Observabilityをはじめよう!(後編) 〜Metrics/Logs/Tracesチュートリアル〜

この記事は2020年9月8日に行われたCloudNative Days Tokyo 2020における発表を文章化したものです。
はじめに
仲亀と申します。さくらインターネットでエバンジェリストやインフラエンジニアをしています。
本連載では、監視について興味をお持ちの皆さんに向けて、Observabilityを始めるための情報をお伝えしています。前編では、Observabilityの背景や、その構成要素であるMetrics、Logs、Tracesとは何かを説明しました。それに続く後編となるこの記事では、Observabilityを実践するためのツール群を紹介します。
Observabilityを実践する
ここからはObservabilityの実践として、3つのTelemetry、すなわち、Metrics、Logs、Tracesについて、実際にどんなツールを使えばよいかという具体的な話をしていきます。
前編でもお伝えしましたが、Observabilityを実践するには、まずはMetricsから始めて、Metricsがいい感じにできたら次はLogsに行き、最後にTracesという流れで進めるのがよいと思います。よって、この記事ではMetricsを重点的に説明し、LogsとTracesについては軽い紹介にとどめます。

Metrics
Prometheus
Metricsを始めるには、私が大好きなPrometheusをぜひ使っていただきたいです。PrometheusはSoundCloudというサービスのエンジニアによって開発された監視システムです。内部に時系列のデータベースを持っていて、かつPull型のデータモデルを持っています。Prometheusの強いところとしてはServiceDiscoveryという機能を備えていて、サーバを手で追加しなくても、各プラットフォームやシステムのAPIなどを経由して、自動的にサーバやアプリケーションの情報を取得して登録してくれます。サーバを消した場合も同様に自動的に削除されます。
Prometheus公式サイト
それから、PromQLという、Prometheusが持つ独自のクエリ言語があります。これを使うことでシンプルかつ柔軟なクエリを投げることができます。PromQLはかなりシンプルな構造なので、学習コストも比較的低めです。あとはラベルという概念があるので、Kubernetesとの親和性も非常に高いです。PrometheusはKubernetesでの監視のスタンダードになっているので、Kubernetesを使っている場合はぜひPrometheusを使ってください。
Prometheusは公式サイトとGitHubからバイナリを入手することができます。アーカイブをダウンロードし、展開して、バイナリを起動すればいいだけです(下記コマンド参照)。非常に簡単ですね。Dockerコンテナなどもあります。
$ tar xvfz prometheus-*.tar.gz $ cd prometheus-* $ ./prometheus
公式サイトにはFIRST STEPSというページもあって、Prometheusを始める方法がすごくわかりやすく書かれているので(英語ですが)、ぜひこのURLにもアクセスしてみてください。
Exporters
このPrometheusは簡単に使える上に、さらにExporterというのがあります。サーバとかアプリケーションのMetricsを獲ってくれるエージェントと考えていただければOKです。いろいろなExporterがありますが、特に個人的に便利だと思うのはまずNode Exporterです。これはサーバのCPUとかメモリなどのMetricsを獲ってくれるExporterです。これはどんな状況でもとりあえず入れるぐらいになっています。
あとはBlackBox Exporterというのがあります。これはPrometheusを使ってブラックボックス監視を実現するツールです。例えばURLの死活監視や、ICMPによる死活監視もできます。監視を始めるときはいきなりNode Exporterを使ってサーバのMetricsを取得するのではなく、URL監視やサービス自身の監視から始めた方がよいと思います。ですので、Prometheusを使うときはNode ExporterでMetricsを取りつつ、BlackBox Exporterでサービスの監視をするのがよいでしょう。
OpenMetrics
最近あまり話題になりませんが、OpenMetricsについてもここで少し紹介しておきます。OpenMetricsはCNCF(Cloud Native Computing Foundation)のSandboxプロジェクトの1つで、PrometheusのMetricsのフォーマットをクラウドネイティブなMetricsのフォーマットとして標準化していきましょうというプロジェクトです。

OpenMetrics公式サイト
先ほどのExporter達は、基本的には既存のアプリケーションやOSSに対するMetricsを収集するツールです。例えばnginxやMySQLなど、既存のアプリケーションやOSSに関してはExporterを使えばよいのですが、自分で作ったサービスのアプリケーションやシステムのExporterは存在しないので、自分で作る必要があります。そういうアプリケーションがMetricsを吐くときに、このOpenMetricsのフォーマットを使うとよいでしょう。
Prometheusはストレージに注意
Prometheusを使っていくときに問題になるのがストレージです。Prometheusは、デフォルトではTSDB(Time Series Database)というローカルのストレージを利用するのですが、これは冗長化や可用性が考慮されていません。ですので基本的にはシングルインスタンスでシングルテナントで動かす前提ですし、TSDB自体が壊れたらどうするかというと、これは古いドキュメントしか見つけられなかったのですが、TSDBのファイルシステムからその対象のファイル群を削除してくださいと書かれています。それぐらいシンプルで何も考慮されていないので、運用が結構大変ではなかと思います。
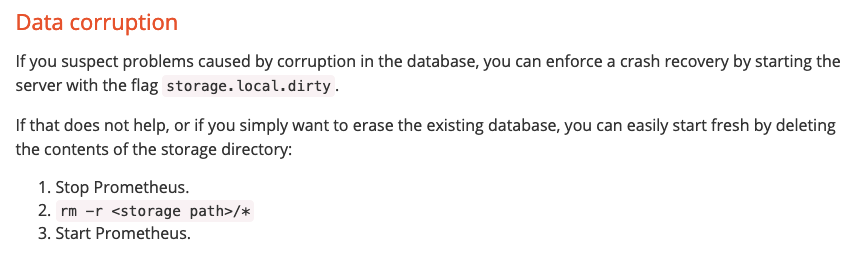
TSDBが壊れたときの対処方法 (出典:Prometheus公式ドキュメント)
あとは、それらのMetricsの容量設計にも注意が必要です。これは公式ドキュメントに載っていますが、容量はこんな計算式で見積もることができます。
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample
ストレージ問題への対策としては、PrometheusにはRemoteStorageという機能があり、これを使って外部のデータベースにMetricsを保存することができます。最近話題になっているCortexやThanos、昔からあるInfluxDB、マネージドサービスだとGoogle Big Query、他にもいろんなサービスやアプリケーションが対応しています。Prometheus自身は、冗長化やスケーラビリティについてはそれ専用のアプリケーションにまかせるという方針になっているので、これらを利用するのがよいでしょう。
PrometheusOperator
また、PrometheusをKubernetesで使う場合は、PrometheusOperatorを使うとよいでしょう。Kubernetesで使う場合、Prometheus本体やAlertManagerなどいろいろなコンポーネントを展開する必要がありますが、PrometheusOperatorを使うとこのあたりを自動的に展開したり冗長化してくれたりします。
さらに何よりうれしいのはServiceMonitorというカスタムリソースがあり、これを使うことによって監視の構成の一元化、統一化を図ることができます。Prometheusを使っていくと設定がカオスになることが多いのですが、その辺をよしなに簡単にしてくれるというか、このラベルのアプリケーションを監視してほしいという情報を与えればCRDが自動的にマニフェストを生成してくれるのでかなり使いやすいです。KubernetesでPrometheusを使うときはぜひ使ってみてください。
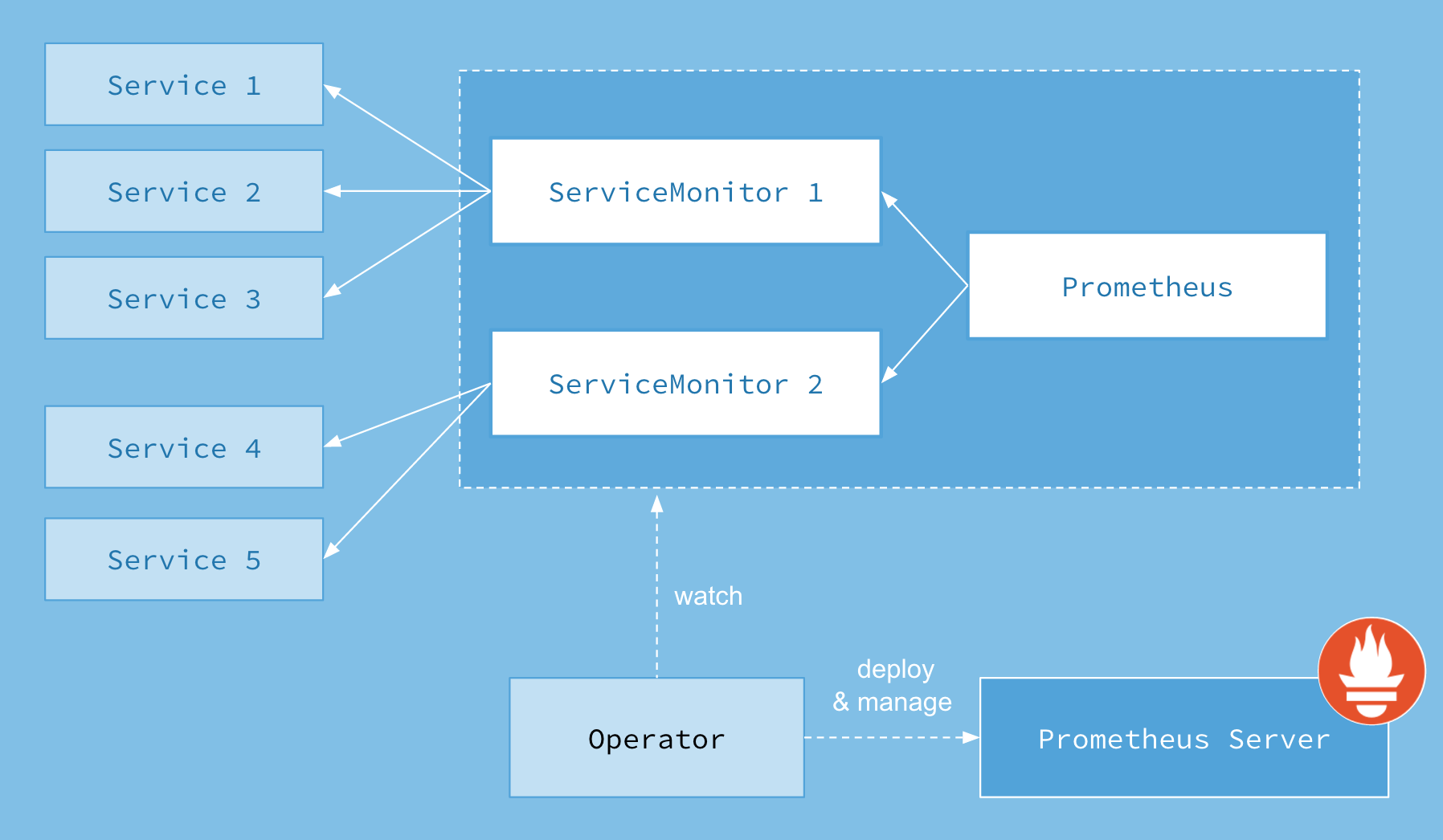
PrometheusOperatorを使った監視 (出典:The Prometheus Operator: Managed Prometheus setups for Kubernetes)
Client Libraries
Prometheusの最後に紹介するのがクライアントライブラリです。これは自前のアプリケーションにPrometheus用のエンドポイントを簡単に追加するためのライブラリです。Go、JavaもしくはScala、Python、Rubyに対応していて、その他のサードパーティのアプリケーションやライブラリもさまざまな言語に対応しているので、ご自身のアプリケーションからMetricsを吐きたい場合はこの辺を使っていくのがよいかと思います。個人的にはOpenMetricsのMetricsを仕込むよりは、まずはクライアントライブラリでちょっと簡単に作ってみるのがよいと感じています。
Logs
次に、簡単になりますがログに関して話をしていきます。
ログは、Grafana Labsが出しているGrafana Lokiをぜひ使っていただければと思います。これはPrometheus likeなツールで、Prometheusの特徴であるPromQLやラベルなどの概念を持っています。よって、Prometheusで例えばapp=prometheusというラベルがあったとき、それをそのままこのLokiに持ってくることができます。

Grafana Loki公式サイト
本記事の前編で説明した、各Telemetryの要素が連携する必要があるというのは、実はこのあたりがすごく重要です。Prometheusで取得したMetricsが異常な値を示している場合(特定のタイミングでトラフィックが急上昇していたとか)、そのトラフィックのその瞬間のログとMetricsのラベルをもとにして、Lokiに飛ぶことができます。こういったことができるので、すごくLokiがおすすめです。
それから、LokiはElasticsearchのように全面にインデックスを張るのではなく、各エントリーに対してメタデータをラベルとして持たせることによって高速化を図っています。これが結構重要です。
また、LokiはCortexのアーキテクチャを踏襲したマルチテナントモデルを持っています。Loki自体は下の図に示したように、Lokiのサーバがあり、それに対してGrafanaからアクセスしに行きます。で、各サーバに対してPromtailという、fluentdなどと同じようなエージェントを持たせることによって、ログに対してラベルを持たせたり、そのログ自身をLokiに問い合わせるというような動作をします。
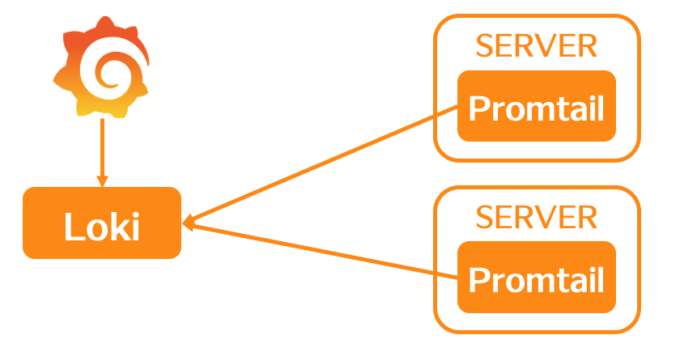
そして、そのためのLogQLというクエリ言語があるのですが、これがほぼPromQLと似たような形で使えるので学習コストが非常に低いです。LogQLではログにラベルを付与することができます。静的に追加することもできますし、ログのエントリーのカッコ内の文字列、例えば「level=error」といったところからラベルを作ることもできます。
Alertingももちろんできます。下記の設定は公式サイトのサンプルから持ってきたものです。
- match:
selector: '{app="some-app"} != "info"'
stages:
- regex:
expression: ".*(?Ppanic: .*)"
- metrics:
panic_total:
type: Counter
description: "total count of panic"
source: panic
config:
action: inc
ここで今回はpanic_totalというMetricsを作成しています。こうするとこのMetricsがPrometheusを参照することができるので、あとは通常のPrometheusのAlertingと同じような形でアラートを実現することができます。こうすることで、いわゆるログのアラートもこのLokiを使って実現できます。
Lokiの注意点もストレージです。IndexとChunksという2種類のストレージがありますが、それぞれ下記に列挙するストレージにしか対応していません。
- Index: Cassandra, GCS, File System, S3
- Chunks: Cassandra, BigTable, DynamoDB, BoltDB
Indexはいいとして、ChunksをオンプレミスでやろうとするとCassandraぐらいしか選択肢がなくてなかなかつらいです。Lokiを使う場合はパブリッククラウドを利用することをおすすめします。
Tracing
最後にTracingについて軽く説明します。
TracingはJaegerを使えばよいかと思います。Uber Technologiesが開発したトレーシングシステムの1つです。OpenTracingという規格の互換データモデルを持っています。各言語ごとにInstruments(トレーシングの仕組みを持たせるためのライブラリ)を提供しているので、こちらを使うことで簡単にトレーシングができます。
Jaeger公式サイト
で、Jaegerを使って欲しい理由は、Grafanaとの連携が非常に良いからです。最近出たGrafana 7.0からはJaegerとZipkinに対応していて、Grafana上でトレーシングの参照ができるようになりました。よって、下記の図のような形で、JaegerもLokiもPrometheusも各コンポーネントがGrafanaに情報を送り、Grafana上ですべてのObservabilityを実現できることが最大のメリットです。

Observability Readyな運用フロー
このようにして最終的に作り上げられるObservability Readyな運用フローとしては、まずアラートが上がったらGrafanaでDashboardを見ます。そしてDashboardで「ここおかしいな」と思ったら、Metricsを叩くためにクエリを叩いてもいいですし、ログが見たいと思ったらLokiに行くのもよし、もう少しユーザのリクエストが見たいと思ったらJaegerの方に飛ぶと、そういう風にしていけばよいかと思います。
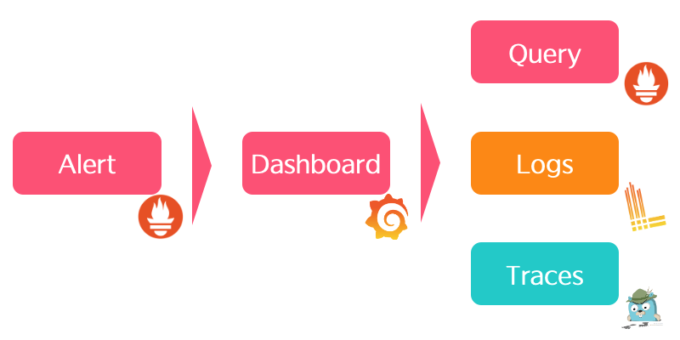
Observability Readyな運用フロー
まとめ
システムの大規模化に伴って、大量のコンポーネントや未知の障害に対するアプローチとしてObservabilityという考え方が必要になってきました。そして、そのためにはTelemetryの3つの要素(Metrics、Logs、Traces)を意識しましょうという話をし、各要素について具体的なツールをご紹介しました。
Observabilityの各要素については、単純にそれぞれを意識するだけではなく、その3つがきちんと連携することが重要です。ここが今回一番お伝えしたい重要なポイントです。ぜひそういったところを意識した上でObservabilityのシステムを構築していただければと思います。
というわけで、「Observability完全に理解した」となっていただけましたでしょうか。最後までお読みいただきありがとうございました。
