今日から始めるPrometheusによるシステム監視(2) 〜PrometheusとCNCF、Observability〜

この記事は2021年3月6日に行われたオープンソースカンファレンス 2021 Online/Springにおける発表を文章化したものです。
今回は「今日から始めるPrometheusによるシステム監視」ということで、Prometheusというツールについてご紹介をしていこうかなと思います。皆さんに「Prometheus完全に理解した」と言えるようになっていただきたいというのが今回の目標です。
本連載は3本で構成されていて、それぞれ以下の内容を扱います。
- Prometheusの特徴とアーキテクチャ
- PrometheusとCNCF、Observability(この記事)
- Prometheusを使ってみよう
PrometheusとCNCF
Prometheusは、CNCF(Cloud Native Computing Foundation)という組織のプロジェクトの1つとしてホストされています。Linux Foundationをご存じの方も多いかと思いますが、CNCFはこのLinux Foundation配下の組織の1つでして、クラウドネイティブなオープンソースのプロジェクトを推進する組織です。クラウドネイティブないろんなソフトウェアをどんどん使っていこうね、それがどんどん成熟するように推進していくよ、後押ししていくよう手伝うよ、というようなコミュニティがCNCFです。
CNCFのWebサイト
実はPrometheusは、このCNCFの2つ目のGraduated Project(グラデュエーテッド・プロジェクト)です。Graduated Projectとは何かというと、いわゆる「卒業プロジェクト」というふうによく言われます。
CNCFのプロジェクトには主に3段階あって、下からSandbox(サンドボックス)、Incubating(インキュベート)、Graduatedの3つがあります。Sandboxが最も若い、出たばかり、まだまだ将来性はあるけどバグも多かったり、メンテナーも少なかったり、といったところで、まだまだ浅い、いわゆる本当に使う人が限られるようなプロジェクトが位置します。Incubating Projectというのは、ある程度認知も増えてきて、ソフトウェアとしても完成してきているけれども、コミュニティの状態だとか、もしくはソフトウェアの成熟度が足りない、といったレベルであることを示します。
最後に、これらをある程度満たした状態、これは単にソフトウェアそのものの成熟度以外にも、そこを取り巻くコミュニティだとか、メンテナンスの継続性だとか、いろんな視点から、このソフトウェアは今後、独立して十分やっていけるね、CNCFが後押しをしなくても十分やっていけるプロジェクトになったね、という状態になったものがGraduatedと言われてまして、PrometheusはこのGraduated Projectの2番目のプロジェクトとして認められたという形になります。ですので、実はPrometheusは出てからすでになかなかの年数も経っているというのもありますし、卒業プロジェクトの1つでもあるので、いろんなところで使われ始めています。
また、CNCFのプロジェクトの3つのフェーズは、イノベーター理論と呼ばれるものとすごく合致しています。Sandboxプロジェクトはイノベーター層。Incubatingはアーリーアダプタ層。Graduated Projectはアーリーマジョリティ層以降という形で、そういった層の人々が使うと言われています。
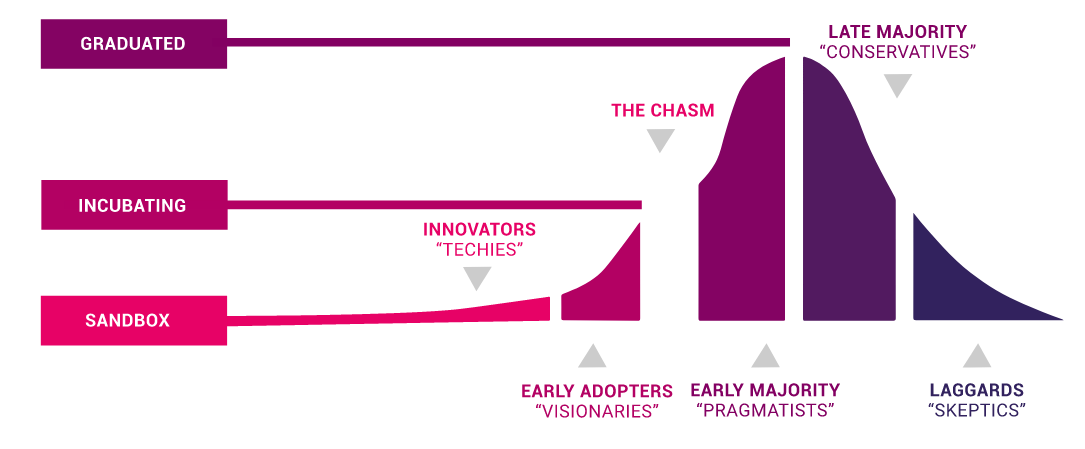
CNCFのプロジェクトのフェーズとイノベーター理論の関係(出典)
イノベーター理論にはキャズムというものがあります。アーリーアダプターからアーリーマジョリティに行くまでの間に、最後に超えなければならないひと踏ん張りというのがあると思うんですけども、これを超えたということは、もうある程度の人たちが使ってもいい、それこそエンタープライズ系のように、それなりに実績のあるものを使いたいという人たちでも使えるようなプロジェクトとして認められたということで、Prometheusは非常に成熟度が高くなってきているプロジェクトの1つでもあります。
ただ、例えばZabbixのようにかなり安定していて枯れているかというと、まだまだそういうわけではないので、Zabbixとかに比べるとまだまだ歴史は浅いんですけども、そんな中でも比較的いろんな方に使っていただけるソフトウェアの1つかなと思います。
Observabilityとは
というわけで、Prometheusはある程度成熟していて、かつクラウドネイティブのモニタリングソフトウェアというお話をしてきました。このクラウドネイティブを語る上でよく出てくるキーワードとしては、コンテナとかサービスメッシュとかマイクロサービスなどがありますが、特にPrometheusを使う上で意識した方がよいものとして、「Observability」(オブザーバビリティ)というキーワードがあります。そもそも「クラウドネイティブとは何ですか?」といったところはCNCFのサイトで公開されているのをぜひ調べていただきたいんですけども、その中でもこのObservabilityというものが挙げられています。このObservabilityって何ですか?というところもちょっと深掘りしていこうと思います。
というわけでObservabilityを語っていきたいんですけども、その前に1つ、皆さんにご注意があります。Observabilityという言葉は、実は人によって意味が異なります。つまりこれから私が話をする「Observabilityはこういうものですよ」という意見や解釈というのは、人によって違ったりだとか、ある人は別の視点だったりとかします。ですので皆さんにおかれましては、私が言ったことがすべてではなく、「あ、この人はこういうふうにObservabilityを捉えているんだ」というふうな形で見ていただければと思います。

Observabilityという言葉、日本語にすると「可観測性」なんですけども、これはどういうことかと言うと、システムの状態を取得して見える状態にする、つまり可観測な状態にすることを可観測性、Observabilityと定義しています。このObservability、つまりシステムの状態を取得して見える化するってどういうこと?という話を、より深掘りしていきます。
従来の、例えば10年前のシステムは、Web 3層モデルと呼ばれるような、ロードバランサがあって、Webサーバ、アプリケーションサーバ、データベースという、下図のような簡単な3層モデルが多かったと思うんですよね。万が一こういったシステムで障害が起こったとしても、それぞれのコンポーネントレベルで追っていけばよかったので、障害のトラブルシューティングは比較的容易に行うことができました。
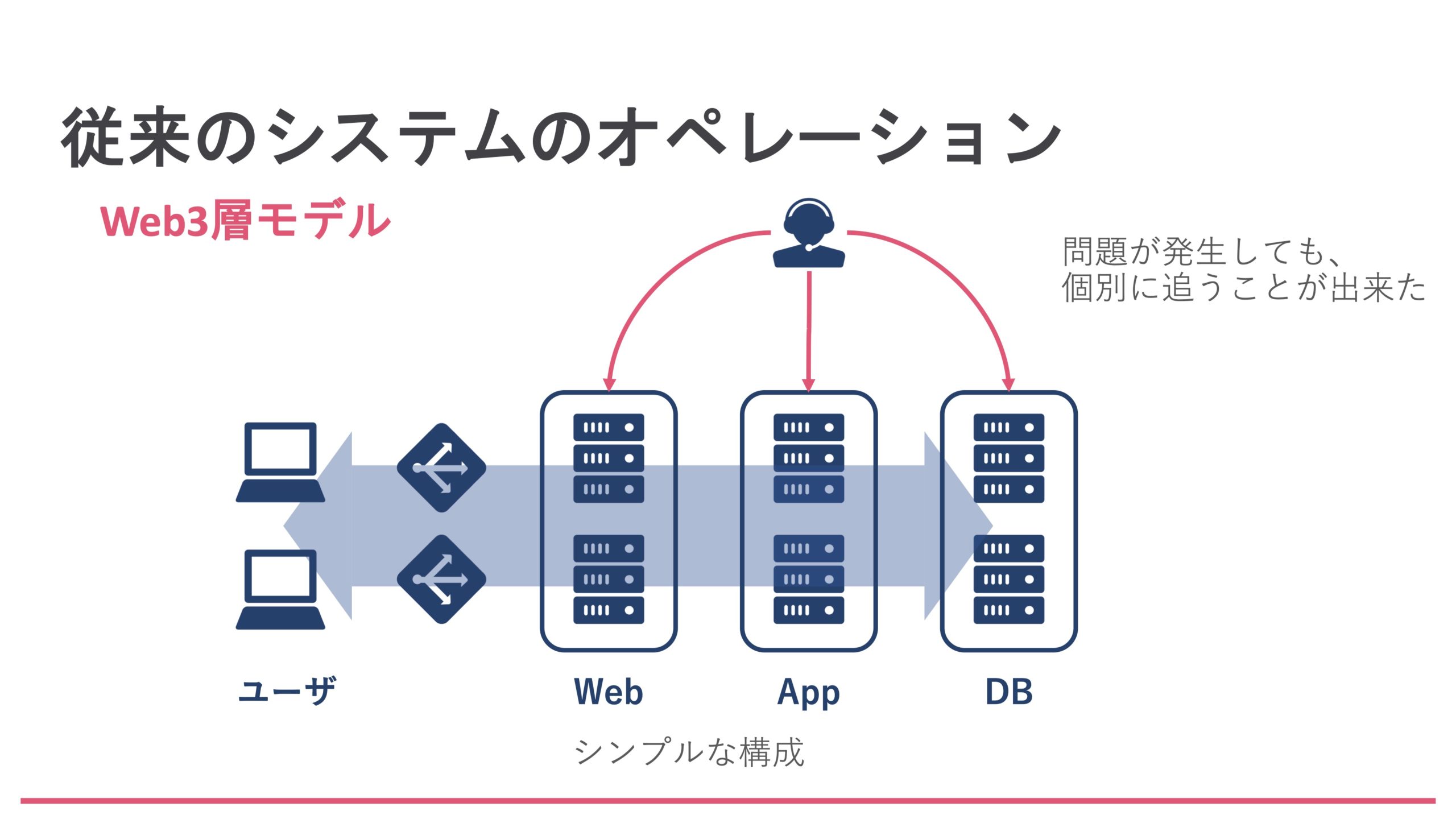
しかし、現在はKubernetesをはじめとして、マイクロサービスと呼ばれるようなものが全盛の時代です。このような分散システムでは、小さなサービスを組み合わせて使います。システム内に大量のコンポーネントが存在していますので、障害が発生したときに1つ1つを人間の手で追うというのはなかなか難しいというか、ちょっと無理ではないかというレベルなんですね。
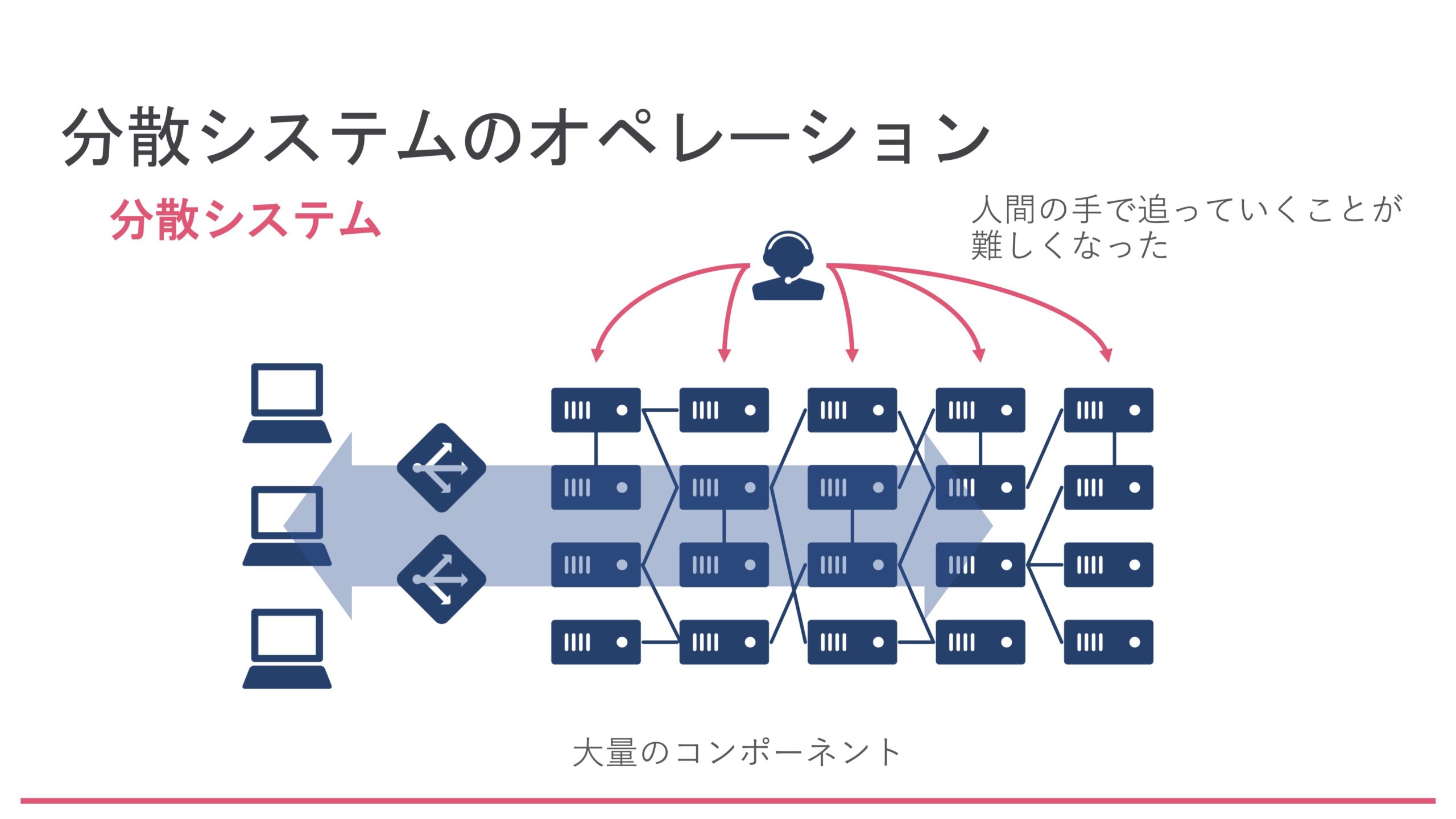
すごくいい例がありまして、こちらはTwitterの分散システムの例です。この円のように広がっているトゲトゲしたものは、1つ1つが実はシステム名です。その円の中に引かれている1つ1つの線がシステム間のつながりです。このように、ある程度大規模なシステムになってくると構成は非常に複雑になります。これらを人間の手で1つ1つ追うのは無理ですよね。といったところで、これらのシステムの状態をきちんと横断的に見えるようにしましょうというのがObservabilityという話なのです。
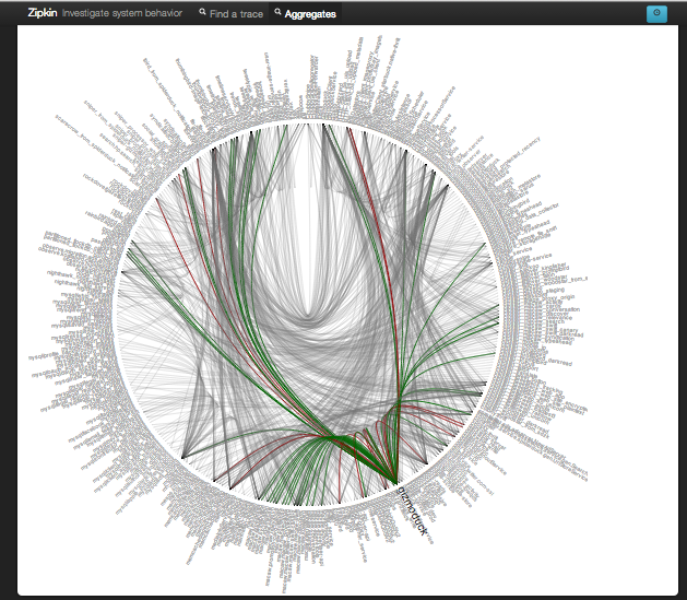
Twitterの分散システム (出典:Observability at Twitter)
ですので、Prometheusを使っていく上で、ただの監視ツールとして使うのも全然OKです。ただ、Prometheusを使っていく上でぜひ気にかけていただきたいのは、PrometheusはObservabilityを実現する要素の1つであるという点です。さまざまなコンポーネントを1つ1つ手で登録していくのではなく、Service Discoveryを使って簡単に登録すると。そうすることによって、人間が今まで手で行っていたような作業を自動化し、ある程度システム側に寄せることができたりだとか、クラウドネイティブにできるよね、というような話だと思います。
ObservabilityとPrometheus
続けて、ObservabilityとPrometheusについてお話をしていきたいと思います。Observabilityを語る上で、また新しい言葉がでてきて申し訳ないのですがご留意いただきたい用語がありまして、「Telemetry」(テレメトリ)という言葉があります。Telemetryというのは何かといいますと、Observabilityを実現するためのツールに求められる要素の一つです。ObservabilityとTelemetryはイコールではないのでご注意ください。あくまでも要素であるよというふうに私は解釈しています。
ですので、Telemetryを実現するツールを導入すること自体がObservabilityの実現ではありません。つまり、Prometheusを使ったからObservabilityが実現できましたというわけではありません。Prometheusはあくまでもそれを実現するためのツールであって、Prometheusを使うだけではなく、それを活用することによってどうやってObservabilityを実現していくか、横断的にシステムの状態を見えるようにするかっていうのが、Observabilityを作り上げていく上での目的という話なんですね。
Telemetryを語るときに出てくる要素として、Metrics、Logging、Tracingの3つがあります。Metricsはご存じの方もいると思いますが、例えばZabbixなどもMetricsを使っていますし、世の中の監視システムのほとんどはMetricsを前提としています。次にLogging。これも当たり前に使っていると思います。ここでちょっとあまり見ない用語はTracingですね。分散トレーシングも結構昔からある言葉ではあるんですけども、あまり身近ではないかもしれません。
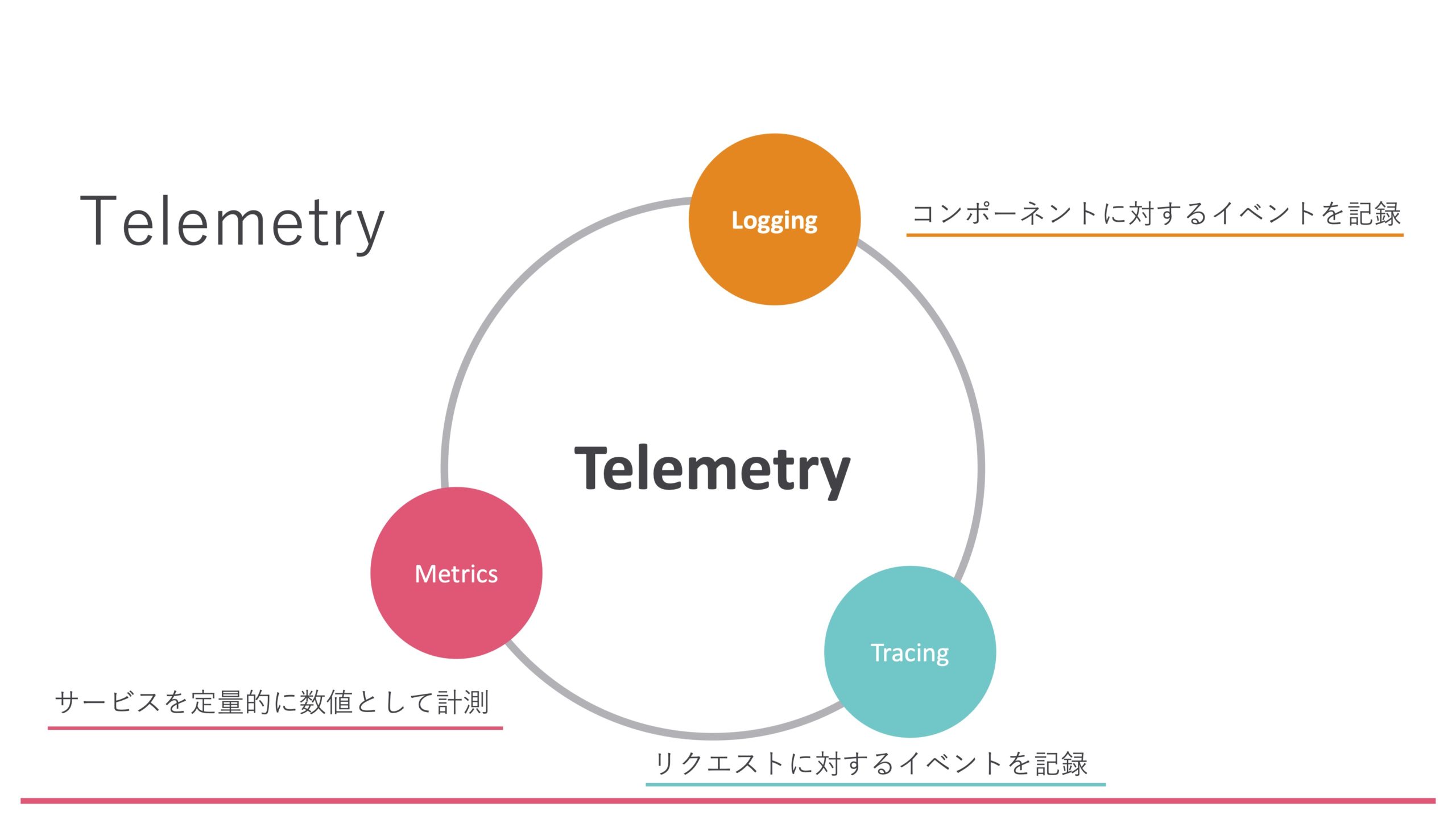
Observabilityを実現していくにはこの3つの要素を適切に扱っていく必要があるんですけども、Prometheusがこれらすべてを実現できるかというとそんなことがなくて、Prometheusはこの中の要素の1つ、具体的にはMetricsを実現するためのツールなんですね。このMetricsというのは、継続的な数値データであったりします。例えばメモリの使用量があるタイミングで1GBでした、あるタイミングで2GBでした、それが3GBになり、また2GBに戻りましたというような継続的なデータだったりだとか、あとはそれが時系列として並んでいるようなデータですね。
こういったデータは比較的構造がシンプルなので統計的な集計ができます。例えば、ある時間全体を見て、実際にどのような変化があったのか、もしくはシステムのリソースの使用量はどのくらいだったのか、そういった集計ができるわけですね。また、その集計をしていくことによって、例えば毎週金曜日はMetricsが大幅に上昇しているので、仕事が終わった後にみんなWebサイトにアクセスするんだろうなといったことがわかり、対策としてサービスをスケールしたり、相応にインスタンスを追加したりというようなことができたりします。つまり、Prometheusを使うことによって、Metricsを活用した集計やトレンド予測が実現できます。

次回は
次回は、Prometheusを実際に始めるにはどうすればよいか、という話をしていこうと思います。