今日から始めるPrometheusによるシステム監視(3) 〜Prometheusを使ってみよう〜

この記事は2021年3月6日に行われたオープンソースカンファレンス 2021 Online/Springにおける発表を文章化したものです。
今回は「今日から始めるPrometheusによるシステム監視」ということで、Prometheusというツールについてご紹介をしていこうかなと思います。皆さんに「Prometheus完全に理解した」と言えるようになっていただきたいというのが今回の目標です。
本連載は3本で構成されていて、それぞれ以下の内容を扱います。
1. Prometheusの特徴とアーキテクチャ
2. PrometheusとCNCF、Observability
3. Prometheusを使ってみよう(この記事)
Prometheusをはじめよう!
Prometheusを始めるには、(prometheusという名前の)バイナリを実行しましょう。以上です。
……結論としてはこれだけなんですが、ちょっとこれだけだとさすがに親切ではないので、デモを交えて説明します。
インストールと起動
まずはブラウザで「Prometheus GitHub」と検索すると、PrometheusのGitHubが出てきます。そこからPrometheusのリポジトリに行って、Releasesページを開きます。

GitHubのPrometheusリポジトリに行き、Releasesをクリック
ここでちょっと注意していただきたいのが、リリースされているものを見ると、Latest-releaseとPre-releaseがあります。Pre-releaseはβ版、いわゆる初期リリースみたいなものですので、基本的にはLatest-releaseの方を使っていただければと思います。
Latest-releaseとなっているバージョンを使用
各アーキテクチャごとにバイナリが用意されていますので、今回はlinux-amd64というものを使用します。アーカイブのURLをコピペしてきまして、wgetで手元にダウンロードします。wgetはすぐ終わるので、ダウンロードしてきたファイルをtarで解凍します。そうするとディレクトリができ上がるので、そこを見ていくと、こんな感じでファイルが展開されます。
$ wget https://github.com/prometheus/prometheus/releases/download/v2.25.2/prometheus-2.25.2.linux-amd64.tar.gz $ tar xfz prometheus-2.25.2.linux-amd64.tar.gz $ cd prometheus-2.25.2.linux-amd64 $ ls -aF ./ LICENSE console_libraries/ prometheus* promtool* ../ NOTICE consoles/ prometheus.yml
上記の中のprometheusというのがPrometheusサーバー本体ですね。ここで以下のコマンドを実行するとPrometheusが動きます。(編集部注:システム上で iptables などのファイアウォール機能を使っている場合は、コマンド実行前にポート 9090 の通信を許可する必要があります。)
$ ./prometheus
Prometheusを動かしたら、動かしたホストの9090番ポートに接続します。URLとしては下記にアクセスします。
http://(ホストのIPアドレス):9090/

Prometheus起動後の画面
これで最低限のインストールとセットアップは完了しました。非常に簡単です。(編集部注:実行中のprometeusを終了するには、コマンドラインで Ctrl-C を入力します。)
Node Exporterの利用
このままだと何も監視していない状況なので、さらにNode Exporterというものを使ってみようと思います。
本連載の1本目の記事で、Prometheusを使うときにExporterがいろいろあるという話をしました。それを見ていこうと思います。「Prometheus Exporter」で検索すると「Exporters and integrations」というページが出てきて、大量のリンクが表示されます。これらがすべてPrometheusのExporterです。
PrometheusのExporterページ
今回はこの中からNode Exporterを使います。一覧ではNode/system metricsexporterとなっています。これはいわゆるLinuxなどのシステムのメトリクス情報を収集するためのMetrics Exporterになっています。これを使う場合も、先ほどのPrometheusと同じでReleasesページに飛んで、linux-amd64のリンクをコピーして、wgetでダウンロードします。あとは解凍するとnode_exporterディレクトリができあがるので、そのディレクトリに入って、コマンドを動かしてあげるだけでOKです。
$ wget https://github.com/prometheus/node_exporter/releases/download/v1.1.2/node_exporter-1.1.2.linux-amd64.tar.gz $ tar xfz node_exporter-1.1.2.linux-amd64.tar.gz $ cd node_exporter-1.1.2.linux-amd64 $ ./node_exporter
動かしたらログを見て、以下のようなログが出ていればOKです。
msg="Listening on" address=9100
では、Prometheusを使っていく上で、Exporterの情報はどこに書けばいいですかという話をします。先ほどダウンロードしたPrometheusのアーカイブの中に、prometheus.ymlというファイルがあるというお話をしました。このYAMLファイルを開いてみましょう。すると、以下のような形でファイルが書かれています。
$ cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
...
ここからコメントや不要な行を消してあげると、これだけになります。
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
このファイルのscrape_configsというところにPrometheusの設定、特に監視ターゲットの設定を書いていきます。具体的には、ターゲットごとにjob_nameとコンフィグを持ちます。job_nameはprometheusで、static_configsにターゲットを追加します。static_configsというのは、PrometheusのService Discoveryとは別に用意されているターゲット追加機能で、静的にターゲットの情報を収集できるというものです。これを使えば、従来のように単純にサーバのIPアドレスだとかFQDNを渡すだけで簡単にターゲットの監視ができるわけです。
今回はこのstatic_configsを使って、先ほどダウンロードしたNode Exporterを監視します。Node Exporterは9100番ポートでリスニングしているので、下記のように書いて保存すればOKです。
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
あとは、以下のようにPrometheusを実行してあげればOKです。
$ ./prometheus
では実際に動いたPrometheusを見てみましょう。まず上部メニューのStatus→Targetsを選択すると、こんな風にnodeとprometheusが動いています。

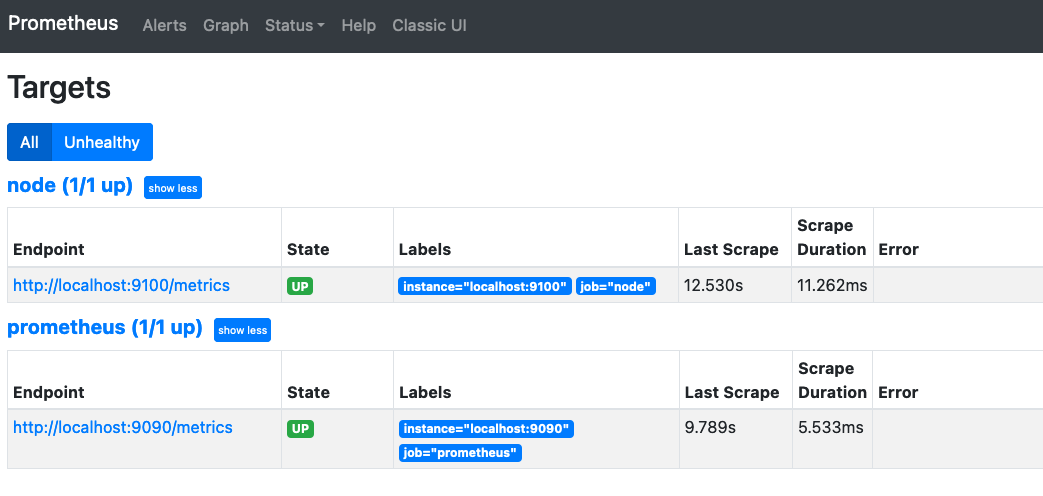
ここで、このサーバのメモリの使用率を見たいとなった場合、画面上部のフォームに「node」と打つと、大量のメトリクスが候補として出てきます。その中からメモリ関係に絞りたいなと思ったら、フォームに「memory」を追記すると、メモリに関わるような情報が出てきます。その中から今回は「node_memory_Active_bytes」を選択します。
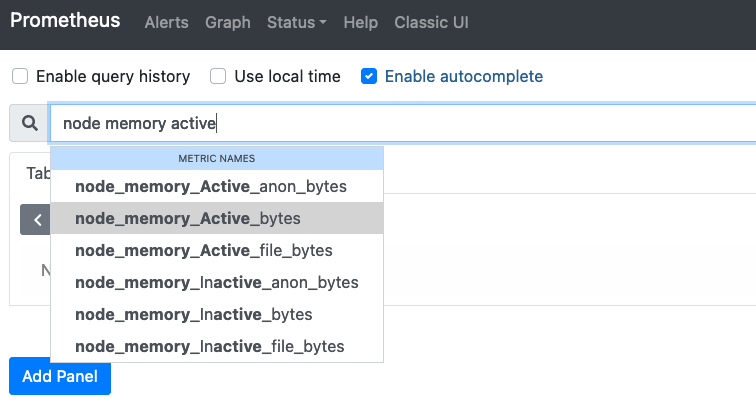
node_memory_Active_bytesを選択
すると、下図のように数値が出てきます。単位はバイトです。
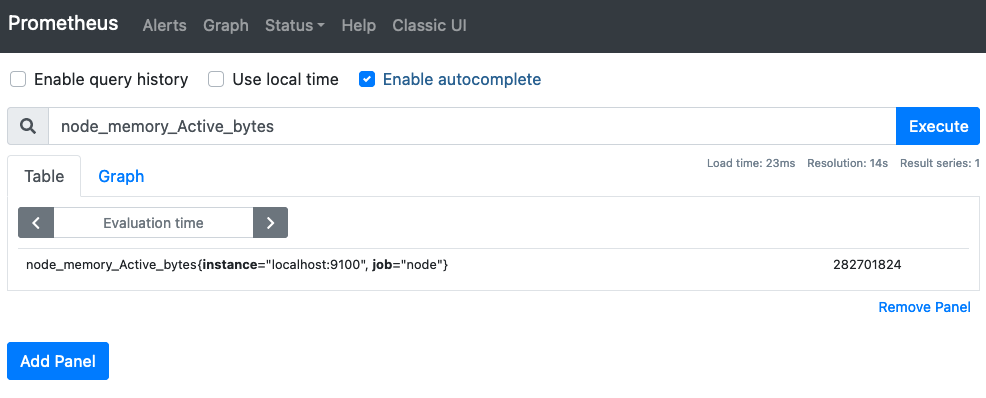
node_memory_Active_bytesを実行したところ
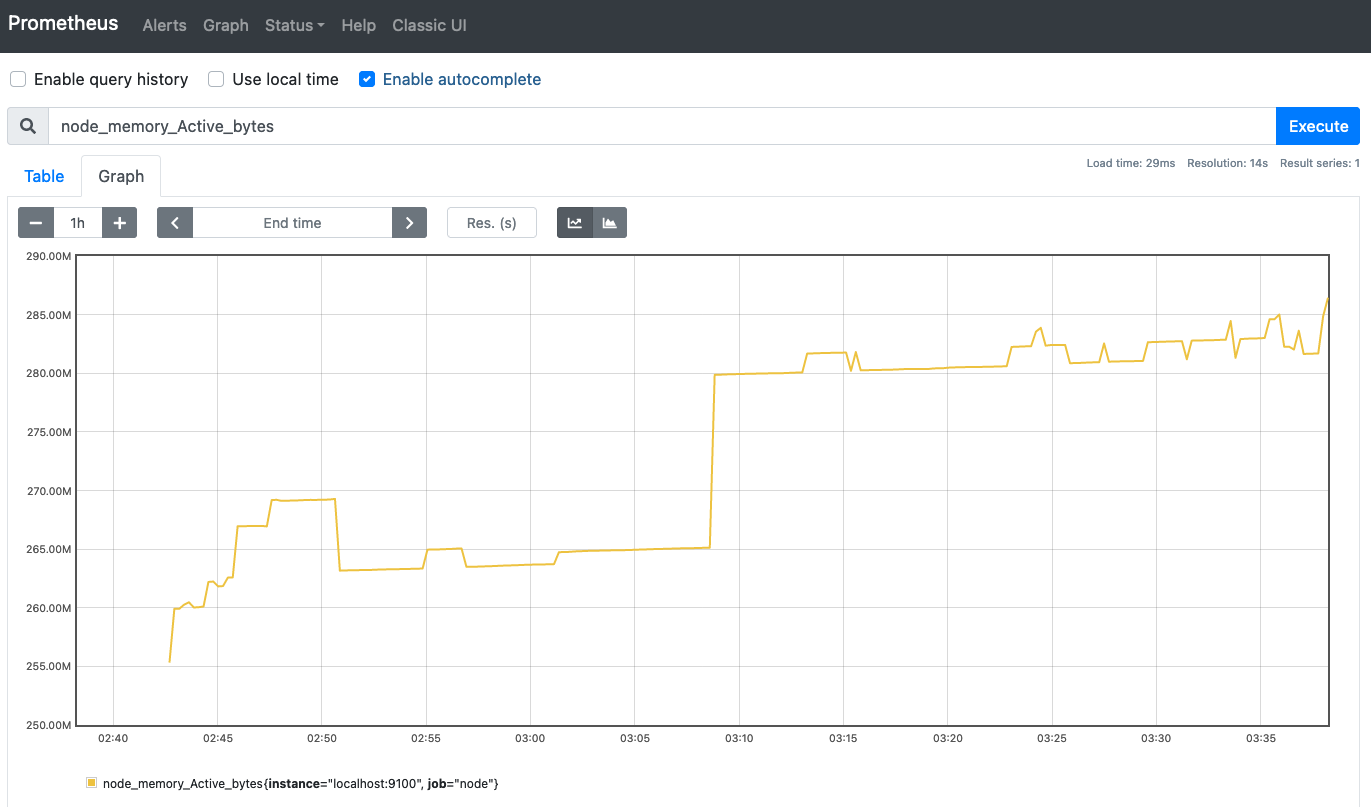
さらに上部のGraphタブを開くとグラフも表示されます。
また、先ほど取得したのはメモリの使用量だけでしたが、使用率を取りたいとなった場合にどうするかというと、割合を取りたい場合は現在の値を全体で割ってあげればよいので、メモリ全体の容量を取得すれば計算できそうです。それもMetricsが用意されていて、node_memory_MemTotal_bytesというものがあります。これを使ってフォームに計算式を書いてあげると、使用率のグラフを表示できます。
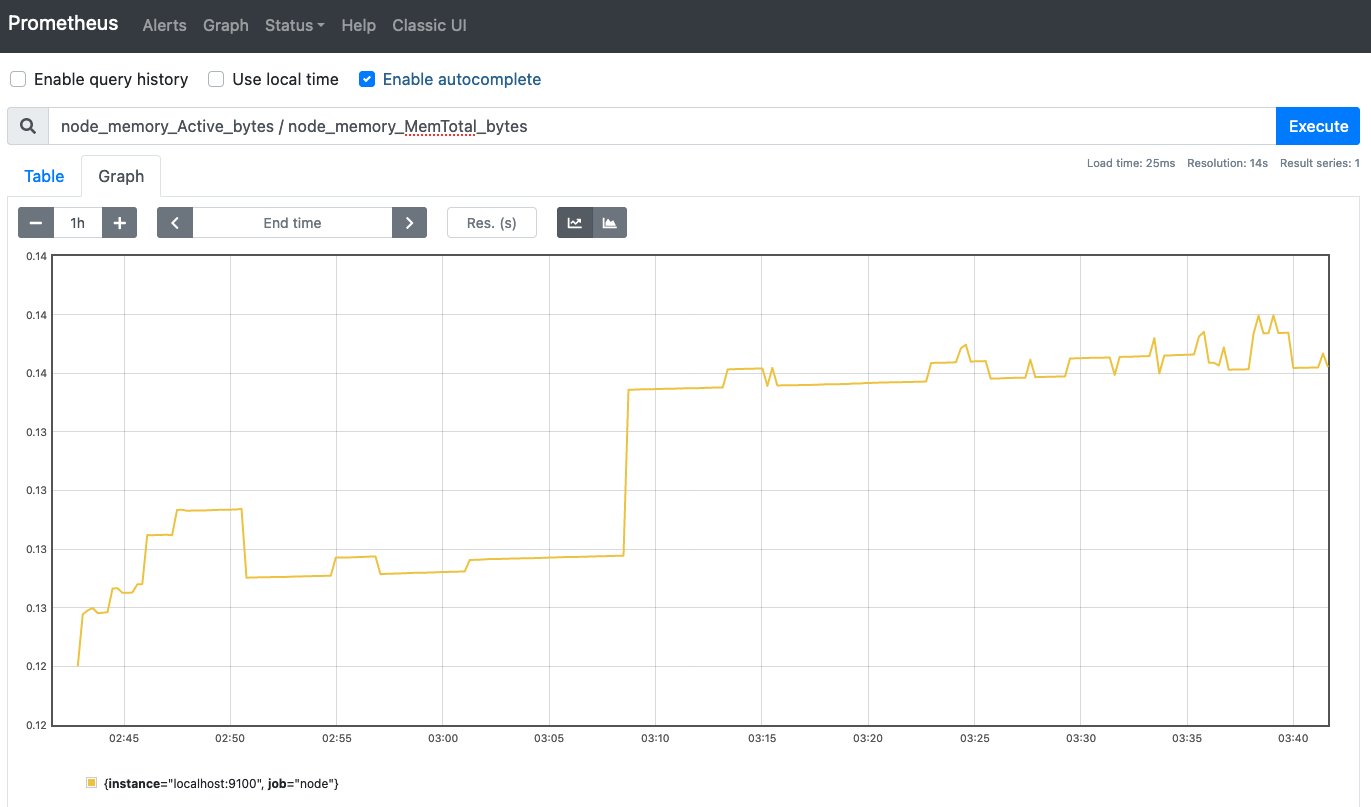
メモリ使用率のグラフは、Y軸の値が小数になっているが、百分率で表示したい場合は「node_memory_Active_bytes / node_memory_MemTotal_bytes * 100」とする
このように非常に簡単、かつとてもシンプルにPrometheusによる監視が実現でき、かつクエリも実行できます。
その他の要素
デモは以上で終わって、この後はPrometheusのその他の要素について軽くお話ししていこうと思います。
Prometheusのストレージ
Prometheusのストレージは、基本的にローカルにデータを持っておりまして、2時間ごとのブロックが作られます。このブロックの中にはChunk(チャンク)データ、Index(インデックス)データ、Meta(メタ)データといった複数のデータが持たれていて、これらのデータによって実際に収集されたMetricsが格納されています。直近2時間未満のデータはメモリ上に展開されておりまして、万が一クラッシュした場合のためにWAL(Write Ahead Log:ログ先行書き込み)が用意されているという形ですね。このような構造ですのでシンプルなんですけども、逆に言うと単体での冗長化だとか永続化の仕組みはありません。

Prometheusのデータ構造
では、冗長化の仕組みがないのでどうするかというと、外部にそういった仕組みを持たせています。これはRemote Storageといって、外部のデータベースに保存する仕組みです。対応したデータベースを利用することによって、そのデータベースに対してMetricsを転送、もしくはそのデータベースからMetricsを読み取ることができます。PostgreSQL、Graphite、InfluxDB、M3DB、Cortex、Thanosなど、さまざまなデータベースが対応しています。これらのデータベース自身が直接PrometheusのRemote Storageをサポートしていたり、あるいはサポートしていなくてもアダプタというものが存在していて、このアダプタをかませることによって、いい形で渡したりというようなことができます。

アダプタを介したRemote Storageの利用
実際にPrometheusを本番で使っていきましょうという場合は、データをローカルに持ち続けてもいいのですが、ある程度の期間だとか大量のデータになる場合は、このRemote Storageを活用していくとよいのではないかと思います。
PromQL
PromQLは、Metricsを抽出、集計する言語です。ラベルによるフィルタリングをどうやってやるのかを軽く紹介していくと、下図のようになります。
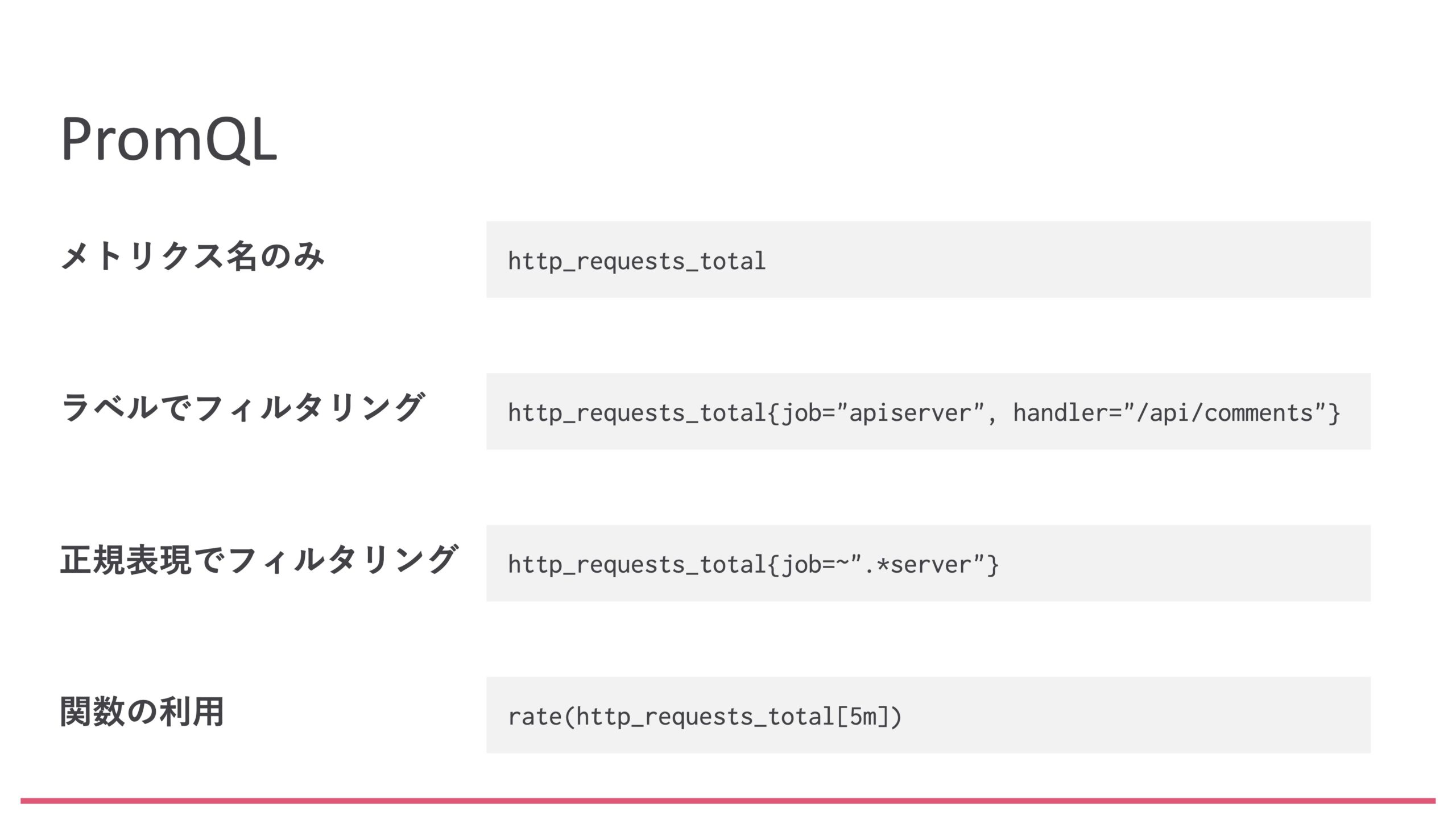
一番上の例は単にメトリクス名のみを使った場合です。先ほどのデモでもnode_memory_MemTotal_bytesだとかnode_memory_Active_bytesといったものを使いましたが、あれはMetricsそのものをただ単に引っ張ってきたというものになります。
今回はサーバが1つだけだったので1つのMetricsが取れましたが、これが複数台や複数のコンポーネントが存在する場合は、それぞれでフィルタリングする必要があります。そうなった場合は、上から2番目に書いてあるラベルによるフィルタリングを使うことによって実現できます。ラベルは、メトリクス名の後に"{...}"で囲んで指定すればOKです。この例ではjobがapiserverとなっていますが、先ほどはnodeとかprometheusというjobがありました。それらをjobに書けば、Node Exporterが取得したMetricsだけ抽出できたり、prometheusと指定すればPrometheusのMetricsだけが抽出されたり、というのが簡単にできるわけです。
この他にも、正規表現でフィルタリングできたりだとか、抽出したメトリクスを関数を使って加工するというようなこともできたりします。
まとめ
Prometheusはクラウドネイティブなシステム監視ソフトウェアの1つです。とてもシンプルかつ簡単に利用できるところが大きな特徴です。
さらに、今回はご紹介できませんでしたが強力なService Discoveryの機能がありますので、例えばKubernetesを使うとか、クラウドプラットフォームを使う場合には、特にぜひこれを利用していただきたいと思います。
また、AlertManagerやGrafanaと連携させることによって、Prometheus単体ではできない機能が利用できます。逆に言うと、高度な可視化やAlertingは不要で、ただ単にデータを収集してくれて軽く検索できればいいということであればPrometheus単体で十分です。Alertingだけは欲しいという場合はAlertManagerを使えばいいですし、Alertingはいらないから可視化だけやりたいという場合はGrafanaを組み合わせればいいです。そういった形で組み合わせて連携することができます。
最後に、Prometheusを使う上でぜひ覚えていただきたいのは、このPrometheusはObservabilityの実現に向けた1つのツールでもあるので、ぜひそういった視点で使っていただければと思います。
さあ皆さん! Prometheusを完全に理解しましたか? この記事を読んで理解した方はぜひ「Prometheus完全に理解した」とツイートしていただければと思います!
