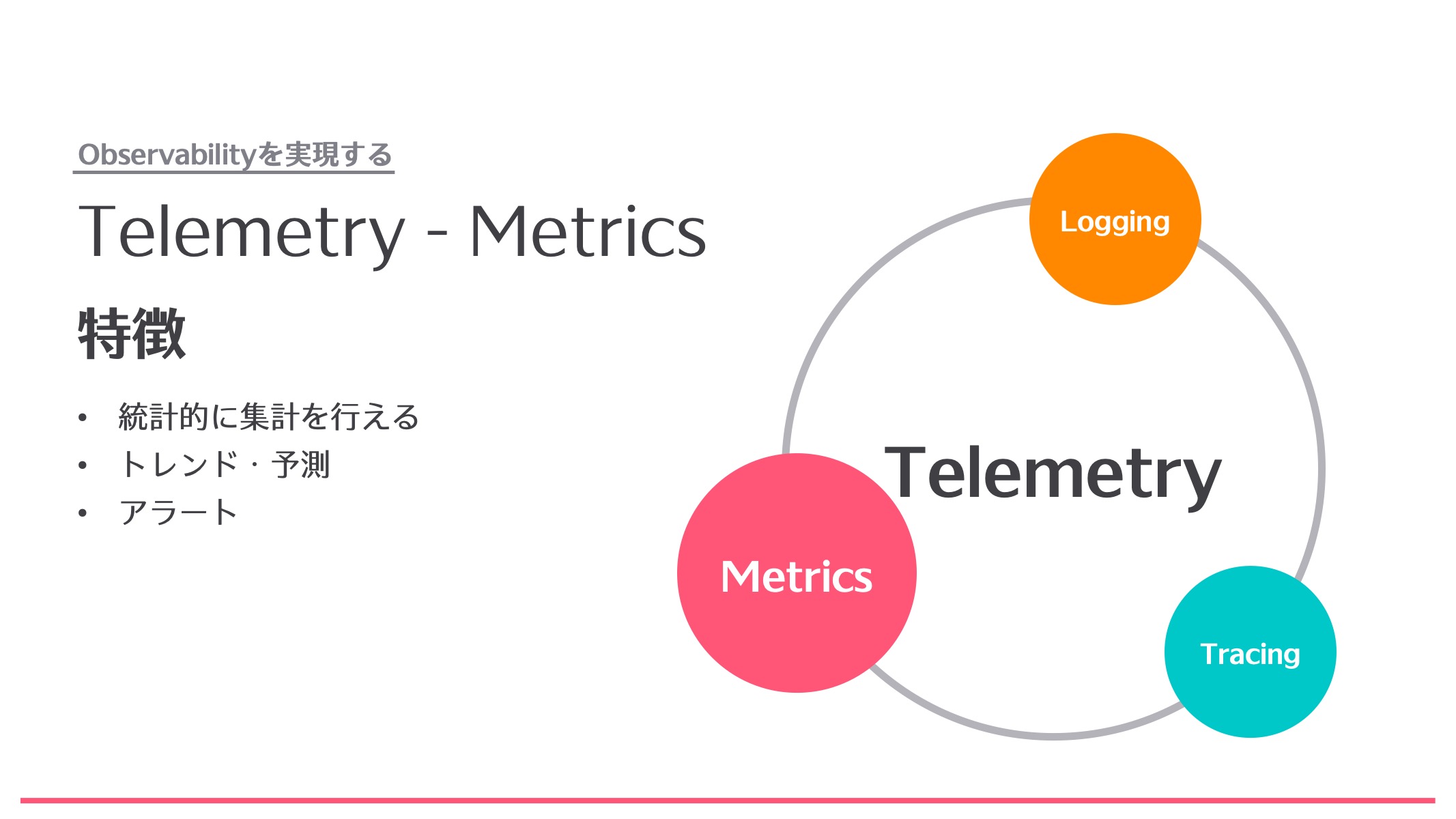
ではObservabilityを実現しましょうという話をこれからしていくのですが、Observabilityを実現するフェーズにおいて重要なキーワードがあります。それはTelemetryです。Telemetryは「Observabilityを実現するツールに求められる要素」と思ってください。Telemetryには主に、Metrics、Logging、Tracingの3つがあります。それぞれ個別に説明していきます。

Metrics
Metricsは統計的な計測を行うためのものです。Metricsを使うことで、トレンドとか予測を行うことができます。例えば毎週、この曜日にだけトラフィックが上がるとか、あるいは一見不規則なように見えても統計的に考えるとある規則性を持った状態だとかをMetricsから収集することができます。また、Metricsを使うことによって、Alertingを行うことができます。基本的にシステム監視のアラートはMetricsを基にしていることがほとんどです。例えば「CPUの使用率が閾値に達した」というアラートも、現在のCPUの使用率がどのくらいかを数値で取っているからできることです。
Metricsの注意点としては、まず単一のMetricsでは何もわかりません。例えば、今トラフィックが100kbpsですと出たところで、それは単なる事実でしかなく、それがシステムに対してどうなのかというのはわかりません。よって複数のMetricsを時系列で見ていく必要があります。それから、大量のMetricsが発生するような環境を作ってしまうとストレージを圧迫します。例えば、後ほど紹介するPrometheusというツールでは、ラベルなどにユニークな値を持たせすぎるとそうなります。よって、ラベルやタグなどのメタデータの持たせ方に注意が必要です。
Logging
次はLoggingです。これは特定の事象やイベントを人間が容易に把握できるような仕組みです。実装という点でも先ほどのMetricsと違って、何かが起きたとき、例えばソースコードの特定の関数が呼ばれたときに指定された動作を行い、○○という関数が呼ばれたというログを出力するだけなので実装が比較的容易です。
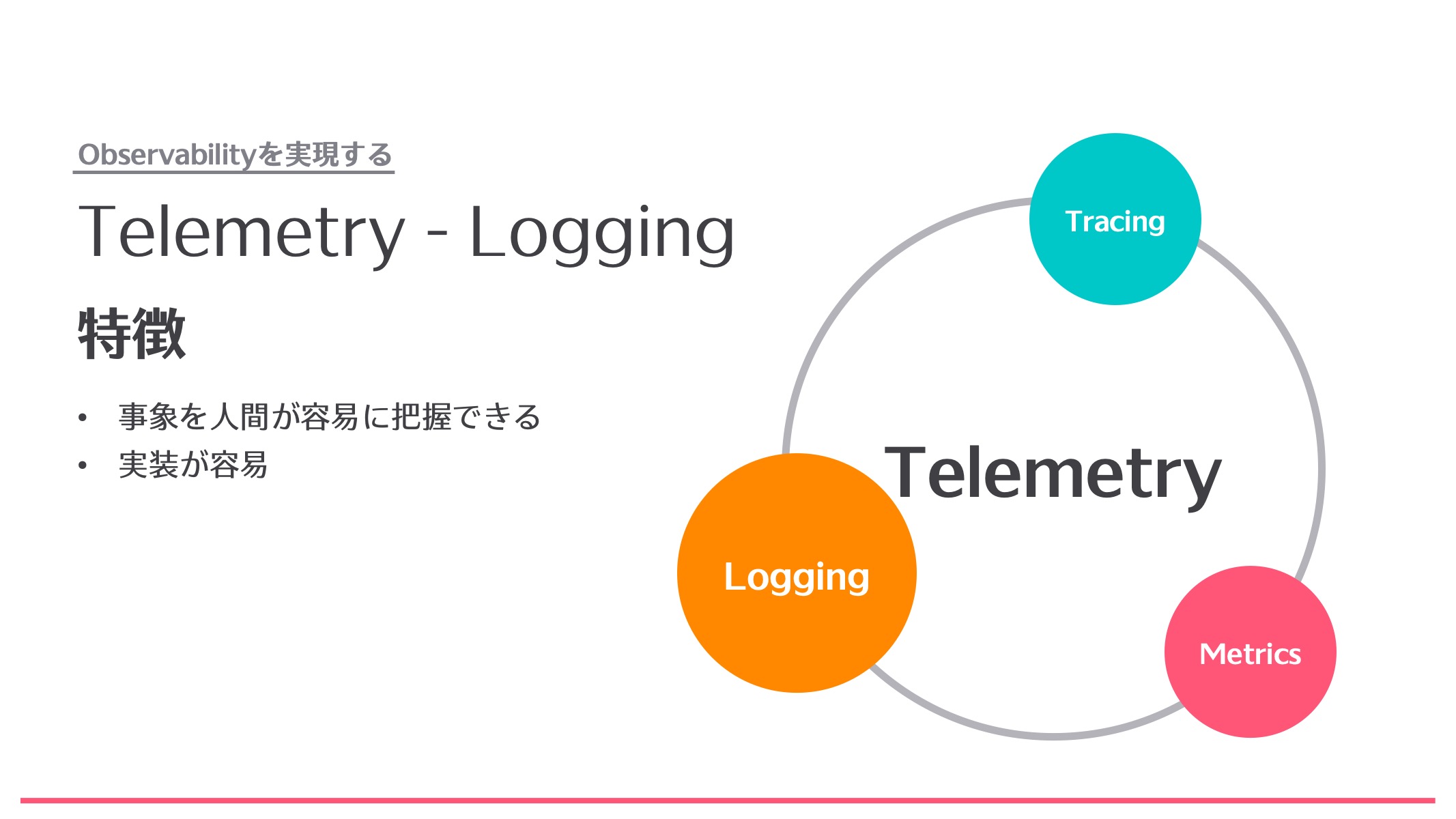
Loggingにも注意点があって、まずストレージの設計に注意が必要です。というのもログはMetricsと違って文字列で、しかも1個のレコードにつき数KBに達する場合があります。そうなると、あっという間にストレージを圧迫してしまいます。それから、ログのレベルの設計も要注意です。例えばデバッグ用であるloglevel=debugを本番環境に設定すると大量のログが出てしまい、本当に必要なログが得られにくくなったり、本番環境のストレージを圧迫することもあります。
また、ログは横断的な検索が苦手です。あるアプリケーションのログを見ることは簡単ですが、複数の連携しているアプリケーションの、AというアプリケーションからBというアプリケーションにリクエストが投げられたとか連携したというような、ログの関連性を取るのはなかなか難しいです。AからBに投げられたらBのログを見るというようなことは人間が頑張って補完していました。
Tracing
最後にTracingです。Tracingは他の2つとは違い、コンポーネントというよりはリクエストのライフサイクルを横断的に見るための考え方です。
例えばユーザが特定のサービスのWebサイトにアクセスしたら、そのアクセスしたというリクエストに対してトレースが行われます。リクエストに対してTracing IDというものが発行され、そのTracing IDがどのコンポーネントを通過したかが記録されます。こうすることで横断的なモニタリングができるので、例えばこのリクエストはこちら側のコンポーネントを通ったとか、エラーが出ている人たちはみんなこちらのサーバに行っている、といったことがわかります。さらに各インスタンス間のレイテンシを測ることもできます。
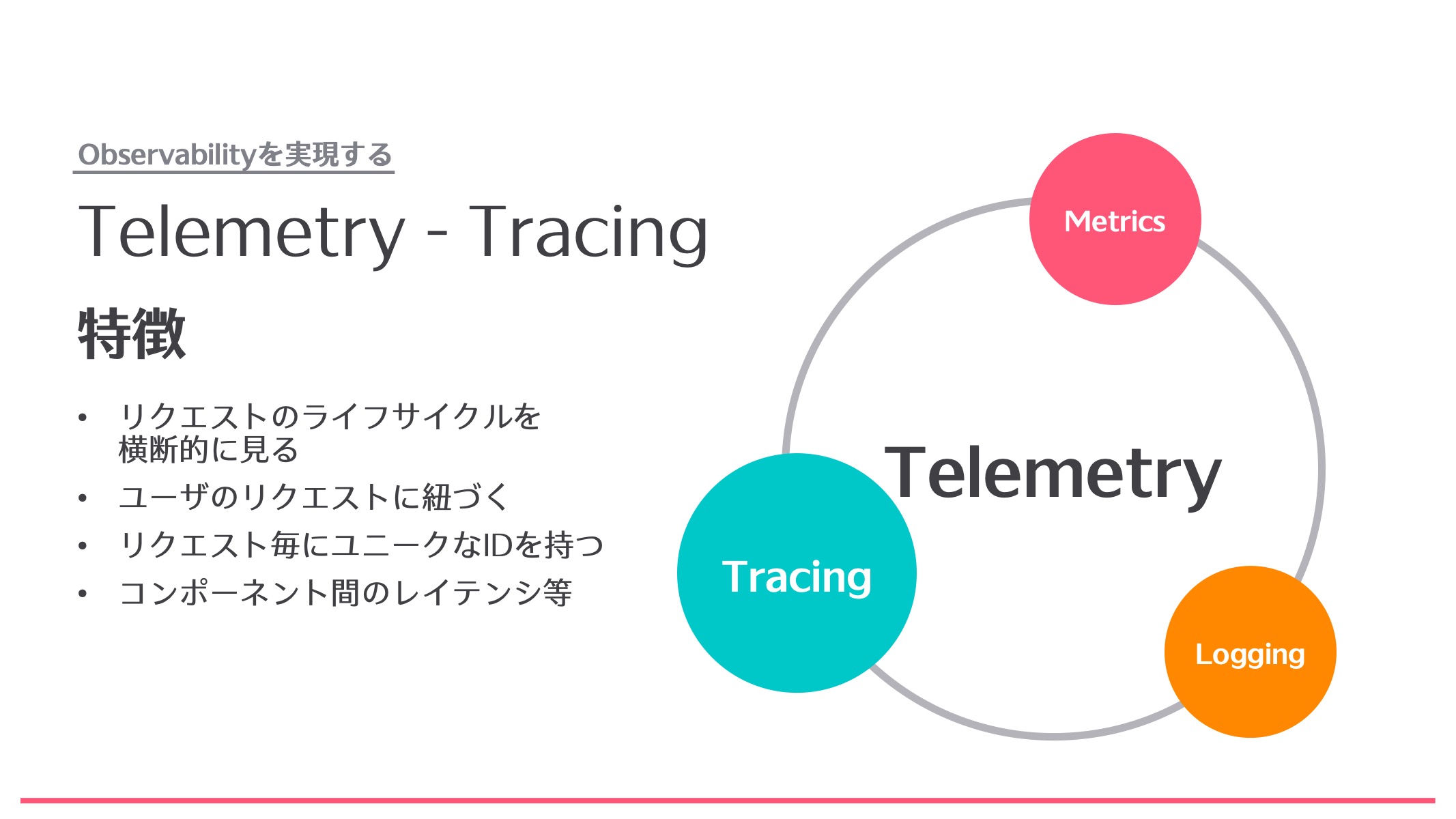
Tracingの注意点としては、まずインフラとソフトウェアに対するアプローチが必要で、インフラで作り込むだけでは実現できません。ソフトウェアにおいても、Tracing IDを発行するだけではダメで、どの関数が実行されたのか、どのような値を持ったのか、などをアプリケーション側に作り込む必要があります。また、それらを実装することでサービスアプリケーション自身に負荷がかかることも懸念材料です。
それから、Tracingの考え方自体は昔からあるのですが、話題になったのが最近ということもあり、知見があまり多くありません。もっとも、Tracingをいきなりやる必要はなく、順序としては最後の方でいいと思います。まずは先ほどお伝えしたMetricsとLoggingからアプローチするのがよいでしょう。
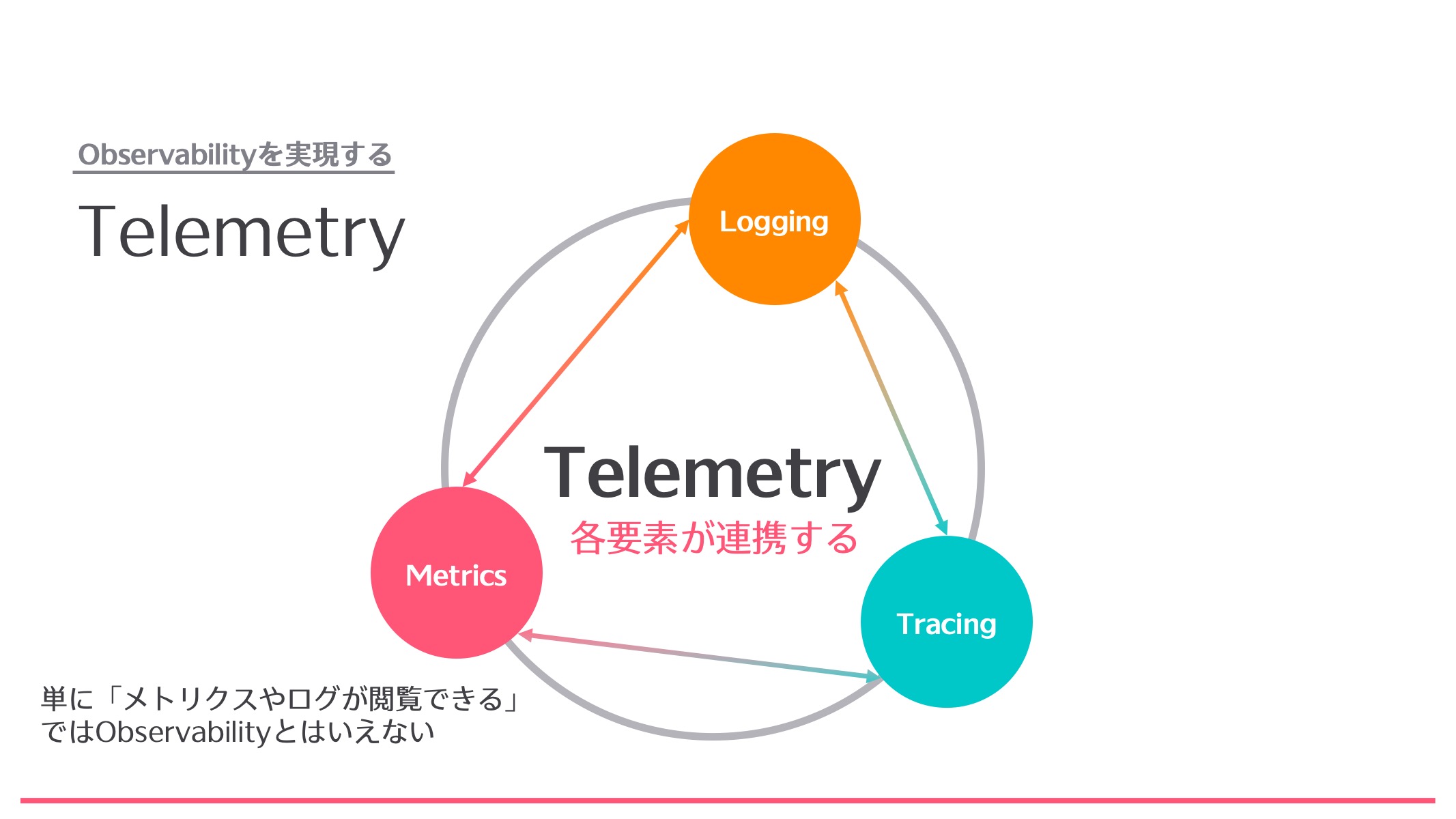
Telemetryの各要素が連携することが重要
ここまでがTelemetryの各要素についての話でしたが、Observabilityを実現するには、これらの各要素が連携をすることが必要です。単にMetricsやログが閲覧できるだけではObservabilityとは言えません。例えばMetricsの情報からログが見えたり、Metricsの情報からTracingが追えたり、逆にTracingからログが追えたり、というような形で、ある何かをキーにして、別の要素にアプローチできるのがObservabilityです。
まとめ
この記事では、Observabilityの概念や、それが必要になってきた背景を説明し、加えてObservabilityを実現するための要素となる、MetricsやLogsやTracesについて説明しました。後編ではObservabilityの実践するためのツールを紹介していきます。