今日から始めるPrometheusによるシステム監視(1) 〜Prometheusの特徴とアーキテクチャ〜

この記事は2021年3月6日に行われたオープンソースカンファレンス 2021 Online/Springにおける発表を文章化したものです。
今回は「今日から始めるPrometheusによるシステム監視」ということで、Prometheusというツールについてご紹介をしていこうかなと思います。皆さんに「Prometheus完全に理解した」と言えるようになっていただきたい、というのが今回の目標です。
本連載は3本で構成されていて、それぞれ以下の内容を扱います。
- Prometheusの特徴とアーキテクチャ(この記事)
- PrometheusとCNCF、Observability
- Prometheusを使ってみよう
目次
Prometheusとは
Prometheus(プロメテウス)は、SoundCloudという海外の音楽系サービスのエンジニアによって開発された監視システムです。もともと、Kubernetesの前身となった、Googleの内部で使われていたBorg(ボーグ)というシステムがあるのですが、それを監視するためのソフトウェアとしてBorgmonというのがGoogle社内で作られました。そのBorgmonをまねて作ってオープンソースとして公開したのがPrometheusです。
Prometheusは時系列のデータベースを採用しているPull型のデータモデルを持っていて、Service Discovery(サービスディスカバリ)という機能によって(監視の対象の)ターゲットを自動的に追従してくれます。さらにPromQL(プロムキューエル)という専用のクエリ言語がありまして、これを使うことによってシンプルかつ柔軟なクエリを発行することができます。それから、多種多様なExporter(エクスポータ)というものが用意されています。いわゆる監視エージェントですね。これを使うことによって、サーバだけではなく特定のソフトウェアとかサービスなど、いろいろなものを監視することができます。
Prometheusのどこがすごいのか
Prometheusの何がすごいのかという話をいろいろしていくんですけども、まずこれを見てください。これは2016年のPromConという海外のカンファレンスで発表された内容を引用したものです。

DreamHackのシステム監視にPrometheusが利用された(出典)
それによると、DreamHackというゲーム系のイベントが以前行われたのですが、このイベントのバックグラウンドのシステムを監視するのにPrometheusが用いられたという情報があります。このときは10,000台のコンピュータ、そして500台のスイッチを監視したことで非常に有名になりました。これが2016年ですからもう5~6年前の話ですよね。その頃にすでにこれだけのコンピュータを監視できていたので、今はそれ以上のアップデートができているはずで、パフォーマンスは非常に高いことが期待できるのではないかと思います。
Prometheusのアーキテクチャ
Prometheusのドキュメントを見ると、Prometheusのアーキテクチャとして下図が出てきます。
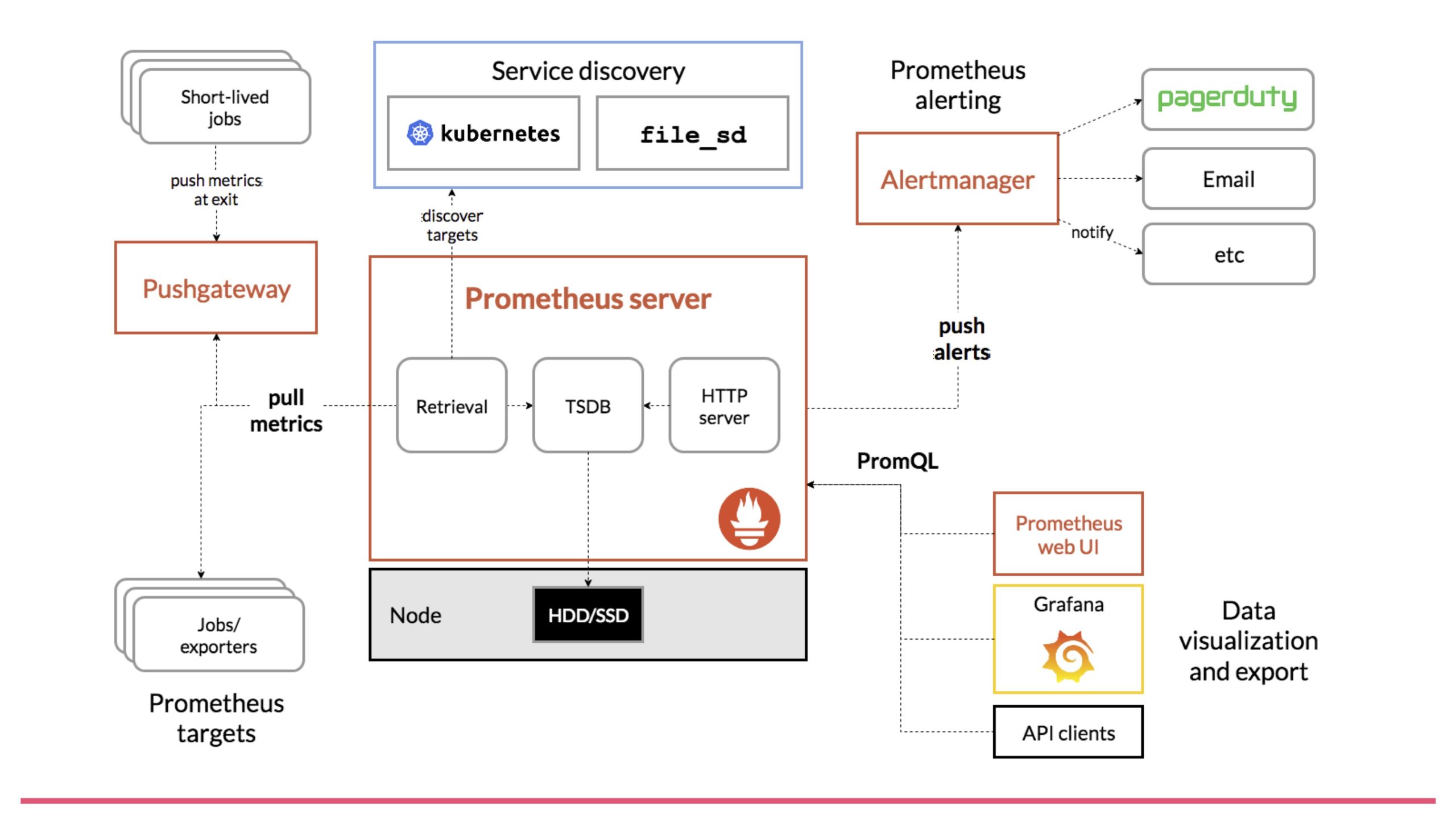
Prometheusのアーキテクチャ
この図は大きく6つに分けることができます。まずPrometheus Server(Prometheus本体)、Service Discovery、Exporterという監視エージェント、アラートの機能をつかさどるAlerting(アラーティング)、そしてクエリの言語であるPromQL、最後に可視化機能であるVisualization(ビジュアライゼーション)、この6つによって構成されています。このあとは各部を解説していきます。
Prometheus Server
これは先ほどお話しした通りPrometheus本体です。このPrometheus Server自体は、各監視ターゲットからMetrics(メトリクス)を収集したり、その収集したMetricsに対してクエリを発行してMetrics情報を参照したり、もしくはそのクエリを自動的に内部で定期的に実行することによってアラートの管理をしたり、というようなことを司ります。
また、このPrometheus Serverをはじめ、Prometheusのエコシステムに含まれるソフトウェアの多くがシングルバイナリで動いてくれます。つまり1個のバイナリをダウンロードしてくるだけで動くわけです。例えばZabbixを利用したい場合、まずZabbixサーバのインストールという手順が発生します。さらにそれだけではなく、MySQLを用意したりだとか、その辺のセットアップが意外と面倒くさいというのはあったりします。そこがこのPrometheus Serverでは、本当にバイナリを1個実行するだけで動いてしまうといったところが特徴としてあります。
Service Discovery
Service Discoveryは、監視対象の情報を自動的に取得してくるような仕組みです。これを使うことによって、対応したAPI、例えばクラウドのプラットフォームとか特定のソフトウェアとかのAPIをたたいて、そこに登録されているインスタンス情報を収集してきます。
例えば、あるクラウドサービスにサーバが3台あって、それらの名前はこれこれで、IPアドレスはこれですよ、というような情報をAPI経由で取得してきて、それをターゲット情報としてPrometheusに渡してあげます。その後、サービスをスケールする必要があったということでサーバを3台追加したとします。これでサーバが6台になりました。この3台が追加されたというのもAPIをたたくことによって参照できるので、自動的に追加されます。さらに、過負荷の状態が終わったところでサーバを3台削除したとします。これで3台に戻るわけですが、こういった場合でもAPIをたたけばこの3台が減ったよという情報が取得できるので、自動的にターゲットから3台減らしてくれる、といった動作をします。これによって、今まで1つ1つ手で登録したり、専用のファイルに記述するといった煩雑なところを自動化することができるわけです。

これの何がうれしいかというと、現代のクラウドサービスだとか、もしくはマイクロサービスと言われるようなシステムを利用する場合に、個々のインスタンスの情報ってすごく頻繁に変わってしまうんですよね。それこそ今はDockerとかKubernetesといったコンテナが当たり前になってきていますよね。コンテナって、何日間もずっと使い続けることもありますが、どちらかというとスポットで作成して消えて、また作成して、というのを繰り返すのが前提としてあったりします。Service Discoveryを使うと、そういうケースにもより対応しやすくなります。
Service Discoveryが対応しているプラットフォームは、例えばAzure、AWS EC2、GCP GCE、あとOpenStackとか、もちろんKubernetesにも対応しています。これらに加えて、さらに拡張することによって、例えば弊社のさくらのクラウドもこのService Discoveryを使って情報を取得してくることができます。
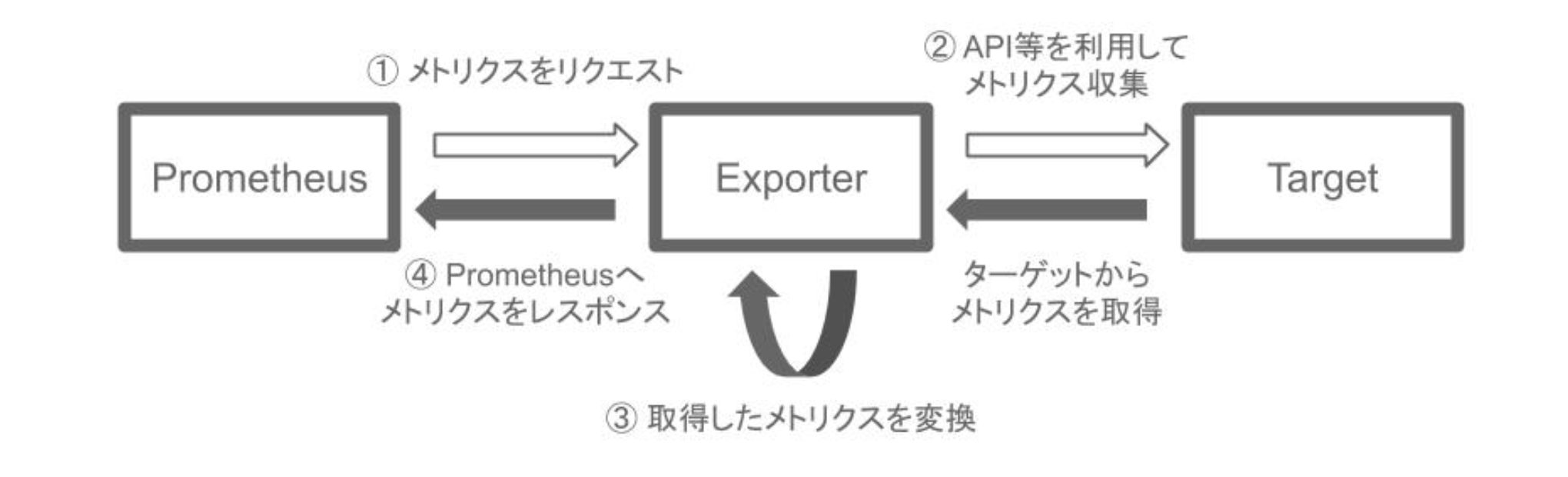
Exporter
Exporterとは何かと言いますと、いわゆる監視エージェントです。Exporterは監視対象からMetricsを収集してきてPrometheusで公開します。例えば、NginxのCPU使用率がどうなのか、リクエストが何件来ているのか、といった情報は取得できますが、それぞれのフォーマットをPrometheusは知らないわけです。毎回それ用のフォーマットをPrometheus側でメンテナンスしていては大変です。そこで、代わりにこのExporterというのを間に置いてあげて、ExporterがNginxだとかApacheだとか、対象のシステムからMetrics情報を取ってきます。取得方法はAPIだったり直接特定のコマンドを実行したり、いろいろあります。そうして得られたMetrics情報をPrometheusが読める形に変換してあげるのが、このExporterという仕組みなのです。
Exporterは現在600種類以上という、ものすごい数があります。自分で作ることもできるので、他のシステムではできなかった監視も簡単に監視することができます。
Alerting
他の監視システムでは、アラートの仕組みは標準で備えられていることがほとんどだと思います。しかし、残念ながらPrometheusの場合はアラート機能そのものはありません。ではどうするかというと、AlertManager(アラートマネジャ)というコンポーネントを使います。これはPrometheusのコミュニティによってメンテナンスされているソフトウェアの1つですが、このAlertManagerがすばらしいのです。例えば複数のPrometheusを展開して、アラートの処理を1つのAlertManagerに向けると、自動的に重複を排除してくれたりします。「このアラートとこのアラートは同じアラートだから2つ出す必要ないよね」ということで1つにしたり、複数の似たようなアラートをまとめて「こういう障害が発生したよ」という形でグルーピングしてあげたり、PrometheusのMetricsのラベルを見て「これはAチーム、これはBチーム」という形でルーティングしたり、そういった柔軟な仕組みをAlertManagerは展開してくれます。
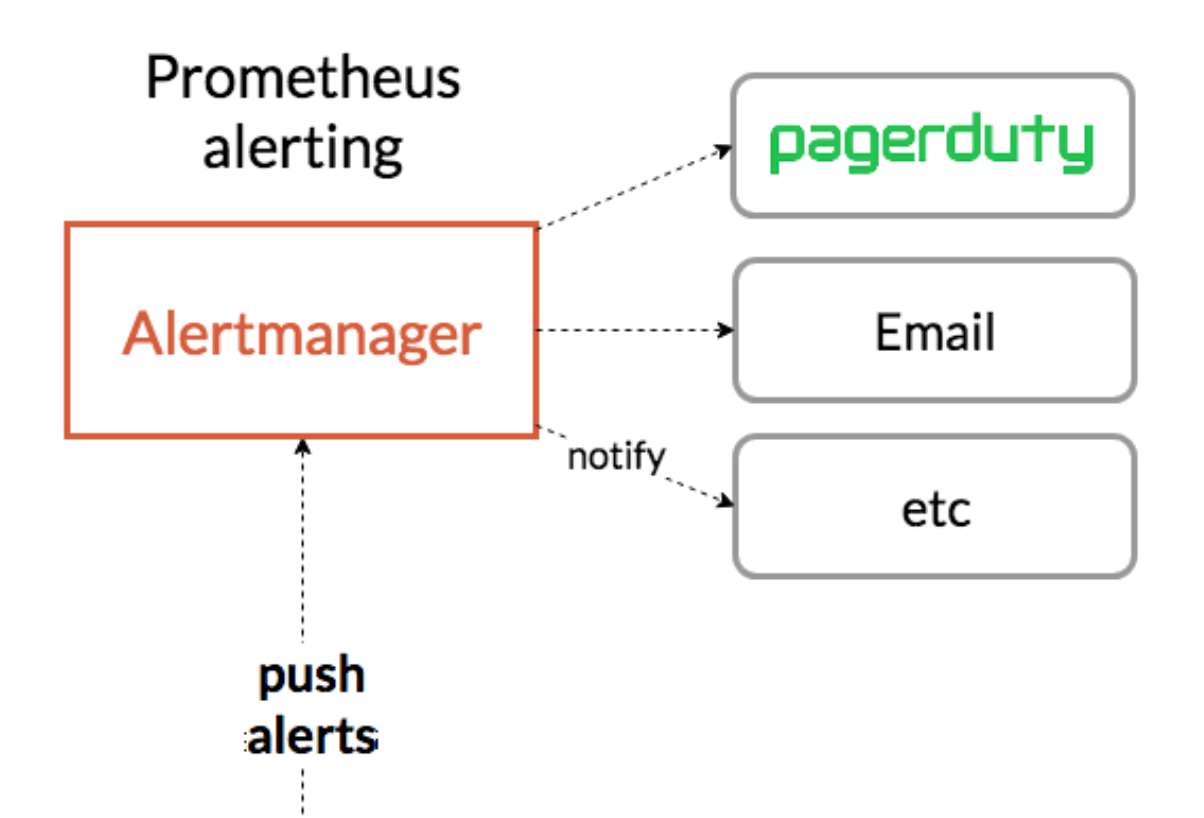
つまり、こういったアラートに関わる柔軟な仕組みをPrometheus本体で作るのではなくあえて分離することによって、それぞれのライフサイクルを隔離して、AlertManagerはアラートに対してより専門的により素早く開発を進めていく、ということでコンポーネントが分かれているのです。
PromQL
PromQLはPrometheus Query Languageの略です。これは後ほどまた詳しく紹介しますが、とてもシンプルで、かつ時系列データにマッチした形で利用できます。このPromQLのすばらしいところは、Metricsのラベルによるフィルタリングができます。例えば、インスタンスの名前とかIPアドレスとか、もしくはクラウドプラットフォームのリージョンなどがラベルとして使えます。Metricsに登録されているラベルでフィルタリングができるので非常に直観的です。
また、PromQLは、フィルタリング以外にも、関数を用いて集計を行ったり、アラートの実行といったところまで幅広く使われています。PromQLはPrometheusを利用する上で必ず覚えておきたい要素の1つですね。
Visualization
Prometheusで可視化をする場合、2つの方法が考えられます。まず1つはPrometheusが持つWeb UIを使う方法です。Reactで作られたWeb UIがPrometheus本体として提供されており、Prometheusのエンドポイントにアクセスすることによって、簡単なMetricsのクエリを実行できます。例えば以下の図では、Prometheusを実行しているサーバのメモリ使用率を表示しています。こういった簡単なMetricsであれば、このWeb UIでも表示できます。
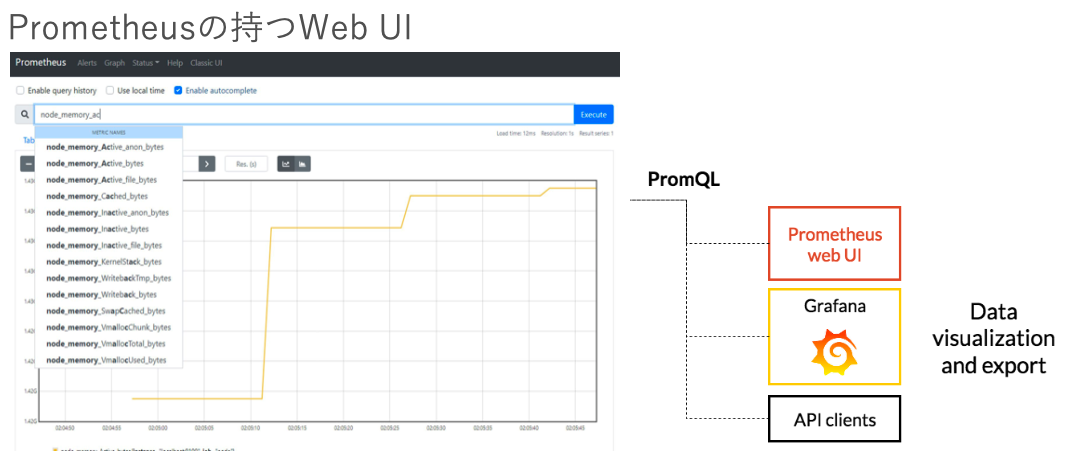
PrometheusのWeb UIを使ったVisualization
しかし、より複雑なことや、もしくは既存のパネルやグラフを保存しておきたいという場合はこのWeb UIでは力不足ですので、ここはまた専門家に来てもらいましょうということでGrafanaを使います。GrafanaはPrometheusをサポートしており、標準データソースとしてPrometheusを選択できます。下図はNodeExporterという、サーバを監視するためのExporterの情報を表示したダッシュボードですが、こんな形で結構リッチなダッシュボードを作ることができます。
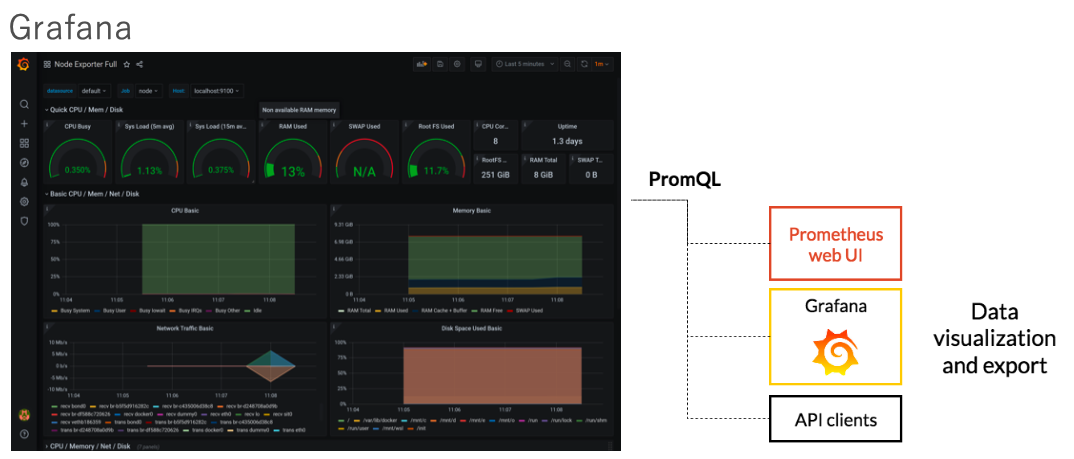
Grafanaを使ったVisualization
このGrafanaと先ほどのWeb UIの2つがあるわけですが、Grafanaの方が高機能だからそちらばかり使えばいいかというとそういうわけではなく、よく見るダッシュボードや保存しておきたいダッシュボードはGrafanaで扱って、その場その場でインスタンスに対して発行したいクエリ、例えば障害が起きたときに調べるためにいろんなクエリを作って発行するような場合にはPrometheus標準のWeb UIを活用しています。
Prometheusのコンポーネントまとめ
こんな感じでPrometheusのアーキテクチャは主に6つのコンポーネントによって構成されています。こうして見ると意外とシンプルだと思います。Service DiscoveryはPrometheusの機能そのものですので、Prometheus Serverがあれば最低限の監視は実現できます。
次回は
次回は、Prometheusを使っていく上でぜひ知っていただきたいお話として、CNCFという組織との関係や、Observability(オブザーバビリティ)の話などをしていこうと思います。